- The paper demonstrates that DeepSeek-R1 models achieve robust cohesion detection (F1-score up to 0.825) but experience significant performance drops for coupling in open-ended tasks.
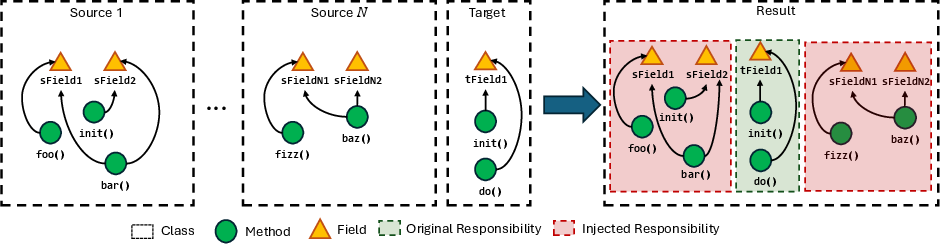
- The methodology uses controlled noise injection and varied prompting strategies based on cognitive load to simulate realistic software design challenges in Java code.
- Findings emphasize the need for enhanced reasoning frameworks to enable LLMs to autonomously handle complex software design evaluations.
Hierarchical Evaluation of Software Design Capabilities of LLMs of Code
Introduction
The rapid integration of LLMs in software engineering tasks has prompted researchers to assess their understanding of critical software design principles. The study "Hierarchical Evaluation of Software Design Capabilities of LLMs of Code" (2511.20933) seeks to elucidate the proficiency of LLMs in understanding two fundamental design principles: cohesion and coupling. This paper critically evaluates the DeepSeek-R1 model family (14B, 32B, 70B), identifying areas of strength and fragility in reasoning, particularly under varying levels of cognitive guidance and contextual complexity.
Methodology
This study employs a structured, multifaceted experimental approach encompassing several methodological steps:
Results
Basic Understanding
The results reveal that under optimal, low-noise conditions, the LLMs demonstrate a reasonable understanding of cohesion and coupling. The $70$B variant achieves an F1-score of up to $0.825$ for cohesion and $0.899$ for coupling, indicating a solid baseline capability for recognizing poorly designed code in simple contexts.
Cognitive Load Impact
Performance varies significantly with the level of guidance. As tasks progress from verification to open-ended generation, models exhibit increasing difficulty, particularly in scenarios requiring full autonomy. Notably, the $70$B variant's performance on coupling drops by over 31% between Verification and Open-ended tasks (Figure 2).
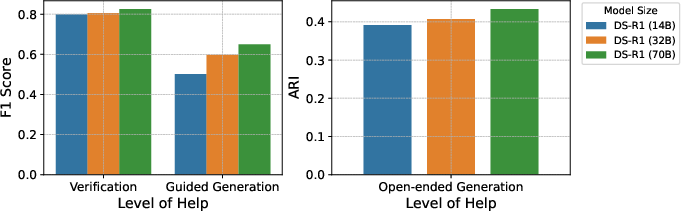
Figure 2: Impact of the cognitive load on the performance of each LLM on the cohesion experiments.
Robustness to Noise
Analysis underlines the models' susceptibility to contextual noise. Coupling tasks, where reasoning about inter-module dependencies is tested, reveal F1 scores plummeting by more than 50% as distortion ratios escalate. Conversely, models maintain stability on cohesion tasks, except in highly autonomous, noisy settings (Figure 3).
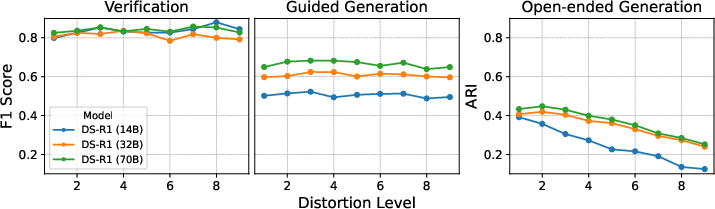
Figure 3: Performance of DeepSeek-R1 14B, 32B and 70B on the cohesion task under each distortion level.
Reasoning Trace Analysis
Cognitive shortcutting is evident in reasoning tasks, with models generating inexplicably shorter Chain-of-Thought traces in open-ended scenarios for coupling. In cohesion tasks, trace lengths increase with cognitive demand, reflecting an effort to grapple with complexity.
Implications and Future Directions
While LLMs exhibit foundational knowledge necessary to assist developers in maintaining code quality, the study identifies clear limitations in their reasoning capabilities, particularly in scaling complexity. This highlights the need for enhanced program understanding frameworks to guide LLMs in environments rich with contextual noise.
Future research should focus on extending these evaluations to other programming languages and paradigms, aiming to develop heuristics enabling LLMs to effectively manage combinatorial challenges. Further studies on leveraging these models for active problem-solving tasks, such as autonomous code refactoring, could reveal deeper insights into their potential roles in software engineering workflows.
Conclusion
The evaluation of DeepSeek-R1 models accentuates their current utility as powerful but constrained tools in software design, limited by their reliance on guidance and vulnerability to noise. Understanding and addressing these constraints marks a pivotal step toward enabling LLMs as fully autonomous software engineering agents.