- The paper demonstrates that state-of-the-art VGMs render gravity at only 10-20% of Earth’s 9.81 m/s², indicating significant under-acceleration.
- It reveals that larger models exacerbate physical inaccuracies, systematically violating Galileo’s principle in relative timing tests.
- A targeted LoRA-based gravity adapter improves dynamics to about 65% of terrestrial gravity, showcasing effective zero-shot correction.
Evaluating Physical Law Representation in Video Generators: Sub-Earth Gravity and Galileo’s Principle Violations
Overview
The paper "Objects in Generated Videos Are Slower Than They Appear: Models Suffer Sub-Earth Gravity and Don't Know Galileo's Principle...for now" (2512.02016) critically analyzes the physical reasoning capacity of modern video generative models (VGMs), with an emphasis on their implicit encoding of gravitational dynamics. The investigation centers on whether these architectures capture the invariance and magnitude of gravitational acceleration, especially as encoded in Galileo's principle: all objects, irrespective of mass or starting height, must fall at identical rates. The study systematically examines several state-of-the-art VGMs spanning a range of parameter scales, evaluates their motion realism, and introduces targeted low-rank adaptation to correct observed deficiencies.
Experimental Protocol and Benchmark Design
The experimental protocol is rigorously constructed to decouple physical law inference from confounding factors such as metric scale ambiguity, camera parameters, and arbitrary frame rates—issues endemic to unconditional video generation. Two principal evaluation regimes are established: the single-ball drop (for effective gravitational measurement) and a two-ball simultaneous-drop protocol (for scale-invariant relative timing, isolating adherence to Galileo's principle).
Synthetic sequences are rendered using Blender to allow pixel-accurate ground truth, with focus on standardized sports balls dropped from controlled heights. The two-ball protocol ensures balls are dropped from variably separated heights in the same frame, with identical background and perspective, so all scale effects cancel in timing ratios. A custom evaluation harness based on SAM2 tracks and measures per-frame dynamics.
Systematic Under-Acceleration: Sub-Earth Gravity in Generated Trajectories
Direct measurement of effective gravity via geff=2h/t2 reveals that all major VGMs, including Wan 5B/14B, Veo3, Cosmos 2B/14B, and Hunyuan, yield object dynamics far slower than physical reality; their median geff ranges from 1 to 2.2 m/s², a stark deficit compared to Earth's 9.81 m/s². This effect is highly robust to prompting strategy (explicit scene and object details, frame constraints), and is not resolved by any simple temporal rescaling—variance across samples and seeds remains high post-normalization, demonstrating that models encode consistently non-physical kinematics in default operation.

Figure 1: All tested models produce synthetic ball trajectories with substantially smaller spatial increments per frame, indicating pronounced under-acceleration relative to terrestrial physics.
Even more intriguingly, scaling model capacity leads not to improvement but to degradation: large models (Wan 14B, Cosmos 14B) exhibit even lower effective gravity and greater distributional variance than their smaller counterparts. This contradicts canonical scaling-law intuition that more parameters and more training data enhance generalization across all axes including physical reasoning.
Violations of Galileo’s Principle: Dissecting Relative Acceleration
The two-ball drop protocol is designed to eliminate all unit-based ambiguities by focusing on timing ratios: for ideal gravity, t12/t22=h1/h2. Systematic deviations are observed in all models. In numerous cases, the ball dropped from a higher position lags dramatically behind its physically required location at the moment the lower ball lands (Figure 2), indicating a failure to encode the universality of gravitational acceleration—a core tenet of both Newtonian and Galilean mechanics. The directionality of errors is model-dependent: smaller models tend to over-accelerate the higher ball (negative mean Δt), whereas larger models under-accelerate (positive mean Δt).

Figure 2: VGM-generated scenes often show the higher ball falling markedly less than required at the lower ball's impact, evidencing failure to enforce gravitational equivalence.
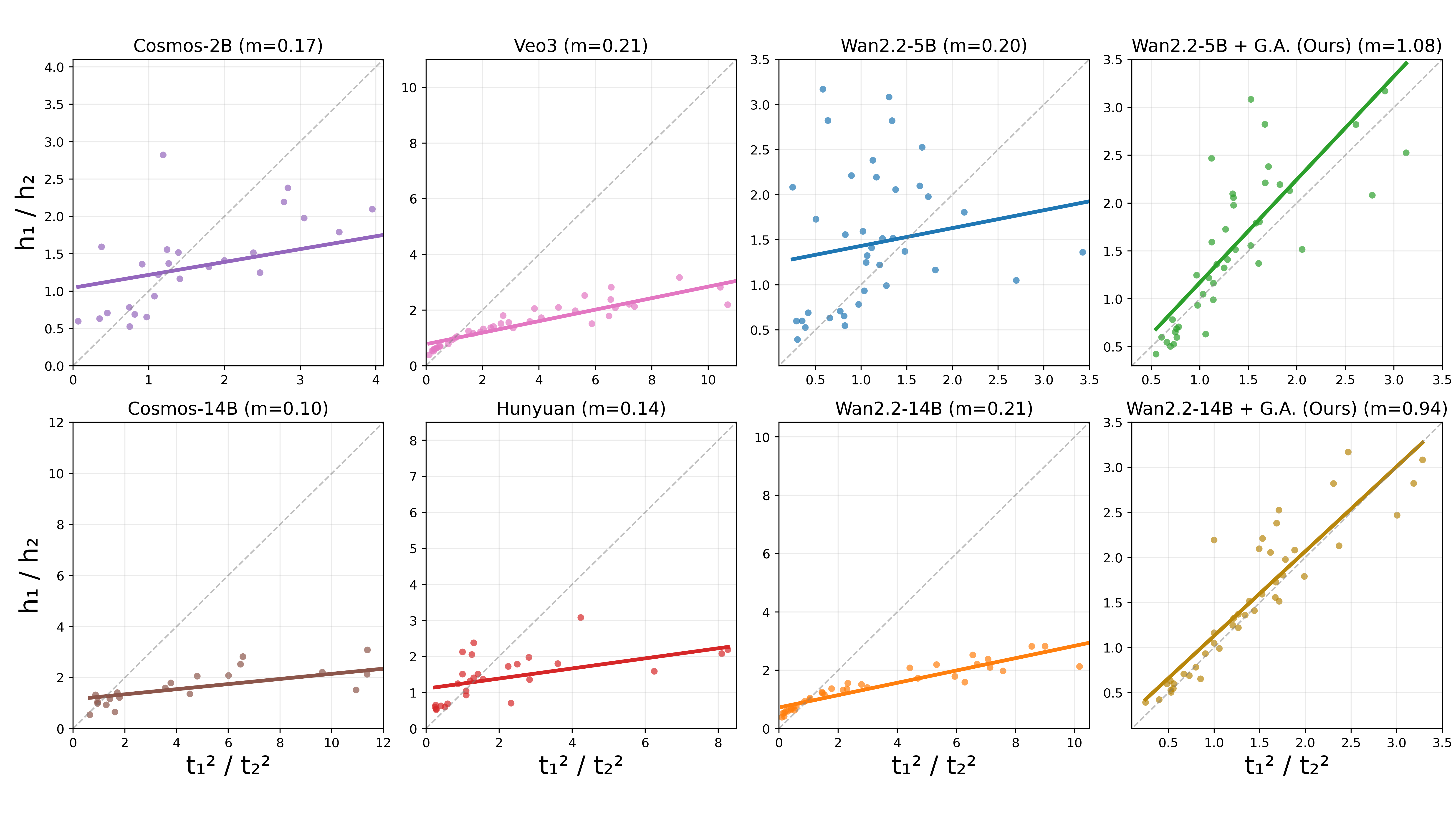
Figure 3: Timing ratio plots reveal all models deviate from the theoretical relationship t12/t22=h1/h2, underscoring a categorical violation of fundamental physics that persists under all forms of global temporal correction.
LoRA Adapter-Based Correction and Generalization
To determine whether the violation of physical laws reflects a knowledge deficit or merely under-activated latent structure, a LoRA-based gravity adapter is trained on just 100 single-ball synthetic drop sequences. Application to the Wan 5B and Wan 14B models increases average geff to 6.43 and 5.51 m/s², respectively—a decisive move toward correct terrestrial dynamics—while reducing timing violations in the two-ball case (Δt mean near zero, reduced spread). Notably, this adaptation achieves substantial correction without any explicit exposure to two-ball or inclined-plane cases, demonstrating generalization to zero-shot regimes.
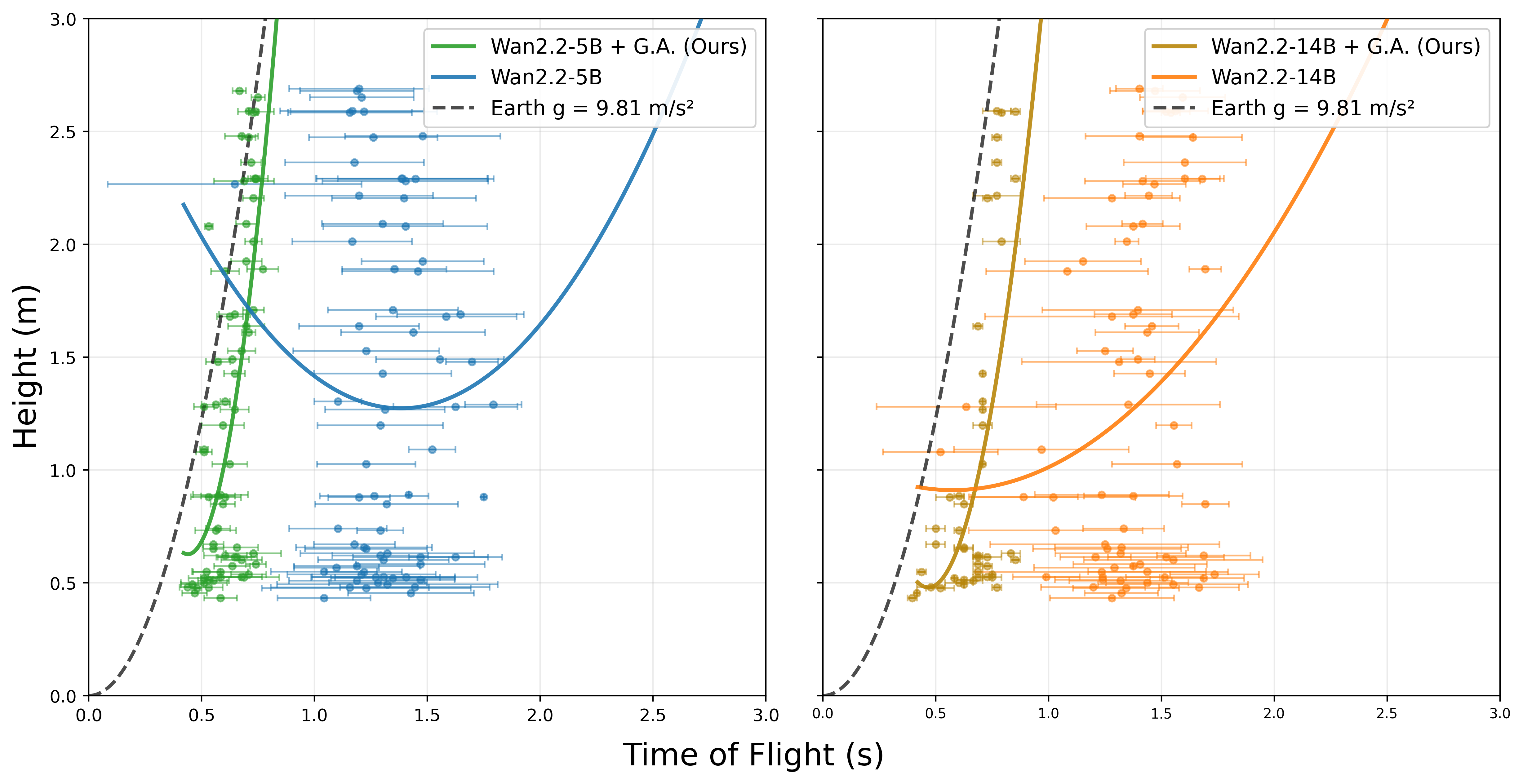
Figure 4: Incorporation of a LoRA-based gravity adapter shifts model behavior toward the h vs t relation governed by g=9.81 m/s², with marked reduction in inter-seed variance.
The adapter also displays zero-shot transfer on real-world datasets (e.g., PISA benchmark), modestly improving physical accuracy despite having been trained exclusively on synthetic and visually idealized scenes. Furthermore, the adapter outperforms explicit trajectory guidance and high-cost full-model finetuning across several key metrics, with substantially reduced parameter overhead and computational demand.
Implications for Physical World Modeling and Model Alignment
Numerical Findings: No VGM tested natively approaches correct gravity, with typical effective values of 10–20% of Earth's gravitational acceleration prior to correction. Post-adaptation, performance approaches 65% of terrestrial g, with notable reduction in variance and relative-timing violations.
Contradictory Claims: Contrary to scaling-law expectations, increasing model size degrades—rather than improves—physical fidelity in gravitational reasoning tasks. This suggests that inductive biases, reward signals, and latent knowledge activation, rather than parameter count, are the bottleneck for learning physically-correct motion laws in generative video.
Practical and Theoretical Implications: Systems that generate visually plausible video, but fundamentally misrepresent physical law, are unsuitable as world models for downstream agents in robotics, simulation, or scientific forecasting. The success of a highly parameter-efficient adapter suggests that VGMs potentially encode hidden physical structure that is neither robustly activated by conventional training nor aligned by perceptual or RLHF-style reward signals, which prioritize superficial plausibility over mechanistic causality.
Future Directions: Several open avenues are indicated:
- Adapting physics-corrective methodologies to larger sets of physical laws (e.g., friction, conservation of momentum/energy).
- Developing physics-informed loss functions for direct enforcement of acceleration, timing, or energy constraints.
- Hybridizing generative architectures with explicit physics engines or analytic modules.
- Probing the boundary of adaptation efficiency versus model scale across different domains.

Figure 5: The gravity adapter, though trained only on vertical drops, improves physical realism for sliding cubes on inclined planes—demonstrating true generalization beyond prompt or heuristic memorization.
Conclusion
The paper establishes that leading video generative models fail to encode Earth-like gravity and systematically violate Galileo’s principle, with larger models often amplifying—not mitigating—these deficiencies. However, it also demonstrates that highly targeted, low-data adaptations can substantially correct these failures, indicating that physical law representations need not be learned ab initio but may instead require specific, principled activation. For AI systems seeking world model capabilities, robust evaluation and targeted alignment with physical laws remain essential milestones beyond scaling and perceptual quality improvements.