CauSight: Learning to Supersense for Visual Causal Discovery
Abstract: Causal thinking enables humans to understand not just what is seen, but why it happens. To replicate this capability in modern AI systems, we introduce the task of visual causal discovery. It requires models to infer cause-and-effect relations among visual entities across diverse scenarios instead of merely perceiving their presence. To this end, we first construct the Visual Causal Graph dataset (VCG-32K), a large-scale collection of over 32,000 images annotated with entity-level causal graphs, and further develop CauSight, a novel vision-LLM to perform visual causal discovery through causally aware reasoning. Our training recipe integrates three components: (1) training data curation from VCG-32K, (2) Tree-of-Causal-Thought (ToCT) for synthesizing reasoning trajectories, and (3) reinforcement learning with a designed causal reward to refine the reasoning policy. Experiments show that CauSight outperforms GPT-4.1 on visual causal discovery, achieving over a threefold performance boost (21% absolute gain). Our code, model, and dataset are fully open-sourced at project page: https://github.com/OpenCausaLab/CauSight.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “CauSight: Learning to Supersense for Visual Causal Discovery”
What is this paper about?
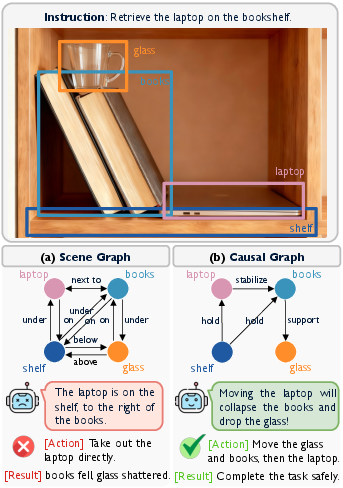
This paper is about teaching AI to look at a picture and figure out not just what things are, but why things are the way they are. In other words, the AI learns cause-and-effect in images. For example, if a glass is on a stack of books that sits on a laptop, the AI should understand that pulling out the laptop could make the books fall and the glass drop. The authors call this skill visual causal discovery.
What were the researchers trying to do?
The paper has three simple goals:
- Build a large, trustworthy dataset of images that shows objects and who affects whom (cause-and-effect links).
- Create a new model, called CauSight, that can discover these cause-and-effect links in many different kinds of pictures.
- Train the model in a way that helps it think through causes step by step and improve through feedback, not just copy answers.
How did they do it? (Methods in everyday language)
To reach these goals, the researchers did three main things.
- They built a dataset for cause-and-effect in images (VCG-32K)
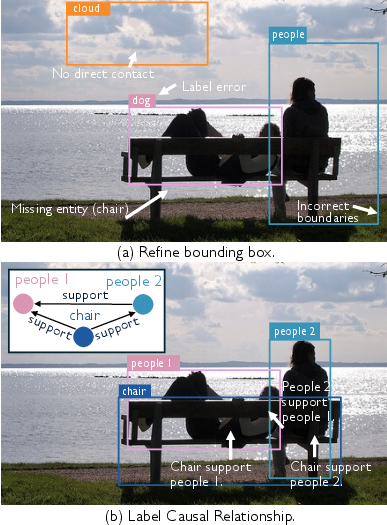
- What it is: 32,000+ images with detailed boxes around objects and arrows showing which object causes another to be in its current state (like “the table supports the vase”).
- How they decided a cause exists: If removing object A would change object B’s state right now (for example, removing a chair would make a person no longer “sit”), then A causes B.
- Why this matters: Most older datasets only say where things are (like “cup on table”) but not why (“table supports cup”). This new dataset captures the “why.”
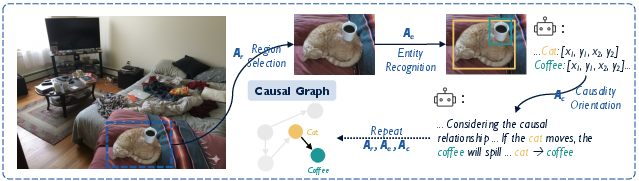
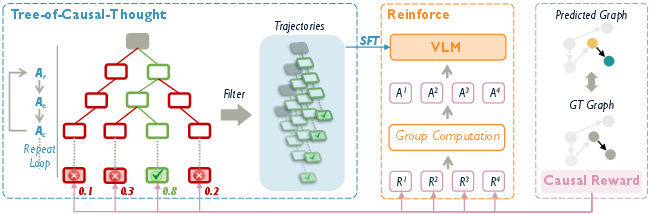
- They taught the model to reason in steps using a “Tree-of-Causal-Thought” (ToCT)
- Think of it like exploring a maze: at each step, the model picks a region to look at, identifies objects there, and then decides who affects whom. It builds a tree of possible reasoning paths and uses a search method to pick the best path.
- Monte Carlo Tree Search (MCTS): This is like trying several promising paths in a game to see which one likely leads to a win. Here, “winning” means correctly figuring out cause-and-effect in the image.
- A stronger “teacher” model generates many step-by-step examples. The student model (CauSight) learns from only the best ones, so it picks up good habits.
- They improved the model with practice and rewards (reinforcement learning)
- Reinforcement learning is like training with a coach who scores your performance. The model tries, gets feedback, and improves.
- The “causal reward” gives points for:
- Recall: finding the true cause-and-effect connections.
- Precision: avoiding wrong connections.
- Format: writing the answer in the correct structure.
- This helps the model not only think clearly but also produce clean, reliable outputs.
Extra note on evaluation: When judging the model, they match predicted objects to real ones and check whether the arrows (who causes whom) point in the right direction. They mostly care about the structure of the connections, not the exact names of the objects.
What did they find, and why is it important?
- Big performance gains: CauSight beat powerful general-purpose AI systems (including GPT-4.1) on discovering cause-and-effect in images, with more than a threefold improvement on average in key metrics.
- Strong generalization: It worked well not only on images it “trained on,” but also on images from a different dataset. That means it learned useful causal principles, not just memorized examples.
- Better balance of “seeing” and “thinking”: The model kept solid object detection while becoming much better at reasoning about cause and effect. Other models were often good at one but weak at the other.
- Step-by-step thinking helps: Training with ToCT (good examples of reasoning steps) and then reinforcement learning (practice with feedback) gave the best results, especially on new, unseen images.
This matters because understanding “why” is crucial for safe decisions in the real world. For example:
- Robots can plan safer actions (don’t pull the laptop if it will topple a glass).
- Self-driving cars can reason about chains of events (if this car brakes, what will that cause?).
- AI becomes more explainable and trustworthy by showing the causal links it believes in.
What’s the bigger impact?
- A new task for AI: Visual causal discovery gives AI a way to move beyond “what is there” to “why it matters.”
- Public resources: The dataset (VCG-32K), the code, and the model (CauSight) are open-source, so others can build on this work.
- Safer, smarter systems: With better causal understanding, AI can make more reliable choices, especially in areas like robotics, autonomous driving, and home assistants.
- A path forward: The two-phase training—first learn good reasoning steps, then improve with rewards—shows a practical way to teach AI to think more like humans about cause and effect.
In short, this paper takes a major step toward AI that doesn’t just see the world—it understands how actions lead to consequences.
Collections
Sign up for free to add this paper to one or more collections.