Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Abstract: Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Walrus: A Cross-domain Foundation Model for Continuum Dynamics” in simple terms
Overview
This paper introduces Walrus, a powerful AI model that learns how things like fluids, gases, and waves move and change over time. Instead of using traditional physics equations (which can be very slow to compute), Walrus looks at a short “movie” of what’s happening and predicts the next frame. It’s designed to work across many kinds of physics—from weather-like flows to star explosions—making it a general tool scientists can use to speed up simulations.
What questions did the researchers want to answer?
They focused on three big questions:
- Can one model learn from many different kinds of physical systems (2D and 3D) and still make good predictions?
- How can we make AI predictions stable over long periods, instead of breaking down after a few steps?
- How can we train such a big model efficiently on modern hardware, even when the data looks very different across tasks?
How did they do it? (Methods explained simply)
The team combined smart design ideas to teach Walrus to handle complex, varied physics.
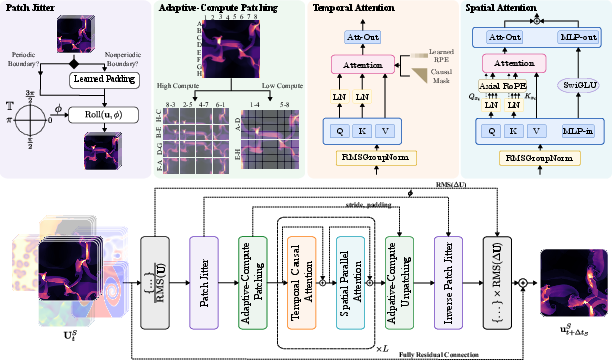
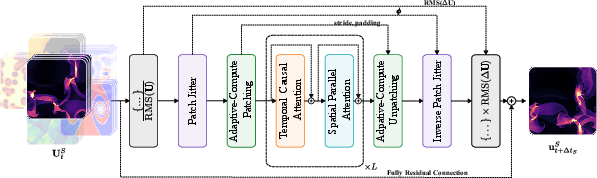
- A transformer that looks across space and time: Think of a transformer as a very attentive reader. Walrus reads a short sequence of snapshots (frames) of the physical system, paying attention to patterns both across the image (space) and across the frames (time). This helps it understand what’s happening and predict the next step.
- Learning from many types of physics at once: Walrus was trained on 19 different scenarios from areas like astrophysics, geoscience, acoustics, plasma, and fluid dynamics. It learned from both 2D and 3D data. For 2D data, they treated it like a thin slice inside a 3D space so the model could handle both in a unified way.
- Stabilizing predictions with “patch jittering”: When AI models break images into small patches to process them, they can accidentally create “checkerboard” artifacts (like weird grids) over time—similar to the patterns you sometimes see when resizing photos. Patch jittering means slightly shifting the patches randomly during training and then shifting the outputs back. This helps cancel out those grid artifacts and keeps long-term forecasts stable.
- Adaptive-compute tokenization (efficient compression): Different tasks have different sizes and complexities. Walrus can flexibly compress inputs more or less depending on the resolution, so that every task gives the model roughly the same amount of work. Think of it like adjusting video quality so all videos stream smoothly without lag.
- Efficient training across many GPUs: Training big models needs lots of GPUs working together. If one GPU gets a harder job than the others, the whole system slows down. The team grouped GPUs so each group handled similar workloads at the same time, and they balanced batch sizes for 2D vs. 3D data. This boosted training speed significantly.
- Predicting changes, not just the next frame: Instead of predicting the full next state directly, Walrus predicts the change from one step to the next. This often makes learning easier and more accurate. They also normalized inputs and outputs carefully so that very fast-changing fields don’t dominate the training.
What did they find, and why is it important?
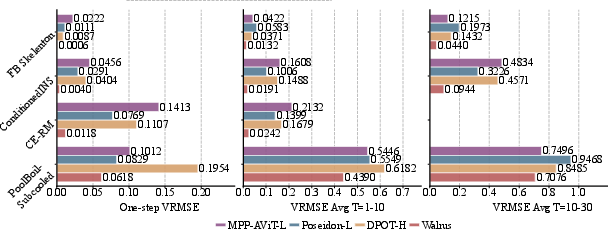
Walrus outperformed other strong models on many tasks:
- It beat prior foundation models on both single-step predictions (the very next frame) and multi-step rollouts (several frames into the future).
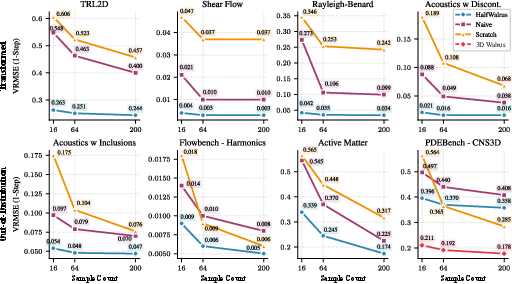
- Patch jittering improved long-term accuracy in 17 out of 19 training scenarios, cutting long-horizon errors by about half on average.
- Smart training strategies increased training throughput (speed) by about 262%, meaning the model learned much faster on the same hardware.
- Across a wide set of downstream tests, Walrus often reduced error by large margins (e.g., around 50–60% in many cases compared to strong baselines).
Why this matters:
- Traditional simulations can be extremely slow, especially for 3D problems (like star physics or complex fluid flows). Walrus can emulate these time-evolving systems faster, making it easier for scientists and engineers to explore ideas, test designs, and run many “what if?” scenarios.
- It works across different domains, so one model can help in multiple areas—like climate-related flows, sound waves, plasmas, and astrophysics.
What are the implications?
- Faster science and engineering: Walrus could make forecasting and design tasks much more efficient by replacing some expensive physics simulations with quick, high-quality predictions.
- Broader applicability: Because it’s trained on many types of physics, it’s a strong candidate for a general-purpose simulation assistant across disciplines.
- Open community use: The team has released code and model weights, so others can build on this work.
A simple but important caution:
- Even when an AI model looks good, scientists still need to check that its predictions match physical reality for the specific quantities they care about. The paper notes some limitations (e.g., certain boundary artifacts or sensitive physical measurements in extreme astrophysical cases). So Walrus is a big step forward, but it’s not a replacement for careful scientific validation.
Key takeaways
- Walrus is a cross-domain foundation model that predicts how continuous systems (like fluids, gases, waves) change over time.
- It uses stabilizing tricks (like patch jittering), adaptive compression, and clever training distribution to handle diverse data and stay stable over long forecasts.
- It outperforms previous models on many tasks and trains efficiently.
- It can help make simulations faster and more practical, but results still need scientific verification for high-stakes applications.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is framed to guide future research.
- Lack of theoretical guarantees for long-horizon stability: patch jittering is justified in expectation under periodic, bandlimited signals, but no convergence rates, bounds, or guarantees are provided for realistic settings with boundaries, nonlinearities, and finite samples.
- Applicability of patch jittering to non-periodic domains and complex boundaries is unclear; its impact with Dirichlet/Neumann walls, obstacles, curvilinear grids, and mixed BCs needs formal analysis and empirical validation.
- Unknown effects of patch jittering on conservation properties (mass, momentum, energy), positivity constraints, and incompressibility; no quantitative study of whether jittering introduces or suppresses physically spurious fluxes.
- No mechanism to enforce hard physical constraints during rollouts (e.g., divergence-free velocity fields, positivity of density/pressure, conservation of invariants); investigate constraint-aware architectures or training objectives.
- Evaluation relies primarily on VRMSE; missing domain-specific, physically grounded metrics (e.g., energy spectra and cascade rates, shock position/strength, vorticity statistics, divergence norms, mass/energy conservation error, radiative fluxes, neutrino luminosity) to assess physical fidelity.
- Uncertainty quantification is absent; no predictive distributions, calibration measures, or ensemble-based uncertainty to assess reliability under distribution shift or chaotic regimes.
- The model infers dynamics solely from short histories without conditioning on PDE coefficients, material properties, or boundary descriptors; future work should explore parameterized conditioning (structured fields, embeddings, or text) for controllability and generalization across parameter sweeps.
- Tokenization and compression via CSM lack an explicit selection policy; there is no auto-tuning or decision criterion that trades accuracy vs. compute across resolutions/aspect ratios—develop adaptive policies (e.g., learned controllers) and evaluate their effect on accuracy and throughput.
- Limited analysis of zero-shot cross-resolution and aspect ratio transfer; quantify how performance changes when resolutions or domain sizes differ from pretraining, including systematic scaling-law studies with tokens per axis and context length.
- Combined 2D–3D training treats 2D data as thin planes in 3D, but there is no ablation on whether this embedding helps or harms 3D generalization and whether more principled cross-dimensional co-learning strategies would perform better.
- Geometry and mesh limitations: the approach assumes Euclidean grids; capabilities on unstructured meshes, adaptive mesh refinement (AMR), non-Cartesian coordinates, and complex metric tensors are not supported or benchmarked—investigate graph/mesh operators or coordinate-aware attention.
- Boundary-awareness is implicit and augmentation-limited; there is no architecture-level mechanism for explicit boundary handling (masked attention, boundary tokens, coordinate encodings) or for enforcing boundary conditions during decoding.
- Time-stride sampling (1–5) is introduced, but the model lacks explicit time-unit or dt embeddings; study robustness to heterogeneous time steps, miscalibrated dt, and variable sampling rates across datasets and tasks.
- Long-horizon reliability beyond 60 steps (especially for chaotic systems) remains uncertain; explore multi-step training, scheduled sampling, integrator-inspired constraints (e.g., symplectic or projection methods), and stabilization beyond aliasing mitigation.
- Cross-domain generalization breadth is still limited by pretraining coverage (19 scenarios, 63 fields); identify physics domains underrepresented or missing (e.g., reactive flows, phase change with complex thermodynamics, multi-phase with surface tension, granular flows, strong radiation–hydrodynamics coupling) and evaluate generalization to unseen PDE families.
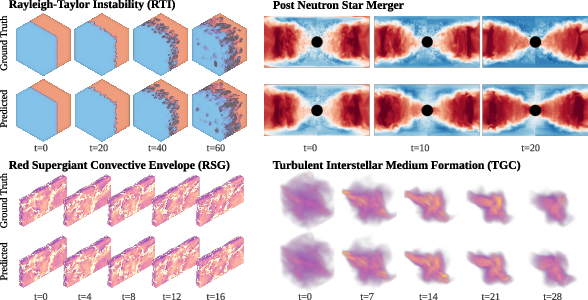
- Scientific validation for frontier 3D systems is incomplete: reported artifacts in RSG and incorrect heavy-element yields in PNS highlight gaps; define and optimize against domain-specific targets (e.g., nucleosynthesis rates, shock morphology, convective statistics) and integrate physics-informed priors or constraints.
- No comparative speed or cost analysis against numerical solvers; measure end-to-end inference speedups, energy/carbon cost, and accuracy–compute trade-offs versus HPC baselines to justify emulator deployment.
- Inference-time resource footprint and scalability are not quantified (e.g., GPU memory/latency for large 3D domains); develop and report quantization, low-precision, or sparse attention strategies for practical deployment.
- Effects of tensor-law aware augmentations in presence of anisotropic physics (gravity, rotation, magnetic fields) are not studied; evaluate whether rotation/reflection augmentations degrade performance when a preferred direction or field breaks isotropy.
- Missing analysis of learned representations and interpretability (attention patterns, spectral content, multiscale features, alias suppression); provide diagnostics linking architectural choices to physical behavior across domains.
- Dataset bias and heterogeneity handling: uniform sampling with local normalization may underweight fast-changing fields; study alternative sampling/loss reweighting schemes that align with physical predictability and domain importance.
- Field-set variability: sub-selected projections allow varying numbers of fields across datasets, but there is no assessment of semantic consistency, failure modes when critical fields are missing, or methods for field mapping between domains.
- Robustness to noisy, partial, or sparse observations is not evaluated; explore data assimilation, sensor fusion, and masked input settings representative of real experiments/observations.
- Topology-aware sampling improves throughput, but there is no general recipe for optimal grouping under different cluster/network topologies; formalize and benchmark distribution policies across hardware configurations.
- Fairness and completeness of baselines: while strong models are compared, other competitive architectures (e.g., mesh-based transformers, PDE-Transformers) are not included; ensure fair pretraining budgets, identical finetuning procedures, and broader baseline coverage.
- Safety and reliability under deployment are not addressed; define failure detection, guardrails for physically implausible outputs, and monitoring for drift when applied to operational forecasting or design optimization.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the released Walrus code/weights and the paper’s methods (patch jittering, adaptive-compute tokenization, 2D→3D augmentation, topology-aware sampling). Each item includes sector links, potential tools/products/workflows, and feasibility notes.
- High-throughput surrogate modeling for engineering design loops
- Sectors: aerospace (airfoil, external aerodynamics), automotive (HVAC ducting, thermal management), energy (combustion chambers, heat exchangers), manufacturing (inkjet/extrusion flows), microfluidics.
- What to deploy: “Walrus-as-a-Service” emulator microservice that ingests short state histories and returns next-step predictions for multi-step rollouts; integration adapters to common solvers (OpenFOAM, COMSOL, ANSYS) to pre-screen candidate designs and prune expensive solver runs.
- Methods used: space-time transformer for multi-step emulation; patch jittering for rollout stability; adaptive-compute tokenization (CSM) to support variable resolutions and aspect ratios.
- Assumptions/dependencies: task-specific finetuning data and boundary-condition alignment; validation against high-fidelity solvers; acceptance criteria set by engineering QA; GPU inference capacity sized to grid resolution.
- Scientific HPC “triage” and parameter-sweep acceleration
- Sectors: astrophysics (post-merger neutron star, red supergiant convection), plasma physics (MHD), geoscience (turbulence–radiative layers).
- What to deploy: a pre-screening pipeline that uses Walrus rollouts to explore parameters, select promising regions, and schedule a small fraction for full HPC simulation; integration into batch schedulers and lab workflows.
- Methods used: autoregressive forecasting across diverse PDE regimes; load-balanced multi-GPU finetuning to adapt Walrus to lab datasets; asymmetric input/output normalization for stable Δ-state prediction.
- Assumptions/dependencies: Walrus is not a drop-in replacement for production-grade results—use for exploration, not final physics claims; domain calibration and diagnostic checks (e.g., conservation diagnostics) are required.
- Fast geoscience scenario evaluation (meso-scale/coastal)
- Sectors: emergency management, urban planning, insurance risk modeling.
- What to deploy: dashboards for rapid shallow-water and radiation-layer “what-if” scenarios (e.g., storm surge, inundation, plume spread) with GIS overlays; batch rollout APIs for ensemble scenarios at variable time strides.
- Methods used: variable time-striding to work across datasets; adaptive tokenization for heterogeneous resolutions; 2D→3D augmentation to unify pipelines.
- Assumptions/dependencies: conservative use for planning and triage; rigorous local validation; careful handling of boundaries/material properties; governance requirements for public-facing decisions.
- Real-time and offline architectural acoustics
- Sectors: AEC (architecture/engineering/construction), VR/AR, pro audio.
- What to deploy: Walrus-based acoustic solvers for early-stage room design, interactive VR audio previews, and rapid inclusion/maze scattering studies; plugins for Unity/Unreal and CAD/BIM tools.
- Methods used: strong performance on linear wave propagation tasks; jittering to reduce grid artifacts; efficient tokenization for large scenes.
- Assumptions/dependencies: material parameter calibration; quality meshes for complex rooms; use offline for final numbers when certification standards apply.
- Training efficiency for multi-task, heterogeneous data
- Sectors: ML platform teams, foundation model builders.
- What to deploy: topology-aware sampling and token-count balancing in FSDP that force same-resolution sampling per sharding group, reducing communication stalls; adopt CSM-based adaptive tokenization to maintain steady token budgets across tasks.
- Methods used: topology-aware sampling (262% throughput gain); CSM encoder/decoder; differential batch sizing for 2D vs 3D.
- Assumptions/dependencies: access to distributed training infrastructure; careful dataset cataloging by resolution/dimensionality; compatibility with current PyTorch FSDP/HSDP setups.
- Stabilization of ViT-style generative pipelines via patch jittering
- Sectors: computer vision, video generation, medical imaging reconstruction, weather nowcasting.
- What to deploy: a drop-in “patch jittering” module around strided conv/transpose-conv tokenizers to suppress aliasing/grid artifacts and improve long-horizon stability.
- Methods used: harmonic-analysis argument for translation-induced averaging out of alias frequency contributions; empirical reduction of long-term error in 89% of scenarios.
- Assumptions/dependencies: benefit strongest when resampling artifacts dominate; evaluate distribution shifts and boundary conditions; may require minor retraining for best effect.
- Education and outreach: interactive PDE/continuum labs
- Sectors: education, science communication.
- What to deploy: Jupyter-based teaching kits that let students roll out phenomena (e.g., Rayleigh–Bénard convection, Gray–Scott reaction–diffusion, shear flows) at interactive speeds using the released Walrus weights.
- Methods used: cross-domain pretrained model; lightweight finetuning pathways to adapt to course-specific examples.
- Assumptions/dependencies: position Walrus as illustrative—not authoritative—physics; include cautionary notes on validation and physical constraints.
- Rapid, policy-oriented decision support (low-stakes, fast-turn)
- Sectors: public health ventilation planning, urban noise mapping, preliminary flood overlays.
- What to deploy: municipal “simulation desk” for quick scenario prototyping, backed by Walrus; templates for report generation with uncertainty annotations.
- Methods used: adaptive tokenization to fit municipal grid data; short rollout windows for decision triage.
- Assumptions/dependencies: not a substitute for certified engineering analysis; transparency about limits and validation status; alignment with agency QA processes.
Long-Term Applications
The following applications require further research, scaling, domain integration, or validation before responsible deployment.
- General-purpose multi-physics digital twins
- Sectors: factories/plants, smart cities/campuses, energy systems.
- What could emerge: unified, sensor-driven digital twins that couple fluids, acoustics, thermal, and plasma subsystems for monitoring, predictive maintenance, and scenario testing.
- Methods leveraged: cross-domain pretraining; compute-adaptive tokenization; 2D/3D unification; autoregressive rollouts.
- Assumptions/dependencies: robust co-simulation and coupling strategies; conservation laws and stability guarantees; integration with real-time data streams; safety and governance frameworks.
- Closed-loop, real-time control of complex flows
- Sectors: aerospace (turbulence suppression), energy (combustion stabilization), process engineering (mixing control), wind farms (wake steering).
- What could emerge: model predictive control (MPC) stacks using Walrus as the fast dynamics emulator for feedback control.
- Methods leveraged: fast, stable rollouts; patch jittering; short-context forecasting for control horizons.
- Assumptions/dependencies: reliable physical fidelity in the control-relevant bandwidth; robust uncertainty quantification (UQ); safety certification; hardware acceleration and latency guarantees.
- Patient-specific clinical CFD
- Sectors: healthcare (cardiovascular flow, airway dynamics).
- What could emerge: pre-operative planning emulators for hemodynamics and respiration; rapid scenario testing under varied physiological parameters.
- Methods leveraged: finetuning on clinical meshes and flows; adaptive tokenization for variable resolution anatomies.
- Assumptions/dependencies: curated, high-quality clinical datasets; stringent validation against gold-standard solvers; regulatory approval; bias and safety assessments.
- Fusion reactor operations and plasma event forecasting
- Sectors: energy (fusion R&D and operations).
- What could emerge: fast surrogates for tokamak edge-localized modes (ELMs) and MHD instabilities to assist operator decisions and control strategies.
- Methods leveraged: Walrus’s MHD pretraining and 3D forecasting; topology-aware training for large grids.
- Assumptions/dependencies: domain-specific data from reactors; extreme-fidelity requirements; integration into control rooms with UQ and human-in-the-loop checks.
- Generative design and optimization of advanced materials and devices
- Sectors: materials (metamaterials, acoustic cloaks), mechanical (structural vibration control), combustion systems.
- What could emerge: surrogate-guided design loops combining Walrus with Bayesian optimization/evolutionary algorithms to search large design spaces.
- Methods leveraged: stable multi-step emulation; variable time-striding; 2D→3D augmentation for cross-scale exploration.
- Assumptions/dependencies: differentiability or surrogate-aware optimization; multi-fidelity validation; manufacturability constraints.
- Accelerated ensembles for climate and environmental risk
- Sectors: climate science, catastrophe modeling, insurance.
- What could emerge: large ensemble runs (shallow-water, radiation layers, mesoscale phenomena) powered by emulators for scenario diversity and speed.
- Methods leveraged: adaptive tokenization across resolutions; transferable operators across regimes; topology-aware sampling for training large ensembles.
- Assumptions/dependencies: strong generalization across regimes; enforcement of conservation laws; careful treatment of chaotic divergence at long horizons; community validation campaigns.
- Standardized adaptive-compute training stacks
- Sectors: ML tooling and infrastructure.
- What could emerge: reference libraries that package CSM, patch jittering, asymmetric normalization, and topology-aware sampling for heterogeneous, multi-domain foundation models.
- Methods leveraged: the paper’s training-engineering innovations generalized beyond physics tasks.
- Assumptions/dependencies: adoption by ML frameworks; compatibility with emerging attention variants; best-practice playbooks for heterogeneous corpora.
- Scientific discovery from learned representations
- Sectors: academia (physics, applied math).
- What could emerge: using Walrus embeddings and behavior to infer latent symmetries, constitutive relations, or regimes; coupling with symbolic regression to hypothesize governing structures.
- Methods leveraged: cross-domain feature learning; multi-physics transfer; controllable augmentations respecting tensor laws.
- Assumptions/dependencies: interpretability tooling; rigorous hypothesis testing; collaboration between ML and domain scientists; careful handling of spurious correlations.
Cross-cutting feasibility notes
- Data availability and quality: Reliable finetuning requires well-curated, domain-matched datasets with correct boundary conditions and material properties.
- Physical correctness and validation: For high-stakes uses, incorporate conservation diagnostics, error bounds, and calibration against numerical solvers; Walrus is best positioned today for exploration, triage, and acceleration rather than definitive results.
- Compute and deployment: 3D inference is memory-intensive; plan GPU provisioning and consider tiling or multi-fidelity strategies.
- Governance and safety: Establish guidelines for where emulators are appropriate, documentation of limitations, and human-in-the-loop review for policy or clinical contexts.
- Method choice: While Walrus is strong across many regimes, Fourier-operator-based models (e.g., AFNO) may outperform on strictly linear, smooth wave problems—tool selection should be regime-aware.
Glossary
- Adaptive-compute Tokenization: A method that allocates computational resources dynamically based on input resolution or problem complexity to improve efficiency. "Adaptive-compute Tokenization: integrating recent adaptive-compute tokenization methods to allocate compute dynamically based on resolution or problem complexity."
- AFNO (Adaptive Fourier Neural Operator): A neural operator architecture that performs computations in the frequency domain to model PDE dynamics efficiently. "DPOT, which utilizes the frequency domain-based AFNO \citep{guibas2022adaptivefourierneuraloperators} block as its core component, is most competitive to Walrus\ in the acoustics and linear wave propagation category."
- Aliasing: A signal processing artifact where high-frequency components are misrepresented at lower frequencies due to insufficient sampling. "Several studies have identified aliasing as one of the major contributors to the autoregressive instability \citep{raoniÄ2023convolutional, mccabe2023towards}."
- AllGather: A synchronous collective communication operation that gathers data from all processes in a group and distributes the combined result to each process. "PyTorch's FSDP utilizes synchronous collective communication primitives such as AllGather during the forward pass itself."
- AllReduce: A collective communication primitive that reduces values (e.g., sums) across processes and broadcasts the result to all processes. "averaging over multiple micro-batches between AllReduce operations prior to parameter updates"
- Asymmetric Input/Output Normalization: A normalization strategy where inputs and outputs are normalized differently to account for distinct distributions. "Asymmetric Input/Output Normalization."
- Axial RoPE: Rotary positional embeddings applied along specific axes (e.g., spatial axes) to encode relative positions efficiently. "using axial RoPE \citep{su2023roformerenhancedtransformerrotary, lu2023unifiedio2scalingautoregressive_axialrope, lu2024fitflexiblevisiontransformer_axialrope} for position encoding."
- Bandlimited signal: A signal whose Fourier transform has zero magnitude above a certain frequency, allowing perfect reconstruction from samples if sampled sufficiently. "We assume that is a bandlimited signal such that ."
- Cauchy integral theorem: A complex analysis result stating that the integral of a holomorphic function over a closed contour is zero, used to show expected alias cancellation. "is a contour integral around the complex unit circle and therefore evaluates to zero by the Cauchy integral theorem."
- Causal attention: An attention mechanism that restricts access to future tokens, ensuring autoregressive consistency over time. "Along the time axis, Walrus\ uses causal attention with T5-style relative position encoding \citep{raffel2020exploring}."
- Compute-Adaptive Compression: A technique that adapts the degree of spatial downsampling/upsampling based on compute and resolution constraints. "Compute-Adaptive Compression."
- Constitutive models: Relations defining material behavior (e.g., stress-strain laws) used in physics-based simulations. "known parameters (PDE coefficients, explicit constitutive models, etc)"
- Convolutional Stride Modulation (CSM): A method that modulates convolution strides to control compression and token counts adaptively across resolutions. "We utilize Convolutional Stride Modulation \citep[CSM]{payelpaper_mukhopadhyay2025controllablepatchingcomputeadaptivesurrogate} in our encoder and decoder modules to natively handle data at varying resolutions by adapting the level of downsampling/upsampling in each encoder/decoder block."
- Continuum dynamics: The study of systems modeled as continuous fields (e.g., fluids, plasmas) evolving over space and time. "Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics."
- Discrete Fourier transform: A transformation that converts discrete signal samples into their frequency components. "We denote the discrete Fourier transform of each of these signals by which we index with ."
- Equivariance (under symmetry transforms): A property where model outputs transform predictably under symmetry operations applied to inputs. "Aliasing can lead to spectral artifacts and a loss of equivariance under symmetry transforms \citep{Karras2021}."
- Euler quadrants problem: A classical test problem in inviscid fluid dynamics involving discontinuous initial conditions across quadrants. "the MultiQuadrantsP task which is a generalization of the classical Euler quadrants problem \citep{euler_quadrants} with periodic boundary conditions."
- Fourier expansion: Representation of a signal as a sum of sine and cosine (complex exponentials) at different frequencies. "we can therefore represent exactly by its Fourier expansion "
- Fourier shift property: A property where shifting a signal in the time/space domain corresponds to a phase multiplication in the frequency domain. "Exploiting the Fourier shift property "
- FSDP (Fully Sharded Data Parallel): A distributed training technique that shards model parameters across devices to reduce memory and improve scalability. "PyTorch's FSDP utilizes synchronous collective communication primitives such as AllGather during the forward pass itself."
- Gradient accumulation: A training technique that accumulates gradients over multiple micro-batches before an optimizer step to emulate larger effective batch sizes. "Combining this with the gradient accumulation as randomized load balancing trick used in \cite{mccabe2023multiple}, we have a system where the groups of nodes where AllGather operations act as a bottleneck are forced to sample data of the same resolution and dimensionality..."
- GroupNorm: A normalization method that normalizes over groups of channels, improving stability in certain architectures. "This is GroupNorm \citep{wu2018groupnormalization} implemented as RMSNorm \citep{zhang2019rootmeansquarelayer} over each group."
- Harmonic analysis: The field studying functions via decomposition into basic waves (Fourier-like methods), used here to analyze and mitigate aliasing. "including a harmonic-analysisâbased stabilization method, load-balanced distributed 2D-3D training strategies, and compute-adaptive tokenization."
- Hierachical MLP (hMLP): A multi-layer perceptron structured in hierarchical blocks to efficiently process spatial tensors. "We use an Hierachical MLP (hMLP) and transposed hMLP for lightweight encoding and decoding \citep{Touvron2022ThreeTE}"
- In-context learning: The ability of a model to infer tasks from prompts/examples without explicit parameter updates. "which utilized in-context learning \citep{ICL_brown2020} for prediction in ODEs and 1D PDEs"
- Inviscid fluids: Fluids modeled without viscosity, governed by Euler equations, highlighting shock and wave phenomena. "On the other hand, Poseidon is particularly competitive on inviscid fluids, particularly the MultiQuadrantsP task..."
- Magnetohydrodynamics (MHD): The study of electrically conducting fluids (e.g., plasmas) and their interaction with magnetic fields. "MHD (3D)"
- Octahedral group: The symmetry group of the cube, consisting of 90° rotations and reflections; used for data augmentation. "Euclidean data is then augmented by the application of tensor-law aware transformations. Here this is limited to the full octahedral group of rotations and reflections..."
- Patch jittering: Random spatial shifts of inputs and inverse shifts of outputs during training to reduce alias-induced artifacts and improve stability. "Patch jittering: a lightweight procedure to improve the stability of autoregressive rollouts which we derive from harmonic analysis and find to reduce long-horizon error in 89\% of the pretraining scenarios."
- Periodic boundary conditions: Boundary conditions where the domain wraps around, causing values at one boundary to match the opposite boundary. "the MultiQuadrantsP task which is a generalization of the classical Euler quadrants problem \citep{euler_quadrants} with periodic boundary conditions."
- QK normalization: Normalization applied to Query-Key pairs in attention to stabilize training and improve scalability. "QK normalization \citep{dehghani2023scaling} is used in both space and time blocks to improve training stability."
- Rayleigh–Bénard convection: A fluid dynamics phenomenon of convection driven by temperature gradients across a fluid layer. "Rayleigh-Benard"
- Rayleigh–Taylor instability: An instability occurring when a dense fluid is accelerated into a lighter fluid, producing complex interpenetration. "Rayleigh-Taylor Instability (3D)"
- Rheology: The study of flow and deformation of matter, particularly non-Newtonian fluids. "spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids."
- RMS GroupNorm: A variant of GroupNorm that uses RMS (root mean square) normalization within groups for stability. "Walrus\ employs RMSGroupNorm as the standard normalization approach within each transformer block."
- RMSNorm: A normalization technique using the root mean square of activations, avoiding dependence on mean and variance estimates. "This is GroupNorm \citep{wu2018groupnormalization} implemented as RMSNorm \citep{zhang2019rootmeansquarelayer} over each group."
- Rotary positional embeddings (RoPE): A positional encoding scheme that introduces sinusoidal rotations to queries and keys for better extrapolation. "using axial RoPE \citep{su2023roformerenhancedtransformerrotary, lu2023unifiedio2scalingautoregressive_axialrope, lu2024fitflexiblevisiontransformer_axialrope} for position encoding."
- Shannon–Nyquist sampling theorem: The principle that a bandlimited signal can be perfectly reconstructed if sampled at twice its highest frequency. "By the Shannon-Nyquist sampling theorem, we can therefore represent exactly by its Fourier expansion..."
- Strided convolution: A convolution operation that subsamples the input by using strides greater than one, reducing spatial resolution. "ViT-style architectures employing symmetric patchification or equivalently strided convolution and transposed convolutions for tokenization/reconstruction"
- Tensor transformation laws: Rules that dictate how tensor components change under rotations and reflections to preserve physical consistency. "When we transform the reference frame, tensor-valued fields must be similarly transformed following tensor transformation laws to preserve physical consistency."
- Topology-aware Sampling: A training sampling strategy that accounts for hardware topology (e.g., sharding groups) to balance workloads and improve throughput. "Topology-aware Sampling: increasing training throughput by 262\% by tying sampling scheme across ranks to minimize task variance within sharding groups."
- Transposed convolution: An operation that upsamples feature maps, often used for reconstruction, which can introduce aliasing artifacts if not handled carefully. "or equivalently strided convolution and transposed convolutions for tokenization/reconstruction"
- T5-style relative position encoding: A positional encoding approach from T5 that represents positions relative to each other, aiding generalization. "Along the time axis, Walrus\ uses causal attention with T5-style relative position encoding \citep{raffel2020exploring}."
- VRMSE (Variance-normalized RMSE): A loss/metric that normalizes RMSE by variance (or RMS) to enable cross-dataset comparisons. "We primarily use VRMSE as in the Well benchmark \citep{ohana2025welllargescalecollectiondiverse} either per-step or averaged over rollout windows for comparison as the normalization allows for easier cross-dataset comparison in limited space."
Collections
Sign up for free to add this paper to one or more collections.