- The paper presents a scalable, KG-guided framework that bypasses expensive human annotation by using controlled semantic perturbations.
- The paper details a four-stage pipeline—subgraph sampling, targeted perturbation, LLM-driven generation, and textual validation—to ensure semantically faithful output.
- The paper’s evaluation reveals that while LLM-based methods excel at relational perturbations, embedding techniques perform better for entity-level changes, highlighting domain adaptation challenges.
Semantic-KG: Knowledge Graph-Guided Benchmarking for Semantic Similarity
Introduction
Semantic similarity evaluation is the cornerstone of robust assessment for LLM-generated text, especially where surface correspondence (syntactic or lexical overlap) frequently diverges from actual semantic content. Prevailing methods such as BLEU, ROUGE, and embedding-based similarity provide approximate surrogates but remain vulnerable to superficial cues and fail to ensure true semantic alignment. The construction of semantic similarity benchmarks is typically bottlenecked by domain expertise requirements, annotation cost, and subjectivity in "semantic equivalence" definitions.
"Semantic-KG: Using Knowledge Graphs to Construct Benchmarks for Measuring Semantic Similarity" (2511.19925) introduces a scalable, domain-adaptable methodology for constructing precise benchmarks for semantic similarity, bypassing expensive human judgments by leveraging knowledge graphs as formal ontological scaffolds for controlled semantic perturbations.
Framework: Automated Benchmark Construction via Knowledge Graph Perturbation
The Semantic-KG framework consists of four mechanistic stages: (1) subgraph sampling, (2) targeted perturbation, (3) LLM-driven statement generation, and (4) KG-centered textual validation.
After a diverse subgraph is sampled from a domain knowledge graph, a controlled perturbation is applied—node/edge removal or replacement—which induces defined semantic deviation. LLMs then synthesize natural language statements from these subgraphs, yielding pairs with known degrees and types of semantic divergence. Output statements are rigorously validated by reconstructing the originating subgraph (post-lemmatization and normalization) from the generated text to retain only semantically faithful instances.
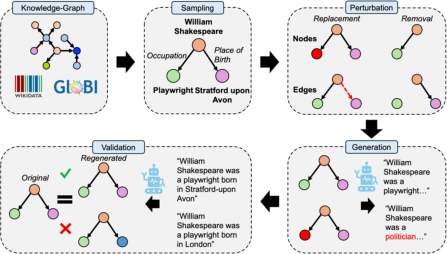
Figure 1: A schematic overview of the Semantic-KG pipeline, explicating sampling, perturbation, generation, and rigorous validation against knowledge graph structure.
This pipeline is applicable to any domain with a high-quality KG and obviates the need for ambiguous or expensive human-annotated similarity labels.
Given the generated corpus, the central task is to predict the binary semantic similarity (equivalent vs. nonequivalent) for a pair of statements. Positive pairs are derived from distinct generations using the same subgraph; negative pairs are those where one member is induced from a perturbed subgraph.
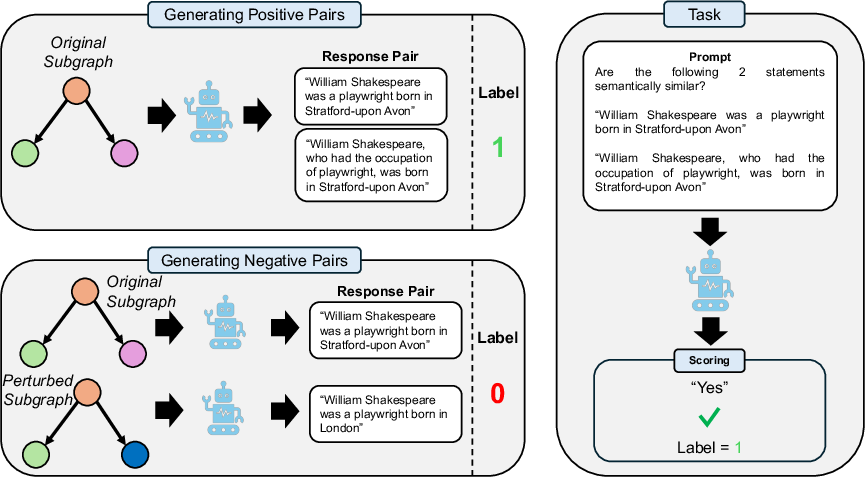
Figure 2: The task schematic: positive pairs derive from a single subgraph, negative pairs from an original and perturbed variant, stratified by perturbation type.
Semantic-KG provides instantiations across four domains:
- Codex: General knowledge (Wikidata-based)
- Oregano: Biomedicine
- FinDKG: Finance
- Globi: Biological interactions
Experimental Evaluation and Insights
The evaluation encompasses three methodological families: LLM-as-a-judge, state-of-the-art sentence embedding models, and traditional NLP metrics. LLM-based methods involve direct binary similarity judgment; embedding models compute cosine similarity, and classic metrics like ROUGE/BLEU are thresholded on F1-optimal splits.
Performance is measured globally and stratified by perturbation type and dataset domain.
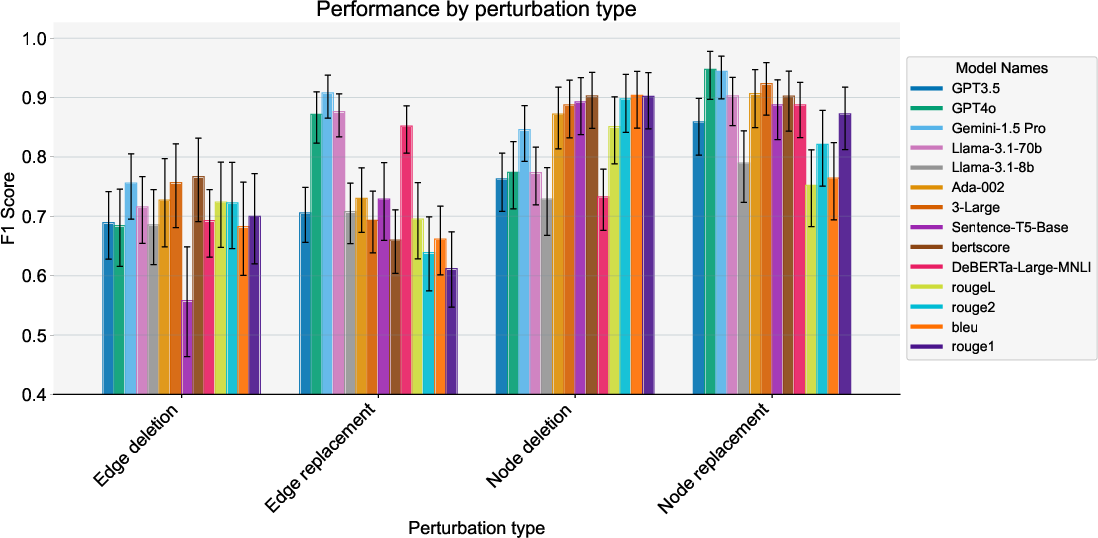
Figure 3: F1 Score performance by perturbation type—a clear performance heterogeneity depending on the type of semantic edit applied.
LLM-based methods generally outperform non-LLMs for edge-level perturbations—relationship modifications—but not consistently for node-level (entity set) changes. Notably, for node removals and replacements, embedding approaches (e.g., Sentence-T5-Base) often outperform LLMs, as confirmed by significant interaction effects: for Sentence-T5-Base, node-removal (β=0.260, p=0.002); for GPT-4o, edge-replacement (β=0.184, p=0.031).
When results are stratified by domain, performance degradation is prominent for specialized datasets, particularly the Globi and FinDKG cases, where even high-performing LLMs can falter, and embedding methods (BERTScore) sometimes display superior robustness.
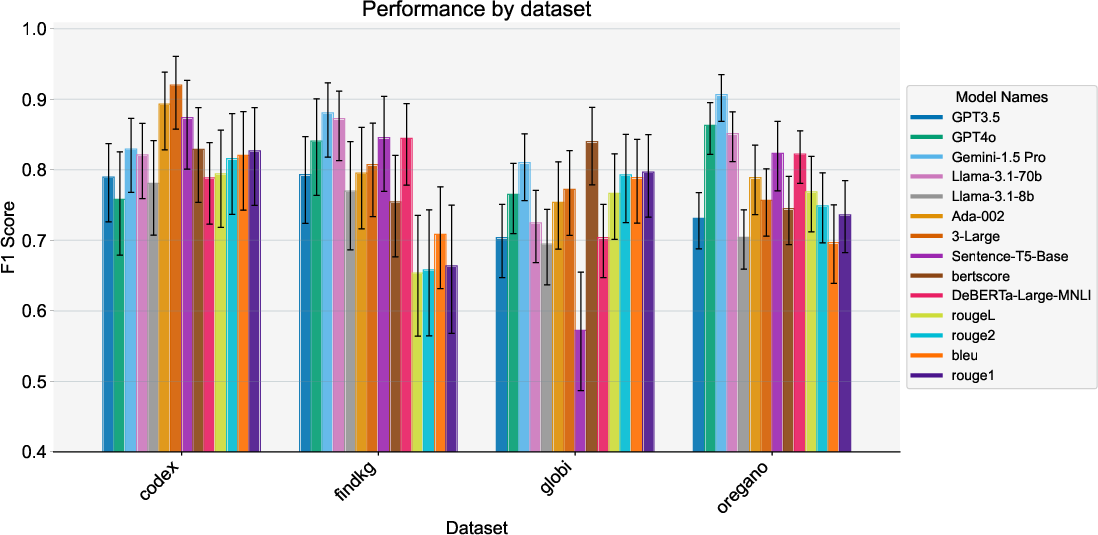
Figure 4: Cross-domain F1 Scores for semantic similarity methods, evidencing robustness variance and domain-adaptation challenges.
Dataset Validation
The authors further validated sampled data for factual correctness (manual spot-check: 99% correctness) and assessed "naturalness" (75% passing rate) via human annotation. A subgraph-to-text-to-subgraph reconstruction metric was established, with validated outputs filtered for exact triple-match equivalence, ensuring the benchmark’s structural precision.
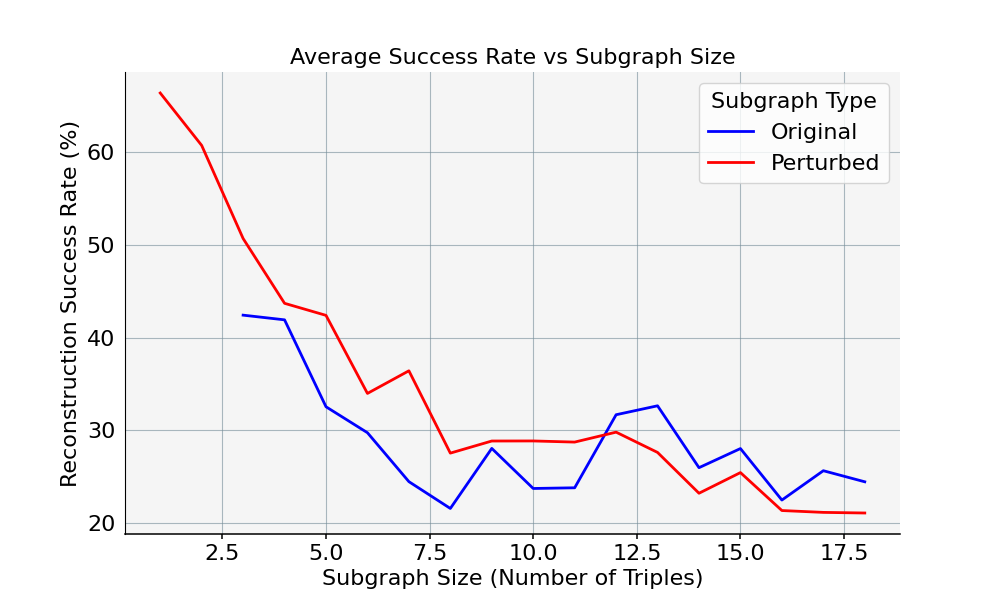
Figure 5: Reconstruction accuracy as a function of subgraph size quantifies reliability of the generation-validation cycle.
Implications and Future Prospects
A key implication is that LLM-based evaluation cannot be considered universally optimal for semantic similarity, particularly outside synthetically simple or general knowledge settings. Embedding-based approaches remain competitive for entity-set focused applications, whereas LLMs provide value in tasks sensitive to relational content. Thus, claim selection of an evaluation method must consider both the nature of semantic variations (entity-centric vs. relation-centric) and the target knowledge domain.
Domain shift substantially impacts method generalizability—domain-specific tuning or benchmarking is indispensable before critical deployments (e.g., in biomedical or financial NLP pipelines).
Practically, the open-source nature of the pipeline enables the rapid construction of domain-new benchmarks, supporting downstream tasks such as RAG re-ranking or LLM output verification with minimal annotation burden.
Theoretically, the work substantiates a hybrid methodology for evaluation: combinatorial KG-based perturbation provides formal semantics for both positive and negative sample construction, addressing annotation subjectivity and offering fine-grained control over semantic variation typology.
Limitations
The pipeline is contingent on the availability and quality of source KGs, which may not exist for all domains or may encode knowledge under closed world assumptions. The classes of perturbations—while controllable—cannot capture all pragmatic nuances of meaning (e.g., implicature, tone, or world knowledge outside graph structure). Reliance on LLMs for text generation and validation induces potential train-data and modeling distribution shift. The current framework privileges binary classification; extension to graded similarity remains for future work.
Conclusion
Semantic-KG provides a scalable, extensible paradigm for constructing semantically controlled benchmarks in any KG-equipped domain without dependence on costly human annotation. Detailed cross-method and cross-domain evaluations reveal crucial performance gaps in current semantic similarity methods, especially for relational content and specialized domains. The framework will catalyze more nuanced and domain-adaptive benchmark design, sharpening both the evaluation and the subsequent deployment of LLM-based and embedding-based NLP systems.
Dataset and code are available: GitHub, Huggingface dataset.