- The paper presents RAGPulse as a high-fidelity workload trace dataset that captures real-world RAG request dynamics and performance bottlenecks.
- It leverages detailed analyses of temporal locality, skewed document access, and dynamic input compositions to inform caching and scheduling strategies.
- The study validates optimization techniques across both offline and online system architectures, effectively bridging academic insights with practical deployment.
RAGPulse: Optimizing RAG Serving Systems with Open-Source Workload Traces
Introduction to Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) enhances LLMs by integrating external knowledge bases to address challenges such as knowledge cutoff and hallucination. RAG systems utilize a multi-stage pipeline consisting of retrieval, augmentation, and generation phases. This workflow synergizes the reasoning capabilities of LLMs with the factual accuracy of external databases, significantly improving the reliability and timeliness of LLM applications.
Despite these advantages, existing generic LLM inference traces do not capture the unique workload characteristics of RAG systems, leading to performance gaps between academic research and real-world deployment. The introduction of RAGPulse aims to bridge this gap by providing an open-source RAG workload trace dataset, offering high-fidelity insights into the real-world dynamics of RAG workloads.
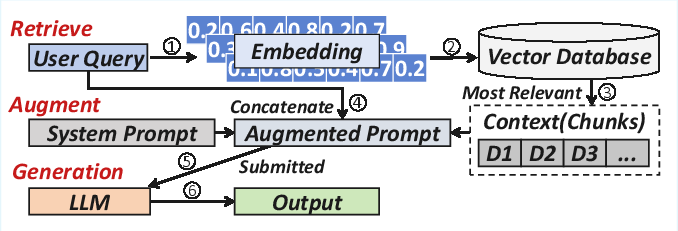
Figure 1: Workflow of RAG.
RAGPulse Dataset Overview
RAGPulse was compiled from a university-wide Q&A system that serves over 40,000 students and faculties. The dataset meticulously records system-level runtime information for various RAG requests, emphasizing temporal locality and skewed hot document access patterns.
Key Dataset Features
- Temporal Locality and Skewed Access Patterns: RAG workloads exhibit a highly skewed access pattern where a small subset of documents is frequently referenced, indicating significant potential for optimization through retrieval caching.
- Dynamic Input Composition: Inputs vary with request length, affecting the proportional contribution of components like system prompts and retrieved passages. This variability suggests heterogeneous processing overheads contingent on request type.
- Periodic Workload Fluctuations: Periodic peaks and troughs in system throughput are consistent with diurnal human activity patterns, providing critical insights for resource scheduling and load balancing.
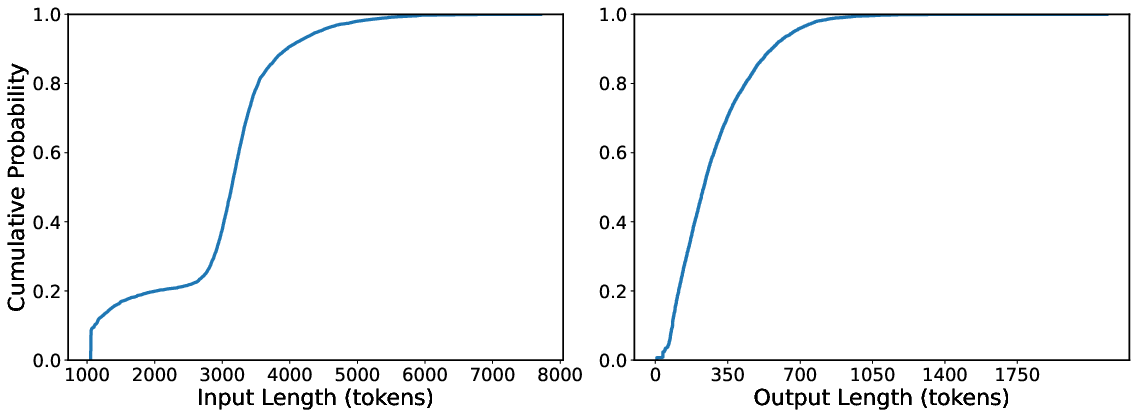
Figure 2: CDF of Input and Output Token Lengths in RAGPulse.
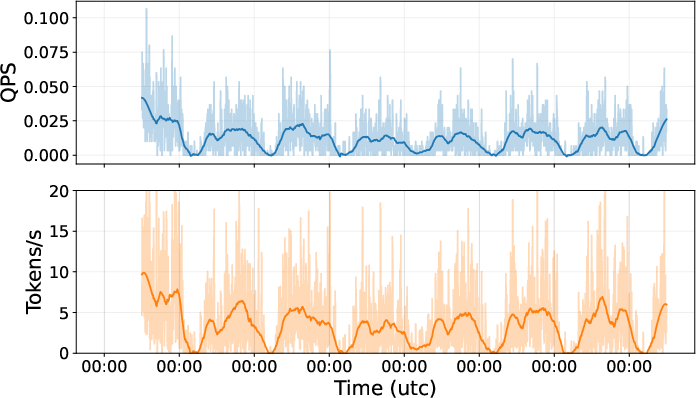
Figure 3: Throughput over time in RAGPulse.
Applications and Implications of RAGPulse
RAGPulse serves as a foundation for several optimization strategies in RAG systems:
- Precise Performance Bottleneck Analysis: Enables analysis of latency contributions across retrieval, reranking, and generation stages to identify bottlenecks.
- Informed Scheduling and Caching: Facilitates the design of sophisticated strategies such as content-aware batching and efficient KV cache reuse under real-world inter-request dependency patterns.
- High-Fidelity Benchmarking: Provides a validated basis for establishing realistic workload models, simulators, and benchmarks for academic and industrial research.
Given these capabilities, RAGPulse is a valuable resource for advancing both the theoretical understanding and practical deployment of RAG systems, empowering researchers to address contemporary challenges in LLM-serving environments.
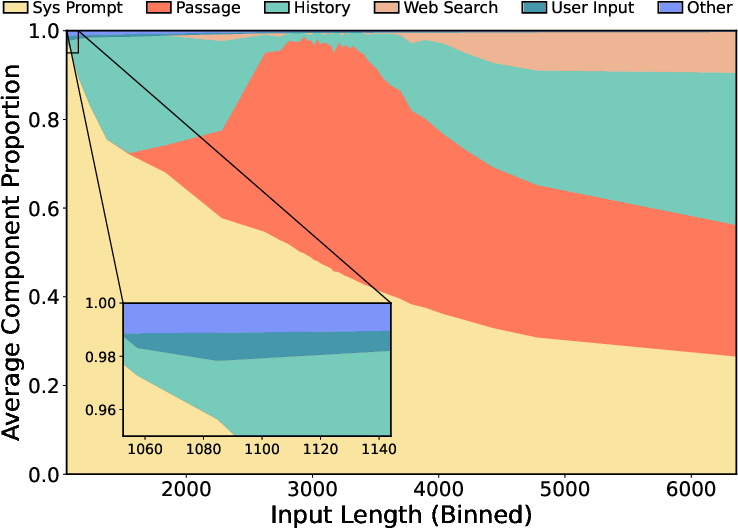
Figure 4: Proportion of Input Components Across Different Input Lengths in RAGPulse.
Twen System Architecture
The data for RAGPulse is derived from Twen, a comprehensive RAG system designed with a microservice architecture that separates retrieval and generation tasks. This architecture utilizes a vast suite of tools, including a high-performance LLM for agent interactions and a robust vector database for document indexing.
Offline and Online Stages
- Offline Stage: Involves constructing a high-quality vector knowledge base from multiple data sources, employing LLMs for tasks such as OCR and text normalization.
- Online Stage: Handles real-time user queries through an Agent LLM that dynamically orchestrates processing tools and generates the RAGPulse trace records.
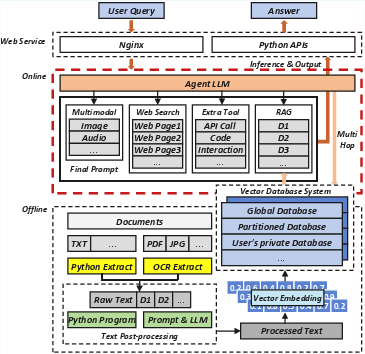
Figure 5: Twen's System Architecture.
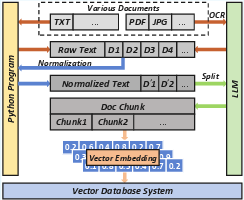
Figure 6: Offline Architecture in Twen.
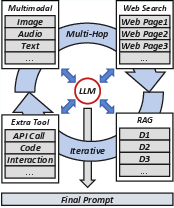
Figure 7: Online Architecture in Twen.
Conclusion
RAGPulse significantly contributes to closing the gap between academic RAG research and real-world implementations. By offering a comprehensive, high-fidelity snapshot of RAG-specific workload dynamics, RAGPulse paves the way for more efficient and reliable RAG serving systems. By embracing these insights, the research community can develop novel optimization techniques that address contemporary challenges in RAG systems, ultimately driving advancements in AI assisting technologies and LLM-serving infrastructures.

