- The paper demonstrates that tool-augmented LLMs achieve a 19.3% gain in final-answer accuracy while suffering from significant reasoning coherence loss.
- The study employs a benchmark of 1,679 mathematical problems and a multi-dimensional metric suite to assess the degradation in reasoning due to tool reliance.
- The paper proposes mitigation strategies, including prompting interventions and preference-optimization fine-tuning, to balance tool use with coherent internal reasoning.
Introduction
The study "From Proof to Program: Characterizing Tool-Induced Reasoning Hallucinations in LLMs" (2511.10899) investigates the impacts of tool augmentation on the reasoning capabilities of LLMs. Specifically, it focuses on Tool-Augmented LLMs (TaLMs) using external code interpreters to solve complex mathematical problems. The core issue identified is "Tool-Induced Myopia" (\task{}), where models overly rely on tool outputs at the expense of coherent internal reasoning.
Methodology
The investigation uses a benchmark of 1,679 competition-level mathematical problems, requiring a mix of computational support and abstract reasoning. The study develops a multi-dimensional metric suite to assess the degradation in reasoning potentially induced by tool use. This includes final-answer accuracy, win rates in reasoning processes, miss rates for logical steps, and process reward models (PRMs) for step-level evaluation. Notably, TaLMs were assessed against their Base (non-tool-enhanced) LLM counterparts.

Figure 1: Comparison of Base LLM and Tool-augmented LLM (TaLM) reasoning. The Base LLM (top) derives the solution through step-by-step mathematical reasoning, while the TaLM (bottom) relies on empirical checks and multiple tool calls to search for the minimum, a failure mode characteristic of Tool-Induced Myopia (\task).
Experimental Findings
The analysis reveals that TaLMs achieve a 19.3 percentage point gain in final-answer accuracy. However, their reasoning, compared to non-tool-enhanced LLMs, often lacks coherence, with the reasoning process deteriorating as tool reliance increases. This overreliance shifts error patterns from simple arithmetic issues to more severe global reasoning failures, encompassing logic, assumptions, and creative strategy missteps. Moreover, statistical analysis indicated no significant correlation between code complexity and the presence of \task, suggesting \task{} is not driven merely by complex or difficult code but rather by the strategic use of the tool.
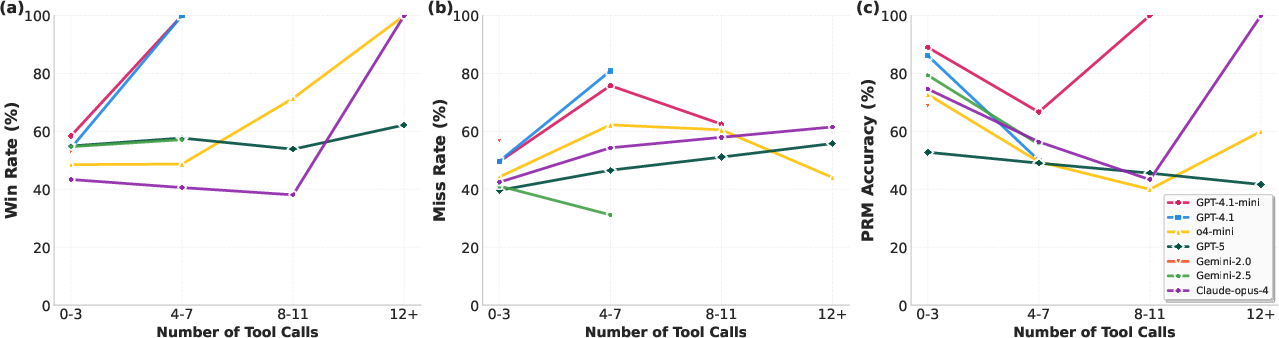
Figure 2: Reasoning behavior vs. tool usage. Metrics are computed over bins defined by the number of tool calls in model solution: {0--3, 4--7, 8--11, 12+}.
Mitigation Approaches
To address \task, the study proposes two strategies. The first is a prompting intervention encouraging models to use tools as evidentiary support rather than central pillars of reasoning. The second, more technical approach, involves preference-optimization-based fine-tuning, which effectively encourages the integration of code interpreters as assistants rather than focal reasoning components. Experimentation with these mitigations demonstrates improved reasoning behavior and higher reasoning depth alongside tool utilization.
Practical Implications
These findings highlight crucial considerations for the deployment of TaLMs in real-world applications. In domains where trust and reliability are paramount, understanding and addressing tool-induced reasoning deficiencies is critical. The proposed strategies for mitigation offer a pathway for enhancing reasoning fidelity, particularly in tasks demanding robust problem-solving capabilities.
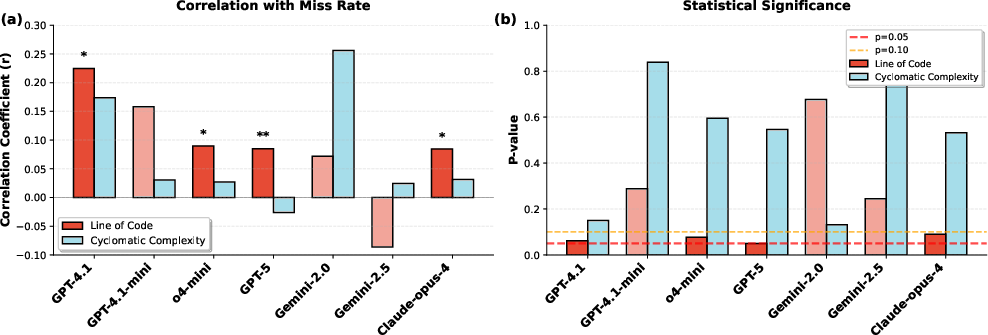
Figure 3: Correlation between code complexity metrics and Miss Rate across TaLMs. (a) Pearson correlation coefficients for Line of Code and Cyclomatic Complexity with Miss Rate. (b) Corresponding p-values with significance thresholds at p=0.05 (red) and p=0.10 (orange). Asterisks denote marginal significance (**p<0.10, **p<0.05). No statistically significant correlations are found, suggesting that \task{} is not driven by code complexity.
Conclusion
This paper provides an in-depth characterization of \task{}, a subtle yet impactful form of reasoning hallucination in tool-augmented LLMs. Through rigorous experimentation and innovative metric development, it sheds light on previously underexplored dimensions of LLM reasoning degradation. Achieving a balance between computational capabilities and intrinsic problem-solving skills is essential to harnessing the full potential of advanced LLMs in practical, high-stakes scenarios.