- The paper demonstrates that intrinsic planning using text-only LLMs in the 8-puzzle yields low success rates and highlights model-specific bottlenecks.
- It details how structured prompting (CoT and AoT) and tiered feedback can improve performance while exposing limitations in state tracking and heuristic search.
- The study emphasizes that pure LLM agents lack robust goal-directed planning, underscoring the need for integrated state-management and search modules.
Limits of Innate Planning in LLMs: An Evaluation on the 8-Puzzle
Introduction
This paper systematically explores the intrinsic planning and stateful reasoning capacities of LLMs in environments demanding sequential goal-directed behavior, specifically within the constraints of the classic 8-puzzle domain. Unlike prior approaches that exploit external code execution or tool-based augmentation, this study evaluates pure model performance, isolating the language system's ability for autonomous plan formulation, state tracking, and heuristic search. Four models—GPT-5-Thinking, Gemini-2.5-Pro, GPT-5-mini, and Llama 3.1 8B-Instruct—are rigorously tested under standardized prompting protocols and structured feedback regimes. The investigation reveals critical bottlenecks in near-term LLM agentic utility.

Figure 1: The 8-puzzle evaluation pipeline directly assesses LLM state tracking and planning without external code.
Methods
Task Design
The 8-puzzle is selected for its well-defined rules, solvable state space (181,440 unique configurations), and tight coupling of state representation and planning. Models are provided with a random puzzle instance and must generate a legal sequence of moves leading to the canonical solved configuration, using only textual reasoning.
Prompting Strategies
Three major prompting regimes are benchmarked:
- Zero-Shot: Only rules and goal state are provided. No examples or stepwise cues.
- Chain-of-Thought (CoT): Three worked examples encourage stepwise reasoning.
- Algorithm-of-Thought (AoT): Three examples demonstrate search-based, Manhattan-guided trajectories.
Tiered Feedback
Failed attempts are iteratively retried using three feedback settings:
External Move Validator
In a final, more assisted regime, models are given a list of valid moves from the current state and are instructed to select the best one, absent the need for legality checks, but preserving the planning challenge.
Results
Aggregate analysis shows low success rates across models and conditions. Notably, GPT-5-Thinking achieves a 30% success rate in AoT, modestly outperforming others, while Gemini-2.5-Pro and Llama 3.1 8B-Instruct are almost entirely unsuccessful. Failure modes are predominantly invalid moves for all except Llama in CoT (which displays severe parse errors).
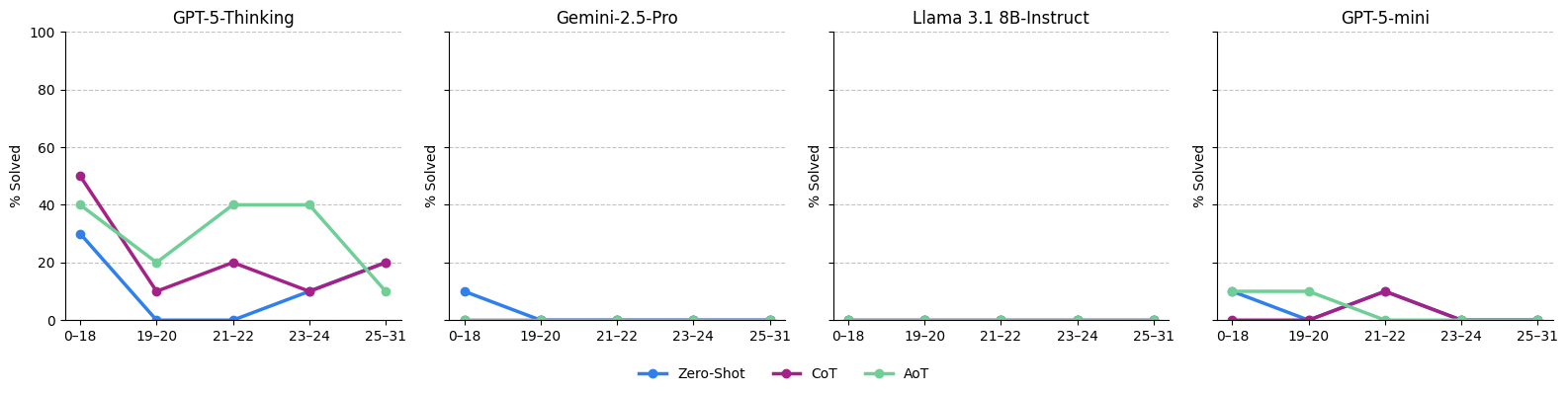
Figure 3: Success rates of each model and prompting regime stratified by puzzle difficulty; moderate-length puzzles do not correlate monotonically with performance.
Failure Mode Analysis
Looping and invalid moves are the dominant causes for episode failure, especially evident in the breakdown of termination outcomes. GPT-5-mini's performance deteriorates with more complex prompting, shifting increasingly to graceful failure (clarification requests).
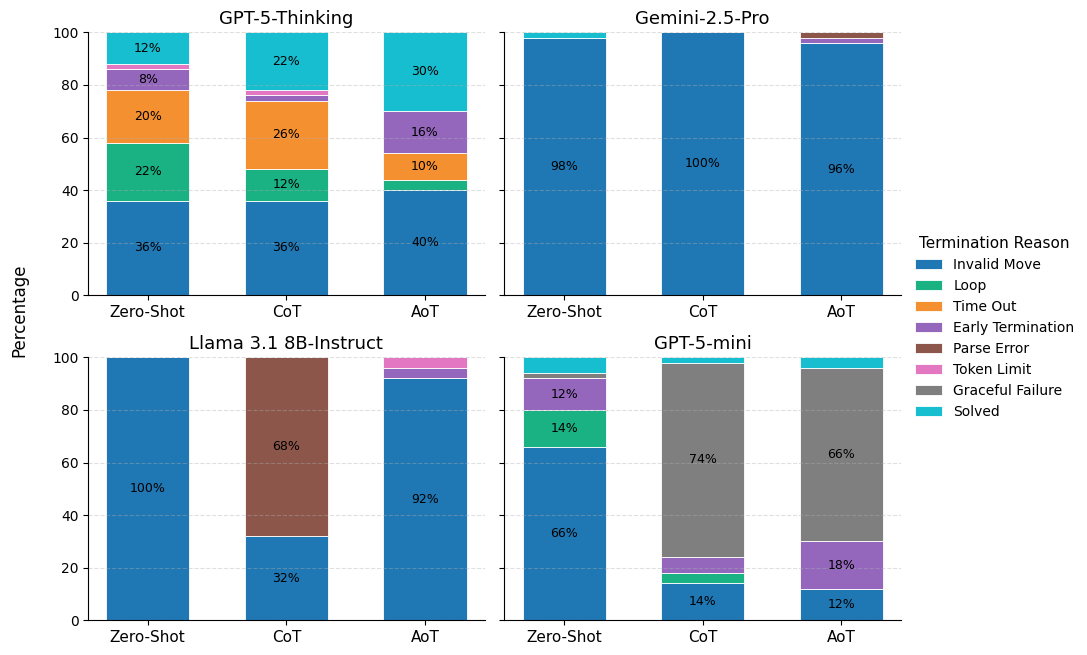
Figure 4: Stacked breakdown of trial outcomes reveals the varied impact of prompting on both success and distinct failure classes.
Feedback-Induced Gains
Introducing explicit feedback and progress-saving mechanisms yields enhanced rates. The strongest improvement is observed for GPT-5-Thinking under AoT with suggestive feedback, achieving a 68% success rate, but requiring significant computational and token budget (mean 24 minutes, 75,000 tokens, 49 moves per successful puzzle). For GPT-5-mini and Gemini-2.5-Pro, improvements are less pronounced (peaking at 18%), and further feedback sometimes inversely correlates with success.
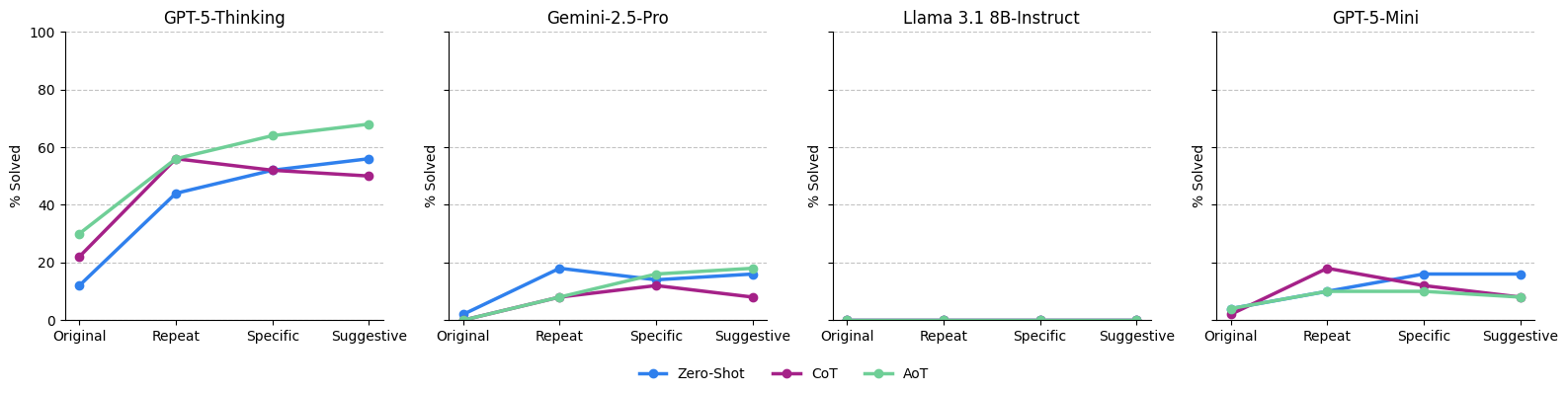
Figure 5: Success rates for prompting strategies as feedback granularity and repetition increase, showing non-monotonic effects.
External Move Validator: Planning Isolates
When state-tracking (invalid moves) is offloaded, none of the models can solve a puzzle, with looping becoming the universal failure mode (GPT-5-Thinking loops in 100% of trials). GPT-5-mini demonstrates persistent early termination after a large number of legal—but ultimately unproductive—moves, reflecting weak long-term planning heuristics.
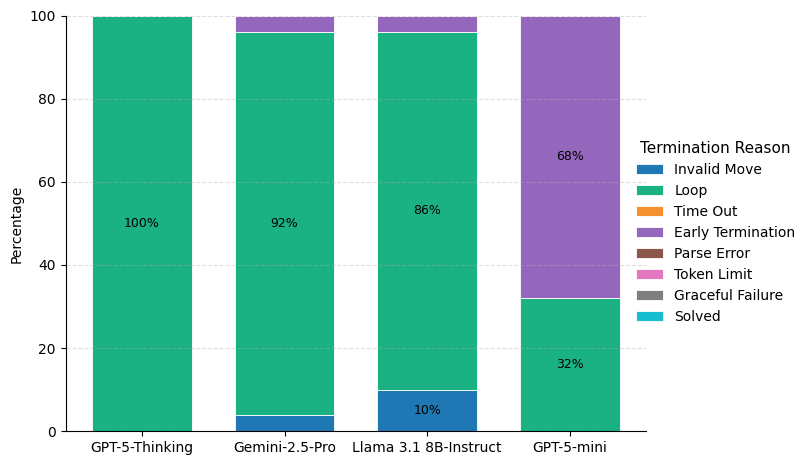
Figure 6: When restricted to valid actions, looping predominates, evidencing a failure of goal-directed planning heuristics.
Planning Efficiency
When valid moves alone are furnished, models make numerous moves with minimal state progress under Manhattan distance, confirming the lack of effective search strategies.
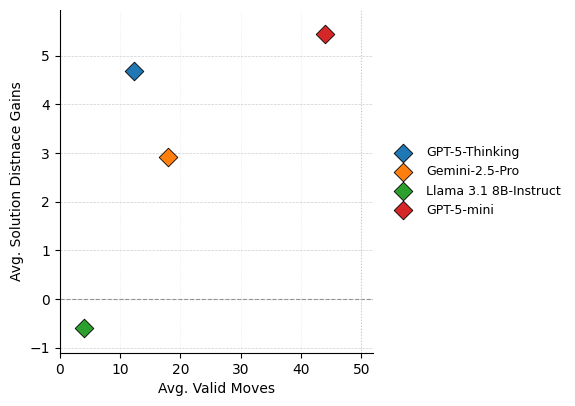
Figure 7: Comparative assessment between move count and solution progress quantifies inefficiency in planning when legality is guaranteed.
Discussion
This work presents a granular dissection of the innate planning and state-tracking ability in modern LLMs. Despite advances in prompt-based guidance (CoT, AoT), improvement is highly model-specific and can introduce new failures (parse errors, graceful refusals). Feedback and iterative retries boost success—especially for GPT-5-Thinking—but introduce prohibitive computational cost. The planning deficit becomes stark when state updates are outsourced: models overwhelmingly fail due to looping, unable to exploit even simple heuristics for goal attainment, underscoring brittle state representations and ineffective forward search.
The empirical results suggest two fundamental limitations:
- State Representation: LLMs frequently hallucinate or lose track of the true environment state, producing invalid or incoherent action proposals undetected by self-checks. This risk directly undermines reliability in agentic applications.
- Heuristic Planning: Absent tool augmentation, even SOTA models lack robust, goal-directed search strategies and cannot avoid cycles or random walks.
The observed disconnect between academic benchmark performance and planning underscores a gap between current LLM architectures and the demands of real-world autonomy. The unreliability and high confidence in flawed solutions indicate pressing safety concerns for tasks requiring sequential correctness (agentic robotics, financial trading, logistics).
Practical and Theoretical Implications
- Agentic AI Deployment: Pure LLM agents are currently unsuitable for tasks requiring robust stateful planning without external tool support. Confidence calibration and explicit state-maintenance mechanisms remain unsolved challenges.
- Prompt Engineering Limits: Advanced prompting is not universally beneficial and can induce confusion in certain architectures. Optimal prompting remains deeply dependent on model specifics and underlying representation capability.
- Search-Augmenting Modules: Future progress may require architectural or functional integration of explicit search and state-encoding modules, potentially merging symbolic and neural reasoning for agentic reliability.
- Self-Verification: Reliance on LLMs for high-confidence chain generation without error detection leads to undetectable mistakes propagating downstream.
Prospects for Future AI Systems
These findings indicate a need for research into explicit state-encoding, online self-verification (cf. (Stechly et al., 2024)), and planning modules that can endow LLMs with authentic heuristic search capabilities. Integration of symbolic reasoning or hybrid neuro-symbolic architectures may be required for reliable autonomous agents.
Conclusion
This study reveals that contemporary LLMs—both large and small—exhibit substantive deficiencies in innate planning and state tracking when deprived of external tools. Improvements via prompt and feedback engineering are costly and fail to achieve reliability, while outsourcing action validity exposes fundamental planning limitations. High-confidence error propagation remains a serious risk for agentic deployments. Closing these gaps will require architectural innovation targeting state maintenance and search.
Limitations
Results are constrained to the 8-puzzle domain and a set of 50 puzzles, with randomization minimizing but not guaranteeing against training contamination. Broader generalization to other sequential domains warrants further inquiry.

