- The paper introduces Blend-ASC, a hyperparameter-free adaptive variant of Self-Consistency that reduces sample usage by up to 6.8×.
- It derives power-law scaling laws for margin differences, offering theoretical guarantees for convergence in large language model inference.
- Extensive experiments demonstrate that Blend-ASC outperforms traditional methods, ensuring efficient and scalable reasoning with LLMs.
Optimal Self-Consistency for Efficient Reasoning with LLMs
Introduction
The paper "Optimal Self-Consistency for Efficient Reasoning with LLMs" (arXiv ID: (2511.12309)) addresses the challenge of improving test-time inference for LLMs through a method known as Self-Consistency (SC). This technique involves generating multiple responses from an LLM, selecting the most frequent answer, and can be understood as a plurality vote or an empirical mode estimation. However, the naive application of SC is not scalable due to its inefficiency and the lack of a unified theoretical treatment.
Theoretical Foundations and Analysis
The authors provide a comprehensive analysis of the scaling behavior and sample efficiency of SC, framing it within mode estimation and voting theory. They derive power-law scaling laws for SC across datasets and scrutinize the sample efficiency of both fixed-allocation and adaptive sampling strategies. The paper introduces Blend-ASC, a hyperparameter-free variant of SC that dynamically allocates samples, thereby significantly enhancing sample efficiency by using 6.8× fewer samples than traditional SC.
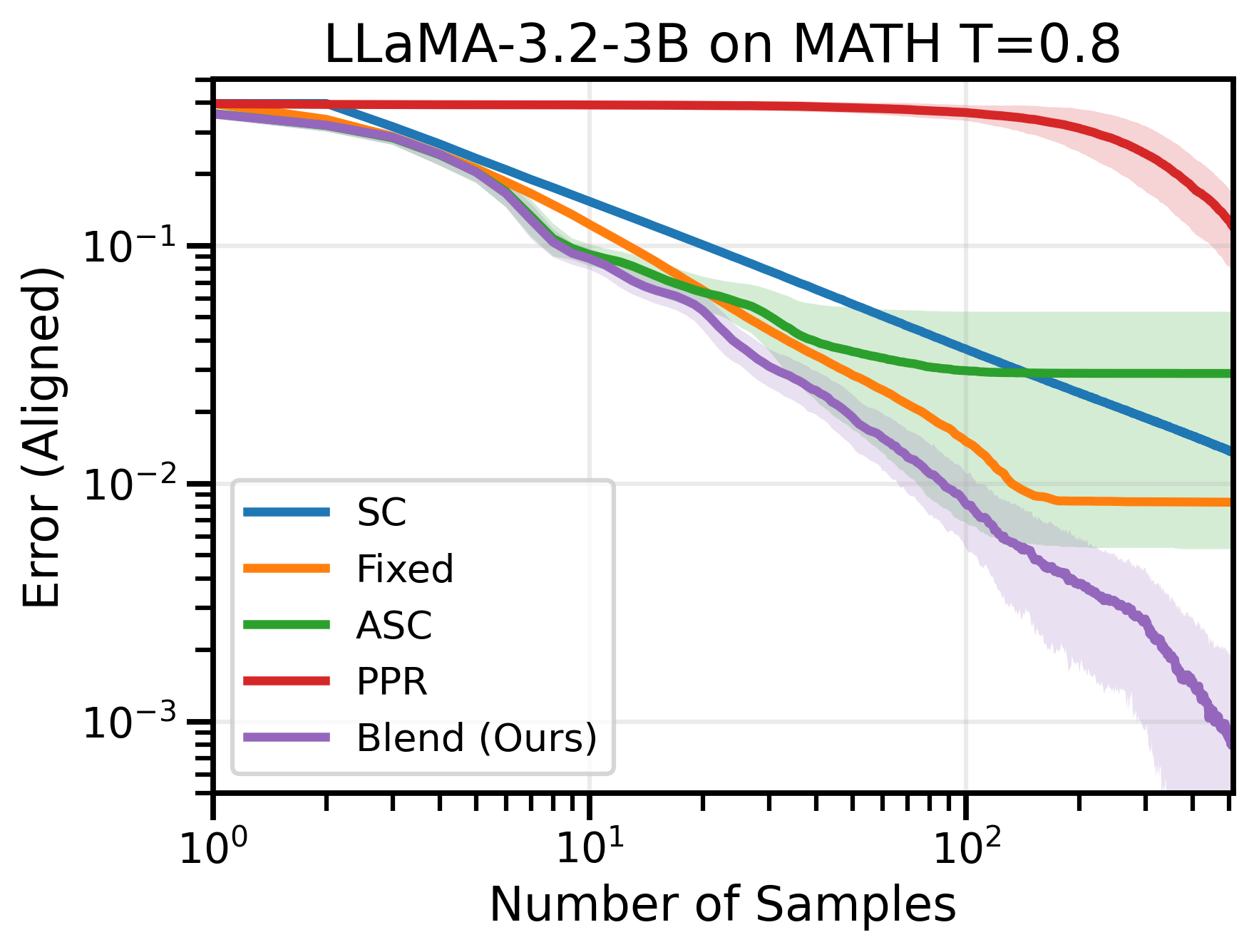
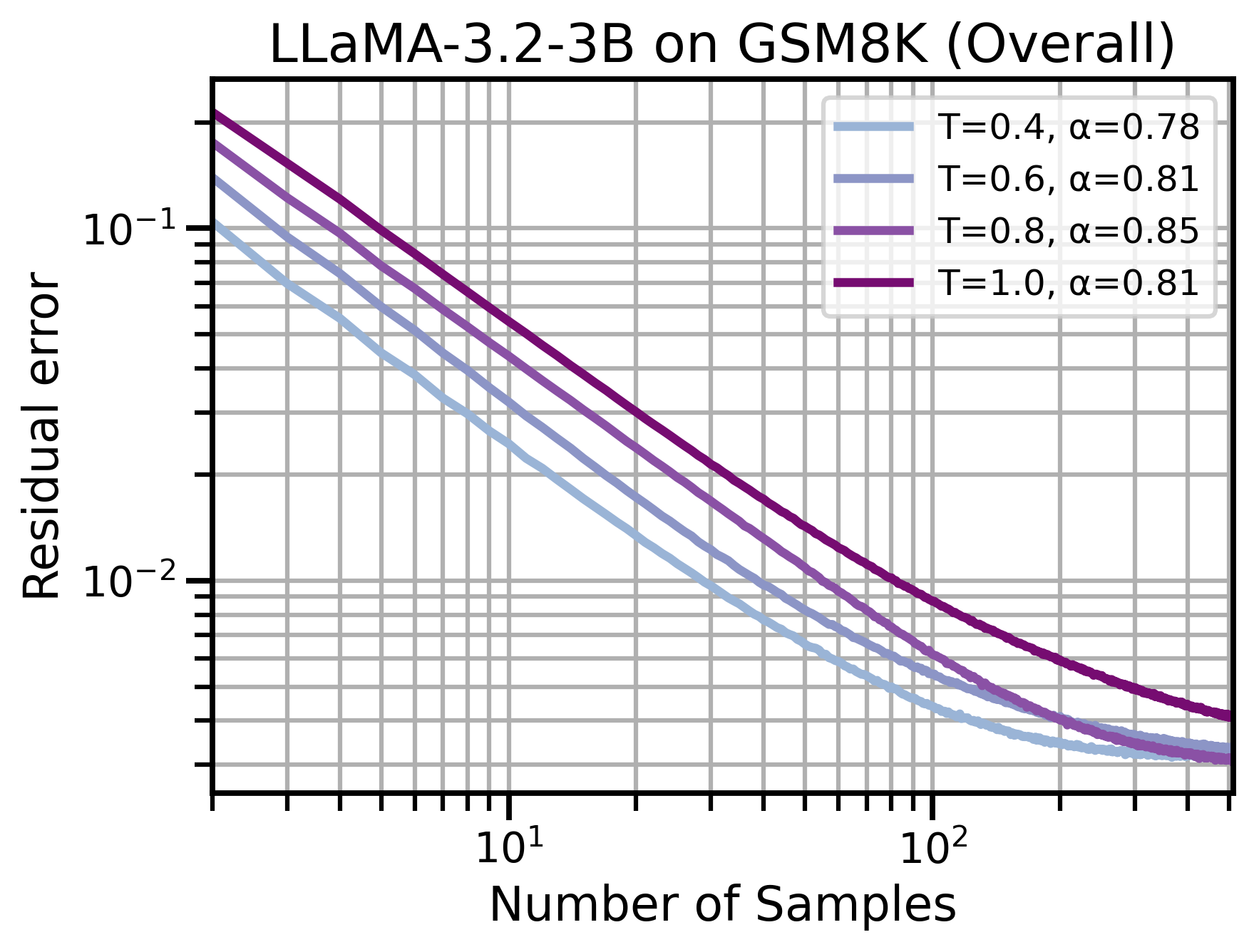
Figure 1: (Left) Blend-ASC outperforms SC, ASC, Fixed-Allocation SC, and asymptotically-optimal PPR-1v1, by converging to the limiting answer the fastest on aligned questions. (Right) SC exhibits scaling laws across free-response datasets, with power-law convergence to its limiting error.
Self-Consistency as Mode Estimation
SC, when viewed through the lens of mode estimation, simplifies to generating several outputs from the LLM and selecting the most frequent one, akin to a majority vote. This method is particularly effective when the model is aligned with the input question, converging to the correct answer as the number of samples increases. However, its efficiency at scale is hindered by the uniform allocation of samples, a problem the paper addresses by proposing adaptive sampling.
Through theoretical modeling, the authors show that margins (differences between the most and second most probable responses) lead to predictable power-law scaling across datasets. This insight allows the paper to propose optimal sampling strategies that significantly reduce the computational resources required for inference.
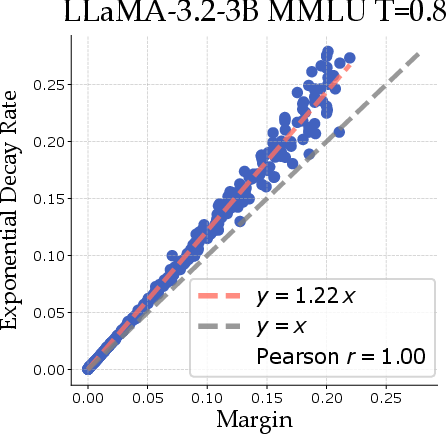
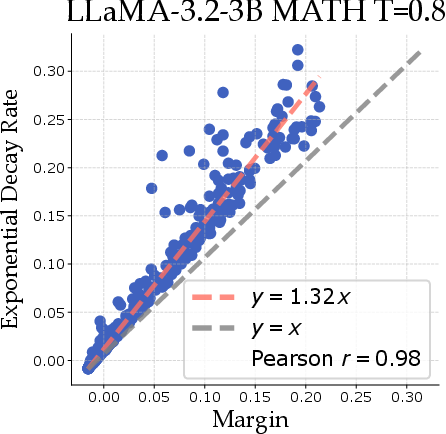
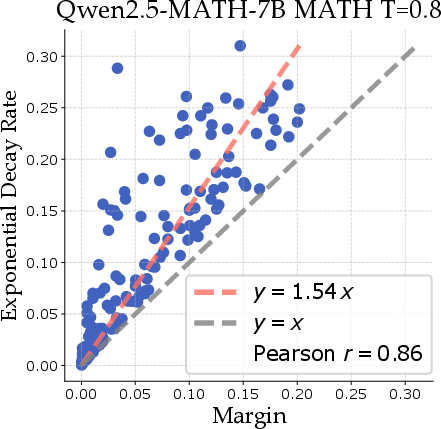
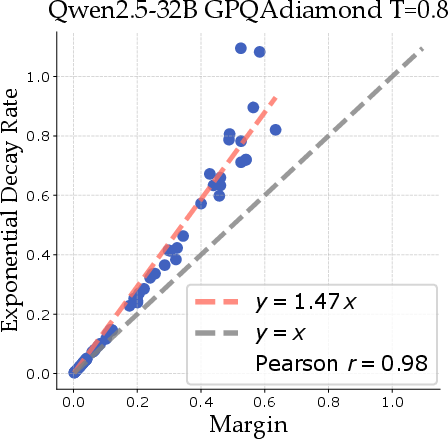
Figure 2: Margin correlates with decay rate across several model and dataset combinations, where decay is fit for x≥16 for ϵ to have negligible impact on the bound.
Optimal Adaptive Self-Consistency
The core contribution, Blend-ASC, combines the dynamic allocation strengths of existing methods with a novel approach that utilizes adaptive confidence scores to efficiently allocate samples among questions. Unlike previous approaches that require extensive tuning or fixed budgets, Blend-ASC adjusts dynamically, providing a practical, scalable solution for deploying SC in large-scale applications.
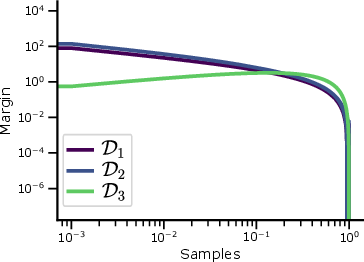
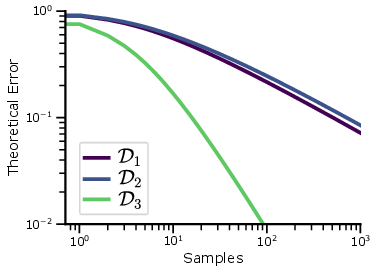
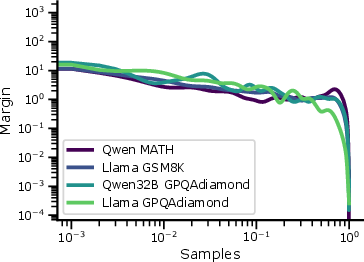
Figure 3: Large dataset sizes induce power-law scaling. (Left) Margin distribution for D1−D3 with n=1. (Middle) Error scaling D1−D3, with D3 having the fastest convergence. (Right) Margin distribution from sampling 100 points from each dataset and applying KDE.
Numerical Experiments
The paper demonstrates through extensive experiments that Blend-ASC outperforms existing SC variants, achieving superior sample efficiency across various datasets and model combinations. This is evidenced by its consistent edge in mode estimation and reduced sample requirements for error minimization.
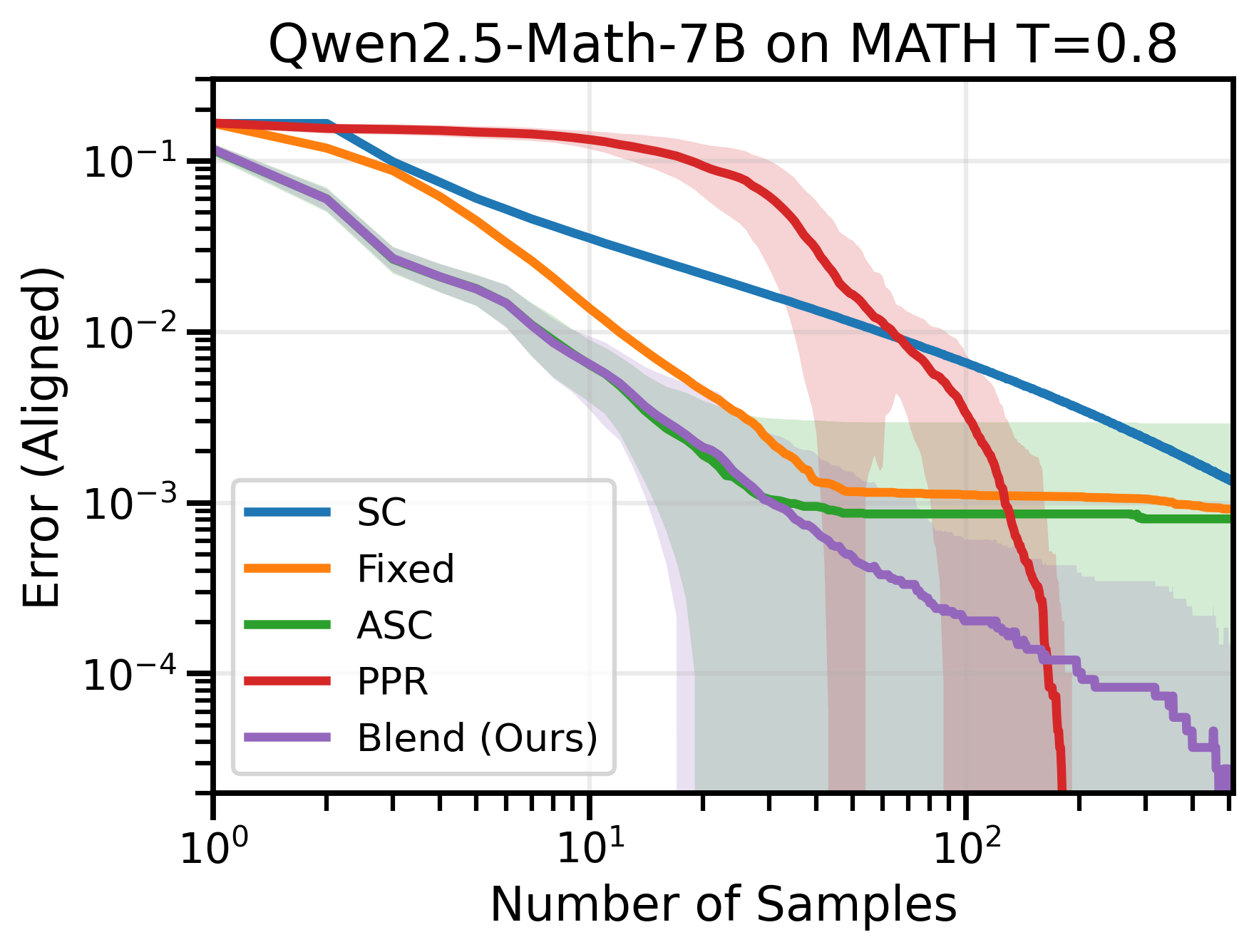
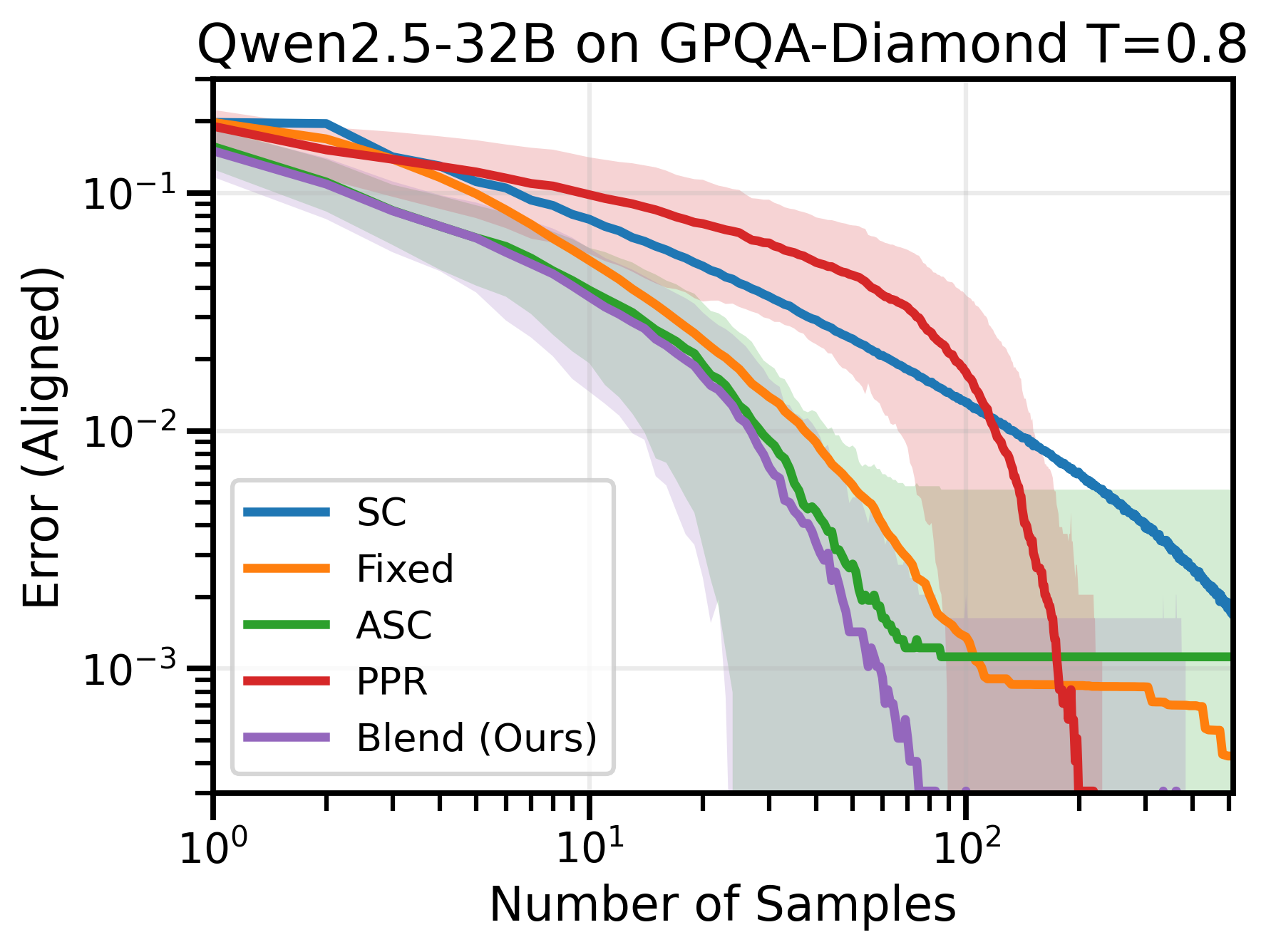
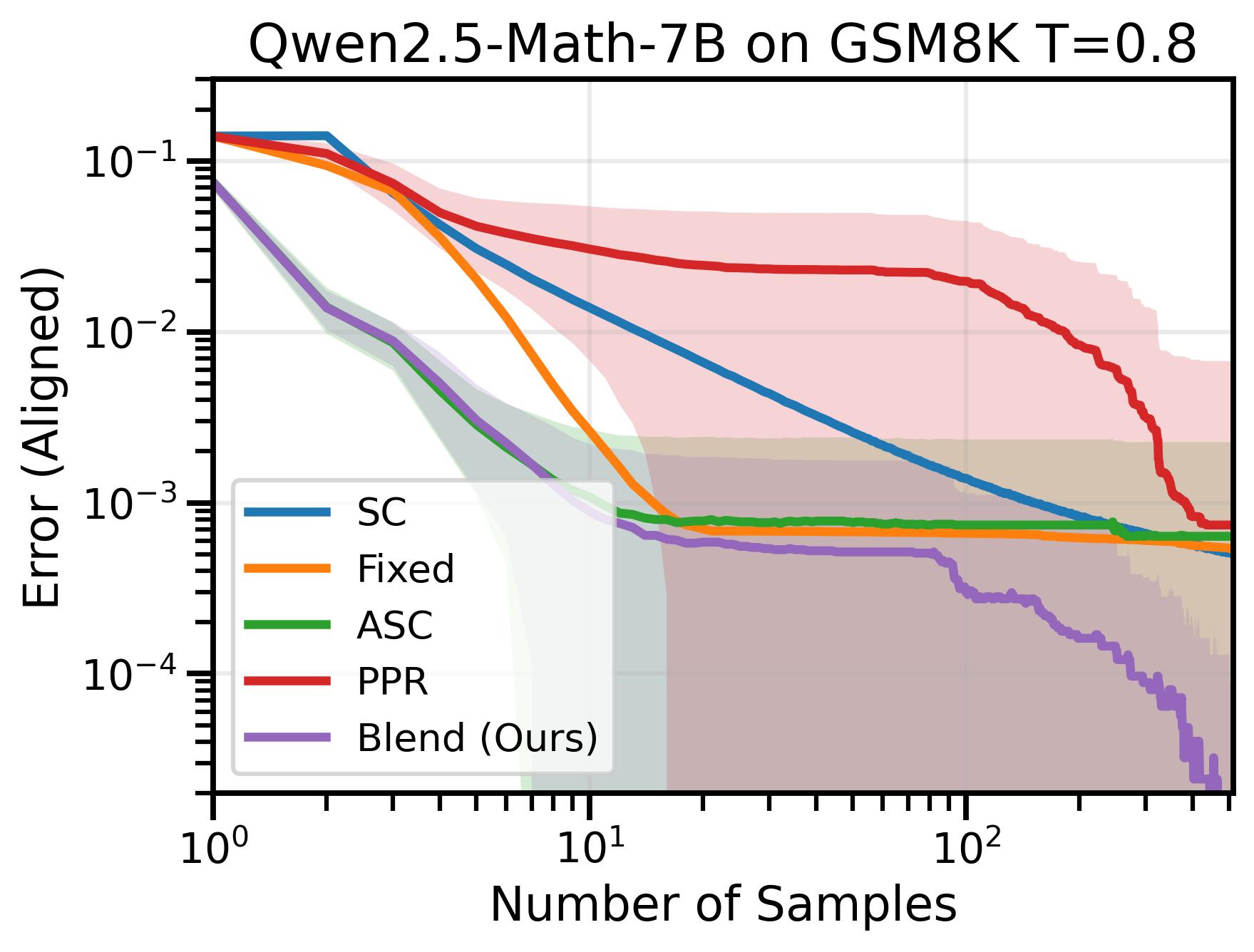
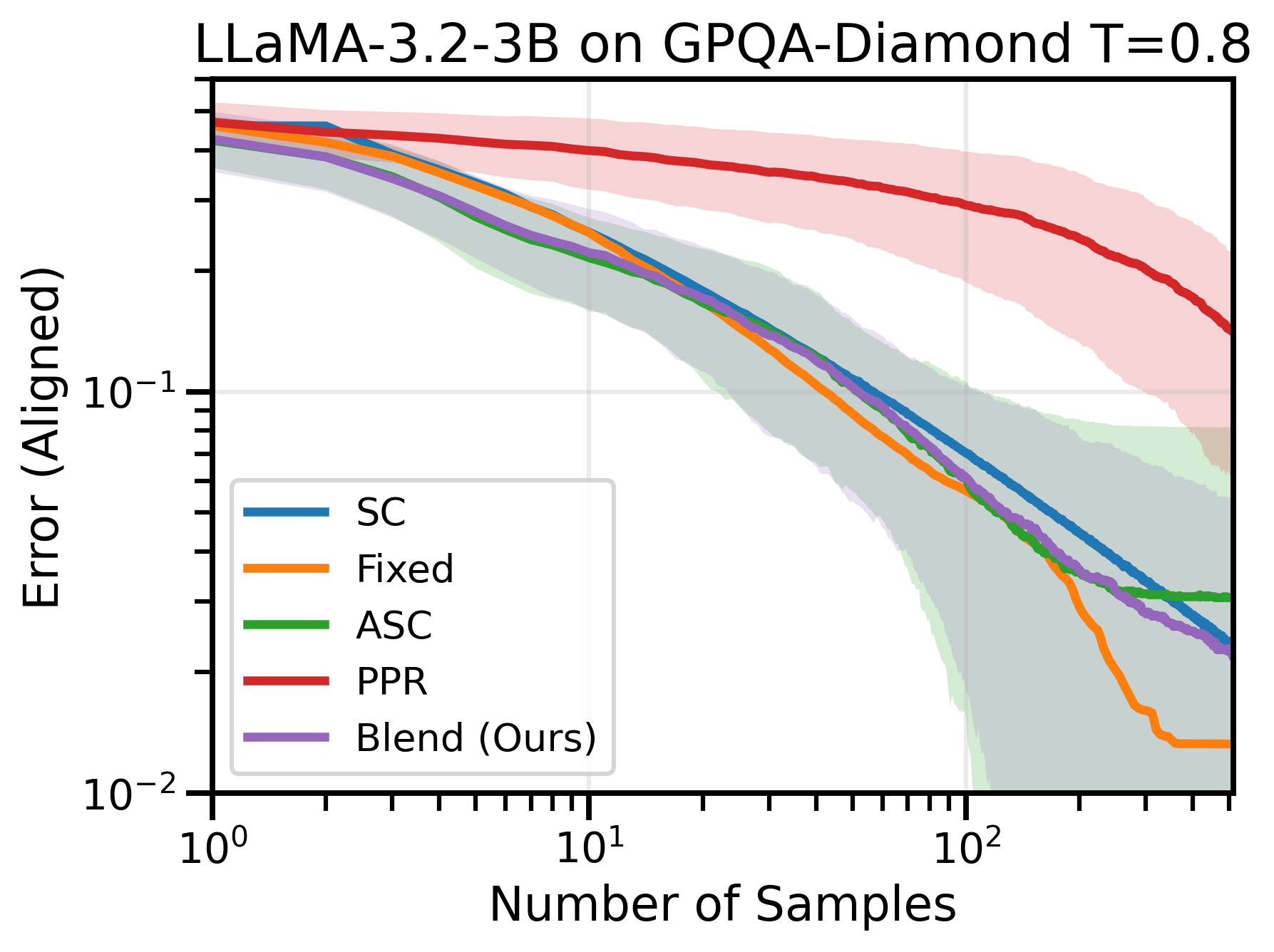
Figure 4: Across many datasets and model combinations, Blend-ASC consistently outperforms all methods in mode-estimation, achieving the lowest sample efficiency for target error.
Conclusion
By framing self-consistency through the lens of mode estimation and voting theory, this paper establishes theoretical guarantees for convergence and paves the way for efficient, large-scale use of SC. The introduction of Blend-ASC represents a significant stride towards optimizing the inference processes of LLMs, with potential applications extending far beyond the current study. Future work may explore extending these principles to other test-time inference methods and their applications in AI systems, enhancing both their theoretical and empirical efficacy.