- The paper demonstrates that sparse attention post-training dramatically reduces active attention edges while maintaining predictive performance.
- The methodology applies constrained optimization via GECO to enforce sparsity on attention heads in pre-trained LLMs.
- Experimental results show similar logit attribution scores with a fraction of connectivity, offering enhanced mechanistic interpretability.
Sparse Attention Post-Training for Mechanistic Interpretability
Introduction
This paper introduces a novel methodology for enhancing the interpretability of LLMs by imposing sparsity on attention mechanisms post-training. The main contribution lies in a post-training regime that refines transformer attention into sparse patterns without compromising the model's performance. This approach leverages sparsity to expose a more structured connectivity pattern, thereby making the internal workings of LLMs more interpretable for mechanistic analysis.
Sparse Attention and Sparsity Regularization
The study derives inspiration from the need to make complex neural networks more interpretable. Mechanistic interpretability has made progress by reverse-engineering neural networks, uncovering interpretable circuits within large models. However, the intrinsic complexity of LLMs remains a bottleneck. The authors propose applying a sparsity regularization as a post-training strategy, effectively simplifying the global circuit by reducing the number of active components such as attention heads and multi-layer perceptrons (MLPs).
Their method employs a sparsity constraint optimized through a constrained-loss objective, aiming to retain performance while minimizing connectivity to a small fraction of its original state. Evaluation shows dramatic reductions in connectivity—with attention maps reduced to approximately 0.3% of their original edges—without degrading predictive accuracy. The implication is clear: much of the computational power of transformers is redundant, and a structured approach to sparsity reveals a more interpretable algorithmic structure.
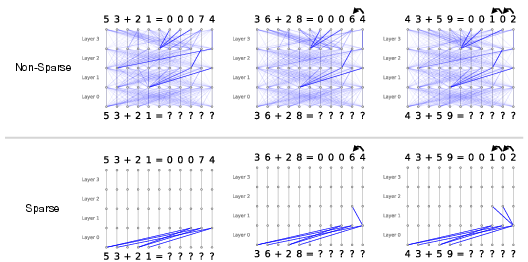
Figure 1: Simple example showing the attention patterns of sparse and non-sparse transformers trained on a two-digit addition task, highlighting the improved interpretability of the sparse model.
Methodology and Sparse Attention Layer
Central to the authors' methodology is the Sparse Transformer architecture, which utilizes sparsity-regularized hard attention. The goal is to establish sparse attention as a functional replacement for traditional softmax attention. This architectural choice supports loading pre-trained LLM weights at initialization, ensuring seamless integration without loss of initial performance. The procedure ensures that the post-training models maintain performance metrics akin to their dense counterparts.
Constrained optimization played a critical role, using the Generalized Expression for Constrained Optimization (GECO) algorithm. This allows the model to balance sparsity and performance dynamically, adapting regularization strength based on real-time evaluation against a performance threshold.
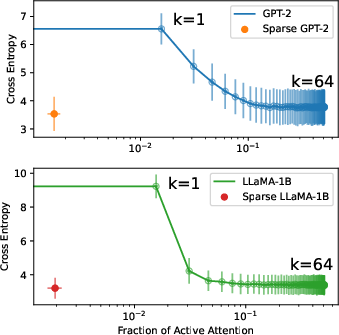
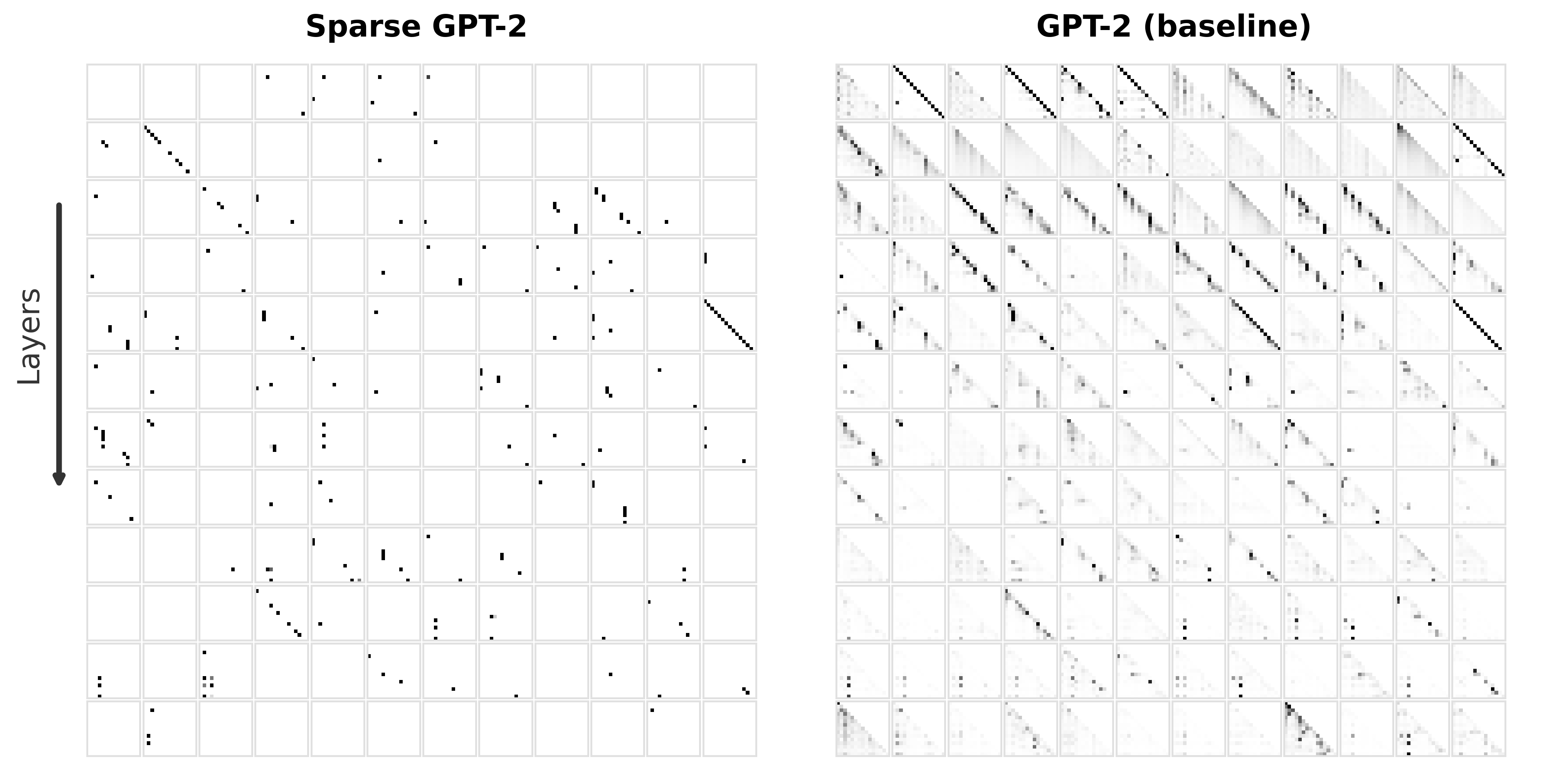
Figure 2: Cross-entropy loss with respect to the mean proportion of non-zero attention edges, comparing dense and sparse attention patterns.
Experimental Evaluation
The experimental evaluation involved fine-tuning pre-trained models such as GPT-2 and LLaMA3-1B on the OpenWebText dataset. The models demonstrated that sparse attention could preserve performance levels while significantly reducing active attention edges, effectively consolidating information flow.
Notably, sparse models required far fewer attention heads to achieve similar logit attribution scores compared to dense models. This efficiency indicates a condensed and focused computational pathway facilitated by sparse attention.
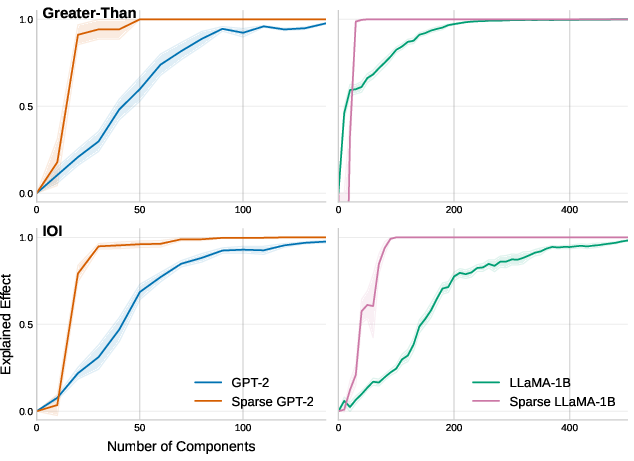
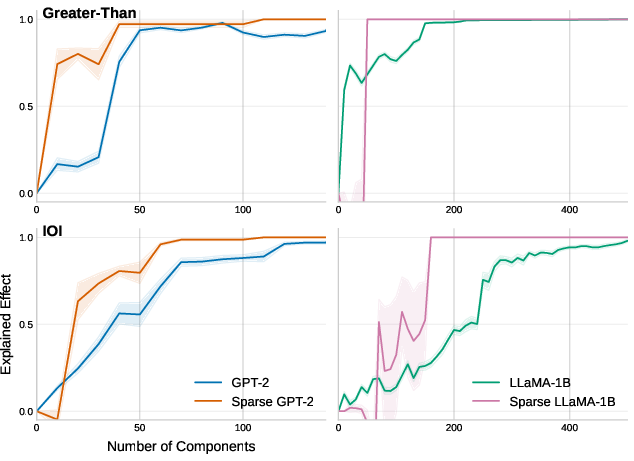
Figure 3: Logit attribution showing the efficiency of top-k attention heads selected via activation patching scores.
Discussion and Implications
The findings of this study assert that sparsity in attention mechanisms not only maintains but often enhances interpretability. Task-specific circuits become significantly smaller, allowing for more accessible mechanistic interpretations without degrading model efficacy. Such a transformation in model structure simplifies the task of aligning these vast systems with desirable behaviors and outcomes.
Moreover, the authors posit that sparse attention could be a critical tool in future explorations of cross-layer analyses and circuit-tracing approaches in complex model architectures. Extending this approach to other components, such as MLPs, or applying it in conjunction with distillation and low-rank adaptation methods could further enhance model interpretability and efficiency.
Conclusion
This paper presents a compelling case for employing sparsity constraints as a post-training adjustment to transformer models, opening new pathways for interpretability and analysis. By orchestrating a more structured and parsimonious attention mechanism, LLMs can be made both effective and interpretable, potentially advancing the field of AI towards more transparent and comprehensible architectures. Future work should explore scaling these techniques to even larger models, further pushing the boundaries of what is possible in model interpretation and alignment.