Physics Steering: Causal Control of Cross-Domain Concepts in a Physics Foundation Model
Abstract: Recent advances in mechanistic interpretability have revealed that LLMs develop internal representations corresponding not only to concrete entities but also distinct, human-understandable abstract concepts and behaviour. Moreover, these hidden features can be directly manipulated to steer model behaviour. However, it remains an open question whether this phenomenon is unique to models trained on inherently structured data (ie. language, images) or if it is a general property of foundation models. In this work, we investigate the internal representations of a large physics-focused foundation model. Inspired by recent work identifying single directions in activation space for complex behaviours in LLMs, we extract activation vectors from the model during forward passes over simulation datasets for different physical regimes. We then compute "delta" representations between the two regimes. These delta tensors act as concept directions in activation space, encoding specific physical features. By injecting these concept directions back into the model during inference, we can steer its predictions, demonstrating causal control over physical behaviours, such as inducing or removing some particular physical feature from a simulation. These results suggest that scientific foundation models learn generalised representations of physical principles. They do not merely rely on superficial correlations and patterns in the simulations. Our findings open new avenues for understanding and controlling scientific foundation models and has implications for AI-enabled scientific discovery.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores a new way to understand and control a large AI model that predicts how physical systems change over time (like fluid flow or chemical reactions). The authors show that inside the model, there are “hidden directions” that represent understandable physics ideas—such as swirling motion (vortices), diffusion (spreading), and speed (how quickly things evolve). By nudging the model along these directions, they can make the model add or remove these physical features on purpose.
Key Questions
The paper asks simple but important questions:
- Do big AI models trained on physics learn real, general physical concepts, not just patterns in data?
- Can we find those concepts inside the model?
- If we find them, can we “steer” the model to create or remove those physical features in its predictions?
- Do these learned concepts transfer to different kinds of physics, not just the one they were found in?
How Did They Do It?
Think of the AI model (called Walrus) as a very smart simulator trained on a huge library of physics “videos” (The Well). Inside the model, there are layers that produce internal signals—like the model’s “thoughts” while it makes predictions. The authors use four simple steps:
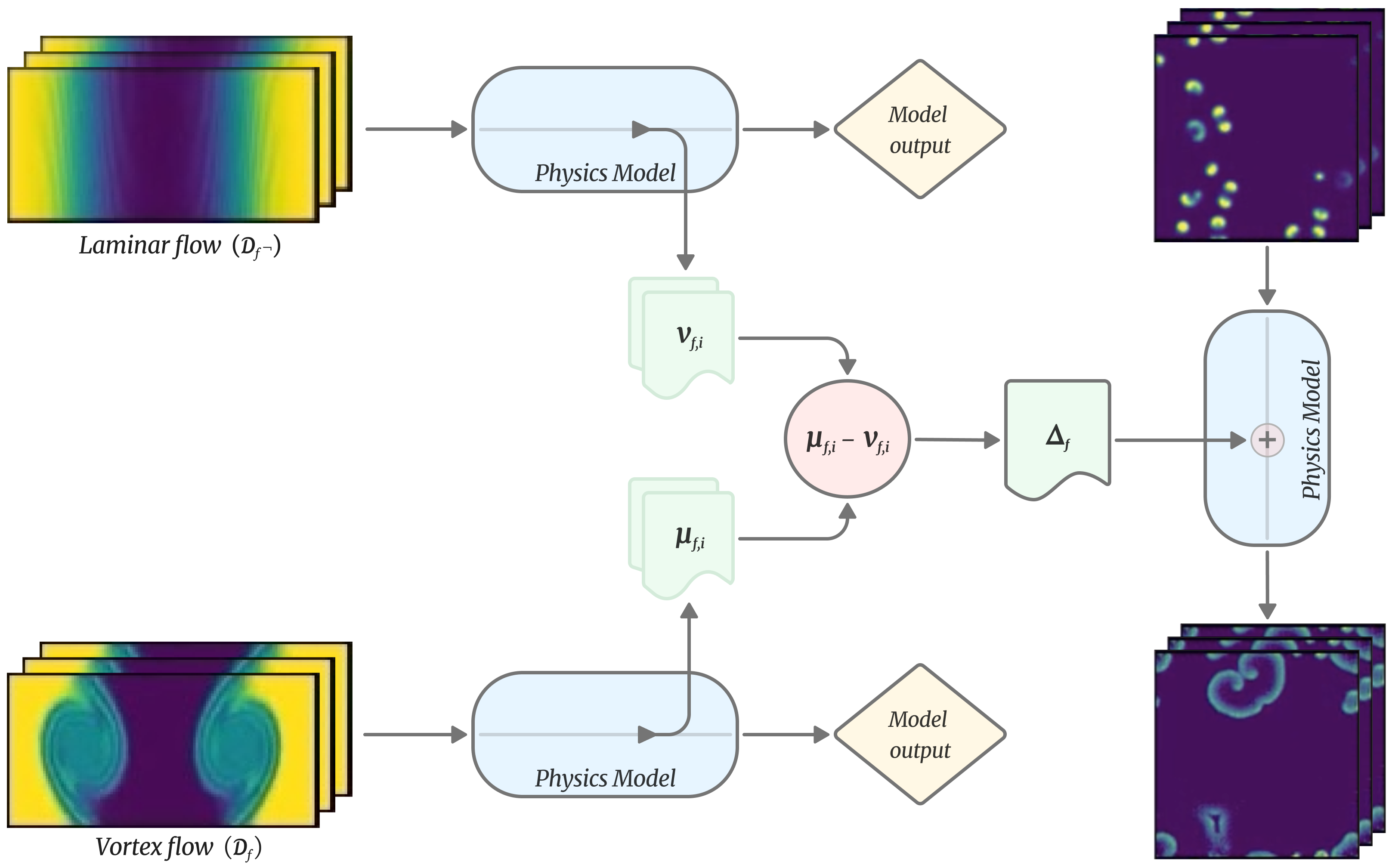
1) Pick two versions of the same kind of simulation
They choose groups of simulations that differ by one clear feature. For example, in shear flow (a type of fluid motion), one group has strong swirling vortices, and the other is smooth and straight (laminar).
2) Record the model’s internal signals
As the model watches each group, they save the layer’s “activation” (its internal state). Imagine listening in on the model’s “brainwaves” while it watches swirling vs. non-swirling flows.
3) Subtract to find a “concept direction”
They average the activations for “with feature” and “without feature,” then subtract them. The result is a single “direction” in the model’s hidden space that points toward the concept—like a compass direction for “vortex.” This is called a “delta” or “concept vector.”
- Analogy: If you average pictures of cats and average pictures of dogs, then subtract, the difference highlights “cat-ness” vs. “dog-ness.” Here, it highlights “vortex-ness” vs. “no vortex.”
4) Gently push the model along that direction
During prediction, they add a scaled amount of the concept vector back into the model’s layer (like turning up or down a slider). If the concept is real and causal, the output should change in a way that matches the concept: turning up “vortex” should produce more swirling; turning it down should smooth it out.
To transfer these concepts across different systems (which might have different sizes or layouts), they use an averaged version of the concept that only keeps the “channel” information (like color channels in an image) but ignores exact positions. This helps the concept work across domains.
What Did They Find?
The authors ran several experiments, and the results were surprisingly strong and easy to see.
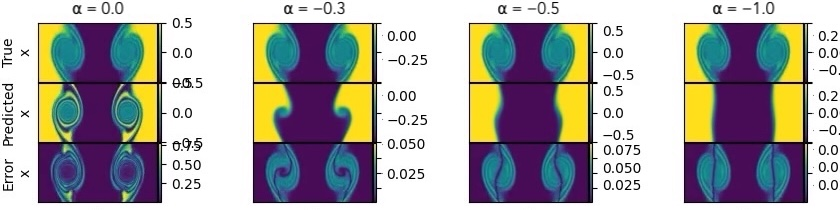
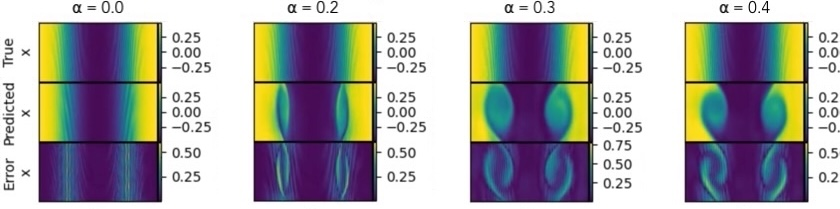
- Vortex control in shear flow:
- Turning the “vortex” slider down removed swirls and made the flow smooth (laminar).
- Turning the slider up added swirls to a flow that was originally smooth.
- This shows the concept vector actually causes the physical feature to appear or disappear.
- Diffusion control:
- Turning up “diffusion” made boundaries blur and spread more.
- Turning it down made boundaries sharper and more confined.
- This matches how diffusion works physically.
- Simulation speed control:
- Turning up the “speed” concept made events (like vortex formation) happen earlier in the simulation window.
- Turning it down delayed those events.
- This is like speeding up or slowing down the model’s sense of time.
- Cross-domain transfer to different systems:
- Rayleigh–Bénard convection (heated fluid): the “vortex” concept changed convection strength and pressure patterns.
- Euler gas dynamics (compressible gas): the “vortex” concept increased or decreased rotating features near shock fronts; the “speed” concept made shock fronts move faster or slower.
- Gray–Scott reaction–diffusion (chemical patterns): adding the “vortex” concept turned moving “gliders” into spiral-like patterns—even though this isn’t fluid flow. This suggests the model learned a general idea of “rotation/spiraling” that applies beyond fluids.
Why this matters: The changes weren’t random—they matched the physical meaning of each concept. And they often showed up where physics would expect them (e.g., vortices near shocks), which suggests the model captured real physical ideas.
Why It Matters
This work suggests that:
- Big physics models don’t just memorize; they learn abstract, reusable concepts—similar to how LLMs learn ideas like “negation” or “politeness.”
- These concepts are “linear” in the model’s hidden space, meaning you can point to them with a single direction and adjust them like a slider.
- You can causally steer the model to explore “what if” scenarios—speed things up, add rotation, increase diffusion—even across different types of physics.
This could help scientists:
- Test hypotheses quickly by adding/removing features and seeing the outcome.
- Fix or adjust simulations in real time if they drift or miss important features.
- Audit what the model “knows” about physics by applying targeted nudges and checking the response.
A Few Caveats
- Physical realism can depend on how strong the steering is and how close the initial conditions are to the target regime. Push too hard, or start too far from the regime, and results can look unrealistic.
- Including detailed spatial structure in the concept sometimes led to less realistic secondary fields; using the averaged concept (without positions) often produced cleaner cross-domain results.
- More work is needed to confirm that all steered outcomes obey the true governing laws, not just produce look-alike patterns.
Bottom Line
The paper shows that large physics models have steerable “concept knobs” inside them. By finding and turning these knobs—like vortex, diffusion, and speed—you can make the model add or remove physical features on purpose, even in different types of systems. This is an exciting step toward more understandable, controllable, and scientifically useful AI for physics.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete issues unresolved and open for future investigation:
- Quantitative validation is missing: no metrics are reported for how steering alters physical quantities (e.g., vorticity magnitude via Q-criterion/λ2, enstrophy, shock speed, diffusion coefficient, energy spectra) or whether conservation laws (mass, momentum, energy) and boundary conditions are respected during and after interventions.
- Physicality of induced features remains unclear: it is unknown whether feature induction reflects physically valid perturbations and subsequent lawful evolution versus cosmetic pattern synthesis; rigorous checks via PDE residuals, divergence constraints (e.g., ∇·u≈0 in incompressible regimes), and consistency in auxiliary fields are needed.
- Layer dependence is uncharacterized: only a single late transformer block (
blocks.39) is probed; the sensitivity of concept extraction and steering to layer choice (early/mid/late, attention vs MLP, pre-/post-LN) and to multi-layer interventions is not evaluated. - Steering function design lacks justification: the chosen scaling
α‖a‖^2/‖Δ‖^2with subsequent renormalization is ad hoc; compare alternative injection schemes (constant-step, norm-preserving projected updates, gating, per-channel scaling) and analyze their stability and physical fidelity. - Hyperparameter selection is unprincipled: no method is provided to select
αsafely; highαproduces unphysical fields; develop adaptive or constrainedαselection (e.g., via conservation-law monitors, Lipschitz bounds on rollout error, or constraint-aware optimization). - Difference-of-means directions may conflate features: the approach can pick up spurious correlations (e.g., parameter co-variation across regimes); evaluate with controlled datasets, stratification by parameters, and discriminative methods (Fisher LDA, logistic probes, supervised contrastive) to isolate cleaner directions.
- Sample efficiency and robustness are not assessed: how many trajectories or windows are required for stable concept direction estimation, and how sensitive directions are to sample choice, window length
T, random seeds, and normalization choices remains unknown. - Normalization scheme may not generalize across domains: per-position mean/std computed on “training data” are not specified for cross-domain use; investigate whether normalization must be recomputed per system, and its effect on transferability and scale invariance.
- Polysemanticity/feature entanglement is unaddressed: concept directions may mix multiple phenomena; compare against Sparse Autoencoders, dictionary learning, and attribution graphs to seek monosemantic, localized features.
- Spatial averaging vs full spatial tensors is not theoretically grounded: spatially-averaged channel-only directions often perform better for transfer, but why and when this holds is unknown; analyze what is encoded in channels vs spatial dimensions and develop principled spatial alignment schemes.
- Transfer generality is unquantified: transfer is demonstrated on three systems qualitatively; quantify transfer success rates across more systems in The Well, parameter sweeps, and diverse initial conditions, and define domain-general benchmarks and metrics.
- Causal claims need stronger evidence: beyond output changes under injection, perform causal mediation and activation patching to identify mediators/subcircuits and rule out confounders; test whether ablations of discovered subcircuits remove the concept effect.
- Long-horizon stability is not evaluated: assess whether steering-induced changes remain stable or drift over longer rollouts, how error accumulates, and whether interventions increase rollout brittleness or mode collapse.
- Initial-condition sensitivity is anecdotal: formalize the observed dependence on proximity to regime transition and derive criteria or predictors for when small interventions suffice versus when they cause unphysical distortions.
- Composition and interactions of concepts are unexplored: investigate whether multiple concept directions can be composed linearly, whether they interfere nonlinearly, and how to orthogonalize or disentangle overlapping directions.
- Symmetry properties are unknown: test whether concept directions are invariant or equivariant under spatial symmetries (translation, rotation, reflection) and whether symmetry-aware directions improve physical plausibility and transfer.
- Localized steering is not studied: interventions are applied “across all tokens and time steps”; evaluate targeted spatial/temporal steering (e.g., near shear layers or shock fronts) and whether localized injections improve realism and reduce collateral distortions.
- Impact on base model fidelity is unmeasured: determine whether steering degrades Walrus’s predictive accuracy on unsteered frames or tasks (OOD effects), and quantify trade-offs between controllability and base performance.
- Gray-Scott “vorticity” interpretation is speculative: validate that induced spirals are consistent with Gray-Scott parameter regimes via reaction-diffusion diagnostics (e.g., dispersion relations, pattern classification), not just visual resemblance.
- “Speed” concept semantics are ambiguous: distinguish between genuine time-reparameterization (dt scaling) and other latent changes; verify by matching physical time steps and comparing event timing, shock positions, and phase alignment.
- Reproducibility details are scant: specify exact datasets, parameter ranges, sample counts, seeds, code, and hooks to enable replication and statistical significance testing across runs.
- Alternative concept discovery pipelines are not compared: benchmark difference-of-means against linear probes, CCA, spectral methods (PCA/SVD on activations), and supervised contrastive approaches for concept isolation quality and downstream steering efficacy.
- Safety and governance of steering are not discussed: outline safeguards to prevent misuse (e.g., creating plausible but unphysical outputs), monitoring for violations, and user guidelines for responsible application in scientific workflows.
Practical Applications
Overview
This paper introduces “physics steering,” a causal intervention technique that identifies single “concept directions” in the activation space of a physics foundation model (Walrus) and injects them during inference to induce, suppress, or modulate physical behaviors (e.g., vorticity, diffusion, temporal speed). The method generalizes across domains (fluids, compressible Euler flows, reaction–diffusion), suggesting the model learns abstract, transferable physical representations. Below are practical applications, organized by deployment horizon, with sector links, suggested tools/workflows, and feasibility notes.
Immediate Applications
These are deployable with current models and tooling (e.g., Walrus + PyTorch hooks), primarily in research, ML engineering, and simulation workflows.
- Simulation debugging and targeted error diagnosis
- Sectors: aerospace, automotive, energy (CFD), climate/weather, academia (scientific ML)
- What it enables: Use concept vectors (e.g., “vortex,” “diffusion,” “speed”) to probe which internal features drive artifacts, suppress spurious structures, or induce missing phenomena to localize failure modes in surrogate rollouts.
- Tools/workflows: “Activation Steering Debugger” (layer hooks, α sweeps, before/after field diffs), steering dashboards, layerwise sensitivity maps.
- Assumptions/dependencies: Access to intermediate activations; domain-expert review to judge physical plausibility; α tuning; model comparable to Walrus.
- Counterfactual “what-if” exploration during design reviews
- Sectors: engineering (aero/auto/marine), energy (turbomachinery, wind), climate R&D
- What it enables: Rapidly explore “more/less vortical,” “more/less diffusive,” or “faster/slower evolution” scenarios without resimulating PDEs from scratch; stress-test designs under nearby regimes.
- Tools/workflows: “Counterfactual Lab” UI; saved “concept knobs”; batch-run counterfactuals on design variants.
- Assumptions/dependencies: Surrogate model fidelity in neighborhood of interest; initial conditions not too far from target regime.
- Rollout stabilization and drift correction in autoregressive surrogates
- Sectors: digital twins (process, manufacturing, energy), robotics simulation
- What it enables: Use negative steering along failure-prone features to damp drift (e.g., prevent spurious eddies), improving long-horizon predictions.
- Tools/workflows: Closed-loop alpha scheduling; anomaly detectors that trigger steering; “safety envelope” heuristics.
- Assumptions/dependencies: Empirical calibration of α; monitoring for unphysical side effects in secondary fields.
- Data augmentation targeted by concept control
- Sectors: ML for PDEs, simulation data engineering
- What it enables: Generate augmented rollouts with controlled presence/absence of features (e.g., induce mild vortices), balancing datasets to improve robustness and reduce spurious correlations.
- Tools/workflows: “Steered Augmenter” that tags outputs with α and concept metadata; training curriculum using concept-intensity schedules.
- Assumptions/dependencies: Guardrails to avoid unphysical samples; labels linking concept intensity to physical parameters.
- Rapid domain adaptation via spatially averaged concept directions
- Sectors: engineering, climate, chemicals
- What it enables: Transfer feature controls from one dataset to another (e.g., shear flow → Euler) using channel-only concept vectors to warm-start fine-tuning or calibrate behavior.
- Tools/workflows: “Concept Bank/Registry” with spatially averaged vectors; alignment utilities (pad/interpolate if needed).
- Assumptions/dependencies: Cross-system feature alignment holds best with spatial averaging; careful validation in new domain.
- Temporal alignment and resampling harmonization
- Sectors: data engineering for simulators, multi-lab data integration
- What it enables: Use “speed” concept to reconcile trajectories recorded at different frame rates, easing dataset merging and comparative analysis.
- Tools/workflows: Temporal harmonization module using speed steering; α-to-frame-rate calibration curves.
- Assumptions/dependencies: Stable mapping between α and effective progression; local validity over rollout windows.
- Model auditing and interpretability reporting for scientific surrogates
- Sectors: regulated engineering (aero/energy), research compliance, policy-facing reports
- What it enables: Demonstrate causal links between learned features and outputs; document steering tests (induce/suppress) as transparency evidence.
- Tools/workflows: “Steering Audit Kit”: standardized tests, plots, and metrics (field-wise consistency, expected-location emergence, e.g., vortices at shocks).
- Assumptions/dependencies: Agreed metrics for physical plausibility; reproducible seeds and α schedules.
- Educational interactive labs for physics
- Sectors: education, public outreach
- What it enables: Hands-on “concept sliders” to see how vorticity, diffusion, or speed affect fields across systems, aiding intuition about PDE dynamics.
- Tools/workflows: Web app/Jupyter widgets backed by Walrus-like surrogates; preloaded concept vectors and lesson plans.
- Assumptions/dependencies: Lightweight inference; curated examples to avoid unphysical artifacts.
- Sensitivity analysis and hypothesis testing
- Sectors: academia, R&D labs
- What it enables: Small α perturbations as controlled experiments to assess sensitivity to features vs. parameters; quick screening before costly HPC runs.
- Tools/workflows: α–response curves; mapping α to expected parameter shifts (e.g., proxy for Re/Sc changes).
- Assumptions/dependencies: Local linearity of representation; monotonic α effects in the studied band.
- Benchmarking interpretability across physics models
- Sectors: academia, model providers
- What it enables: Compare steerability and cross-domain transfer across architectures/datasets; standardize interpretability diagnostics for physics FMs.
- Tools/workflows: Public benchmark suite built on The Well; shared “concept vector” leaderboards.
- Assumptions/dependencies: Access to model internals; consistent evaluation protocols.
Long-Term Applications
These require further research, scaling, validation, or integration into production systems.
- Steered digital twins for closed-loop industrial control
- Sectors: chemicals, energy, manufacturing, HVAC, process control
- What it could enable: Real-time actuation recommendations by nudging surrogate toward desired regimes (e.g., suppress undesired eddies, enhance mixing) while respecting safety envelopes.
- Tools/products: Control stack integrating sensor assimilation, concept steering, and model predictive control; “α-scheduler” with uncertainty-aware constraints.
- Dependencies: Hard guarantees on physicality; robust uncertainty quantification; latency budgets; operator-in-the-loop oversight.
- Generative design with “concept knobs”
- Sectors: aerospace, automotive, turbomachinery, microfluidics, built environment
- What it could enable: Explore design spaces with interactive control over flow features (e.g., vortex strength near surfaces), accelerating optimization and creativity.
- Tools/products: CAD/CFD co-pilot with real-time steered surrogate; multi-objective optimizers coupling concept steering and constraints.
- Dependencies: Tight coupling to CAD meshing; validation with high-fidelity solvers; transfer across Reynolds regimes.
- Physics-aware guardrails for scientific FMs
- Sectors: safety-critical engineering, regulatory tech
- What it could enable: Automated steering away from unphysical regimes during inference; enforce conservation or boundedness by projecting activations off unsafe directions.
- Tools/products: “Physicality Validator + Steering Safety Net” modules; formalized invariants library.
- Dependencies: Detection of unphysical states; provable constraints; standardized conformance tests.
- Discovery of cross-domain invariants and new abstractions
- Sectors: academia, national labs
- What it could enable: Use transferable concept vectors to uncover abstract patterns (e.g., “rotation” spanning fluids and reaction–diffusion) and generate hypotheses about emergent laws or analogies.
- Tools/products: Feature-atlas of physics-concepts; automated hypothesis generation and ranking.
- Dependencies: Rigorous physical validation; partnerships with domain experts; replication across datasets.
- Simulation acceleration via steer-to-target macroscales
- Sectors: HPC, climate, weather, plasma physics
- What it could enable: Drive surrogates toward desired macrostructures, reducing need for ultra-fine resolution in exploratory runs before selective high-fidelity refinement.
- Tools/products: Coarse-to-fine pipelines with concept-guided pre-runs; adaptive refinement triggers based on feature intensities.
- Dependencies: Demonstrated stability under steering; error estimators; coupling to AMR solvers.
- Standardized “concept vector APIs” and marketplaces
- Sectors: software, cloud AI platforms
- What it could enable: Share, version, and compose concept directions across models and domains (e.g., “vortex_v1,” “diffusion_high_v2”), enabling plug-and-play steering.
- Tools/products: Registry, provenance tracking, compatibility validators, license management.
- Dependencies: Inter-model portability; governance for safety and IP; metadata standards.
- Policy decision-support via counterfactual stress testing
- Sectors: climate risk, urban planning, insurance, infrastructure policy
- What it could enable: Stress-test extreme scenarios by steering toward intensified features (e.g., stronger convection patterns), to explore consequences and resilience.
- Tools/products: Policy-facing dashboards with uncertainty overlays; interpretable narratives linking “concept intensity” to risk metrics.
- Dependencies: Strong external validation; communication of limits/uncertainty; ethical use and transparency.
- Automated experiment design in labs
- Sectors: materials, microfluidics, synthetic biology
- What it could enable: Steer simulated patterns (e.g., spirals, mixing) to identify conditions that likely reproduce desired behaviors in physical experiments.
- Tools/products: Experiment recommender integrating steered surrogates with Bayesian optimization.
- Dependencies: Reliable α-to-parameter mapping; sim-to-real validation; instrumentation constraints.
- Curriculum-integrated virtual physics labs
- Sectors: education
- What it could enable: Standards-aligned modules where students manipulate abstract features to learn PDE dynamics, stability, and pattern formation.
- Tools/products: LMS-integrated apps; teacher dashboards; assessment rubrics tied to concept mastery.
- Dependencies: Accessible compute; curated, age-appropriate content; guardrails against misleading artifacts.
- Certification frameworks for AI-driven engineering
- Sectors: regulators, standards bodies
- What it could enable: Causal-steering tests as part of model certification (prove model responds to physically meaningful directions and resists unsafe ones).
- Tools/products: Test suites, thresholds, audit reports; third-party validation services.
- Dependencies: Community consensus on metrics; incident reporting; legal harmonization.
- Multiphysics co-simulation mediated by shared abstractions
- Sectors: energy systems, aerospace, geoscience
- What it could enable: Coordinate coupled surrogates (fluid–structure–chemistry) using shared concept controls (e.g., “mixing,” “rotation”) for stable, interpretable interactions.
- Tools/products: Concept-level orchestration layer; cross-model alignment protocols.
- Dependencies: Robust cross-domain transfer; synchronization and latency management.
- Patient-specific hemodynamics planning (research-to-clinic)
- Sectors: healthcare (cardiovascular)
- What it could enable: Explore “what-if” flow patterns (e.g., suppress recirculation zones) in silico to assess intervention options.
- Tools/products: Clinical planning sandbox; links to imaging-derived boundary conditions.
- Dependencies: Regulatory-grade validation; strict physicality and uncertainty bounds; privacy and safety guidelines.
Cross-Cutting Assumptions and Dependencies
- Access to foundation models with activation hooks (e.g., Walrus-like models) and rights to use them.
- High-quality, diverse simulation data (The Well or analogous) to learn transferable concepts.
- Calibration of α and layer choice; spatial averaging often improves cross-domain plausibility.
- Proximity of initial conditions to target regime improves realism; large α risks unphysical fields.
- Physicality checks and uncertainty quantification are essential, especially for safety-critical use.
- Compute and latency constraints for real-time or large-scale deployments.
- Governance, auditability, and clear communication of limits for policy and clinical contexts.
Glossary
- Activation space: The vector space of a model’s internal activations where directions can correspond to concepts or features. "Inspired by recent work identifying single directions in activation space for complex behaviours in LLMs"
- Activation steering: A causal intervention technique that adds a precomputed concept vector to activations to change model outputs. "Activation steering is a causal intervention technique where a precomputed vector, representing a concept, is added to the models activations at a specific layer during a forward pass."
- Activation tensor: The multi-dimensional array of activations captured at a layer during a forward pass. "we extract the activation tensor "
- Autoregressive training: Learning to predict the next state given previous states in a sequence. "Walrus is trained autoregressively to predict the next state of a physical system given a sequence of previous states."
- Buoyancy field: A field variable representing buoyancy-driven effects in fluid simulations. "the intervention appears to manifest as moderate changes to convection in the buoyancy field"
- Causal control: The ability to deliberately manipulate internal representations to produce targeted behavior changes. "we can steer its predictions, demonstrating causal control over physical behaviours"
- Channel dimension: The feature dimension of an activation tensor, indexing learned channels/features. "where is the sequence length, the channel/feature dimension, and , are spatial dimensions (width and height)."
- Concept delta: A difference between mean activations for contrasting inputs used to isolate a concept direction. "This direction can be found by the computation of concept deltas, that is, by finding differences between model activations for different inputs"
- Concept direction: A direction in activation space encoding a specific concept that can be injected to steer behavior. "These delta tensors act as concept directions in activation space, encoding specific physical features."
- Concept vector: A vector in activation space corresponding to a concept and used for steering. "We inject these concept vectors during the model's forward pass to achieve activation steering"
- Counterfactual exploration: Probing “what-if” scenarios by intervening on a model’s internal state. "we can perform counterfactual exploration (\"what if this flow were more diffuse?\")"
- Cross-domain transfer: Applying learned concept directions across different physical systems or datasets. "For cross-domain transfer experiments where spatial structures may not align between different physical systems, we also compute a spatially-averaged concept direction"
- Delta tensor: The difference-of-means activation tensor between two regimes capturing a concept. "The \"delta tensor\", or concept direction, were then computed by taking the difference between the two averaged activation tensors."
- Density field: A spatial field of mass density values in a simulation. "Density field for $\scriptstyle\overline{}_{\text{vortex}$ injection into Euler quadrants."
- Diffusion: The process of molecular mixing or spreading in a medium. "we computed the diffusion delta direction as the difference between the averaged activations for several high molecular diffusion and low molecular diffusion Shear Flow data files â that is, two groups of Shear Flow simulations with identical Reynolds numbers but different sets of Schmidt numbers."
- Difference-of-means approach: Computing concept directions by subtracting averaged activations across contrasting regimes. "The success of our simple difference-of-means approach suggests that these core physical concepts are represented strongly and linearly in the model's activation space"
- Euler Quadrant: A fluid dynamics dataset simulating compressible, inviscid gases governed by Euler equations. "Euler Quadrant: A second alternative fluid dynamics dataset which seeks to simulate two compressible, inviscid gas species governed by the Euler equations."
- Forward hook: A mechanism to intercept and modify activations during a forward pass. "Using a forward hook at the same target layer, the original activations were modified by addition of the concept direction."
- Foundation model: A large pretrained model intended for broad applicability across tasks or domains. "a large physics-focused foundation model"
- Gray-Scott reaction-diffusion: A reaction–diffusion system producing rich spatial patterns (e.g., spirals, gliders). "Gray-Scott Reaction-Diffusion: An entirely unrelated system outside the field of fluid dynamics."
- Laminar regime: A smooth, orderly flow state with minimal mixing or turbulence. "transformed into a smooth, parallel state characteristic of a laminar regime."
- Latent space: The internal representational space where high-level concepts can be linearly encoded. "single directions in the latent space of the physics foundation model that correspond to specific physical concepts like vorticity, diffusion, and simulation speed."
- Linear representation hypothesis: The idea that concepts are represented as linear directions in activation space. "posits that features (i.e., concepts) are represented linearly as directions in a models activation space"
- Magneto-hydrodynamics: The study/simulation of electrically conducting fluids interacting with magnetic fields. "Magneto-hydrodynamics"
- Mechanistic interpretability: Reverse-engineering neural networks to understand their internal computations. "Recent advances in mechanistic interpretability have revealed that LLMs develop internal representations"
- Monosemantic features: Features with a one-to-one mapping to neurons in a learned sparse representation. "resulting in monosemantic features"
- PDEs (Partial Differential Equations): Equations involving multivariable functions and their partial derivatives governing physical systems. "spatiotemporal surrogate modelling of physical systems described by PDEs."
- Polysemanticity: The phenomenon where neurons represent multiple features due to capacity constraints and superposition. "Polysemanticity. refers to the theory that deep learning models can represent more features than the dimensionality of their activation space would suggest."
- Rayleigh-Bénard Convection: Thermal convection in a fluid layer heated from below and cooled from above. "Rayleigh-Bénard Convection: An alternative fluid dynamics dataset which models fluid heated from below and cooled from above, creating convection patterns."
- Reaction–diffusion system: A system where chemical species react and diffuse to form spatial patterns. "This dataset contains simulations of a chemical reaction-diffusion system which produces various pattern formations, including gliders, spots, spirals, and mazes depending on parameter settings."
- Reynolds numbers: Dimensionless quantities characterizing the ratio of inertial to viscous forces in fluid flow. "identical Reynolds numbers"
- Rollout mode: Running a model forward over multiple steps using its own predictions iteratively. "The model was run in rollout mode, processing windowed segments of consecutive timesteps."
- Schmidt numbers: Dimensionless numbers expressing the ratio of momentum diffusivity (viscosity) to mass diffusivity. "different sets of Schmidt numbers."
- Shear Flow: A fluid dynamics setup where layers of fluid move parallel at different velocities, creating shear. "we focused our initial investigations on vorticity within the Shear Flow dataset"
- Shock fronts: Discontinuities in flow variables (e.g., pressure, density) that move through a medium. "the shock fronts move faster with positive steering and slower with negative steering."
- Single Direction Steering: Steering behavior via a single activation-space direction associated with a complex behavior. "which showed that complex behaviours in LLMs, such as refusal behaviour, can be identified with a single direction in activation space."
- Sparse Autoencoders (SAEs): Autoencoders that learn sparse, often more interpretable, feature representations. "Methods such as probing and Sparse Autoencoders (SAEs)"
- Spatial alignment: Matching spatial dimensions across datasets or models via padding/interpolation for transfer. "Spatial alignment: When spatial dimensions are similar (differing by at most one element), we pad or interpolate to match dimensions, preserving spatial structure."
- Spatially-averaged concept direction: A channel-only concept vector obtained by averaging over spatial positions for cross-domain use. "For cross-domain transfer experiments where spatial structures may not align between different physical systems, we also compute a spatially-averaged concept direction"
- Spatiotemporal surrogate modelling: Learning models that emulate the dynamics of physical systems over space and time. "Walrus is a large vision transformer \citep{vaswani2017attention, ho2019axial} based foundation model designed for spatiotemporal surrogate modelling of physical systems described by PDEs."
- Steering tensor: The tensor injected into activations to steer outputs, potentially including spatial structure. "the impact which the presence of spatial dimensions in the steering tensor can have."
- Token deltas: Per-step predicted changes to tokens rather than predicting full token states. "Walrus predicts token deltas at each time step"
- Transformer block: A layer unit in a transformer architecture comprising attention and feedforward sublayers. "for a particular transformer block of a physics foundation model."
- Tracer fields: Passive scalar fields used to visualize or track flow properties. "On the left tracer fields for $\scriptstyle_{\text{diffusion}$ injection into Shear Flow vortex regime"
- Vision transformer: A transformer architecture adapted for grid/imagelike inputs. "Walrus is a large vision transformer \citep{vaswani2017attention, ho2019axial} based foundation model"
- Vorticity: A measure of local rotation in a fluid flow (curl of velocity). "we focused our initial investigations on vorticity within the Shear Flow dataset"
- Walrus: The specific physics foundation model studied in the paper. "Walrus is a large vision transformer \citep{vaswani2017attention, ho2019axial} based foundation model designed for spatiotemporal surrogate modelling of physical systems described by PDEs."
- The Well: A large multi-domain benchmark of physics simulations used for pretraining and evaluation. "The Well ... is a large-scale (15TB) benchmark dataset comprising 16 distinct numerical simulations"
Collections
Sign up for free to add this paper to one or more collections.