CryptoBench: A Dynamic Benchmark for Expert-Level Evaluation of LLM Agents in Cryptocurrency
Abstract: This paper introduces CryptoBench, the first expert-curated, dynamic benchmark designed to rigorously evaluate the real-world capabilities of LLM agents in the uniquely demanding and fast-paced cryptocurrency domain. Unlike general-purpose agent benchmarks for search and prediction, professional crypto analysis presents specific challenges: \emph{extreme time-sensitivity}, \emph{a highly adversarial information environment}, and the critical need to synthesize data from \emph{diverse, specialized sources}, such as on-chain intelligence platforms and real-time Decentralized Finance (DeFi) dashboards. CryptoBench thus serves as a much more challenging and valuable scenario for LLM agent assessment. To address these challenges, we constructed a live, dynamic benchmark featuring 50 questions per month, expertly designed by crypto-native professionals to mirror actual analyst workflows. These tasks are rigorously categorized within a four-quadrant system: Simple Retrieval, Complex Retrieval, Simple Prediction, and Complex Prediction. This granular categorization enables a precise assessment of an LLM agent's foundational data-gathering capabilities alongside its advanced analytical and forecasting skills. Our evaluation of ten LLMs, both directly and within an agentic framework, reveals a performance hierarchy and uncovers a failure mode. We observe a \textit{retrieval-prediction imbalance}, where many leading models, despite being proficient at data retrieval, demonstrate a pronounced weakness in tasks requiring predictive analysis. This highlights a problematic tendency for agents to appear factually grounded while lacking the deeper analytical capabilities to synthesize information.

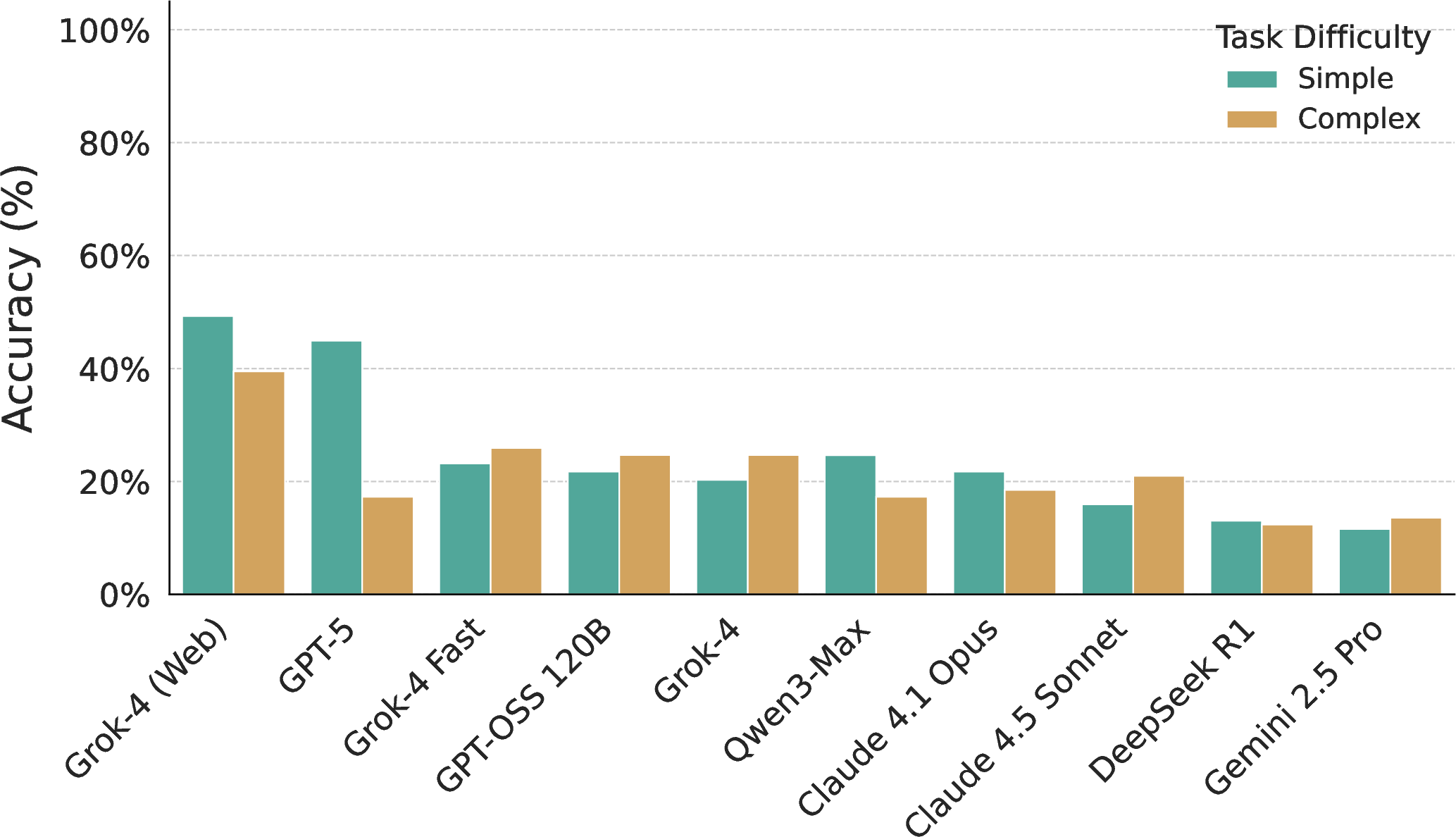
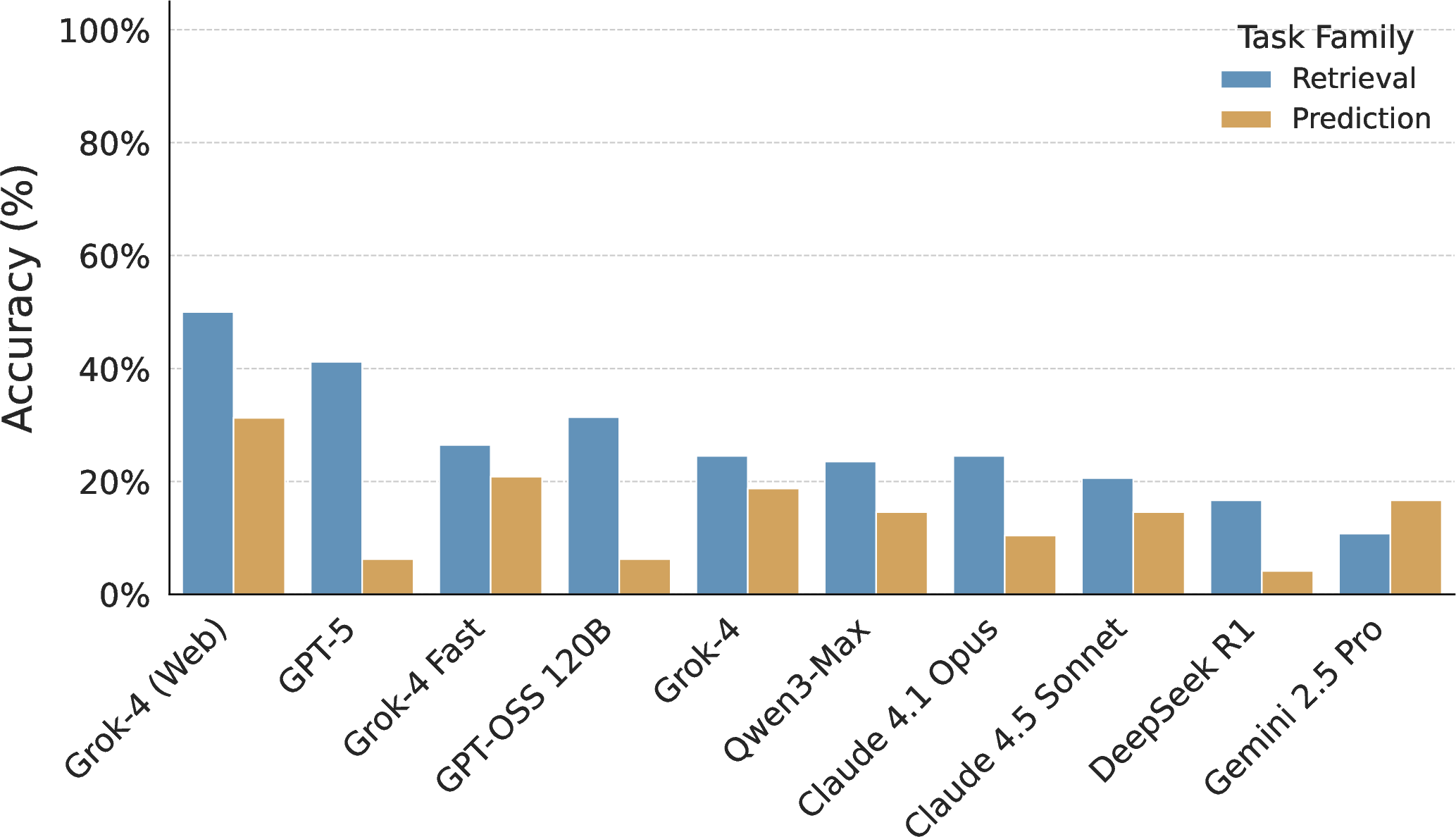
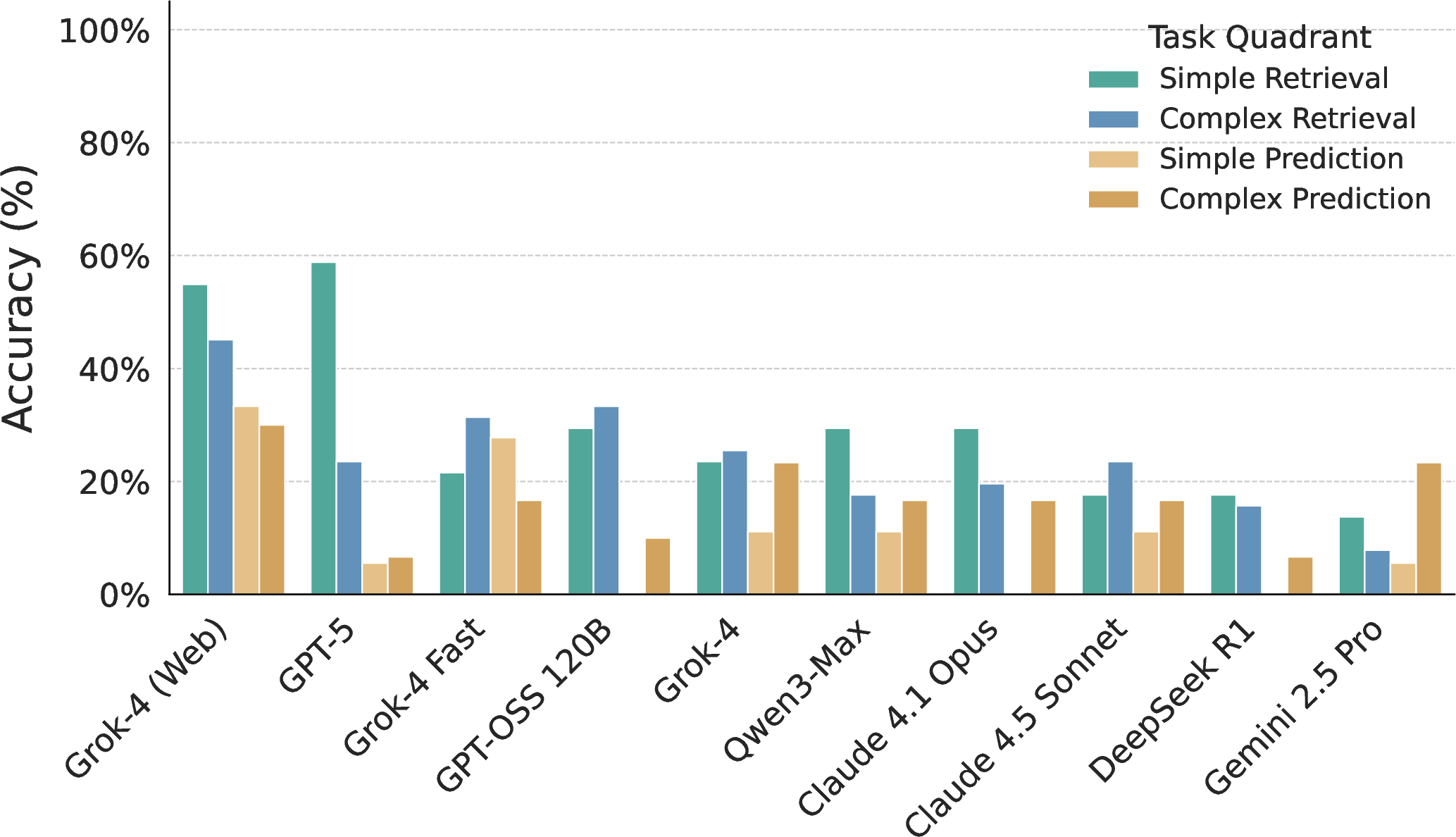

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces CryptoBench, a new kind of “real-world test” for AI agents that work with cryptocurrency. Think of it like an advanced, constantly updated exam that checks whether AI can:
- find the right facts on live crypto websites,
- combine information from different places,
- and make sensible short-term predictions in a fast-moving, sometimes misleading online environment.
Unlike many tests that use static pages or old data, CryptoBench runs on the live internet and is updated every month so the questions stay fresh and relevant.
What questions did the researchers ask?
The researchers focused on a few simple, important questions:
- Can today’s AI agents handle real crypto tasks that change quickly and require expert knowledge?
- Are AIs equally good at finding facts and making predictions, or are they unbalanced?
- Does putting a model inside an “agent” setup (giving it a web browser tool and a plan) make it better?
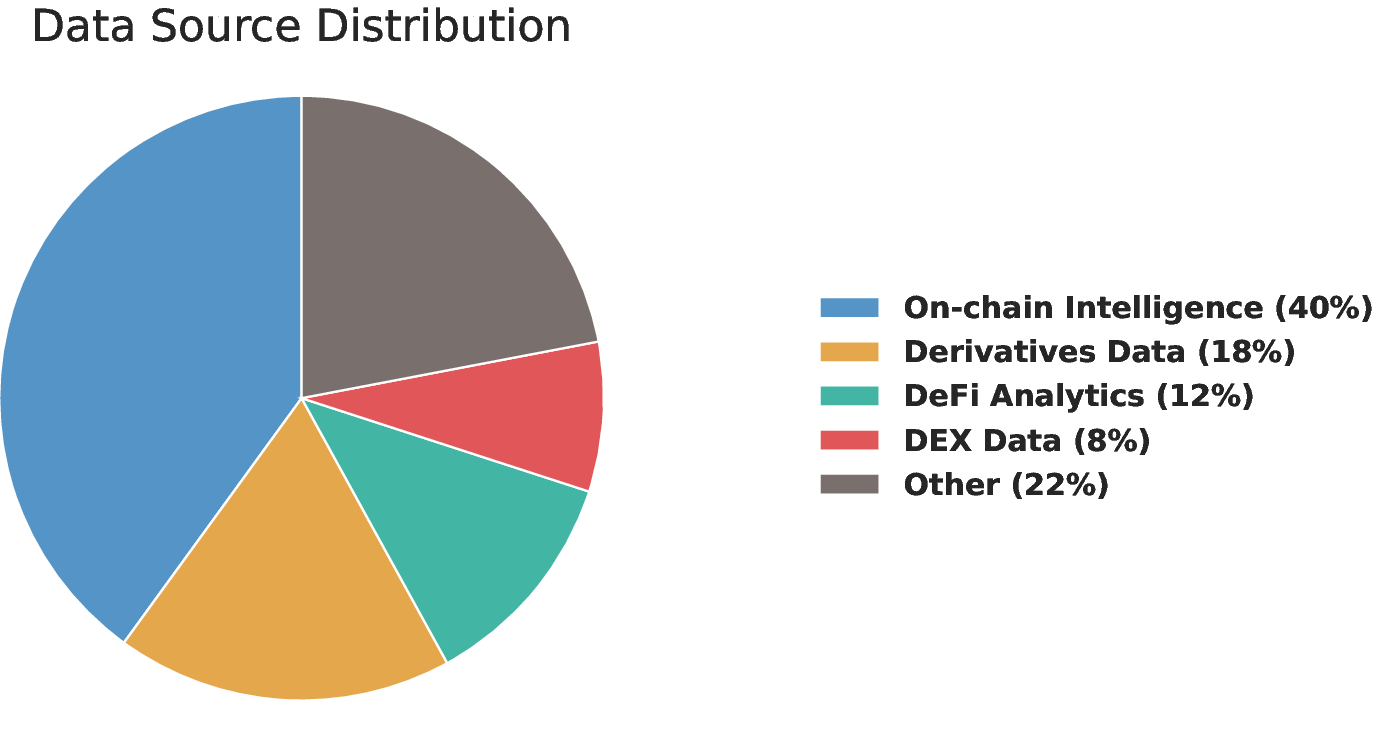
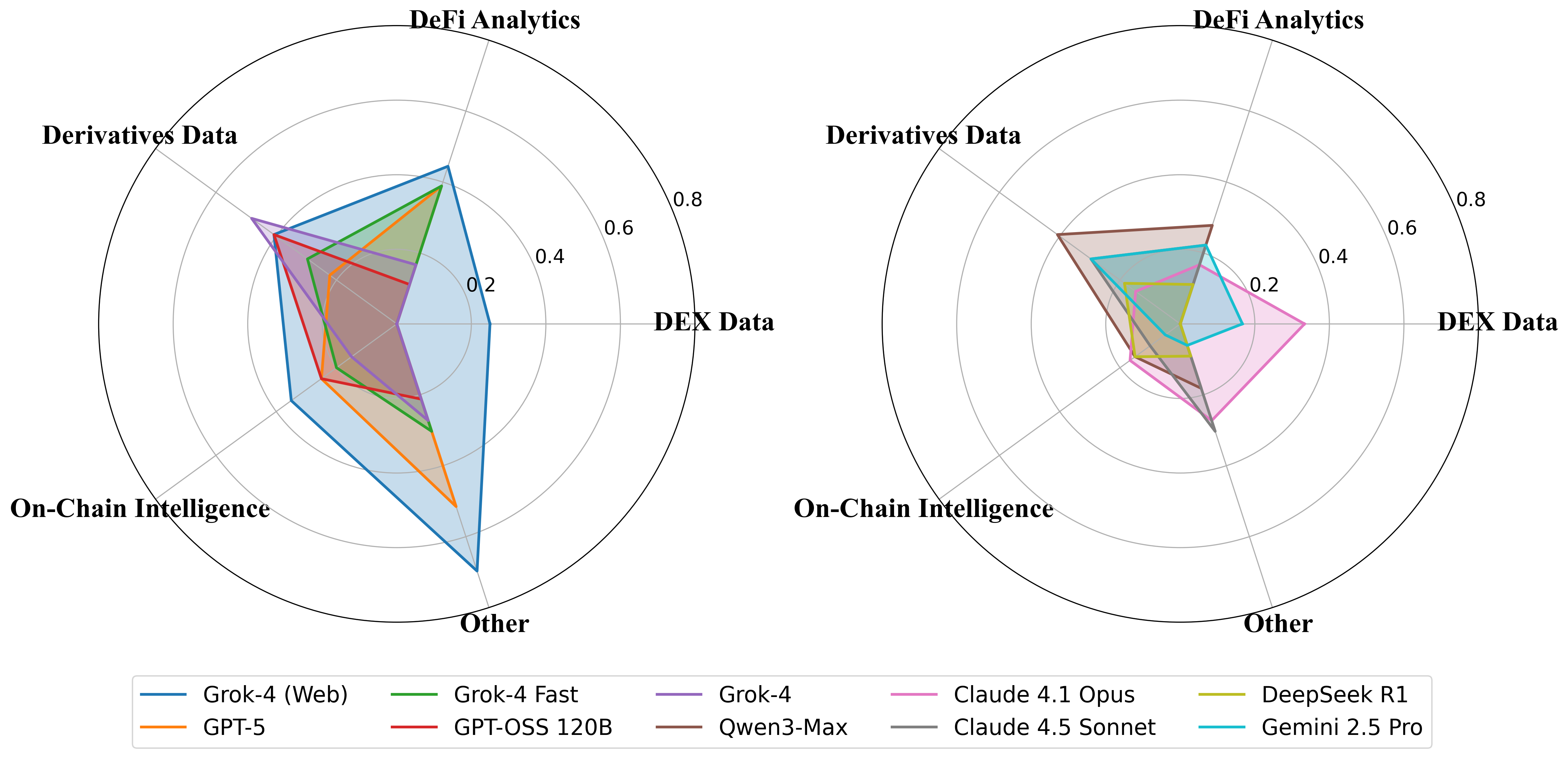
- Which kinds of crypto tasks are hardest (like on-chain wallet analysis, DeFi dashboards, or derivatives data)?
- Can we score these tasks fairly and automatically without needing a human every time?
How did they study it?
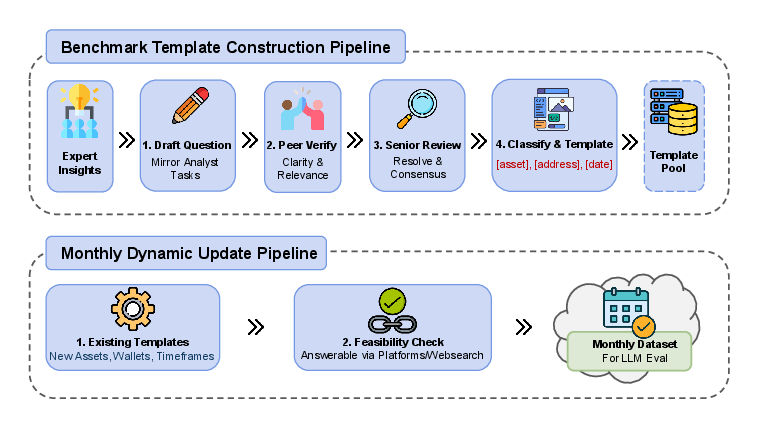
They built CryptoBench using expert-designed tasks and a clear scoring system:
- Expert-made, real tasks: Crypto analysts (like DeFi researchers and on-chain investigators) wrote questions that match what professionals actually do. Examples include checking whale wallet activity, reading real-time dashboard numbers, and judging short-term risks.
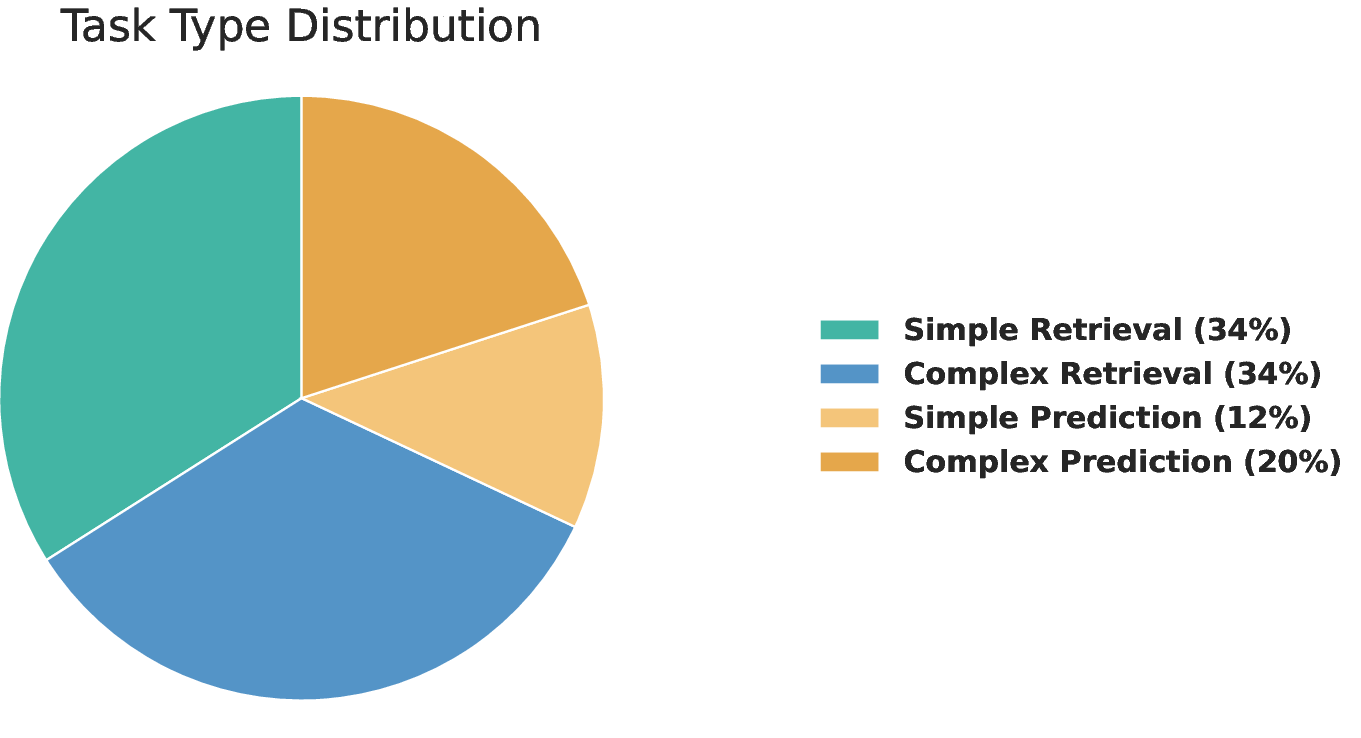
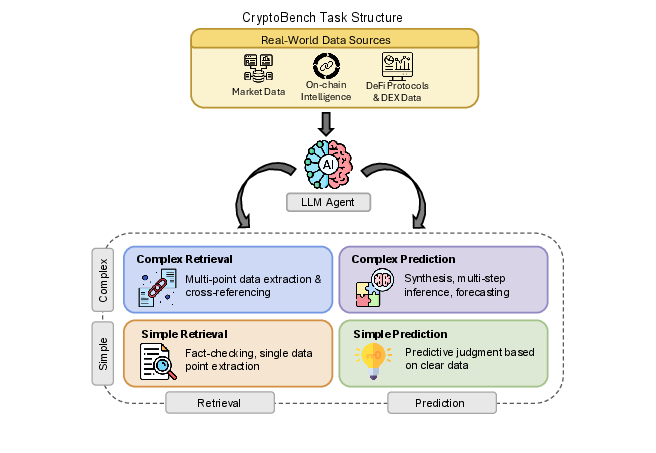
- Four types of tasks (the “four quadrants”):
- Simple Retrieval: find one specific fact (like a token’s current 24h volume).
- Complex Retrieval: gather and combine several facts (like listing top liquidity pools and their yields).
- Simple Prediction: make a basic judgment from a small clue (e.g., will a big token unlock likely push price down soon?).
- Complex Prediction: make a multi-step forecast using info from several places (e.g., compare two projects’ tokenomics and predict which will attract more long-term investors).
- Dynamic and monthly: About 50 new questions are added each month. Key details (like wallet addresses or time ranges) change so models can’t just memorize answers.
- Real tools and data: Tasks require visiting live platforms (blockchain explorers, DeFi dashboards, market data sites) and dealing with messy, constantly changing information.
- Quality control: Every question goes through a three-step check (author, validator, and adjudicator) to make sure it’s clear, answerable, and has a reliable source.
- How they scored answers:
- They used an “LLM-as-a-judge” approach—another AI model grades the response with a simple 0–3 rubric:
- 3 = completely correct, 2 = mostly correct, 1 = partly correct, 0 = wrong or irrelevant.
- For numbers that change quickly (like prices), they allow a small wiggle room (±5%).
- They report an overall “Average Success Rate” so you can compare models easily.
- Models tested: Ten well-known LLMs were evaluated two ways:
- “Direct” mode (just ask the model).
- “Agent” mode (wrap the model in a small agent framework with web-browsing tools).
Simple analogy for key terms:
- Benchmark: a standardized test.
- LLM agent: an AI that can plan steps and use tools (like a web browser) to solve tasks.
- On-chain data: the public record of transactions written directly on blockchains (like a shared online ledger).
- DeFi dashboards: live webpages that show the latest stats for crypto protocols (like scoreboards for apps that run on blockchains).
- Agent framework: giving the AI a “browser and mouse” plus a plan so it can click, read, and extract information.
What did they find?
- Big gap between finding facts and making predictions:
- Many top models were pretty good at retrieval (finding and quoting numbers) but much worse at prediction (using those numbers to forecast or judge risk).
- Even the best model answered under half of all questions perfectly in direct testing—showing how hard these tasks are.
- Simple tasks were easier than complex ones:
- Performance dropped when tasks needed multiple steps or combining several sources.
- The agent setup changed rankings:
- Some models did better when given a browsing tool and a plan, and the order of “best to worst” shifted. This means raw intelligence doesn’t automatically translate to good real-world performance—tool use and planning matter.
- Specialized crypto tasks are tough:
- Models did better on general info and struggled more with deep on-chain analysis, DEX data, and advanced DeFi metrics.
- Common failure patterns:
- Shallow search: Using the first result (like an old blog post) instead of the official, live dashboard.
- Stale info: Reporting outdated numbers in fast-moving markets.
- Integration errors: Fetching the right facts but combining them wrong (like mixing up who outperformed whom).
- Prediction hallucination: Making confident stories or forecasts that aren’t grounded in the actual data found.
Why this matters:
- In crypto (and finance), it’s not enough to just find facts. You need to reason about them quickly and correctly. The benchmark shows today’s AI often looks “confident and factual” but struggles to think ahead reliably.
Why does it matter?
CryptoBench gives researchers, builders, and users a realistic way to see what AI agents can and cannot do in one of the fastest, most chaotic online environments. The main takeaways are:
- We need better reasoning, not just better browsing: Current AIs can collect data but often fail to make solid short-term predictions—especially under pressure.
- Real-world testing changes the game: Live, constantly updated questions reveal weaknesses that static tests miss. This pushes AI improvements in the right direction.
- Safer, smarter tools for finance: By highlighting where AIs fail (like source selection and synthesis), CryptoBench helps guide the next generation of agents that could assist analysts more reliably.
- Lessons for other fields: If an AI can handle crypto’s speed and noise, it’s more likely to handle other fast-changing domains (like breaking news or cybersecurity).
In short, CryptoBench is a tough, practical test that shows where AI agents shine (finding facts) and where they still struggle (reasoning and prediction). It’s a roadmap for building AI that doesn’t just sound smart, but actually makes smart decisions in the real world.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to be actionable for future researchers.
- Ground truth for prediction tasks is underspecified: how are “future” outcomes defined, verified, and time-boxed, and what is the protocol when outcomes are ambiguous or evolve (e.g., partial events, protocol changes)?
- Lack of probabilistic forecasting and calibration: predictions are largely categorical (e.g., bullish/bearish) without probability assignments or calibration metrics (e.g., Brier score, log loss, reliability diagrams).
- Coarse scoring rubric (0–3) may mask nuanced failure modes; need finer-grained, component-level metrics (retrieval accuracy, synthesis correctness, causal reasoning quality, tool-use efficiency).
- LLM-as-a-judge reliability is not validated: no inter-judge agreement, bias assessment, or calibration against expert human graders; need blinded human-vs-LLM adjudication studies.
- The ±5% tolerance is uniform across metrics; no sensitivity analysis on whether tolerance should vary by metric volatility (TVL vs. price vs. address counts) or by source latency.
- Reproducibility in a dynamic benchmark is unaddressed: no versioning scheme for monthly question sets, seeds, model configs, or captured web states to enable repeatable experiments.
- Sample size and statistical power: 50 questions per month may be too small for robust per-category and per-quadrant conclusions; no power analysis or confidence intervals reported.
- Short evaluation window (one month) limits generalization; no longitudinal analysis to assess performance drift, stability, or learning effects across multiple update cycles.
- Human baselines are missing: no comparison to professional crypto analysts or trained novices to contextualize model performance gaps and identify ceiling/floor effects.
- Agent framework is constrained to a single web-browsing tool; no evaluation of multi-tool orchestration (blockchain APIs, exchange APIs, portfolio calculators, graph explorers).
- Vision is absent: dashboards often present visual charts; models were not evaluated on screenshot parsing, chart reading, or OCR—a key real-world requirement.
- Access parity and fairness are unclear: some platforms are paywalled, rate-limited, or region-restricted; no controls to ensure consistent access conditions across models.
- Latency and freshness are not measured: time-to-answer and data staleness penalties (for rapidly changing metrics) are not part of the evaluation, despite time sensitivity being a core domain property.
- Adversarial robustness is not tested: no tasks include misinformation detection, spoofed dashboards, honeypots, or MEV manipulation to assess source vetting under adversarial conditions.
- Safety and risk behaviors remain unexplored: the benchmark does not test whether agents propose unsafe actions (e.g., interacting with risky contracts) or violate platform terms.
- Tool-use ablations are missing: no experiments to separate planning quality, browsing competence, and extraction reliability; unclear which agentic components drive observed ranking shifts.
- Model configuration transparency is limited: temperatures, prompts, step limits, browsing policies, and error handling are not reported; sensitivity of results to these variables is unknown.
- Platform coverage scope is unspecified: chain diversity (e.g., Solana, L2s, emerging chains), oracle/ecosystem breadth, and cross-chain tooling coverage lack detailed characterization.
- Source reliability assessment is not quantified: agents’ ability to rank and cross-verify sources (official dashboards vs. third-party blogs) needs dedicated tasks and metrics.
- Ambiguity and answer stability controls need quantification: beyond the verification protocol, there are no metrics for answer half-life, volatility thresholds, or source change detection.
- Contamination resistance is asserted but not measured: no audits of model training data overlap, template memorization risk, or leakage via public benchmark artifacts.
- Automation and adjudication scalability are unproven: as tasks grow or diversify, how will ground-truth generation, dynamic updates, and judge consistency be maintained at scale?
- Domain taxonomy and difficulty calibration are not validated: tasks may vary in intrinsic difficulty; no item response theory or psychometric calibration to equate items across months and categories.
- Efficiency and cost are ignored: no measures of compute, tool-call counts, page loads, or bandwidth; real-world viability requires cost/latency-aware metrics.
- Multilingual coverage is absent: crypto intelligence often appears in non-English channels (Telegram, X); models’ multilingual retrieval and synthesis are not evaluated.
- Ethical and licensing considerations are not discussed: scraping real-time platforms, API terms, and data redistribution policies could impact benchmark release and replication.
- Release details are unclear: availability of templates, code, judge prompts, ground truths, browsing logs, and versioned datasets for independent replication is not specified.
- Evaluation of complex on-chain graph reasoning is limited: tasks do not explicitly require path tracing, entity resolution, or anomaly detection on transaction graphs using graph-native tools.
- No connection to real-world PnL or decision outcomes: agents are not evaluated on the downstream impact of their predictions or recommendations (e.g., simulated or historical backtests).
- Handling of ephemeral entities (tokens/wallets disappearing or rebranding) is not addressed: need protocols for template invalidation, automatic replacement, and audit trails.
- Cross-framework generality is unknown: results rely on SmolAgent; evaluating multiple agent frameworks (e.g., ReAct variants, tool-augmented planners) could test benchmark portability.
- Generalization beyond crypto to broader finance is untested: unclear which capabilities transfer to TradFi analytics, and which are crypto-specific.
- Learning curves and training utility: whether fine-tuning or RL on CryptoBench improves agent performance without overfitting the dynamic templates remains an open question.
- Multi-agent collaboration is not considered: tasks that benefit from specialized sub-agents (retrieval, reasoning, risk) could reveal different capabilities and coordination challenges.
Practical Applications
Immediate Applications
Below is a set of concrete, deployable applications that leverage CryptoBench’s findings, methods, and innovations right now.
- Continuous vendor evaluation and procurement for AI agents in crypto
- Description: Use CryptoBench’s monthly, expert-curated tasks and Average Success Rate metric to compare, select, and monitor LLM agents for research, trading, and operations.
- Sectors: Finance (crypto funds, exchanges, market makers), Software (AI tooling).
- Tools/workflows: CI/CD evaluation harness; LLM-as-a-Judge rubric with ±5% numerical tolerance; quadrant-specific scorecards; agent ranking dashboards.
- Assumptions/dependencies: Access to live internet and specialized platforms; periodic benchmark updates; standardized evaluation environment; potential API subscriptions (e.g., Nansen, Arkham, CoinGecko).
- Production guardrails for AI agents based on observed failure modes
- Description: Implement source fidelity checks, timestamp enforcement, cache-avoidance, and integration validation to reduce shallow search, stale info, and synthesis errors identified by CryptoBench.
- Sectors: Finance, Software.
- Tools/workflows: “Source specificity” policies (official dashboards, first-party APIs), “temporal bounding” in prompts, automated recency checks, multi-source cross-verification, result reconciliation before final output.
- Assumptions/dependencies: Tool orchestration capability; access to authoritative data; ops team to maintain guardrails and reliability tests.
- Task routing across LLMs using quadrant strengths
- Description: Route retrieval-dominant tasks to retrieval-strong models (e.g., Simple/Complex Retrieval) and inference-heavy tasks to models with better prediction profiles; use SmolAgent-like orchestration.
- Sectors: Software, Finance.
- Tools/workflows: Meta-controller that assigns tasks by quadrant; model selection policy informed by CryptoBench breakdowns; fallbacks and escalation paths.
- Assumptions/dependencies: Reliable per-model performance profiles; routing infrastructure; monitoring to prevent drift.
- Benchmark-driven prompt engineering and SOPs for crypto analysis
- Description: Encode CryptoBench’s design principles (metric precision, source naming, temporal bounds) into reusable prompt templates and analyst SOPs.
- Sectors: Finance, Education (analyst training), Software.
- Tools/workflows: Prompt libraries mapping to SR/CR/SP/CP quadrants; checklists for metric definitions (TVL vs. TVS, FDV vs. MC), time windows, and tolerance ranges.
- Assumptions/dependencies: Organizational adoption; analyst training; access to consistent data sources.
- Crypto analyst copilot MVPs
- Description: Deploy an agent that can perform SR/CR tasks (e.g., governance proposal summaries, top holder breakdowns, TVL/APY lookups) with robust source and time checks.
- Sectors: Finance (funds, DeFi protocols), Software.
- Tools/workflows: Browser-based agent with source whitelists; report templates; audit trails; human-in-the-loop sign-off for CP tasks.
- Assumptions/dependencies: API keys/subscriptions to analytics platforms; UI integration; human oversight for predictive recommendations.
- Real-time operations monitors for exchanges and risk desks
- Description: Use CryptoBench task archetypes to monitor funding rates, open interest, liquidation levels, and DEX liquidity shifts; auto-alert anomalies with verified sources.
- Sectors: Finance (exchanges, risk), Energy (if adapted to grid telemetry), Software.
- Tools/workflows: Streaming data endpoints; alert pipelines; anomaly detection; dashboards with source attribution.
- Assumptions/dependencies: Stable real-time feeds; clear tolerance ranges; policy for handling conflicting sources.
- Retail investor safety assistant
- Description: A lightweight browser/plugin that cross-verifies yields, flags phishing wallets, checks whale transfers, and validates token claims against official dashboards.
- Sectors: Daily life (retail crypto), Finance.
- Tools/workflows: One-click “verify” actions; labeled trust tiers for sources; time-stamped outputs; risk scoring.
- Assumptions/dependencies: Free/paid access to on-chain intelligence platforms; usability and education UX; disclaimers and risk disclosure.
- Academic reproduction and curriculum integration
- Description: Use CryptoBench’s dynamic, contamination-resistant benchmark to teach and study agent design, predictive reasoning, and tool-use in adversarial environments.
- Sectors: Academia, Education.
- Tools/workflows: Course modules aligned to quadrants; replication packages; error analyses; open leaderboards.
- Assumptions/dependencies: Public availability of benchmark updates; institutional IRB/ethics for live-data studies; compute resources.
- Compliance and audit overlays for AI outputs
- Description: Add evaluators that score outputs using the CryptoBench rubric before dissemination; block or flag noncompliant predictions or unverified facts.
- Sectors: Finance (compliance), Policy.
- Tools/workflows: LLM-as-a-Judge scoring; trace logging; pre-publication gates; exception workflows.
- Assumptions/dependencies: Auditable traces; governance buy-in; defined risk thresholds; model-judge calibration.
- Tool provider benchmarking and go-to-market support
- Description: On-chain intelligence platforms and DeFi dashboards can publish CryptoBench-derived performance metrics to demonstrate reliability and ecosystem value.
- Sectors: Software (data providers), Finance.
- Tools/workflows: Benchmark-aligned demos; API reliability SLAs; source coverage maps.
- Assumptions/dependencies: Transparent methodology; shared evaluation harnesses; marketing and disclosure standards.
Long-Term Applications
Below are strategic applications that require further method development, scaling, or policy maturation before broad deployment.
- Predictive reasoning modules to close the retrieval–prediction gap
- Description: Develop new architectures and training strategies (e.g., tool-augmented forecasting, RLAIF/RLHF on forward outcomes, causal reasoning) to improve SP/CP performance.
- Sectors: Software/ML, Finance, Academia.
- Tools/workflows: Outcome-labeled datasets; delayed reward pipelines; simulators for counterfactuals; hybrid symbolic-statistical models.
- Assumptions/dependencies: Reliable ground-truth for future events; careful leakage control; long-horizon training; evaluation robustness.
- Crypto-specific AI certification standards
- Description: Establish regulator- and industry-accepted certification based on CryptoBench for AI advisors, research tools, and automated trading systems.
- Sectors: Policy, Finance.
- Tools/workflows: Standardized tests across quadrants; minimum accuracy thresholds; stress scenarios; audit procedures.
- Assumptions/dependencies: Regulator engagement (e.g., SEC/CFTC); liability and disclosure frameworks; third-party auditors; evolving benchmarks.
- Autonomous trading and treasury management agents
- Description: Deploy agents that not only retrieve and synthesize but act—placing orders, managing liquidity, and hedging—under strict risk controls informed by benchmark performance.
- Sectors: Finance (funds, treasuries), DeFi.
- Tools/workflows: Risk/rule engines; circuit breakers; sandbox-to-prod promotion gates; continual evaluation against dynamic tasks.
- Assumptions/dependencies: Regulatory clearance; robust fail-safes; high-quality execution venues; MEV-aware strategies.
- Cross-domain dynamic benchmarks modeled on CryptoBench
- Description: Adapt the “living benchmark + expert curation + four-quadrant” design to healthcare (clinical decision support), energy (grid operations), robotics (real-world manipulation), and cybersecurity (threat intel).
- Sectors: Healthcare, Energy, Robotics, Cybersecurity, Education.
- Tools/workflows: Domain-expert committees; dynamic templating of entities; live-data integrations; contamination controls.
- Assumptions/dependencies: Access to authoritative, real-time data; privacy and compliance (HIPAA, NERC-CIP); expert bandwidth; evaluation automation.
- Agentic compliance auditors
- Description: Independent agents that continuously score and explain other agents’ outputs (fact retrieval vs. predictions), detecting hallucinations, stale info, and synthesis mistakes.
- Sectors: Policy, Finance, Software.
- Tools/workflows: Cross-model adjudication; calibrated judges; discrepancy trackers; escalation protocols.
- Assumptions/dependencies: Reliable judge calibration; transparency and trace logging; guardrails against collusion.
- MEV-aware and on-chain simulation frameworks for agents
- Description: Integrate MEV analytics and transaction simulation to anticipate slippage, sandwich risks, and validator behavior before executing strategies.
- Sectors: Finance (DeFi, trading), Software.
- Tools/workflows: EigenPhi-class analytics; mempool simulators; execution risk models; pre-trade checks.
- Assumptions/dependencies: Access to low-latency chain data; chain-specific tooling; simulator fidelity; evolving MEV landscapes.
- Open leaderboards and marketplaces of evaluated agents
- Description: Create public registries where agent performance (by quadrant, category, and live tasks) is tracked and discoverable for procurement and integration.
- Sectors: Finance, Software, Academia.
- Tools/workflows: Continuous benchmarking pipelines; anti-gaming mechanisms; provenance metadata; versioning and change logs.
- Assumptions/dependencies: Community governance; reproducibility standards; incentives and reputational stakes.
- Curriculum learning and auto-evolving template generation
- Description: Use performance analytics to generate new task templates that target weak capabilities, creating an auto-curriculum for agents.
- Sectors: Software/ML, Academia.
- Tools/workflows: Template generators; difficulty schedulers; feedback-driven task creation; learning progress tracking.
- Assumptions/dependencies: Robust analytics; expert oversight; safeguards against overfitting to templates; diversity maintenance.
- Improved LLM-as-a-Judge calibration and standards
- Description: Advance judge models and rubrics for fair scoring across volatile, real-time financial tasks; formalize tolerance bands and uncertainty reporting.
- Sectors: Academia, Policy, Software.
- Tools/workflows: Multi-judge ensembles; human calibration rounds; reliability metrics; uncertainty-aware scoring.
- Assumptions/dependencies: Access to adjudication datasets; consensus-building; cost management for multi-judge evaluation.
- Organizational AI governance playbooks grounded in dynamic evaluation
- Description: Formalize policies for deployment gates, periodic re-evaluation, change management, and rollback procedures informed by CryptoBench trends.
- Sectors: Finance, Policy, Enterprise IT.
- Tools/workflows: Governance committees; risk registers; KPI scorecards (per quadrant); incident response protocols.
- Assumptions/dependencies: Executive sponsorship; regulatory alignment; continuous monitoring resources; cross-functional coordination.
Glossary
- Algorithmic front-running: The practice of using algorithms to anticipate and trade ahead of pending transactions for profit, often exploiting timing advantages. "strategies from algorithmic front-running to coordinated misinformation campaigns"
- Annualized Percentage Yield (APY): A standardized measure of the annual return on an investment that accounts for compounding. "identify a specific liquidity pool's Annualized Percentage Yield (APY)"
- Block explorer: A web tool that indexes blockchain data, allowing users to view blocks, transactions, and addresses. "using block explorers and advanced analytics platforms"
- Circulating market capitalization: The total market value of the circulating (currently tradable) supply of a token. "'circulating market capitalization'"
- Daily active addresses: The number of unique blockchain addresses that have participated in transactions over a day, used as a proxy for user activity. "'daily active addresses'"
- Decentralized Exchanges (DEXs): Peer-to-peer marketplaces on blockchains that enable token swaps without centralized intermediaries. "interpret data from Decentralized Exchanges (DEXs) and derivatives platforms"
- Decentralized Finance (DeFi): A financial ecosystem built on blockchains that replaces intermediaries with smart contracts and protocols. "Decentralized Finance (DeFi) dashboards"
- DeFi primitives: Fundamental building blocks or base protocols in DeFi upon which more complex applications are built. "DeFi primitives (e.g., questions related to restaking, modular blockchains, or new oracle designs)"
- Derivatives: Financial instruments whose value derives from an underlying asset, commonly used for hedging or speculation. "derivatives platforms"
- DEX aggregators: Services that route trades across multiple decentralized exchanges to optimize price and liquidity. "DEX aggregators and information sites for swap rates and liquidity data."
- EigenPhi: A specialized analytics platform used to analyze MEV and on-chain profitability. "via EigenPhi"
- Etherscan: A widely used Ethereum block explorer for viewing addresses, transactions, and token data. "on Etherscan"
- Fully Diluted Valuation (FDV): The market value of a token assuming all possible tokens (including locked or unissued) are in circulation. "Fully Diluted Valuation (FDV)"
- Funding rates: Periodic payments exchanged between long and short perpetual futures traders to keep contract prices anchored to spot. "funding rates"
- Futures: Contracts that oblige parties to buy or sell an asset at a predetermined price at a future date; common in crypto derivatives. "futures and derivatives data"
- Governance proposals: Formal proposals within crypto protocols/DAOs that token holders vote on to change parameters or policies. "List the last five governance proposals for the Aave protocol"
- Governance voting: The act of token holders casting votes on protocol decisions within decentralized governance systems. "staking, selling, or governance voting?"
- Key Opinion Leader (KOL): Influential individuals or entities whose on-chain activity can impact market sentiment and behavior. "Key Opinion Leader (KOL) wallets"
- Liquidity pool: A smart-contract-based pool of tokens that provides liquidity for trading on DEXs, often earning fees or yields. "Find the three largest liquidity pools on the Curve Finance platform"
- Liquidation: The forced closing of a leveraged position when collateral value falls below maintenance thresholds, common in derivatives. "liquidation levels."
- LLM-as-a-Judge: An evaluation paradigm where a LLM scores or critiques other model outputs using a rubric. "LLM-as-a-Judge framework"
- Market maker: An entity that provides liquidity by continuously quoting buy and sell prices, reducing bid-ask spreads. "market makers"
- Maximal Extractable Value (MEV): Value that can be extracted by reordering, inserting, or censoring transactions within a block. "Maximal Extractable Value (MEV)"
- Modular blockchains: Blockchain designs that separate roles (e.g., execution, settlement, data availability) across specialized layers or networks. "modular blockchains"
- On-chain intelligence aggregators: Platforms that consolidate blockchain data and analytics (e.g., wallet labels, flows) for investigation and insights. "on-chain intelligence aggregators (e.g., Nansen, Arkham)"
- On-chain transaction graphs: Network graphs constructed from blockchain transactions to analyze relationships and flows among addresses. "on-chain transaction graphs"
- Open interest: The total number of outstanding derivative contracts (e.g., futures or perpetuals) that have not been settled. "open interest"
- Oracle: A service that supplies external data (e.g., prices) to smart contracts, enabling them to interact with real-world information. "oracles"
- Prediction markets: Markets where participants trade contracts based on the outcomes of future events, producing crowd-aggregated forecasts. "prediction markets like PolyMarket"
- Profit and Loss (P&L): The net financial result of trading activities, measuring gains minus losses over a period. "Profit and Loss (P{paper_content}L)"
- Restaking: Reusing staked assets or security guarantees to secure additional services or protocols, compounding utility/yield. "restaking"
- SmolAgent: An agentic framework used to equip LLMs with web-browsing and tool-use capabilities for task execution. "SmolAgent framework"
- Stablecoin: A cryptocurrency designed to maintain a stable value, typically pegged to a fiat currency like USD. "A new stablecoin yield farm is offering a 500\% APY."
- Token unlock: A scheduled release of previously locked tokens into circulation, often affecting supply and price dynamics. "Token A has a major token unlock scheduled for next week, releasing 10\% of its circulating supply to early investors."
- Tokenomics: The economic design of a token, including supply, distribution, incentives, and utility mechanisms. "Compare the tokenomics of Project A (high inflation, utility-focused) and Project B (fixed supply, governance-focused)."
- Total Value Locked (TVL): The total dollar value of assets deposited in a DeFi protocol, measuring its scale and usage. "Total Value Locked (TVL)"
- Total Value Secured (TVS): The total value that an oracle or security mechanism safeguards across integrated protocols. "Total Value Secured (TVS)"
- Whale: A blockchain address or entity that holds or moves large amounts of crypto, potentially influencing markets. "whale wallet"
- Yield farm: A DeFi opportunity where users provide liquidity or stake assets to earn high variable returns, often denominated in APY. "A new stablecoin yield farm is offering a 500\% APY."
- Yield farming strategies: Tactics for allocating assets across DeFi protocols to maximize yield while managing risk. "yield farming strategies"
- “Rat Trading”: A colloquial label for deceptive or malicious trading behavior, often implying manipulative practices. "potential ``Rat Trading''"
- Long/short ratios: A metric comparing the number or size of long positions to short positions in derivatives markets, indicating sentiment. "long/short ratios"
Collections
Sign up for free to add this paper to one or more collections.