- The paper classifies annotation bias into instruction, annotator, and contextual/cultural biases, demonstrating their impact on model fairness.
- It employs detection techniques such as inter-annotator agreement, model disagreement, and metadata analysis to uncover systematic biases.
- It proposes proactive and reactive mitigation strategies, emphasizing ethical practices and cultural inclusivity in multilingual LLM development.
Annotation Bias in Multilingual LLMs
Introduction
The paper "Bias in, Bias out: Annotation Bias in Multilingual LLMs" (2511.14662) explores the pervasive challenge of annotation bias within the field of multilingual LLMs. This bias stems from the distortions introduced during the data labeling process, which can significantly impact model performance, fairness, and generalization. In diverse cultural settings, annotation bias is compounded by task framing, annotator subjectivity, and cultural mismatches. This essay provides a comprehensive analysis of the paper's contributions and insights regarding the taxonomy of annotation bias, detection and mitigation strategies, and the broader implications for LLM development.
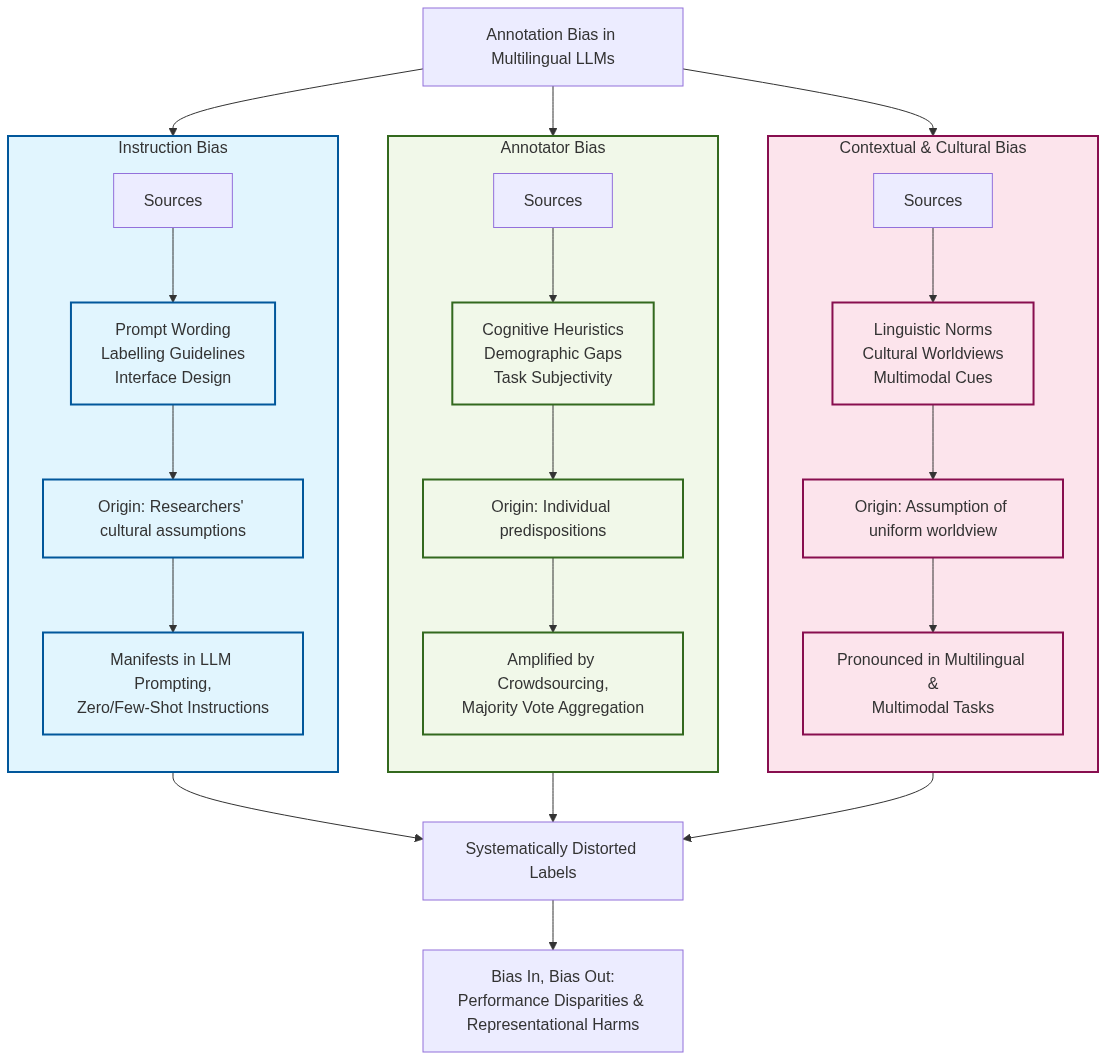
Figure 1: Taxonomy of annotation bias types observed in multilingual LLMs, showing three primary categories.
Types of Annotation Bias
The paper categorizes annotation bias into three primary types: Instruction Bias, Annotator Bias, and Contextual and Cultural Bias.
Instruction Bias arises when implicit assumptions within task design, prompts, or guidelines influence annotators' interpretations. This bias is prevalent in tasks like sentiment analysis, where cultural nuances are often overlooked.
Annotator Bias refers to biases stemming from annotators' individual or group predispositions, shaped by cognitive heuristics, demographic attributes, or social norms. This bias can skew results, especially in subjective tasks such as hate speech detection.
Contextual and Cultural Bias emerges from imposing a specific world view or linguistic norm across varied cultural settings, affecting multilingual and multimodal tasks that depend on region-specific expressions and interpretations.
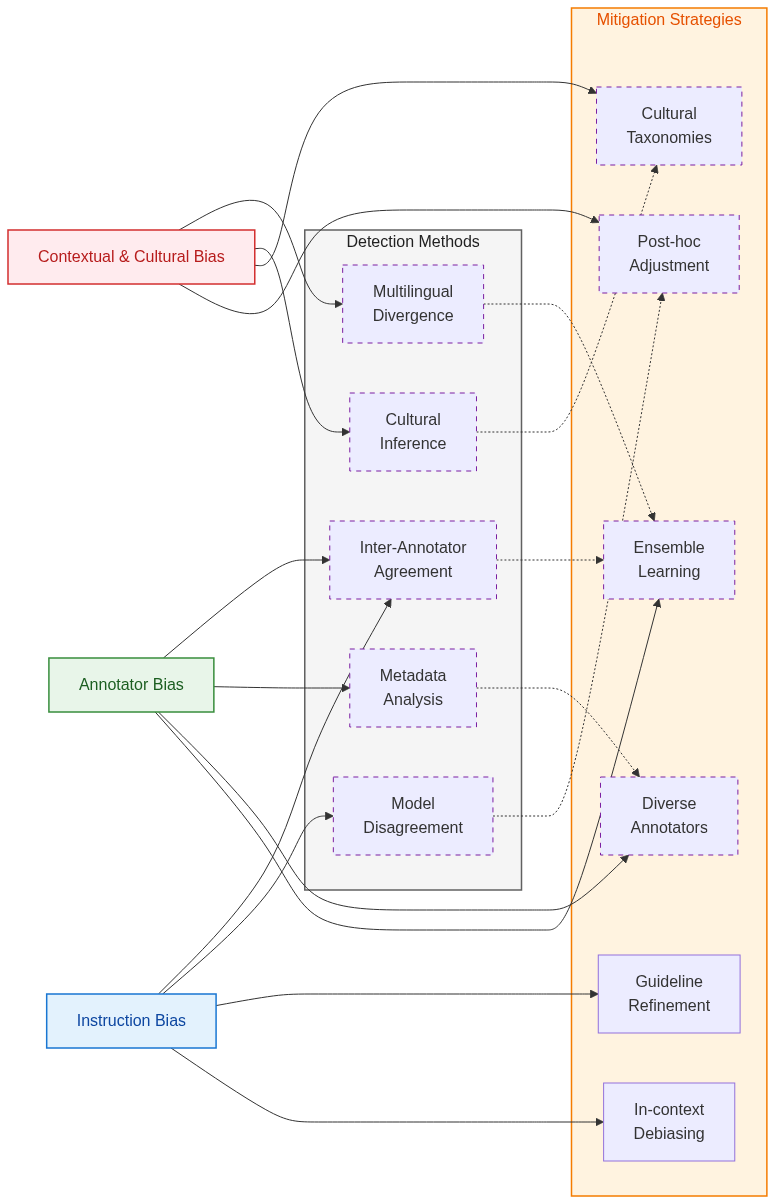
Figure 2: Relationships between annotation bias sources, detection methods, and mitigation strategies.
Detection and Mitigation Strategies
The paper outlines methods to detect annotation bias, including inter-annotator agreement, model disagreement, and metadata analysis. These techniques aim to identify systematic patterns of bias within annotated datasets.
Detection methods include:
- Inter-annotator agreement: Metrics like Cohen’s κ assess agreement levels between annotators.
- Model disagreement: Analyzing prediction divergences between models trained on the same data reveals annotation ambiguity.
- Metadata analysis: Examines annotator demographics and task contexts to uncover systematic bias.
Mitigation strategies are divided into proactive and reactive approaches:
- Proactive strategies: These involve diverse annotator recruitment, iterative guideline refinement, and culturally grounded taxonomies to prevent bias during data collection.
- Reactive strategies: These include post-hoc adjustments via embedding debiasing or ensemble learning to address bias after data annotation or model training.
Practical and Ethical Considerations
The paper also touches on the ethical aspects of annotation work, focusing on annotator well-being and the dynamics of crowdsourcing platforms. Annotators often work under stressful conditions, which can impact data quality and exacerbate biases. Ethical practices such as task rotation and mental health support are crucial to mitigate these effects.
Moreover, the power dynamics in crowdsourcing can lead to lower data quality and suppression of minority viewpoints. Promoting fair labor practices and recognizing annotators as skilled contributors can enhance data integrity and model reliability.
Conclusion
The exploration of annotation bias in multilingual LLMs underscores the need for balanced and ethical annotation practices that acknowledge cultural diversity and aim for fairness. By classifying biases, proposing detection methods, and suggesting mitigation strategies, the paper contributes valuable insights to improve the robustness and equity of NLP systems. Prospective advancements in AI should prioritize culturally inclusive benchmarks, enriched annotator metadata, and community-driven annotation processes. These steps are vital to foster LLMs that truly reflect the diverse experiences and knowledge inherent in human communication.
