- The paper presents a diffusion-based triplane reposing method for text-to-4D avatar synthesis, ensuring high-fidelity geometric consistency and temporal coherence.
- The approach decomposes synthesis into stages—static avatar generation, skeleton-driven motion encoding, and U-Net-based diffusion—reducing generation time to 36 seconds for 14 frames.
- The method outperforms traditional techniques by addressing artifacts like the 'jelly effect' and delivering state-of-the-art perceptual and geometric metrics.
TriDiff-4D: Fast 4D Generation through Diffusion-based Triplane Re-posing
Introduction and Motivation
TriDiff-4D introduces an efficient generative pipeline for direct text-to-4D avatar synthesis via diffusion-based triplane reposing (2511.16662). The method is designed to overcome persistent issues in prior 4D generation approaches: temporal and geometric inconsistencies, perceptual artifacts, motion irregularities, high computational cost, and constrained control over motion dynamics. Conventional pipelines relying on 2D image/video priors and optimization-based procedures manifest artifacts such as the "Janus problem" and "jelly effect," limiting geometric fidelity and animation realism.
TriDiff-4D explicitly incorporates learned priors over 3D structure and motion, enabling skeleton-driven 4D avatar generation that is temporally coherent and anatomically accurate, with significant speedup in generation time. The architectural design decomposes 4D synthesis into three tractable stages—static avatar generation in canonical pose, skeletal motion generation from text, and diffusion-based integration of avatar and pose sequences—thereby enabling single-pass, control-rich avatar animation.
Methodology
TriDiff-4D operates in three stages to disentangle structure modeling and motion control, recombining these components in a conditional diffusion process:
- Triplane Avatar Generation: A triplane-based diffusion model creates high-fidelity 3D avatar features from textual descriptions, decomposing geometry and color to optimize independently for structural and appearance consistency. The output triplane feature maps represent the avatar in three orthogonal planes, accommodating subsequent pose transformations.
- Skeleton-driven Motion Encoding: Text prompts specifying desired motion are transformed into 3D skeletal sequences using a transformer-based text-to-motion model. Skeleton data is projected into triplane-compatible 2D maps (occupancy and normalized index maps for each plane), providing rich spatial priors for subsequent conditional diffusion.
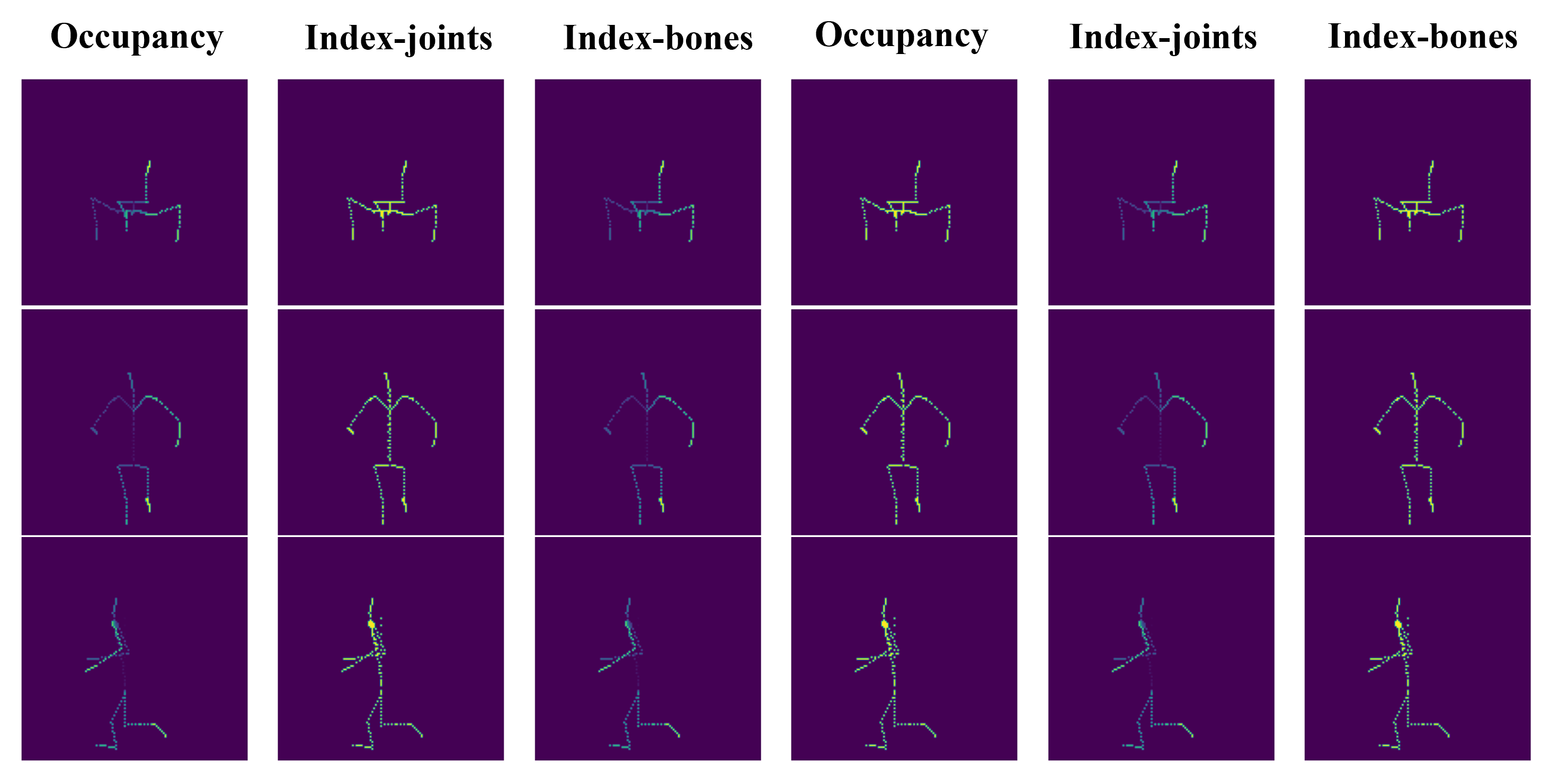
Figure 1: Triplane skeleton encoding yields occupancy and index maps projected onto XY, XZ, YZ planes, facilitating spatially aligned pose conditioning.
- Diffusion-based Reposing: Initial triplane avatar features and the sequence of skeleton encodings form the conditioning input for a U-Net-based conditional diffusion model. Spatial alignment between features and pose priors is achieved via direct concatenation or through multi-resolution cross-attention mechanisms. These architectures allow precise joint-to-feature mapping, reducing pose transfer artifacts and preserving appearance.
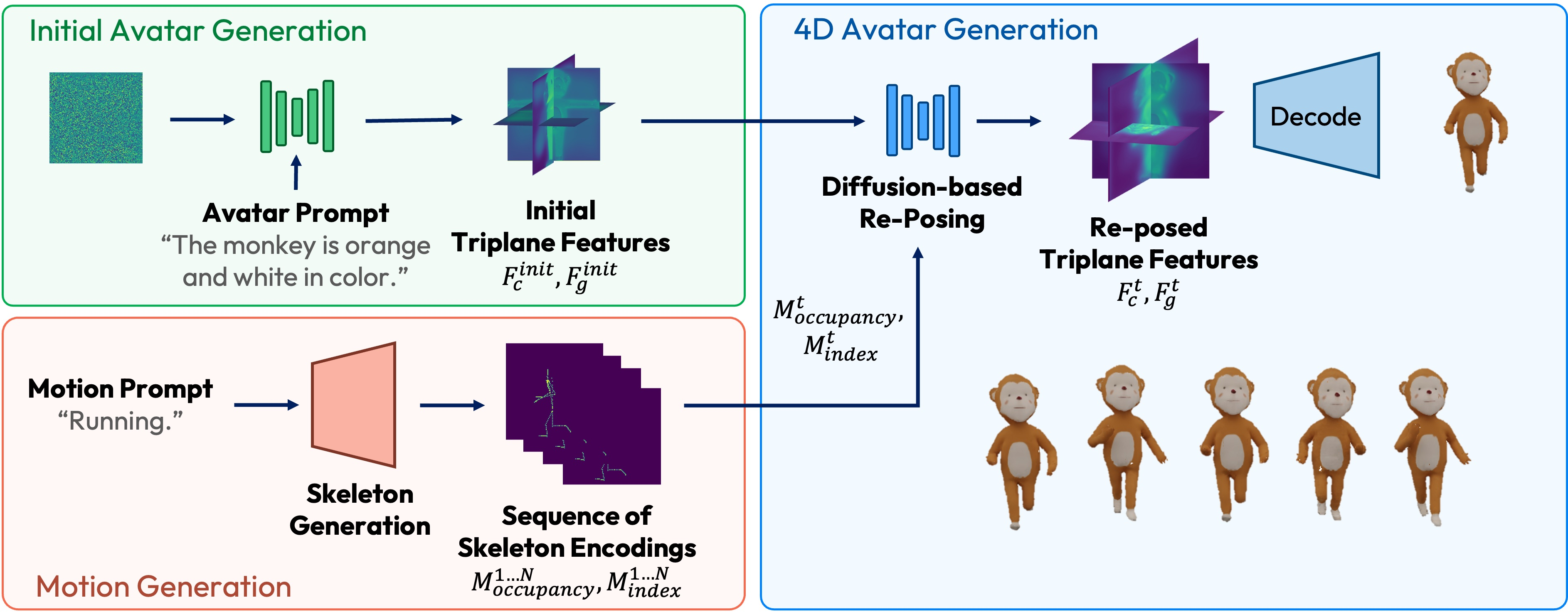
Figure 2: TriDiff-4D pipeline overview: triplane avatar generation, skeleton encoding, and diffusion-based reposing for pose-controlled animation.
Experimental Results
TriDiff-4D achieves compelling computational efficiency: it generates a 14-frame 4D mesh sequence in just 36 seconds on a single H100 GPU, compared to hours required by optimization-based competitors.
On perceptual and geometric metrics (Consistent4D benchmark), the method delivers competitive FVD (626.29), LPIPS (0.13), and CLIP (0.94) scores, outperforming or matching state-of-the-art baseline models. User study results confirm strong preferences for TriDiff-4D on motion and geometry consistency (86.73% and 56.12%, respectively) and overall visual and animation quality (79.59%).

Figure 3: Comparison of running motions. TriDiff-4D maintains geometric proportions during high dynamic movements, eliminating unrealistic "jelly effect" stretching.

Figure 4: TriDiff-4D versus MAV3D. Enhanced articulation, scene quality, and consistent appearance across frames.
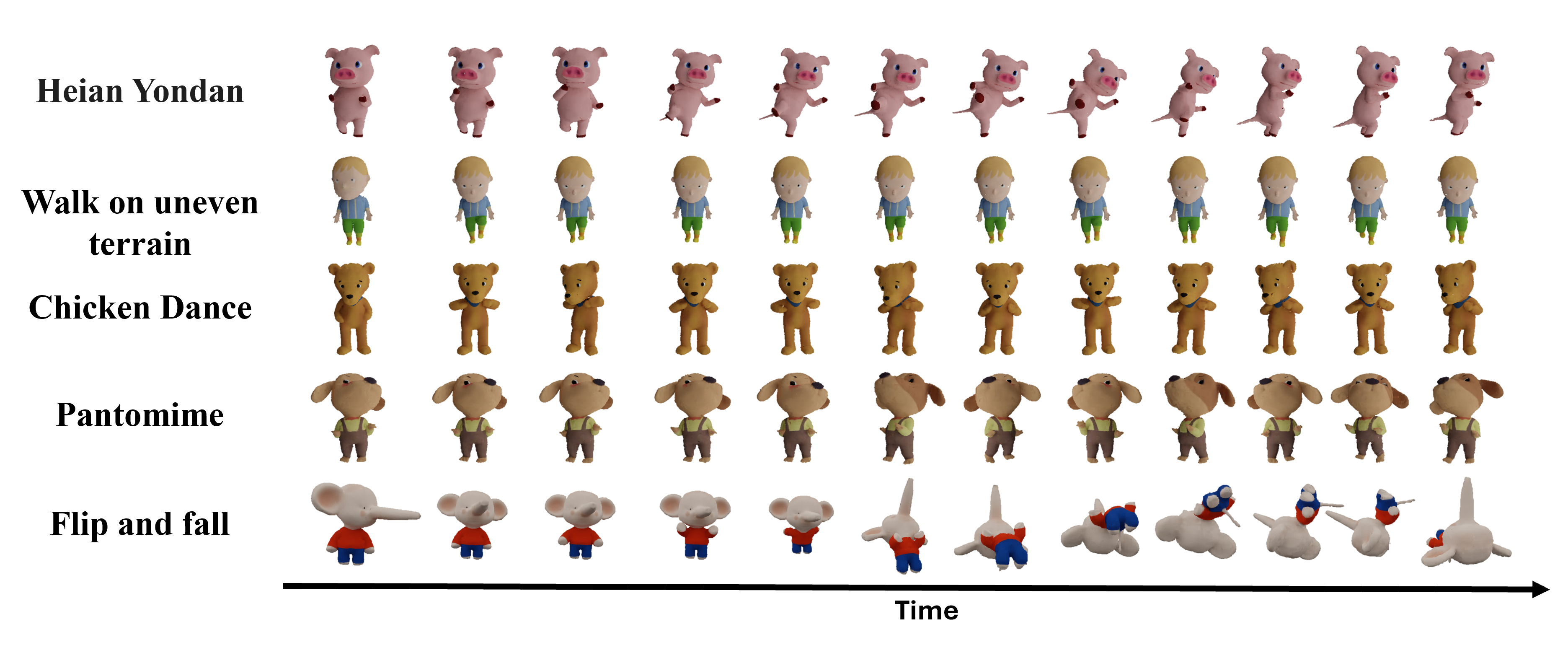
Figure 5: TriDiff-4D generates extreme pose transitions and complex motions, preserving geometry and appearance.
Ablation studies show that index-based skeleton encoding yields materially sharper structural localization than heatmap approaches, which leads to decreased pose and appearance quality due to weakened joint connectivity representation.
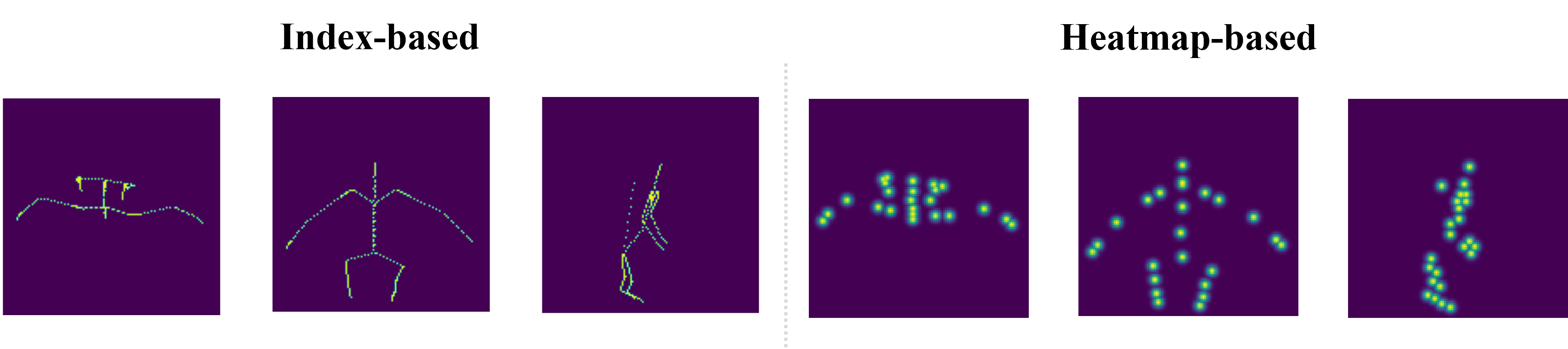
Figure 6: Skeleton encoding comparison—index-based (left) maintains discrete joints, heatmap-based (right) produces smoother and less precise localization.
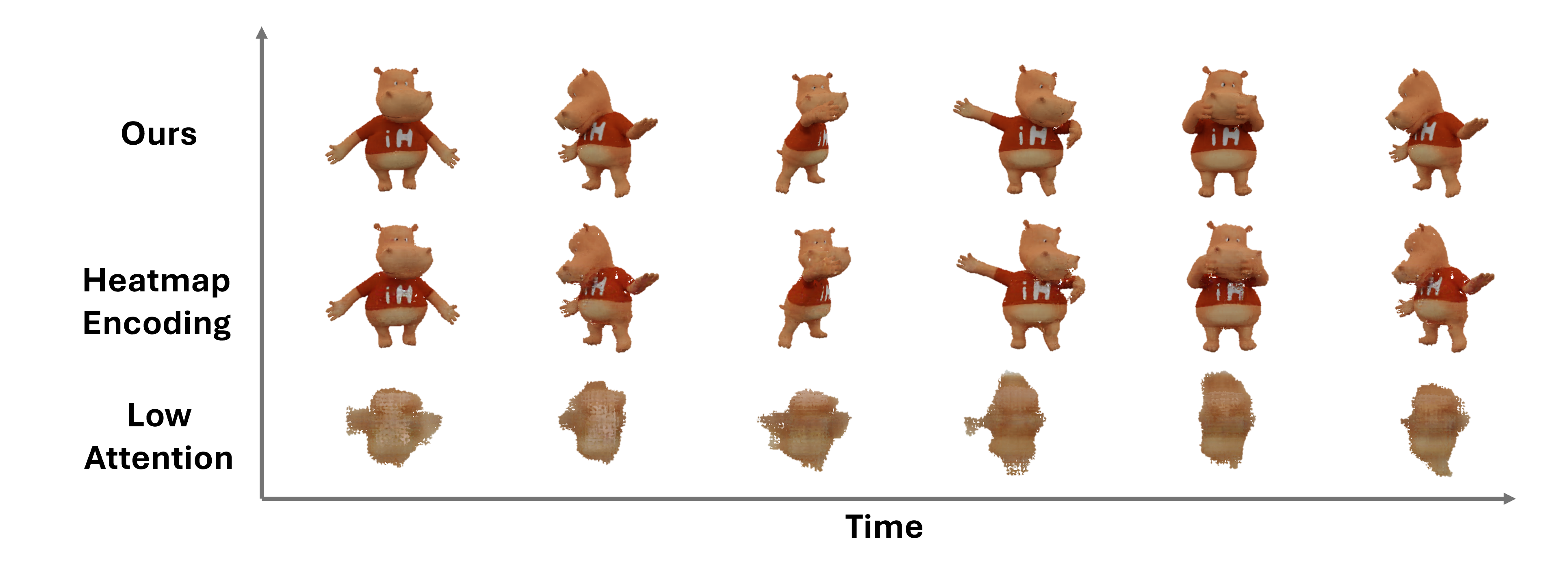
Figure 7: Effects of skeleton encoding and attention resolution on generated avatar quality in ablation study.

Figure 8: Triplane feature alignment with skeleton across sequential time steps, confirming preserved structure and appearance fidelity.
Practical and Theoretical Implications
TriDiff-4D redefines text-to-4D avatar synthesis with skeleton-guided, triplane-conditioned diffusion, offering several distinct advantages:
- Temporal and Volumetric Consistency: Direct 3D skeleton conditioning in triplane space sustains volumetric appearance and eliminates artifacts across frames and viewpoints, addressing Janus and jelly problems.
- Efficiency and Scalability: Non-iterative forward passes and triplane representations drastically accelerate 4D avatar generation, enabling real-time workflows and scalable deployment in content production for games, animation, and XR.
- Modularity and Controllability: Separation of appearance and pose priors allows fine-grained, flexible control for animation, compatible with diverse rendering engines (NeRF, Gaussian Splatting).
Further research is indicated in extending the model for articulated non-human avatars and clothing dynamics, which are currently limited by dataset availability. The future integration of advanced generative paradigms such as flow matching and scalable transformer-based diffusion holds promise for increased diversity, realism, and efficiency.
Conclusion
TriDiff-4D establishes a new paradigm for controllable, efficient 4D avatar generation. Through diffusion-based reposing in triplane feature space conditioned on skeleton sequences, the pipeline attains high levels of motion realism, volumetric consistency, and appearance fidelity with practical computational demands. The framework's modularity and scalability point toward widespread application in dynamic 3D content creation and animation, with theoretical impact on generative model design for temporally evolving 3D assets.