- The paper introduces FFGo, which utilizes the first frame as a conceptual memory buffer to enable multi-reference video customization.
- It replaces manual prompt engineering with automated dataset curation and few-shot LoRA adaptation to ensure scene transition stability and object identity preservation.
- Experimental results show substantial improvements, with FFGo outperforming baselines by over 30% in quality and retention as evidenced by user studies.
Leveraging the First Frame for Reference-Based Video Customization: An Expert Analysis of FFGo
Introduction: Reconceptualizing the First Frame
This paper, "First Frame Is the Place to Go for Video Content Customization" (2511.15700), introduces a fundamental shift in the treatment of the initial frame within video generation models. Contrary to standard approaches where the initial frame merely seeds the spatiotemporal progression of generated content, this work reveals that modern diffusion-based video generators implicitly treat the first frame as a conceptual memory buffer. This buffer stores multimodal visual entities, supporting explicit subject mixing and controlled scene transition throughout the generation process.
This insight underpins the design of FFGo—a lightweight add-on leveraging the innate capabilities of pre-trained video models for multifaceted, reference-based customization. FFGo utilizes only 20–50 training videos and requires no architectural modifications, preserving generalist priors and circumventing extensive domain-specific finetuning.
Core Methodology: FFGo Add-on for Multi-Reference Customization
Theoretical Foundation
Empirical analysis indicates that pre-trained diffusion-based video generators (e.g., Wan2.2 (Wan et al., 26 Mar 2025), Sora (Liu et al., 2024), Veo) can fuse multiple referenced subjects provided they are composited coherently in the initial frame. However, this innate ability is not reliably triggered by vanilla prompt engineering, suffering from instability and identity loss in generated transitions.











Figure 1: The impact of transition phrase engineering on composition stability and reference preservation across diverse video generators.
Three limitations in default behavior are systematically resolved by FFGo:
- Manual prompt engineering is replaced by automatic dataset curation and structured prompt generation via vision-LLMs (VLMs), specifically Gemini-2.5-Pro.
- Scene transition instability is addressed through few-shot LoRA-based adaptation, robustly activating latent transition capabilities.
- Object identity preservation is enforced by explicit segmentation and composition within the reference frame, encoded in training data.
Pipeline Overview
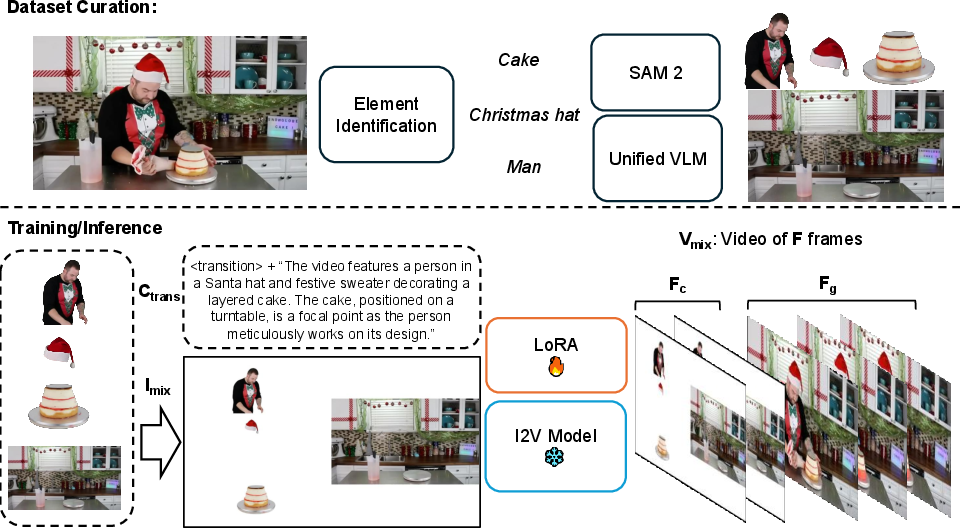
Figure 2: The schematic pipeline for FFGo, with data curation, LoRA adaptation, and clean video inference stages.
- Dataset Curation: VLMs are prompted to extract foreground objects and backgrounds from initial frames. This compositional data is paired with procedurally generated prompts emphasizing element interaction and placement.
- Few-shot LoRA Adaptation: Using only 20–50 high-quality compositional video pairs, low-rank update modules are trained on the I2V backbone, guiding the base model to utilize the initial frame for concept storage and fusion.
- Customized Inference: At test time, multi-object reference frames paired with enhanced prompts yield customized videos. Simple postprocessing (discarding initial compression frames) ensures clean output.
Experimental Results
Generalization and Quantitative Analysis
Evaluation spans multiple application domains: robotic manipulation, simulation (driving, aerial, underwater), filmmaking, and multi-product demonstration—far exceeding the domain capacity of prior work (limited to 3 references and human-object scenes).
Figure 3: Distribution of training data across interaction categories (human-object, human-human, element insertion, robot manipulation).
Qualitative results highlight strong identity retention, compositional control, and generalization across unseen interaction types.

Figure 4: FFGo preserves object/scene identities and produces coherent multi-object interactions, outperforming task-specialized baselines.

Figure 5: FFGo handles five references (four objects + scene) with natural interactions—architectural baselines (VACE, SkyReels-A2) fail to retain all objects.

Figure 6: FFGo exhibits robust multi-human-object interaction synthesis with realistic temporal coherence; baselines lose object integrity.
A user study (n=40, 200 annotations) quantifies the advantage:
- Overall Quality: FFGo = 4.28 vs. VACE = 3.00, SkyReels-A2 = 2.34, Wan2.2-I2V-A14B = 2.09
- Object/Scene Identity: FFGo scores 4.53/4.58, >30% higher than baselines.
- User Preference: FFGo selected as top choice in 81.2% of cases.
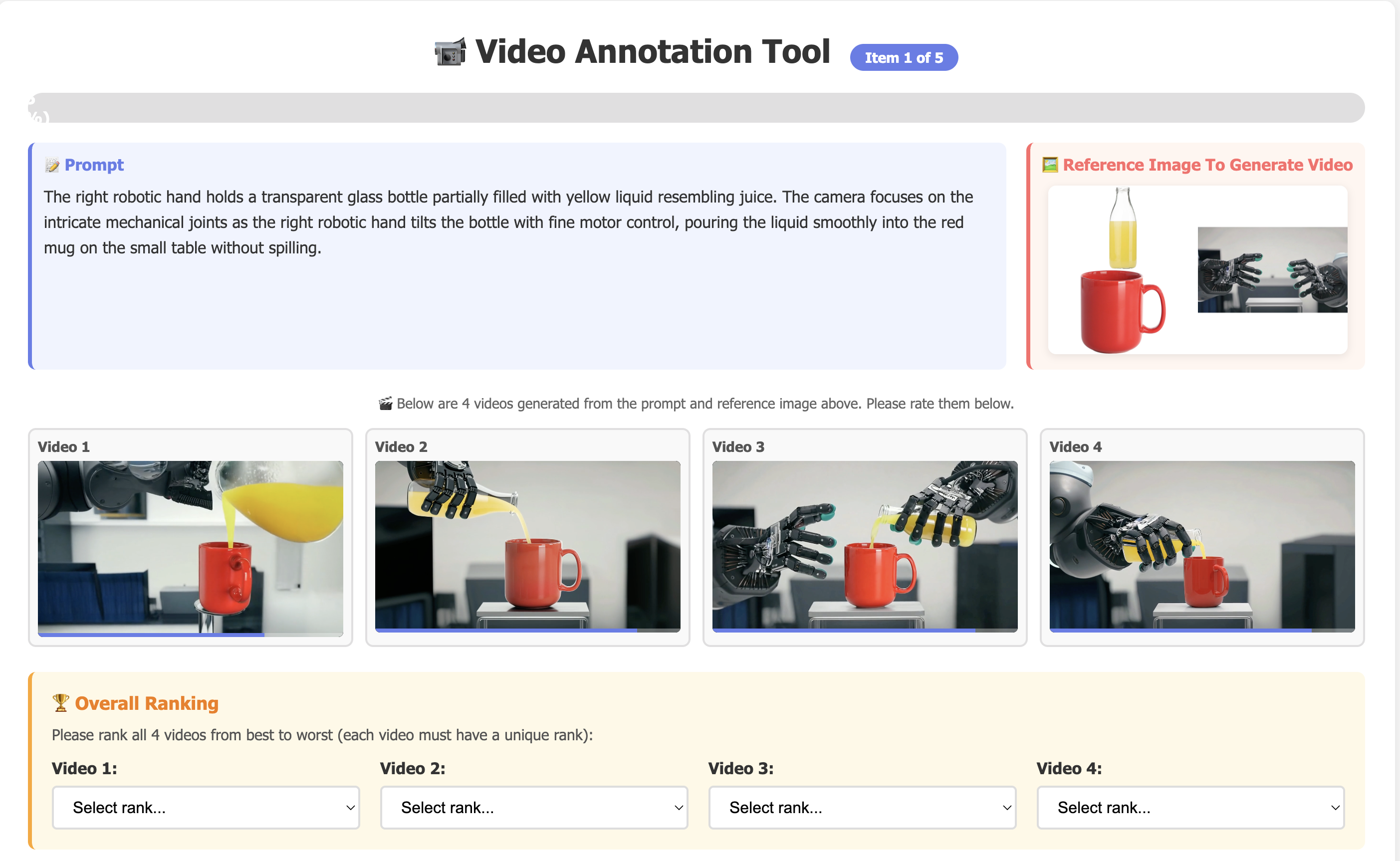
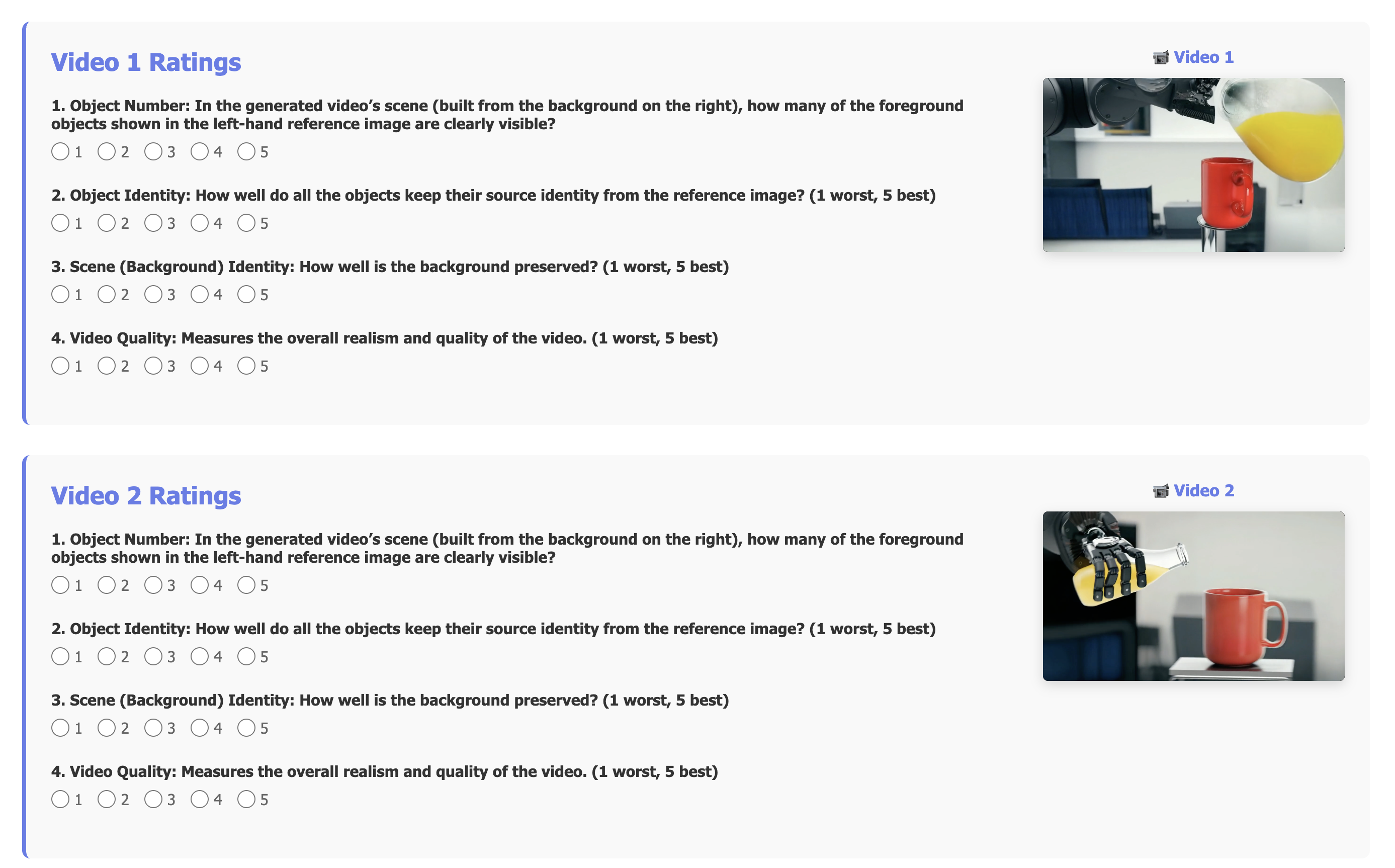
Figure 7: Distribution of user rankings—FFGo overwhelmingly preferred for quality and fidelity.
Preservation of Pre-trained Priors
FFGo’s few-shot LoRA-induced adaptation triggers dormant capabilities rather than overriding backbone priors, as evidenced by rare instances of successful base model output closely matching FFGo’s generated content.

Figure 8: Qualitative similarity between rare successful base model outputs and FFGo, evidencing preservation of original generative priors.
This is a critical property, as domain-specific finetuning on sparse, low-diversity data typically degrades broad applicability and synthesis quality in conventional approaches.
Limitations and Future Outlook
The scalable compositional buffer capacity in the initial frame is bounded by frame resolution—identity retention and selection reliability diminish as reference count increases beyond five. Selective control of individual subject manipulation via prompts remains challenging under high compositional density.
Potential future advancements include:
- Multi-frame conceptual buffers to increase capacity and reference diversity.
- Refined VLM-driven supervision for targeted object manipulation and selection strategies.
- Application to hierarchical scene understanding and event-driven video synthesis.
Practical and Theoretical Implications
The FFGo paradigm fundamentally alters how reference-based customization is realized in video synthesis. By leveraging innate, underutilized conceptual buffering in the initial frame, it enables:
- Efficient subject mixing without sacrificing generalist pre-training advantages.
- Architectural agnosticism: Implementation as a modular add-on for arbitrary I2V models.
- Minimal labeled data requirements, reducing cost and domain adaptation time.
Theoretically, this work posits new directions for emergent properties and in-context utilization of large generative backbones, paralleling recent findings in LLMs and VLMs regarding instruction-following and compositional generalization.
Conclusion
This paper rigorously demonstrates that the first frame in generative video models is best treated as a conceptual memory buffer, enabling controlled reference-based synthesis. Through FFGo—a dataset and LoRA-based pipeline—this innate ability is reliably activated without architectural changes or domain-specific retraining. FFGo markedly outperforms many task-specialized baselines in both qualitative and quantitative evaluations, establishing a new efficiency and generalization standard for customizable video generation. The outlined limitations and conceptual advances point toward promising research trajectories in compositional generative modeling and multimodal integration.