The AI Consumer Index (ACE)
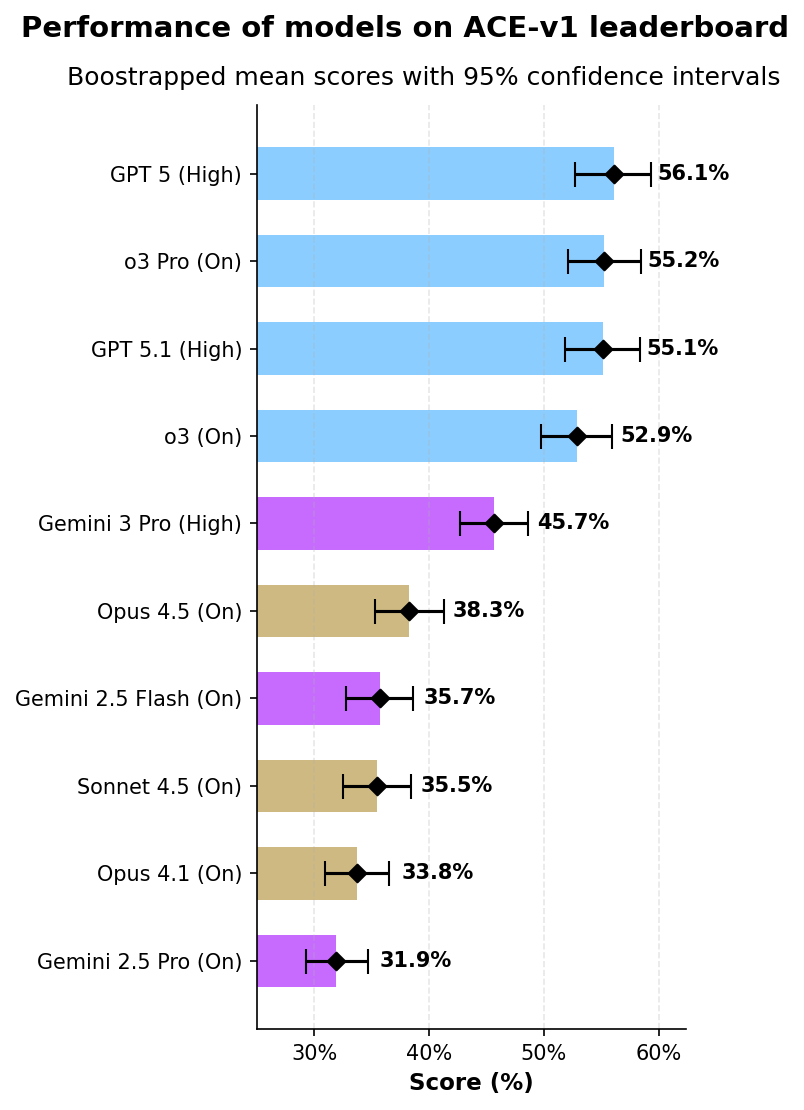
Abstract: We introduce the first version of the AI Consumer Index (ACE), a benchmark for assessing whether frontier AI models can perform everyday consumer tasks. ACE contains a hidden heldout set of 400 test cases, split across four consumer activities: shopping, food, gaming, and DIY. We are also open sourcing 80 cases as a devset with a CC-BY license. For the ACE leaderboard we evaluated 10 frontier models (with websearch turned on) using a novel grading methodology that dynamically checks whether relevant parts of the response are grounded in the retrieved web sources. GPT 5 (Thinking = High) is the top-performing model, scoring 56.1%, followed by o3 Pro (Thinking = On) at 55.2% and GPT 5.1 (Thinking = High) at 55.1%. Model scores differ across domains, and in Shopping the top model scores under 50\%. We find that models are prone to hallucinating key information, such as prices. ACE shows a substantial gap between the performance of even the best models and consumers' AI needs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces the AI Consumer Index (ACE), which is like a school test for AI assistants that people use at home. Instead of checking if AIs can solve math puzzles or write code, ACE checks if they can help with everyday tasks that real people care about—such as finding good deals when shopping, planning food, figuring out games, and doing DIY projects. The big idea: measure how useful and trustworthy AIs are for normal consumers.
Objectives: What questions are the researchers asking?
The paper sets out to answer simple, practical questions:
- Can today’s top AI models actually help with common consumer tasks?
- Do they use real information from the web and avoid making things up?
- In which areas (shopping, food, gaming, DIY) do they do well or struggle?
- What kinds of mistakes do they make (like wrong prices or broken links)?
Methods: How did they test the AIs?
Think of ACE as a carefully designed test with “secret” questions:
- The team built 400 hidden test cases across four areas: shopping, food, gaming, and DIY. They also released 80 public examples so others can try and improve.
- Each test has a persona (a short story about who the user is and what they need) and a clear request. For example: a budget shopper in Canada trying to buy a gaming laptop for a specific game.
- Experts (chefs, gamers, shoppers, tradespeople) wrote the tests and scoring rules to make them realistic and fair.
How scoring works (in everyday terms):
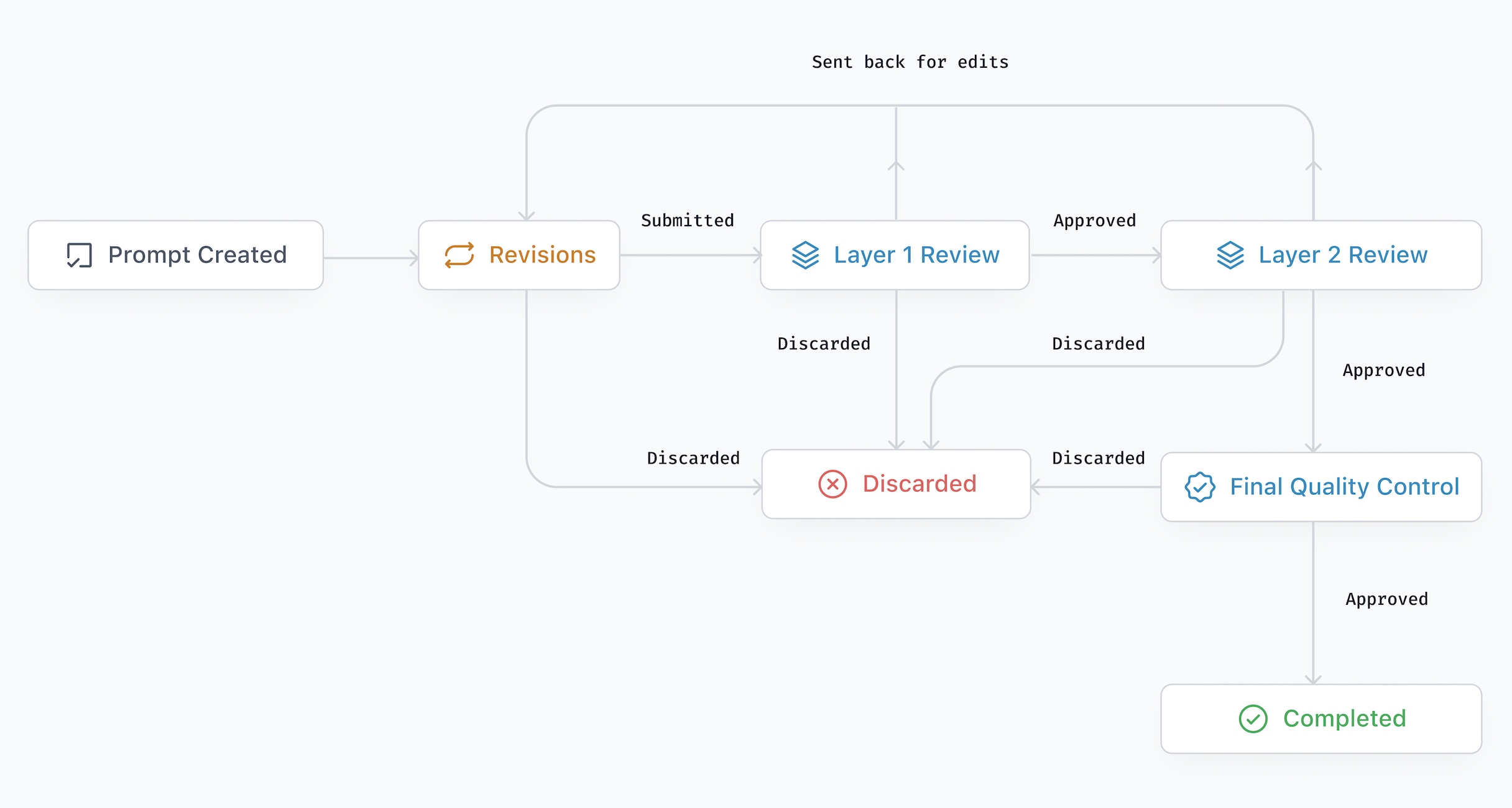
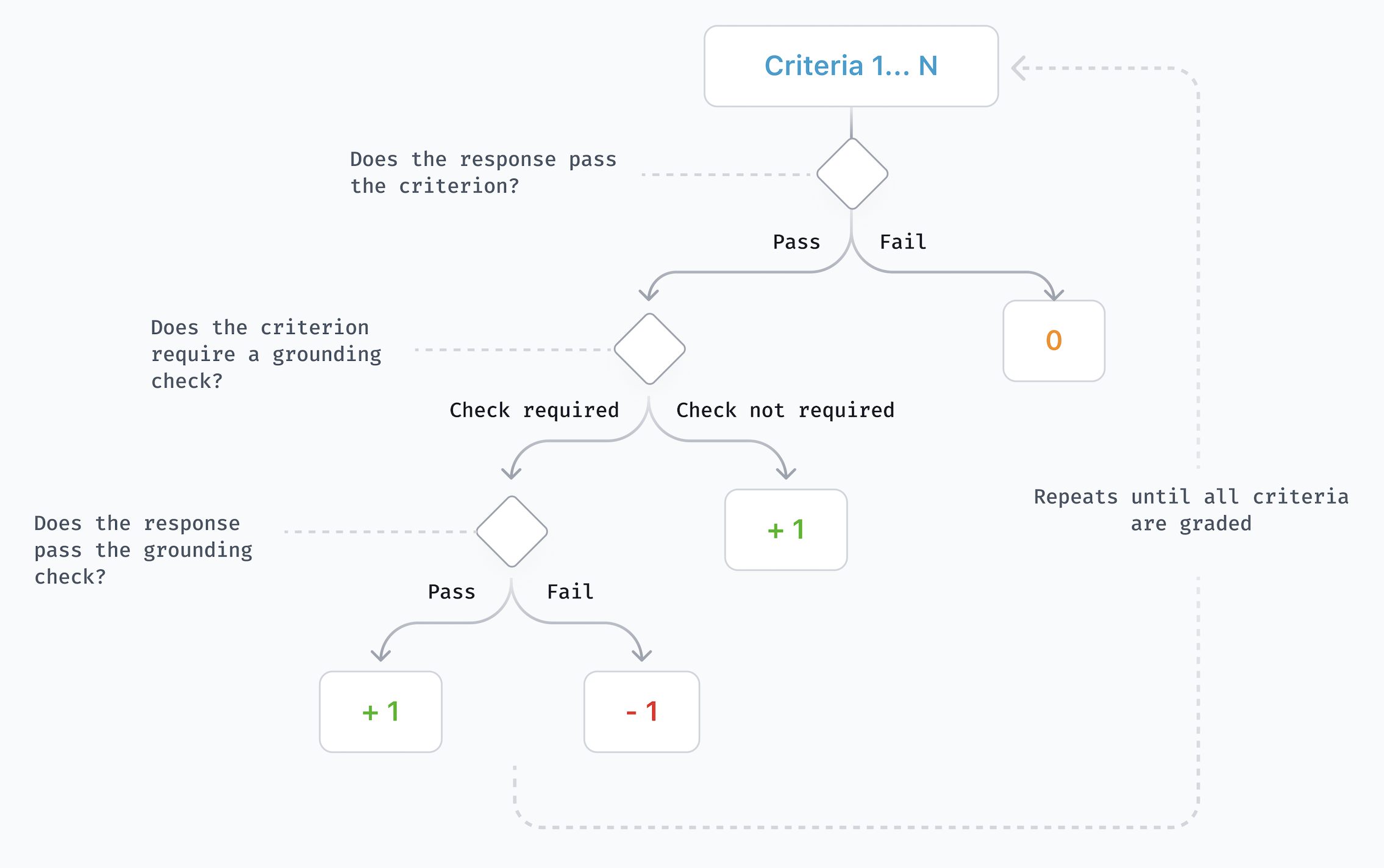
- Hurdle criteria: Like the main goal of the task. If the AI misses this, it gets a zero for that task.
- Grounding checks: If the AI claims a fact (like a price or a technical spec), the test checks whether that fact is supported by reliable web sources the AI found. If not, the AI gets a negative point for “hallucinating” (making stuff up).
- Criteria types: The test looks for different kinds of things, like “does it give a correct link?”, “does it meet the price limit?”, or “does it list the right number of items?”
Extra steps for fairness and consistency:
- Each model answered every task eight times; scores were averaged.
- A separate AI “judge” graded the answers using detailed rubrics.
- The team used a statistics method called bootstrapping (think of it as re-sampling the results many times) to estimate confidence intervals, which show how stable the scores are.
Key terms explained:
- Benchmark: A standard test used to compare performance.
- Grounding: Backing up claims with real evidence from sources.
- Hallucination: When an AI confidently gives false or unsupported information.
- Leaderboard: A ranking chart of models based on their scores.
Results: What did they find?
Big picture:
- The best model scored about 56% overall. That’s better than random, but not close to perfect.
- Scores vary by domain:
- Food was easiest (top score around 70%).
- Gaming was next (about 61%).
- DIY was mid-level (around 55–56%).
- Shopping was hardest (best score about 45%), especially when prices and product details had to be exactly right and properly sourced.
Common problems:
- Hallucinated prices and product specs: Models often guessed instead of citing reliable sources.
- Broken or bad links: Many models struggled to provide working purchase links.
- Nuanced tasks: They did fine on simple steps (like “list three items” or “give instructions”), but were weaker on tricky judgment calls (like safety warnings for DIY or compatibility details for gaming hardware).
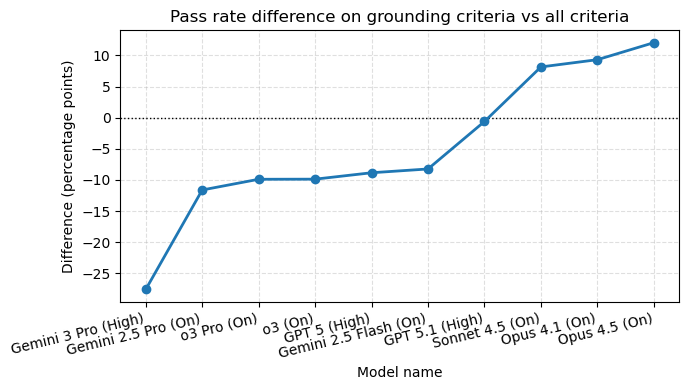
Grounding matters:
- Some models looked helpful but failed grounding checks (their facts weren’t supported by the sources).
- Other models were better at grounding but less good at meeting all the user’s requested details.
Hurdles matter:
- If a model missed the main goal, its score for that task dropped to zero, which lowered average scores by about 21%.
Public vs. hidden test sets:
- The open 80-case set was slightly easier; rankings were similar but not identical.
Why this is important
People increasingly use AI for everyday decisions—what to buy, what to cook, how to fix something, or how to play a game better. This study shows a clear gap between what consumers need (accurate, trustworthy, well-sourced help) and what even the best AI models currently deliver, especially in shopping where real prices and reliable links really matter.
Implications: What does this mean for the future?
For consumers:
- Be cautious. AI can be helpful, especially for ideas and summaries, but double-check important facts like prices, product specs, and links.
- Use AI as a starting point, not the final word—verify with trustworthy sources.
For AI developers:
- Improve grounding (make sure claims are backed by sources).
- Handle links and prices more reliably.
- Focus on nuanced tasks (safety tips, hardware compatibility, dietary details).
For research and product teams:
- Expand ACE to more areas like travel and finance, and to other formats (images, audio, video).
- Refresh tests regularly because the internet changes fast.
- Consider more realistic multi-turn conversations to capture user preferences without long personas.
- Watch out for “gaming” the leaderboard—models should climb by getting truly better for users, not by memorizing the test.
Bottom line: ACE shines a spotlight on practical, everyday AI performance. It’s a wake-up call that, while AIs are improving, there’s still a long way to go before they can be fully trusted to meet real consumer needs—especially when money, safety, and accuracy are on the line.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Validity of LM-as-judge: No quantitative validation of the judge LM’s accuracy (e.g., human audit, inter-rater reliability, error analysis by criterion type), raising uncertainty about grading correctness and potential style/vendor bias toward certain model families.
- Single judge dependency: Results rely on one judge model (Gemini 2.5 Pro, Thinking=High, Temp=0.0); there is no triangulation with multiple independent judges or a hybrid human-in-the-loop protocol to quantify judgment variance and bias.
- Grounding pipeline error rates: The paper notes “anecdotal” scraping/URL/claim-extraction errors but does not measure or report error rates, failure modes (e.g., JS-heavy sites, paywalls, CAPTCHAs, redirects), or their impact on scores per domain/criterion.
- No grounding in DIY/Food: DIY and Food criteria do not include grounding checks (0% grounded), leaving hallucinations in safety guidance, nutrition facts, and recipe constraints unpenalized; it is unclear how often models fabricate critical information in these domains.
- Negative scoring design choices: The -1 penalty for ungrounded claims is unvalidated against user harm; there is no sensitivity analysis on alternative penalty weights, thresholding rules, or partial credit schemes and how these choices alter rankings and conclusions.
- Hurdle stage-gating calibration: Failing a hurdle zeroes an entire task, but there’s no assessment of false negatives (partially useful outputs that miss one hurdle), nor a study of how hurdle selection/wording changes difficulty and rank stability.
- Retrieval vs reasoning disentanglement: Models use their own web-search stacks; there is no controlled condition where all models reason over the same fixed, time-stamped source bundle to isolate reasoning quality from retrieval differences.
- Reproducibility under internet drift: Web content changes over time; there is no archival of scraped pages, claim-link mappings, or content snapshots to enable exact reruns, nor analysis of how re-evaluation at different times shifts scores.
- Sensitivity to configuration: Model settings vary (thinking budgets, temperature for Gemini only, system prompts unspecified); the paper does not report ablations to quantify configuration sensitivity or ensure fairness across providers.
- Statistical significance of ranks: While bootstrapped means and CIs are reported, there is no pairwise significance testing of model differences (overall and per domain), nor an analysis of rank robustness given high run-to-run variance (mean SD ~16.4%).
- Run aggregation choice: Results use the mean over 8 runs; the paper does not compare median, trimmed mean, or best-of-k aggregation, nor evaluate how sampling variance and outliers affect final rankings.
- Coverage gaps: Only four domains (Shopping, DIY, Gaming, Food) and text-only modality are included; finance, travel, healthcare-adjacent consumer tasks, multimedia (images/audio/video), and device-embedded voice use cases are missing.
- Language, locale, and accessibility: The dataset appears English-centric with limited regional diversity (e.g., Halifax example); there is no evaluation across languages, currencies, tax regimes, regional availability, accessibility needs, or non-Western markets.
- Persona representativeness: Personas are expert-authored; there is no evidence of representativeness across demographics, cultures, budgets, or constraints, nor analysis of bias amplification or disparate performance across persona types.
- Real-world task realism: Prompts include added specification text to make evaluation fair but less realistic; multi-turn dialog, implicit preferences, and incomplete/ambiguous user inputs are not evaluated despite being dominant in consumer settings.
- End-to-end outcome metrics: The benchmark emphasizes factual and rubric compliance but does not measure real-world consumer outcomes (e.g., successful purchases, cost/time savings, safety incidents avoided, satisfaction, trust, or engagement).
- Price and availability dynamics: Shopping scores penalize hallucinated prices/links, but there is no standardized protocol for tax/shipping computation, regional price variability, out-of-stock handling, or vendor comparisons across time.
- Link validity criteria: “Provide link(s)” is penalized for broken/hallucinated links, yet the paper does not specify robust link-validation rules (handling redirects/shorteners, canonicalization, dynamic content) or report false positive/negative rates.
- Partial credit for multi-item recommendations: The standard requires all recommended items meet all constraints; there is no exploration of graduated scoring (e.g., proportion meeting constraints) that may better reflect consumer utility.
- Taste and subjective quality: Claims that models struggle with “nuanced matters of taste” lack a validated measurement framework for subjective alignment and preference modeling; open question on incorporating human preference judgments.
- Contamination monitoring: The paper flags contamination risk but does not implement or report safeguards (e.g., watermarking, leakage detection, test-time prompt similarity checks) or measure potential overfitting to open dev cases.
- Safety evaluation depth: DIY safety warnings are a criterion, but there is no systematic safety audit (e.g., hazard identification, risk severity scoring, regulatory compliance, contraindications), nor escalation guidance when tasks exceed DIY skill/safety.
- Fairness across providers: Using a Google judge to evaluate OpenAI/Anthropic outputs may introduce vendor-related biases; the paper does not assess cross-judge agreement or deploy balanced judging ensembles from multiple providers.
- Retrieval tool transparency: Differences in provider browsing/search stacks (engines, scraping, citation formatting) are not documented or normalized, leaving unclear how toolchain design impacts grounding success.
- Benchmark maintenance policy: While the paper notes the need to refresh ACE, there is no formal update cadence, versioning scheme, deprecation policy, or longitudinal tracking plan to compare progress under stable conditions.
- Public reproducibility assets: Beyond code and dev set, key artifacts (claim-link pairs per response, scraped content, adjudications, judge prompts, error logs) are not released, limiting independent verification and bias/variance analysis.
Practical Applications
Immediate Applications
Below are specific, deployable applications that leverage ACE’s findings, methods, and artifacts (dev set, evaluation harness, grounding checks, rubrics, and workflow taxonomy). Each item notes relevant sectors and any key assumptions/dependencies that affect feasibility.
- ACE-driven model selection and procurement
- Application: Use ACE scores by domain to choose models for consumer-facing assistants (e.g., prefer models with higher Food/Gaming scores for those use cases; avoid unverified price quoting in Shopping where top scores are <50%).
- Sectors: Software, Retail/e-commerce, Consumer tech platforms.
- Tools/Workflows: Procurement playbooks that include ACE domain benchmarks as acceptance criteria.
- Assumptions/Dependencies: Access to model APIs; acceptance that held-out set is not public; reliance on ACE’s LM-as-judge approach.
- Grounding-first product QA for consumer assistants
- Application: Embed ACE-style dynamic grounding checks to block hallucinated claims (especially prices and specs) before responses are shown to users.
- Sectors: Retail/e-commerce, Consumer apps, Marketplaces, Comparison shopping sites.
- Tools/Workflows: “GroundingGuard” pipeline using ACE’s claim extraction + link verification; link-health checks; evidence cards referencing source URLs and timestamps.
- Assumptions/Dependencies: Reliable scraping (Firecrawl/SearchAPI analogs), access to web search and provider grounding metadata, handling of dynamic pages; policy for what to do when sources conflict.
- Hurdle-first UX and evaluation gates
- Application: Adopt ACE’s “hurdle” criteria concept as a stage gate in CI/CD and live trust layers (e.g., do not render an answer if the core user goal isn’t satisfied).
- Sectors: Software, Platforms with AI chat/agents, Customer support tooling.
- Tools/Workflows: CI checks that compute hurdle-pass rate; rollbacks if hurdle metrics regress; “core goal satisfied?” gating in runtime.
- Assumptions/Dependencies: Ability to define domain-specific hurdles; LM-as-judge or deterministic validators for these hurdles.
- Safer shopping flows with price provenance
- Application: Require grounded price quotes with source links and timestamps; disable or clearly label prices when grounding fails; auto-fallback to “view price on retailer page.”
- Sectors: Retail/e-commerce, Affiliate/advertising, Fintech budgeting tools.
- Tools/Workflows: Price provenance tags in UI; automated dead-link detectors; regional tax calculation modules (as per prompt constraints like “after tax”).
- Assumptions/Dependencies: Stable URLs; frequent price volatility; legal/compliance review on quoting third-party prices.
- Content design using ACE workflow taxonomy
- Application: Use ACE’s domain workflows to shape consumer AI features (e.g., Shopping: Bargain Hunting, Gifting; Food: Meal Plans; DIY: Repairs; Gaming: Tactics).
- Sectors: Product management for consumer AI; Education and community apps; Game publishers/communities.
- Tools/Workflows: Prompt patterns that explicitly state constraints and checklists; spec appendices from ACE added to prompts (“please explicitly state whether…”).
- Assumptions/Dependencies: Users may not provide explicit personas in real life; may require UI that elicits constraints.
- Continuous benchmarking in CI/CD with bootstrapped, multi-run scoring
- Application: Integrate ACE’s open-source eval harness to routinely test new model versions or prompt/agent changes using multi-run sampling and bootstrapped confidence intervals.
- Sectors: Software, MLOps, Model evaluation services.
- Tools/Workflows: Automated nightly benchmarks on ACE-v1-dev; dashboards for “hurdle pass rate,” “grounding pass rate,” “broken link rate.”
- Assumptions/Dependencies: The held-out set remains hidden; dev set coverage is smaller and slightly easier; model variance across runs requires multiple samples.
- Academic experiments on grounding and LM-as-judge reliability
- Application: Use ACE-v1-dev and harness to study hallucination patterns, judge model choice, and the effect of negative scoring for ungrounded claims.
- Sectors: Academia (NLP, HCI, evaluation science).
- Tools/Workflows: Compare judge LMs; ablate grounding penalties; release replication packages.
- Assumptions/Dependencies: Acceptance of LM-as-judge limitations; measurement error in scraping/grounding.
- Policy and audit test cases for consumer protection
- Application: Regulators and consumer rights orgs can run ACE-style audits on shopping assistants to assess grounded pricing and link validity; publish “dead-link rate” and “hallucinated pricing rate.”
- Sectors: Public policy, Consumer protection, Standards bodies.
- Tools/Workflows: Audit protocols derived from ACE rubrics; reporting templates for transparency.
- Assumptions/Dependencies: Authority to test third-party systems; internet dynamism requires periodic re-testing.
- Instructional materials for AI literacy and safer use
- Application: Teach users to ask for sources, prices with citations, benchmark scores (e.g., CPU/GPU marks), and to verify links—mirroring ACE rubrics.
- Sectors: Education, Public sector digital literacy programs.
- Tools/Workflows: Classroom exercises using ACE dev prompts; consumer checklists for shopping/gaming/DIY/food tasks.
- Assumptions/Dependencies: Dev set is sufficient for pedagogy; keeping examples up-to-date as products change.
- Developer SDKs for claim-link normalization
- Application: Reuse ACE’s approach to normalize provider grounding schemas and extract referenced URLs across model vendors in one pipeline.
- Sectors: Software tools, Integrators, Multi-model platforms.
- Tools/Workflows: Open-source adapters that convert provider schemas to a unified format; claim extraction APIs.
- Assumptions/Dependencies: Providers expose grounding metadata; changes in provider schemas require maintenance.
- Safety-by-default in DIY and food guidance
- Application: Automatically check for presence of safety warnings (DIY) and accurate dietary info (Food) with rubric-based validators; hard-block content missing critical safety notes.
- Sectors: DIY platforms, Recipe/meal planning apps, Smart home assistants.
- Tools/Workflows: Safety rule checkers per workflow; “must-have warnings” lists; escalation to human review.
- Assumptions/Dependencies: Domain expertise to define safety criteria; liability considerations.
- Community and game publisher content QA
- Application: Enforce grounded links and compatibility checks for gaming guides; detect hallucinated strategy claims and broken links.
- Sectors: Gaming, Content platforms, Esports communities.
- Tools/Workflows: ACE-like validators on user-submitted guides; automatic citation extraction and verification.
- Assumptions/Dependencies: Game patches change tactics/compatibility; frequent re-validation needed.
- Data generation and training signal shaping
- Application: Use ACE-like penalties in RL/reward models to discourage ungrounded claims, especially around pricing, specs, and links.
- Sectors: AI model training, Foundation model fine-tuning.
- Tools/Workflows: Reward shaping signals from grounding checks; adversarial datasets with decoy links/prices.
- Assumptions/Dependencies: Access to model training loops; compute for iterative RL; avoiding contamination with held-out cases.
- Daily life practice for consumers
- Application: Personal checklists for AI shopping and DIY queries: request citations, confirm live prices via provided links, and ask the assistant to explicitly state which requirements are met.
- Sectors: Daily consumer use.
- Tools/Workflows: Browser extensions that highlight cited claims and validate links on the fly.
- Assumptions/Dependencies: Users willing to click through and verify; extensions must be maintained as sites change.
Long-Term Applications
These opportunities require further research, scaling, or coordination (standards, policy, or technology maturation).
- Consumer AI certification and trust labels
- Application: Establish an ACE-based certification (e.g., “ACE-Verified for Shopping”) with domain thresholds for grounding, link validity, and hurdle pass rates.
- Sectors: Standards bodies, Retail/e-commerce, Consumer tech platforms.
- Tools/Workflows: Independent test labs; periodic recertification; public scorecards embedded in product pages.
- Assumptions/Dependencies: Industry buy-in; governance for test set secrecy and renewal; guarding against benchmark gaming.
- Regulatory guardrails for price/spec claims
- Application: Incorporate grounding requirements for quoted prices, availability, and compatibility into advertising/consumer protection rules (e.g., FTC guidance).
- Sectors: Policy, Legal/regulatory, Compliance.
- Tools/Workflows: Compliance auditing based on ACE-like rubrics; mandatory disclosures for price timestamps and sources.
- Assumptions/Dependencies: Jurisdictional harmonization; technical capacity for audits.
- Multimodal, multi-turn ACE expansions
- Application: Extend ACE to images/audio/video and multi-turn interactions (e.g., DIY with photos, game clips, or shopping via screenshots).
- Sectors: Software, AR/VR, Robotics-adjacent consumer support.
- Tools/Workflows: Multimodal grounding (e.g., OCR, ASR), visual claim verification; dialog-state aware evaluation.
- Assumptions/Dependencies: Reliable multimodal models; new scraping/parsing capabilities; updated safety criteria.
- Domain expansions to finance, travel, and healthcare-adjacent diets
- Application: ACE-like benchmarks for consumer finance (budgeting, loan comparisons), travel planning (TripScore synergy), and medical-grade dietary advice.
- Sectors: Finance, Travel, Healthcare/nutrition.
- Tools/Workflows: Highly specific rubrics (e.g., APR calculations, visa constraints); compliance and safety gates.
- Assumptions/Dependencies: High bar for safety and regulatory compliance; expert-validated ground truth and sources.
- Model architectures optimized for retrieval-grounded generation
- Application: Train/tune models to prefer grounded content, integrate real-time aggregators (prices/specs), and self-evaluate with ACE-like signals.
- Sectors: AI model R&D, Search/RAG platforms.
- Tools/Workflows: Self-grounding critics; retrieval policies that prioritize authoritative sources; link reliability scoring.
- Assumptions/Dependencies: Access to high-quality retrieval indices/APIs; mitigating latency and cost.
- Cross-provider grounding metadata standards
- Application: Define an open schema for grounding evidence across model vendors (W3C-like standard), enabling universal claim verification.
- Sectors: Standards consortia, AI providers, Integrators.
- Tools/Workflows: Shared JSON schema for citations, content snapshots, confidence scores.
- Assumptions/Dependencies: Provider cooperation; IP and privacy considerations; backwards compatibility.
- Continuous, auto-refreshing evaluation infrastructure
- Application: Always-on ACE benchmarking that re-runs tests as the web changes; detects capability drift and data staleness.
- Sectors: MLOps, Model governance, Compliance.
- Tools/Workflows: Scheduled scrapes and re-evals; drift dashboards; SLA-backed thresholds.
- Assumptions/Dependencies: Budget for compute and scraping; legal constraints on crawling; data versioning.
- Risk scoring for deployment and insurance
- Application: Use ACE-derived metrics (e.g., hallucinated price rate) to quantify operational and legal risk; insurers and platforms set deployment gates.
- Sectors: Insurance, Platform governance, Enterprise risk.
- Tools/Workflows: Risk models tied to grounding/hurdle metrics; premium discounts for certified systems.
- Assumptions/Dependencies: Historical incident data; alignment with legal liabilities.
- Personal AI orchestration with task-specialized model routing
- Application: Agents that route tasks to models with the best ACE domain scores (e.g., different models for Food vs. Shopping) and degrade gracefully when grounding fails.
- Sectors: Consumer AI assistants, OS-level agents.
- Tools/Workflows: Meta-controller that consults ACE scores; fallback strategies; user-facing uncertainty indicators.
- Assumptions/Dependencies: Access to multiple providers; latency/cost optimization; consistent grounding interfaces.
- Proactive safety and compliance validators
- Application: Automatic detection/flagging of missing DIY safety warnings, diet-medication conflicts, or incompatible gaming hardware—before output reaches users.
- Sectors: DIY platforms, Health-adjacent apps, Gaming hardware.
- Tools/Workflows: Domain-specific rule engines + LM verification; human-in-the-loop escalation for high-risk cases.
- Assumptions/Dependencies: Expert-authored rules; liability frameworks; robust false-positive handling.
- Education and public literacy at scale
- Application: National curricula and consumer campaigns that teach ACE-style rubric thinking for evaluating AI outputs, especially when money or safety is at stake.
- Sectors: Education, Public sector, NGOs.
- Tools/Workflows: Open courseware; browser plug-ins that guide verification steps in context.
- Assumptions/Dependencies: Institutional adoption; funding; keeping content current.
- AR-guided DIY and robotics-adjacent assistants with verified steps
- Application: AR overlays for home repairs or crafts that present step-by-step, safety-checked instructions grounded in vetted sources; potential integration with home robotics.
- Sectors: AR/VR, Consumer robotics, Smart home.
- Tools/Workflows: Multimodal grounding, sensor feedback, step validation checkpoints.
- Assumptions/Dependencies: Mature AR hardware/software; reliable object recognition; robust safety models.
- Financial planning-aware shopping agents
- Application: Agents that couple grounded price discovery with budgets/taxes/shipping to make end-to-end buying decisions under constraints.
- Sectors: Fintech, Retail/e-commerce.
- Tools/Workflows: Tax and shipping calculators; budget constraints as hurdles; provenance-preserving carts.
- Assumptions/Dependencies: Access to authoritative tax/shipping APIs; consent and data privacy management.
Notes on feasibility across applications:
- LM-as-judge reliability and measurement error remain active issues; any deployment should monitor judge variance and implement human spot checks for critical paths.
- Internet dynamism means frequent re-validation, caching strategies with timestamps, and explicit “as of” disclosures are essential.
- Open dev set (80 cases) supports reproducible research but is smaller and slightly easier than the held-out set; avoid overfitting product metrics to dev-only outcomes.
- Scraping and citation practices must respect site terms and applicable laws; where feasible, prefer structured APIs over scraping.
Glossary
- ACE: The AI Consumer Index; a benchmark assessing whether frontier AI models can perform high-value consumer tasks. "We introduce the first version of the AI Consumer Index (ACE), a benchmark for assess- ing whether frontier AI models can perform high-value consumer tasks."
- ACE leaderboard: The public ranking of models evaluated on ACE. "For the ACE leaderboard we evaluated 10 fron- tier models (with websearch turned on) us- ing a novel grading methodology..."
- ACE-v1-dev: The open-source development subset of ACE used for research and reproducibility. "We call this ACE-v1-dev."
- ACE-v1-heldout: The hidden test set of ACE reserved for leaderboard evaluation to reduce contamination and overfitting. "ACE contains a heldout set of 400 tasks, which we call ACE-v1-heldout."
- benchmark: A standardized evaluation suite that measures model performance on defined tasks. "We introduce the first version of the AI Con- sumer Index (ACE), a benchmark for assess- ing whether frontier AI models can perform high-value consumer tasks."
- bootstrapped means: Mean estimates computed by resampling to quantify uncertainty and stabilize reported scores. "We use the bootstrapped means for the leaderboard, which vary by less than 0.1% from the non-boostrapped means."
- confidence intervals: Statistical ranges indicating uncertainty around estimated performance metrics. "To calculate 95% confidence intervals, we boot- strap the data 10,000 times with a sample of 400 cases for the overall benchmark and 100 cases for the domain-specific results."
- contamination risk: The danger that models or training data include evaluation content in advance, compromising fairness. "6.2. Contamination risk"
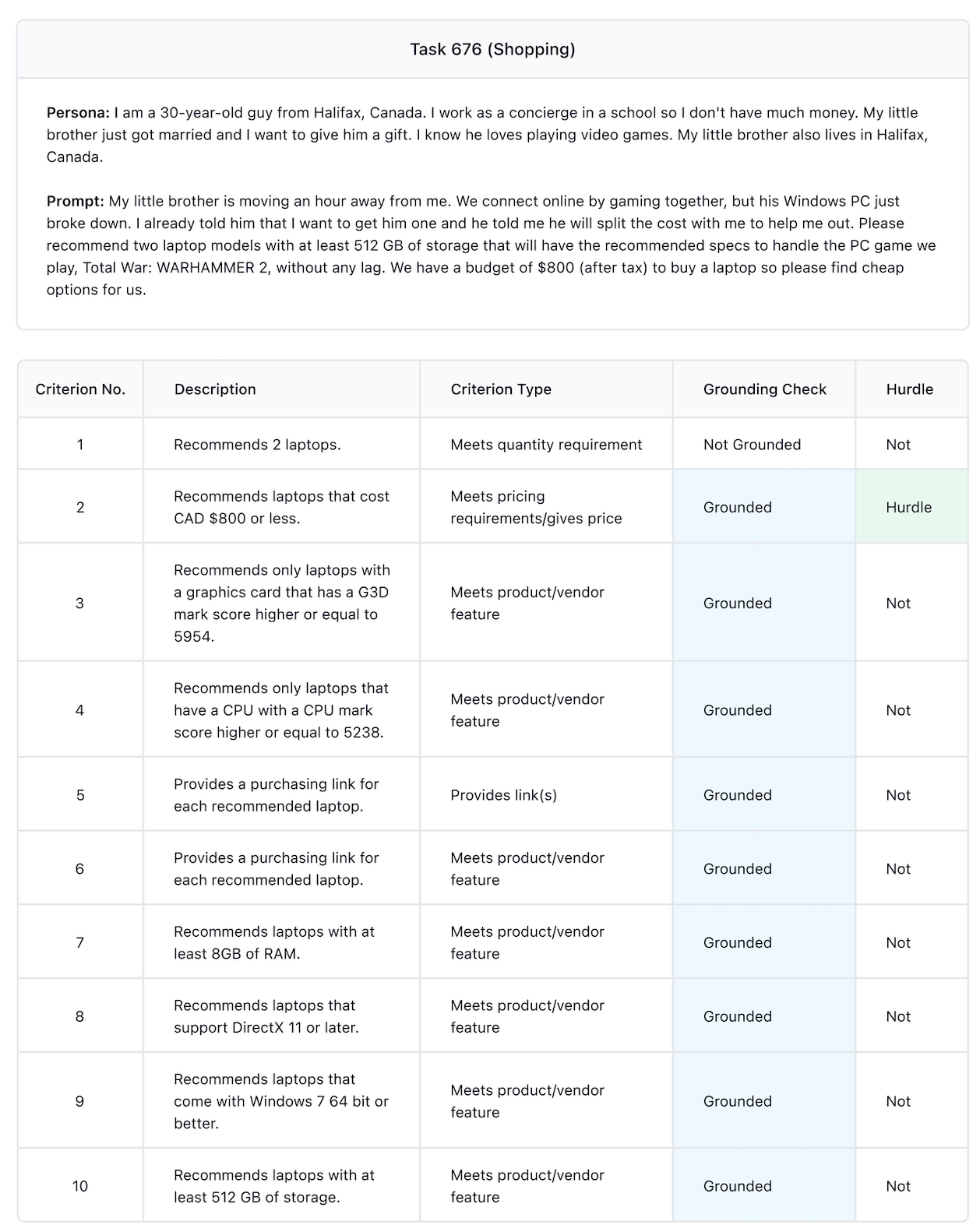
- CPU mark score: A synthetic benchmark metric indicating CPU performance used to check hardware suitability. "Recommends only laptops that have a CPU with a CPU mark score higher or equal to 5238."
- criterion type: A label categorizing each rubric criterion by the kind of requirement it assesses. "using a newly developed taxonomy of cri- teria, the criterion type (i.e., meeting a requested quantity, meeting a product feature, or returning a link)."
- DirectX 11: A Microsoft graphics API version requirement for game compatibility. "Recommends laptops that support DirectX 11 or later."
- eval harness: The tooling/framework that executes evaluations and standardizes provider outputs for reproducibility. "We are also making our eval harness open source for full reproducibility."
- G3D mark score: A synthetic GPU performance benchmark used to ensure graphics capability for gaming tasks. "Recommends only laptops with a graphics card that has a G3D mark score higher or equal to 5954."
- grounding: The practice of supporting model claims with evidence from retrieved web sources. "Our grading methodology is hierarchical to minimize reward hacking. It involves (1) checking for hurdles and (2) checking grounding."
- grounding check: A verification step to determine whether a claim is supported by the cited sources. "If a grounding check is needed, step three is to assess whether the content of the response is actually grounded in the web sources."
- grounding criteria: Rubric items that explicitly require factual support from external sources. "Grounding criteria appear in Gaming (42%) and Shopping (74%) tasks."
- hallucinating: Producing fabricated or unsupported information presented as fact. "We show models are prone to hallucinating key information, such as prices."
- heldout set: A hidden evaluation subset withheld from public release to preserve test integrity. "ACE contains a heldout set of 400 tasks..."
- hurdle criteria: Must-pass rubric items that gate scoring, representing the core task objective. "Hurdle criteria are not inherently more challenging; on average, models pass the same percentage of per task hurdles as the non-hurdle criteria."
- judge LM: A LLM used to grade and score other models’ responses. "All scores are independently graded by a judge LM."
- overfitting: When a model tailors behavior too closely to a test set, reducing generalization. "It is hidden to minimize the risk of contamination and overfitting."
- persona: A user profile in prompts that provides context and constraints to guide model responses. "Each prompt contains a persona, describing the background and primary objective of the user, and a request."
- prompt specification: Additional standardized instructions appended to prompts to clarify user expectations. "The prompt specification is customized to each workflow within the domains."
- reward hacking: Exploiting evaluation mechanics to gain points without genuinely satisfying task intent. "Our grading methodology is hierarchical to minimize reward hacking."
- stagegated: A scoring setup where failing a predefined gate results in zero score on the task. "However, because they are stagegated (i.e., models score 0% on a task if they fail the hurdle), the hurdles make a substantial difference to overall scores."
- taxonomy of workflows: A structured categorization of common task types to ensure dataset diversity. "For each domain in ACE we developed a taxonomy of workflows to ensure dataset diversity and to bet- ter understand common AI consumer use cases."
- Thinking = High: A model configuration enabling an extended reasoning mode for generation. "GPT 5 (Thinking = High) is the top- performing model..."
- Thinking budget: The maximum allocated reasoning tokens/steps for a model’s thought process. "Thinking budgets, where available, are set to max (24k for Gemini 2.5. Flash, 32k for Gemini 2.5. Pro and Opus 4.1, 64k for Sonnet 4.5 and Opus 4.5)."
- web search: Enabling models to query the internet and ground responses in live sources. "All models are tested with web search enabled."
Collections
Sign up for free to add this paper to one or more collections.