- The paper introduces FlipVQA-Miner, an automated pipeline that efficiently extracts structured QA and VQA pairs from textbooks using layout-aware OCR and LLM-based semantic reconstruction.
- It employs MinerU for precise document parsing, significantly reducing token lengths and parsing errors compared to direct LLM prompting.
- Experimental results demonstrate robust performance with F1 scores above 0.96, supporting scalable educational content extraction for AI training.
Overview of "FlipVQA-Miner: Cross-Page Visual Question-Answer Mining from Textbooks"
The paper "FlipVQA-Miner: Cross-Page Visual Question-Answer Mining from Textbooks" (2511.16216) proposes an innovative, automated pipeline designed to extract structured Question-Answer (QA) and Visual Question-Answer (VQA) pairs from educational materials. Leveraging recent advancements in layout-aware OCR combined with semantic parsing facilitated by LLMs, this system offers an efficient solution to transform raw textbook content into AI-ready data. Given the challenges and expenses associated with manually curating high-quality supervised datasets for instruction tuning and reinforcement learning of LLMs, such an approach appears promising in utilizing abundant human-authored content for large-scale model training.
Methodology
The approach implemented in "FlipVQA-Miner" integrates two core components: MinerU for structural parsing and LLMs for semantic reconstruction. MinerU is a document parsing toolkit responsible for converting raw PDFs into a structured format, meticulously preserving layout information, text blocks, tables, and images. This transformation reduces input complexity and error rates for subsequent semantic operations.
Conversely, the LLMs execute semantic reconstruction tasks. By grouping fragmented text blocks, aligning question-answer pairs across disparate sections, and inserting relevant images, the LLMs construct coherent multimodal QA pairs ready for supervision tasks. The computational efficiency of this system is notably highlighted, offering significant reductions in token lengths and parsing errors compared to direct LLM prompting.
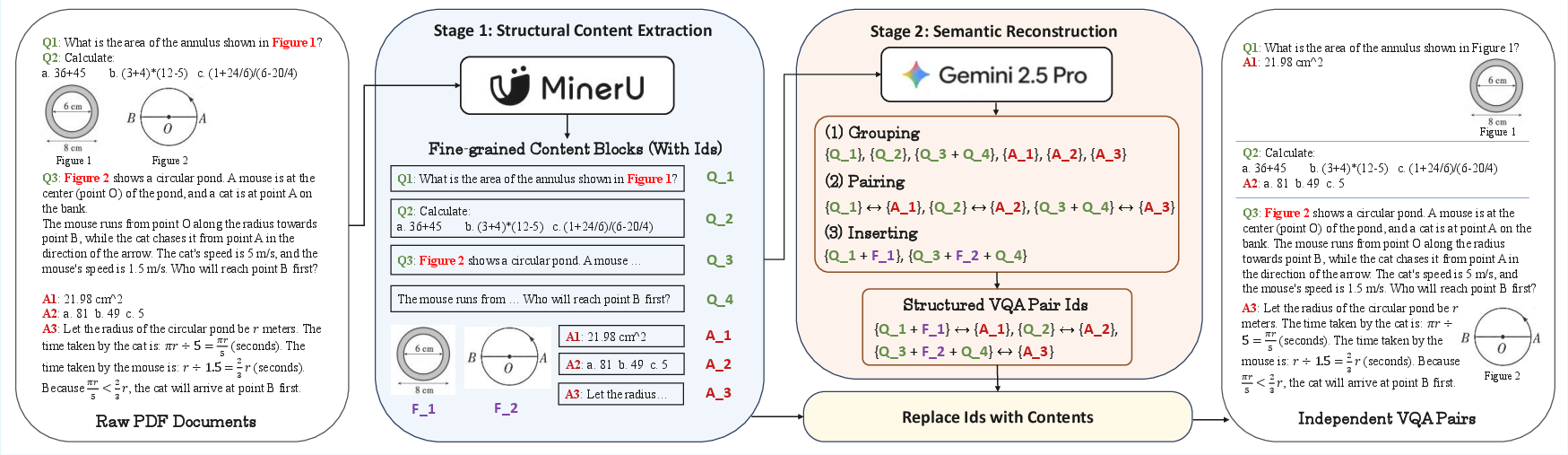
Figure 1: Our approach of VQA pair extraction from raw PDF documents. MinerU provides a structured representation of the document content, while the LLM performs block grouping, QA pairing, and image inserting on the extracted elements.
Experiments and Results
Experiments were conducted across a diverse set of documents, including interleaved VQA pairs from a complex manual, long-distance pairs from an abstract algebra textbook, and a multi-column Chinese exercise book. Results indicate the superiority of the proposed pipeline with F1 scores exceeding 0.98 for text extraction and above 0.96 for vision extraction in all test cases. These outcomes demonstrate robust handling of varying document layouts, languages, and complexities. The extraction protocol involved evaluations based on manual assessment, emphasizing structural accuracy over minor parsing imperfections.
The qualitative demonstrations further establish the system's capability to resolve long-distance dependencies and interleaved content efficiently, highlighting the integration of structural parsing and semantic reasoning.
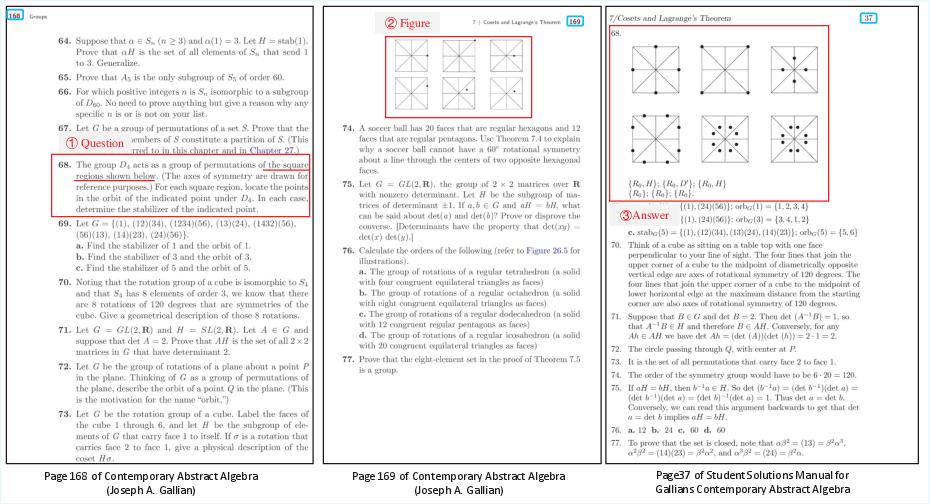
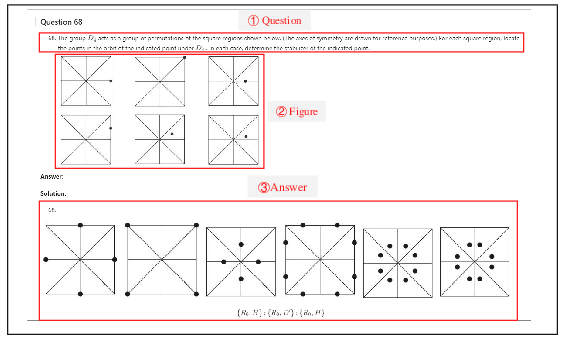
Figure 2: Original question, figure, and answer arrangement in PDF.

Figure 3: Extracted and reconstructed QA pair rendered in Markdown.
Implications and Future Directions
The proposed pipeline has profound implications for scalable data extraction from educational resources, which can potentially augment LLM training by providing extensive authentic human knowledge. As the method enables affordable and high-quality extraction, it addresses the bottlenecks posed by expensive manual data curation, reducing reliance on synthetic datasets prone to errors and hallucinations.
Future research directions should investigate leveraging the extracted QA data for aligning LLMs with curriculum-specific benchmarks that capture domain complexity and knowledge progression. Additionally, understanding difficulty scores and improving curation strategies could yield more robust datasets for training and evaluation. Studies focusing on diverse educational documents to benchmark reasoning-oriented LLMs represent another fertile area for exploration, potentially impacting educational technology and cognitive computing domains.
Conclusion
"FlipVQA-Miner" presents a compelling framework for cross-page visual QA mining from textbooks, significantly enhancing the extraction and usage of educational content for AI models. By unifying advanced OCR techniques with powerful LLMs, this approach facilitates scalable, precise data extraction for model supervision. The potential applications span training enhancements, performance benchmarking, and curriculum-aligned evaluations. Moving forward, enhancements in data curation and exploration of new domains will further cement the role of automated extraction methods in educational AI systems.