SimWorld: An Open-ended Realistic Simulator for Autonomous Agents in Physical and Social Worlds
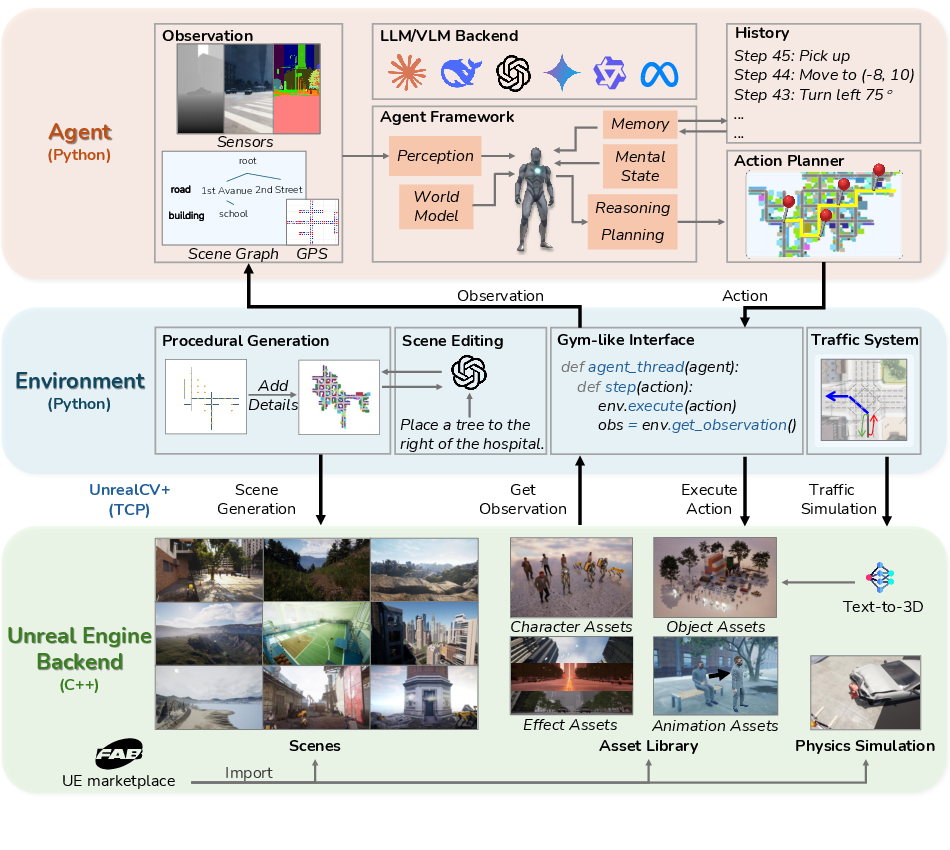
Abstract: While LLM/VLM-powered AI agents have advanced rapidly in math, coding, and computer use, their applications in complex physical and social environments remain challenging. Building agents that can survive and thrive in the real world (for example, by autonomously earning income or running a business) requires massive-scale interaction, reasoning, training, and evaluation across diverse embodied scenarios. However, existing world simulators for such development fall short: they often rely on limited hand-crafted environments, simulate simplified game-like physics and social rules, and lack native support for LLM/VLM agents. We introduce SimWorld, a new simulator built on Unreal Engine 5, designed for developing and evaluating LLM/VLM agents in rich, real-world-like settings. SimWorld offers three core capabilities: (1) realistic, open-ended world simulation, including accurate physical and social dynamics and language-driven procedural environment generation; (2) a rich interface for LLM/VLM agents, with multimodal world inputs and open-vocabulary actions at varying levels of abstraction; and (3) diverse and extensible physical and social reasoning scenarios that are easily customizable by users. We demonstrate SimWorld by deploying frontier LLM agents (e.g., GPT-4o, Gemini-2.5-Flash, Claude-3.5, and DeepSeek-Prover-V2) on long-horizon multi-agent delivery tasks involving strategic cooperation and competition. The results reveal distinct reasoning patterns and limitations across models. We open-source SimWorld and hope it becomes a foundational platform for advancing real-world agent intelligence across disciplines: https://simworld.org.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored, to guide future research and engineering work.
- Quantitative validation of physical realism is absent (e.g., benchmarking UE physics against real-world measurements for locomotion, collisions, friction, vehicle dynamics); specify standardized tests and metrics (drop tests, braking distance curves, slip ratio under rain, stability on slopes).
- Social realism is asserted but not operationalized; define and measure compliance metrics (traffic violations per km, crosswalk yield rates, personal-space intrusions, crowding effects) and compare to human or agent baselines.
- No performance/scalability profiling: throughput (FPS), agent count limits, multi-agent contention, bandwidth of UnrealCV+, and GPU/CPU utilization under different scene complexities and modalities.
- Determinism and reproducibility are under-specified: document physics determinism across OS/GPUs, random seeds for procedural generation and traffic, reproducible versioning of scene edits, and guarantees for synchronous mode experiments.
- Sensor suite is limited to RGB/depth/segmentation; add and validate audio, LiDAR, event cameras, IMU, GPS noise models, and camera intrinsics/extrinsics to enable robotics and AV research.
- Sim2real transfer is unaddressed: provide domain randomization knobs (lighting, weather, materials, textures, sensor noise), calibration against real datasets, and transfer experiments to physical robots or driving simulators.
- Procedural city generation lacks empirical realism validation; align road topology, building density, land-use mix, and pedestrian/vehicle distributions with real city datasets (e.g., OSM, INRIX, OpenAddresses).
- Interiors and indoor semantics are not described; add procedural/handcrafted indoor spaces, furniture layouts, affordance annotations, and multi-room navigation challenges.
- Traffic system uses simple PID and stochastic routing; missing lane-change logic, car-following models (IDM/MOBIL), collision handling, emergency vehicles, accidents, and adaptive signal control—compare against SUMO/Aimsun and validate macro/micro traffic metrics (flow, speed, occupancy).
- Waypoint/path-planning abstraction may ignore dynamic obstacles and non-holonomic constraints; evaluate A* vs sampling-based planners (RRT*, PRM), re-planning under moving obstacles, and path smoothness/safety metrics.
- LLM-based scene editing and text-to-3D asset generation lack quality and safety validation: check scale/units consistency, physical properties (mass, collision meshes), licensing/IP compliance, and filters for unsafe/explicit content.
- Action planner reliability is not evaluated: measure grounding accuracy from language to primitives, ambiguity resolution, recovery from failed/unsafe actions, and generalization across scenes and embodiments; consider learned planners vs rule-based.
- Open-vocabulary action space lacks a canonical schema; define a standardized action grammar/API, disambiguation rules, multilingual support, and synonym resolution to reduce parsing errors across models.
- Observation updates and scene graph consistency under on-the-fly edits are not detailed; ensure incremental updates, stable object IDs, diff logs, and latency bounds for agent perception after edits.
- Multi-agent scaling and social emergence are only illustrated via a delivery task; study larger populations (hundreds–thousands), identity management, communication channels, coalition formation, and adversarial behaviors with quantitative emergent-metric tracking.
- Benchmarking is preliminary: establish standardized task suites (physical, social, economic), clear success metrics (task completion, safety infractions, profit/ROI, cooperation indices), leaderboards, and statistical significance protocols.
- Economic environment (delivery task) lacks formal market modeling: define order arrival processes, price dynamics, auction rules, collusion detection, contract enforcement, risk metrics, and ablations on tool costs and asset investments.
- NPCs and social actors are underspecified; provide configurable behavioral models (rule-based, RL, LLM), cultural norms, personality distributions, and human-in-the-loop validation on social plausibility.
- Agent safety and ethics are not addressed: implement constraints (speed limits, geofences), injury/crash modeling, safe exploration, red-teaming, and content moderation for open-ended edits and interactions.
- Logging, telemetry, and dataset generation pipelines are not described; specify standardized logs (states, actions, rewards, events), compression and sampling strategies, privacy compliance, and ready-to-use datasets for training.
- UnrealCV+ communication details are limited; document throughput/latency under high-res streams, reliability, error handling, remote cluster operation, containerization, and API stability across UE versions.
- Time management under asynchronous mode is unclear: define fairness policies, timeouts, step synchronization with LLM inference latency, and bias mitigation when agents with different compute budgets co-exist.
- Extent of embodiment support is inconsistent (drone appears in comparisons but not in embodiments): clarify drone availability, flight dynamics, aerodynamics, sensor suites, and compliance with airspace rules.
- Robotics manipulation is lightly covered; add contact-rich tasks, tactile sensing, gripper models (suction, parallel-jaw, multi-finger), deformable objects, and evaluation of IK/trajectory generation vs physics outcomes.
- Weather/lighting effects on perception and dynamics are not validated; quantify impact on sensors, friction, braking, visibility, and agent performance under domain shifts.
- Cross-platform and deployment constraints (Windows/Linux/macOS, headless UE, cloud GPUs) are not specified; provide installation footprints, resource requirements, and CI for reproducible builds.
- Licensing and provenance of marketplace and generated assets are not discussed; define allowed uses, redistribution terms, and automated license tracking for scenes/assets included in the release.
- Memory and persistence across episodes are not detailed; offer long-horizon world state persistence (day/night cycles, construction, inventory), agent memory APIs, and save/restore checkpoints for career-scale simulations.
- Reward specification for RL is vague; provide task templates with reward functions, shaping strategies, curriculum learning hooks, and baselines to facilitate training beyond pure LLM agents.
- Failure modes and recovery mechanisms are missing; implement and study detection/recovery for stuck agents, deadlocks at intersections, physics instabilities, and corrupted scene edits.
- Quantitative comparison to other simulators is incomplete; run cross-simulator tasks (e.g., navigation, driving) with shared metrics to substantiate “+++” realism claims and identify trade-offs (fidelity vs speed).
- Data drift under language-driven world edits is not analyzed; measure how iterative edits affect distributional properties (object types, spatial layout) and agent performance over prolonged simulations.
Collections
Sign up for free to add this paper to one or more collections.

