- The paper introduces a modular multi-hop reasoning framework that systematically verifies and corrects image captions for factual accuracy.
- It leverages entity extraction, knowledge graph navigation, and multi-format fact verification to reduce hallucinated entities by over 31%.
- Hierarchical tree representations provided superior spatial reasoning, enhancing overall caption coherence and entity accuracy.
Multi-Hop Reasoning for Factual Accuracy in Vision-LLMs
Motivation and Background
Vision-LLMs (VLMs) have achieved impressive generative capability for tasks such as image captioning but consistently suffer from factual inaccuracies and hallucinations. Unlike LLMs, where fact verification and multi-hop reasoning via external knowledge have seen substantial progress, VLMs lack analogous, explicit mechanisms for systematic fact verification and multi-modal logic inference. The absence of robust reasoning paths connecting visual perception to structured knowledge results in unreliable outputs, restricting VLM deployment in domains needing factual precision.
The authors present a modular multi-hop reasoning framework for VLMs which decomposes the verification process into sequential, interpretable components: entity recognition, knowledge graph traversal, multi-format fact verification, and adaptive caption correction. The system leverages structured knowledge—primarily knowledge graphs—in order to cross-validate factual claims and systematically refine captions, thereby reducing hallucinated entities and enhancing factual consistency.
Framework Architecture and Reasoning Pipeline
The pipeline is composed of five key hops, each modular and independently operable:
- Vision-Language Understanding: A pre-trained VLM (Qwen2-VL-2B-Instruct) generates base captions from images. Preliminary analysis reveals that 69% of entity mentions are hallucinated or incorrect at this stage.
- Entity Extraction Hop: Named entities are extracted from the caption via spaCy NER, targeting locations, organizations, and facilities. This structured output seeds downstream verification.
- Knowledge Graph Navigation: Each entity undergoes exact and fuzzy matching against a domain-specific knowledge graph. Fuzzy matching uses all-MiniLM-L6-v2 embeddings to boost recall for ambiguous or unseen entities. Entities are then partitioned into verified (V) and hallucinated (H) sets.
- Fact Verification: Relationships among entities are evaluated using three distinct knowledge representations—triple-based (subject, relation, object), hierarchical tree (ancestor-descendant), and bullet-point (attribute-value)—supporting robust multi-hop and cross-format validation.
- Caption Correction: Factual errors are corrected in the caption via prompt engineering; the output balances language fluency and logical coherence while integrating verified facts.
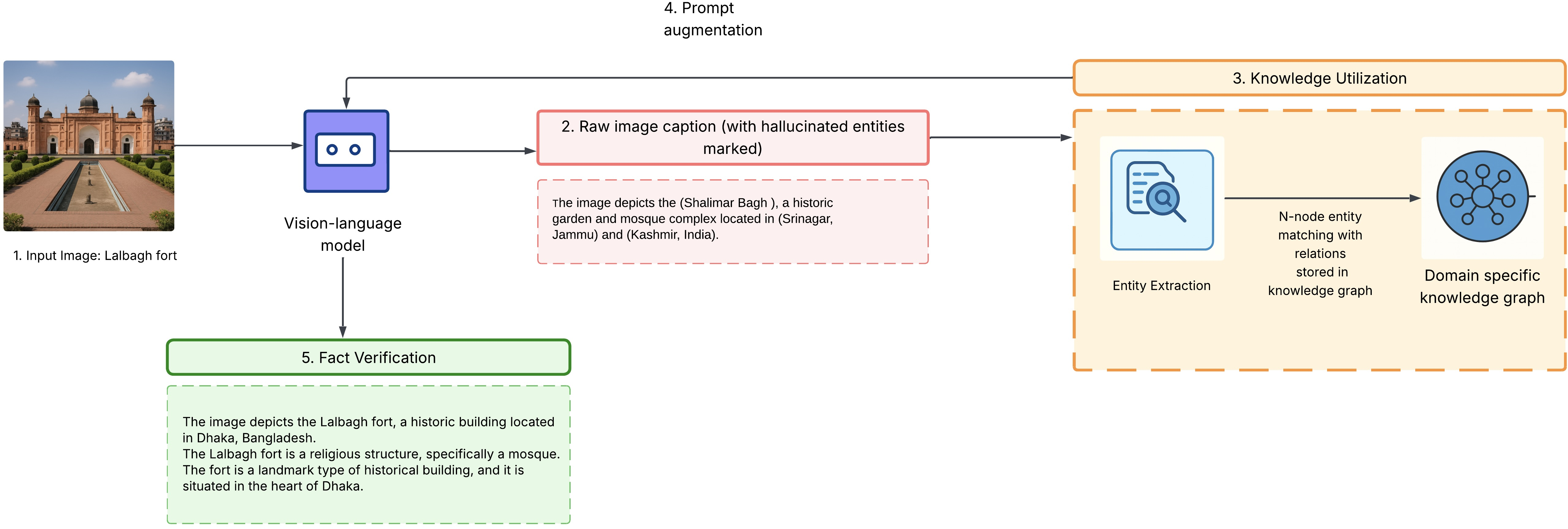
Figure 1: System pipeline for multi-hop reasoning in VLMs: input image to base caption, entity extraction, knowledge graph matching, and final caption correction.
This modular pipeline produces interpretable intermediate outputs and facilitates robust integration with additional knowledge sources or reasoning algorithms.
Knowledge Representation Analysis
Three formats of external knowledge are systematically compared:
- Triple-based Statements: Standard subject-relation-object triples excel for direct entity-relationship queries but fail for nested hierarchical reasoning.
- Hierarchical Trees: Nested structures capture spatial and containment information (e.g., location within geography) with high effectiveness for spatial verification tasks. However, they can incur computational cost for extended transitive inference.
- Bullet-point Attribute Lists: Attribute-value pairs yield rapid lookup and are particularly optimal for prompt-based correction but cannot model complex relationships.
Operationally, the verification routine queries triples first, uses hierarchies for containment checks, and bullet-points for attribute validation. Mixing formats led to a 27% reduction in hallucinated entities versus triple-only setups.
Empirical Evaluation
A mixed-domain dataset was curated, combining Google Landmarks v2, Conceptual Captions, and COCO Captions, with entities split as seen landmarks (60%), unseen or generalizing landmarks (20%), and distractor scenes (20%). Custom metrics quantified performance:
- Entity Accuracy (EA): The ratio of correctly matched entities and detected hallucinations against all entities mentioned.
- Fact Verification Rate (FVR): The proportion of claims precisely verified via knowledge representations.
- Caption Coherence (Cc): Human scoring of output fluency (1-5 scale).
Strong numerical results were reported:
Implications, Limitations, and Future Directions
The demonstrated reduction in hallucinated entities substantiates the efficacy of modular, knowledge-guided fact verification in VLMs. Practically, this establishes a pathway for reliable multi-modal systems in education, cultural archiving, and safety-critical deployments. The modularity further promotes extensibility across knowledge domains and different vision-LLM architectures.
The primary limitation is the manual curation and domain specificity of the current knowledge graph and dataset, constraining open-domain generalization and scalability. Further work will address large-scale dynamic knowledge integration, out-of-domain entity handling, and transferability across VLM models. Enhanced knowledge graph construction, automated knowledge base expansion, and robust evaluation benchmarks are identified as future research vectors.
Conclusion
This paper introduces a principled framework for multi-hop reasoning in VLMs, delivering interpretable fact verification via structured knowledge integration and modular pipeline design. The system achieves over 31% improvement in factual accuracy on image captioning, demonstrates technical superiority of hierarchical representations for spatial reasoning, and provides empirical ablation across knowledge formats. This work bridges the gap between multi-modal generation and knowledge-grounded logic, setting a foundation for factual, reliable vision-language systems.
