- The paper reveals that conventional LIF neurons act as high-frequency detectors, creating representational bottlenecks in image deraining.
- The introduction of VLIF units and hierarchical SDEM/SMU modules enhances spatial awareness and multi-scale feature representation without increasing parameters.
- Quantitative results demonstrate competitive PSNR/SSIM performance at just 13% of previous energy usage, highlighting significant efficiency improvements.
Energy-Efficient Image Deraining with Visual-Aware Spiking Neural Networks
Introduction
While Spiking Neural Networks (SNNs) are established for high-level vision tasks, their application to dense, low-level vision tasks poses unique challenges due to their event-driven, temporally sparse computation and severely limited spatial context. This paper addresses these challenges for the image deraining task and delivers a comprehensive theoretical and empirical analysis of spiking neurons in this context. It identifies the high-pass behaviour and representational bottlenecks of standard Leaky Integrate-and-Fire (LIF) neurons and introduces the Visual LIF (VLIF) unit, which incorporates spatial awareness, thereby overcoming intrinsic limitations without increasing the parameter count. These advances are leveraged in the construction of novel hierarchical and multi-scale SNN modules—the Spiking Decomposition and Enhancement Module (SDEM) and the lightweight Spiking Multi-scale Unit (SMU)—resulting in state-of-the-art performance for image deraining at a fraction of prior SNNs' energy consumption.
Analysis of Spiking Neurons in the Deraining Domain
A foundational discovery is that LIF neurons inherently operate as high-frequency detectors in image deraining. By exploiting their threshold-triggered, temporal spike aggregation, LIF neurons selectively activate for pixels dominated by high-frequency noise, which characterizes residual rain artifacts.
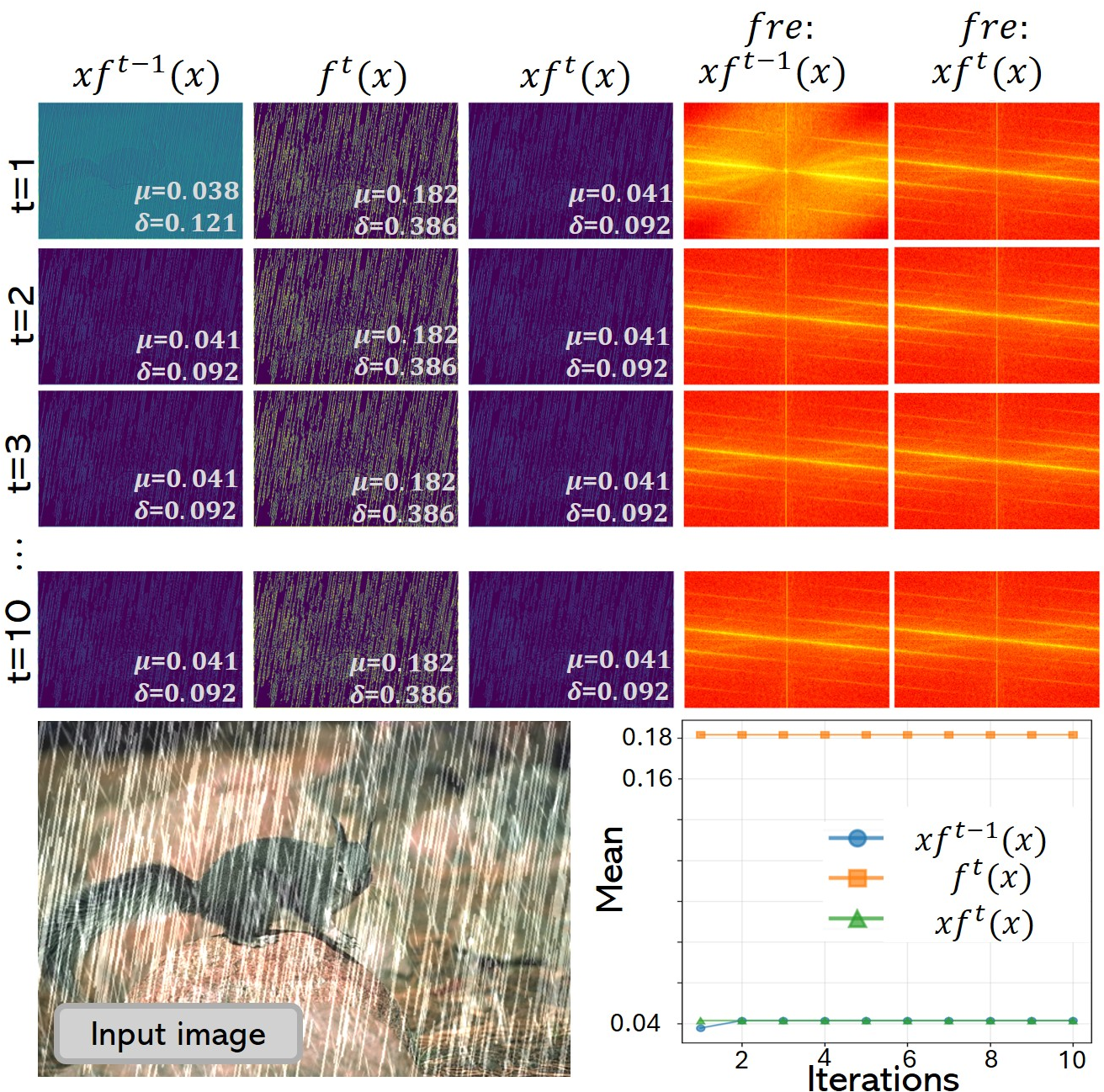
Figure 1: Frequency response characteristics of LIF neurons, highlighting high-frequency rain and exhibiting saturation after t=1.
The theoretical analysis established two key properties: high-frequency selection—the neuron’s initial application identifies prominent high-frequency rain artifacts—and frequency saturation—further applications offer no new high-frequency information due to the operator's idempotence under repeated usage. The authors formalize this behaviour, revealing a saturation effect that severely limits the representational richness of deep SNN models for deraining unless the neuron architecture is fundamentally extended.
Visual LIF: Integrating Spatial Context into Spiking Neurons
Pixel-level spatial blindness of conventional LIF neurons is shown to undermine rain structure encoding especially for spatially diffuse or low-intensity rain streaks. To address this, the paper develops the Vision-LIF (VLIF) neuron. By reorganizing feature maps via pixel unshuffle and patch-to-time conversion, spatial patches are integrated over time, thereby equipping the VLIF with receptive fields that aggregate local context before firing. This patch-based temporal pooling boosts both the spatial continuity and activation density of spiking outputs, allowing VLIF neurons to represent subtle and extended rain structures that standard LIF neurons neglect.
Figure 2: Pipeline and activation differences between LIF and VLIF neurons; VLIF produces denser, spatially coherent response maps.
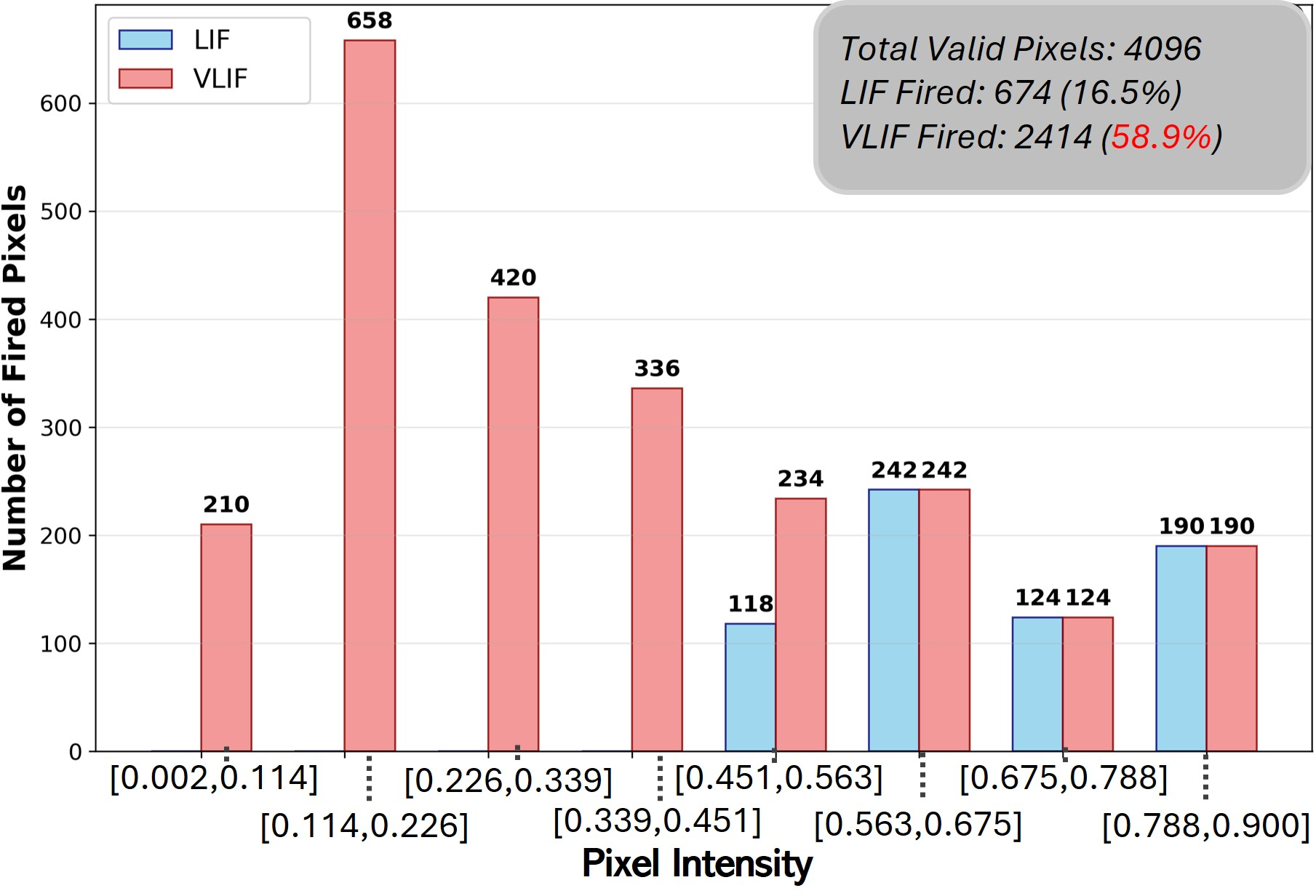
Figure 3: Comparative visualization of neuron firing rates: VLIF achieves significantly higher activation, critical for fine structure reconstruction.
The VLIF outputs are further stabilised and quantised via a normalisation procedure (NI-LIF), mitigating instability/overflow issues observed in integer-based spiking (I-LIF) approaches.
Hierarchical and Multi-scale SNN Deraining Architecture
The network leverages three core building blocks:
- Spiking Decomposition and Enhancement Module (SDEM): SDEM systematically decomposes features into high- and low-frequency components using a cascade of LIF and VLIF neurons. Stage-wise, LIF units target sharp, high-intensity rain, while VLIF units capture smoother, more contextually coherent rain structures. Complementary components are fused, followed by residual and multi-dimensional attention for enhanced representation refinement.
- Spiking Multi-scale Unit (SMU): SMU provides efficient multi-scale modulation by operating SDEM and VLIF at different resolution levels. It exploits patch-wise pooling and aggregation for combined shallow and deep context, using very few FLOPs and parameters.
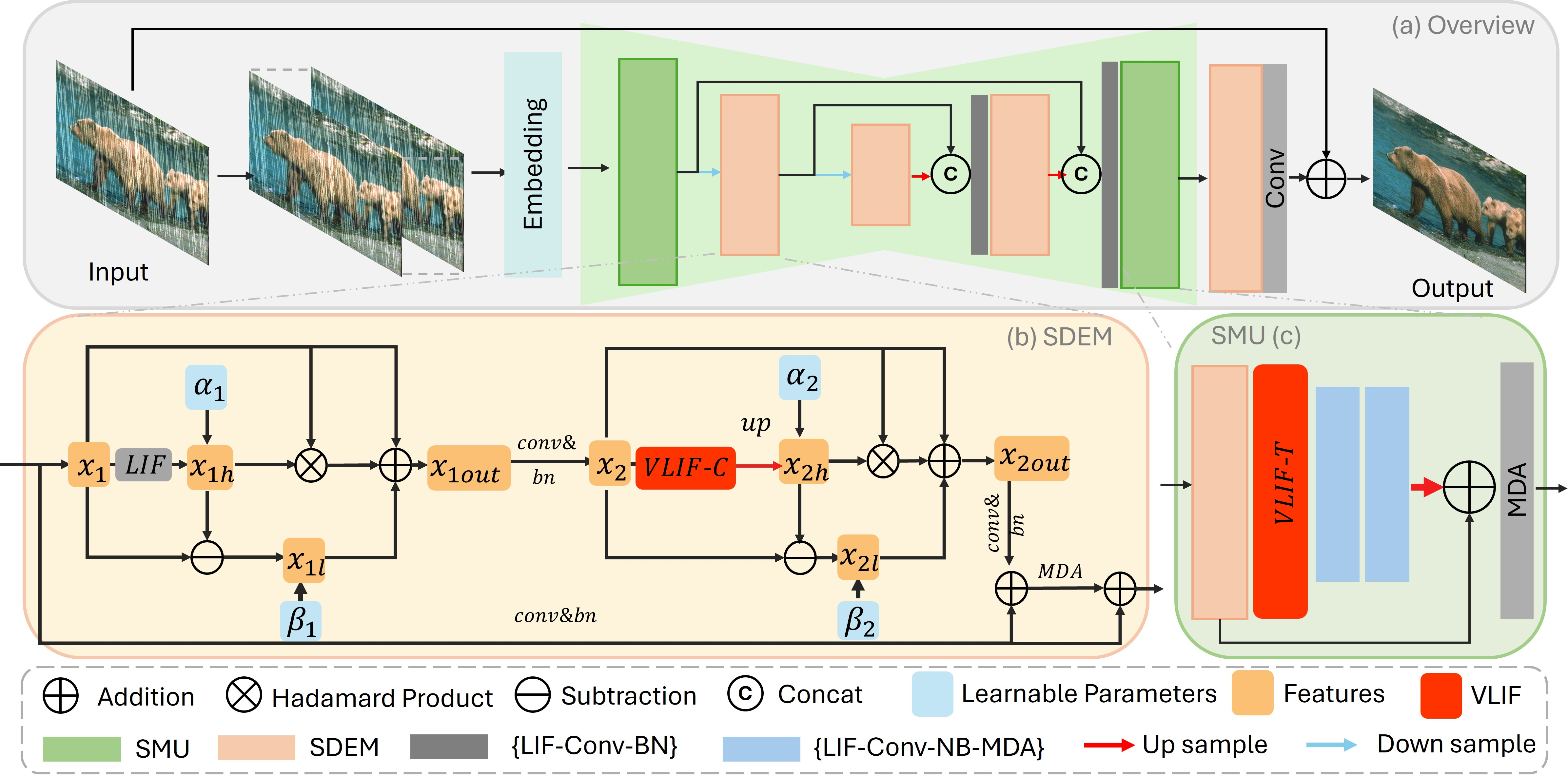
Figure 4: (a) Network architecture. (b) SDEM cascades LIF/VLIF for hierarchical frequency decomposition. (c) SMU augments multi-scale enhancement.
This design achieves rich, hierarchical representation of rain at different scales, all within a highly parameter- and energy-efficient framework.
Quantitative and Qualitative Results
The proposed SNN model decisively outperforms previous SNN-based deraining methods, closing the gap against state-of-the-art CNNs and transformer approaches, notably with an order of magnitude lower energy usage. On Rain200H, the model surpasses ESDNet with just 13% of its energy consumption while halving parameters and FLOPs. Against transformer baselines such as Restormer, it delivers competitive or superior PSNR/SSIM at less than 1.8% of the energy cost and just hundreds of kilobytes of parameter storage.

Figure 5: Qualitative comparison on Rain200H: the model produces sharper, cleaner restoration than CNN/Transformer methods.


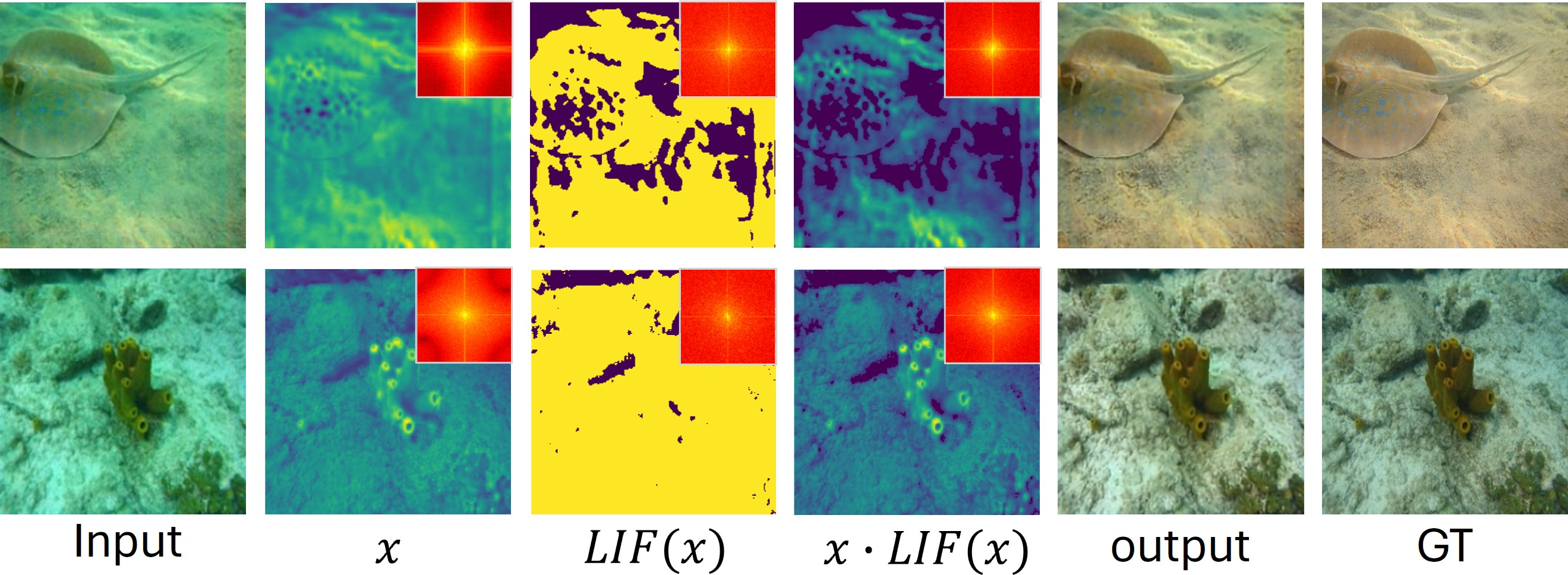
Figure 6: Real-world deraining example demonstrating robustness and generalisation to non-synthetic input.
Ablation studies demonstrate the critical role of VLIF neurons: removal of spatial aggregation (i.e., reverting to LIF) yields dramatic PSNR and SSIM degradation. Intermediate architectural elements (SDEM, SMU, temporal/channel fusion, and attention mechanisms) are all found to contribute incrementally, validating the proposed hierarchical design.
Broader Implications and Future Outlook
The findings reveal that SNNs, when extended with biologically inspired spatial context aggregation as in VLIF, can deliver strong performance in dense vision tasks previously dominated by ANNs. This positions SNNs as credible candidates for deployment on edge and power-constrained platforms in real-world computer vision applications.
Most notably, the work demonstrates that spiking neuron representations are task-adaptive in the frequency domain: for deraining, they act as high-pass detectors, while for underwater image enhancement (a low-frequency correction problem), the same network robustly identifies low-frequency features with minimal reconfiguration. This suggests SNNs can be tuned for other dense restoration domains involving frequency-based corruption or context-specific artifact removal.
The current gap to the very best ANN models persists, largely due to inherent SNN representational constraints and less mature optimization techniques. Nevertheless, the paper provides a foundational blueprint for closing this gap via advanced event-driven architectures and biologically plausible spatial-context enhancements.
Conclusion
This work rigorously advances the state of SNNs for image deraining by detailing the frequency-domain properties of LIF neurons, introducing the context-aware VLIF, and designing a full spiking architecture (SDEM/SMU) that achieves both high accuracy and extreme energy efficiency. The task-adaptive findings and generalisation experiments imply significant future prospects for SNN deployment across diverse, dense, low-level vision tasks, contingent on continued architectural and optimisation advances.
For further technical details and code, see "Exploring the Potentials of Spiking Neural Networks for Image Deraining" (2512.02258).