World Models That Know When They Don't Know: Controllable Video Generation with Calibrated Uncertainty
Abstract: Recent advances in generative video models have led to significant breakthroughs in high-fidelity video synthesis, specifically in controllable video generation where the generated video is conditioned on text and action inputs, e.g., in instruction-guided video editing and world modeling in robotics. Despite these exceptional capabilities, controllable video models often hallucinate - generating future video frames that are misaligned with physical reality - which raises serious concerns in many tasks such as robot policy evaluation and planning. However, state-of-the-art video models lack the ability to assess and express their confidence, impeding hallucination mitigation. To rigorously address this challenge, we propose C3, an uncertainty quantification (UQ) method for training continuous-scale calibrated controllable video models for dense confidence estimation at the subpatch level, precisely localizing the uncertainty in each generated video frame. Our UQ method introduces three core innovations to empower video models to estimate their uncertainty. First, our method develops a novel framework that trains video models for correctness and calibration via strictly proper scoring rules. Second, we estimate the video model's uncertainty in latent space, avoiding training instability and prohibitive training costs associated with pixel-space approaches. Third, we map the dense latent-space uncertainty to interpretable pixel-level uncertainty in the RGB space for intuitive visualization, providing high-resolution uncertainty heatmaps that identify untrustworthy regions. Through extensive experiments on large-scale robot learning datasets (Bridge and DROID) and real-world evaluations, we demonstrate that our method not only provides calibrated uncertainty estimates within the training distribution, but also enables effective out-of-distribution detection.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching powerful video-generating AI models to “know when they don’t know.” These models can make future video frames based on what they’re told or what actions a robot plans to take. That’s useful for things like testing robot strategies or imagining what might happen next. But sometimes the videos they create contain mistakes that don’t match reality—called hallucinations. The authors build a method that helps the model estimate its confidence for every tiny part of every frame, so we can see which parts of the video are trustworthy and which parts might be wrong.
Key Questions and Goals
The paper aims to answer simple but important questions:
- Can a video AI say how sure it is about each part of the video it generates?
- Can those confidence estimates be accurate (not too confident, not too shy)?
- Can the AI highlight exactly where its guesses are uncertain or likely wrong?
- Will this still work when the AI sees something new it wasn’t trained on?
How They Did It (Methods Explained Simply)
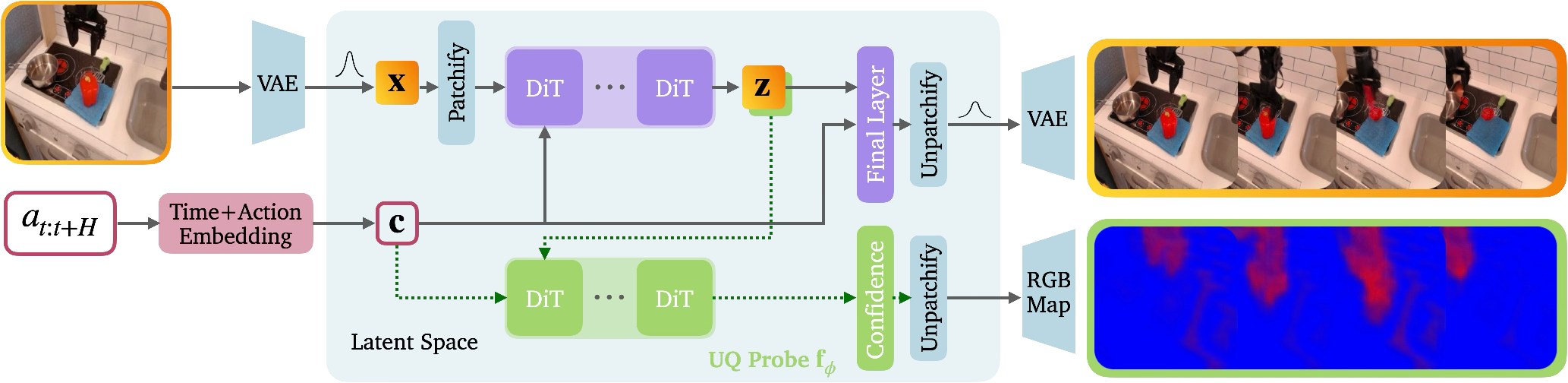
Think of the video model as a “world predictor” that tries to imagine future frames based on the first frame and the next actions (like a robot moving its arm). The authors add a “confidence helper” to this predictor:
- Latent space: Instead of working directly with full-size pixels (which is slow and expensive), the model works in a compressed space—like a secret code or a thumbnail version of the video that keeps important information. This makes training faster and more stable.
- Confidence probe: They plug in a small network (the “confidence helper”) that looks at the model’s internal signals and outputs a confidence score for each tiny region (subpatch/channel) of the video. This gives dense, detailed confidence across the frame.
- Proper scoring rules: Think of checking a weather forecast. If someone says “60% chance of rain” and it rains 60% of the times they say that, they’re well-calibrated. The authors train the model using “fair scoring systems” that reward honest confidence. This makes the model’s “I’m 80% sure” line up with reality.
- Visual confidence heatmaps: They convert the model’s confidence in the compressed space back into a simple color map you can see on the video:
- Blue: high confidence it’s correct
- Red: uncertain
- Green: high confidence it’s wrong (a likely hallucination)
They test a few versions:
- Fixed-scale: one chosen accuracy level.
- Multi-class: several levels (bins) of accuracy.
- Continuous-scale: any accuracy level you ask for at test time.
All versions learn to pair good predictions with honest confidence.
Main Findings and Why They Matter
Here’s what they discovered through experiments on large robot datasets (Bridge and DROID) and real robot tests:
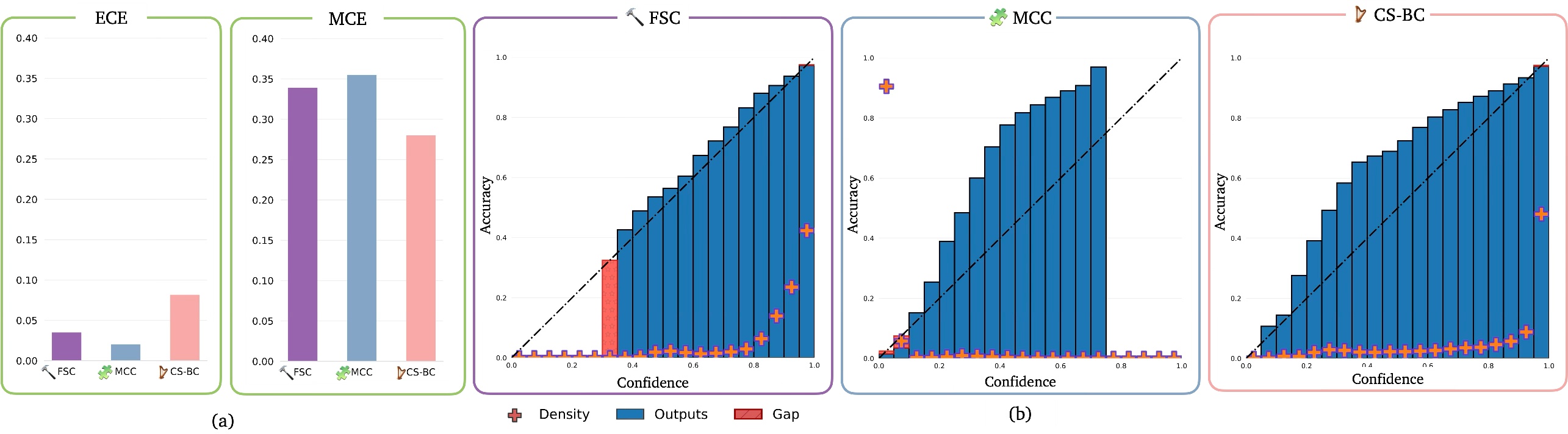
- The model’s confidence is calibrated. When it says “70% sure,” it is right about 70% of the time. They measure this with standard calibration tools (like ECE and MCE), and the errors are low.
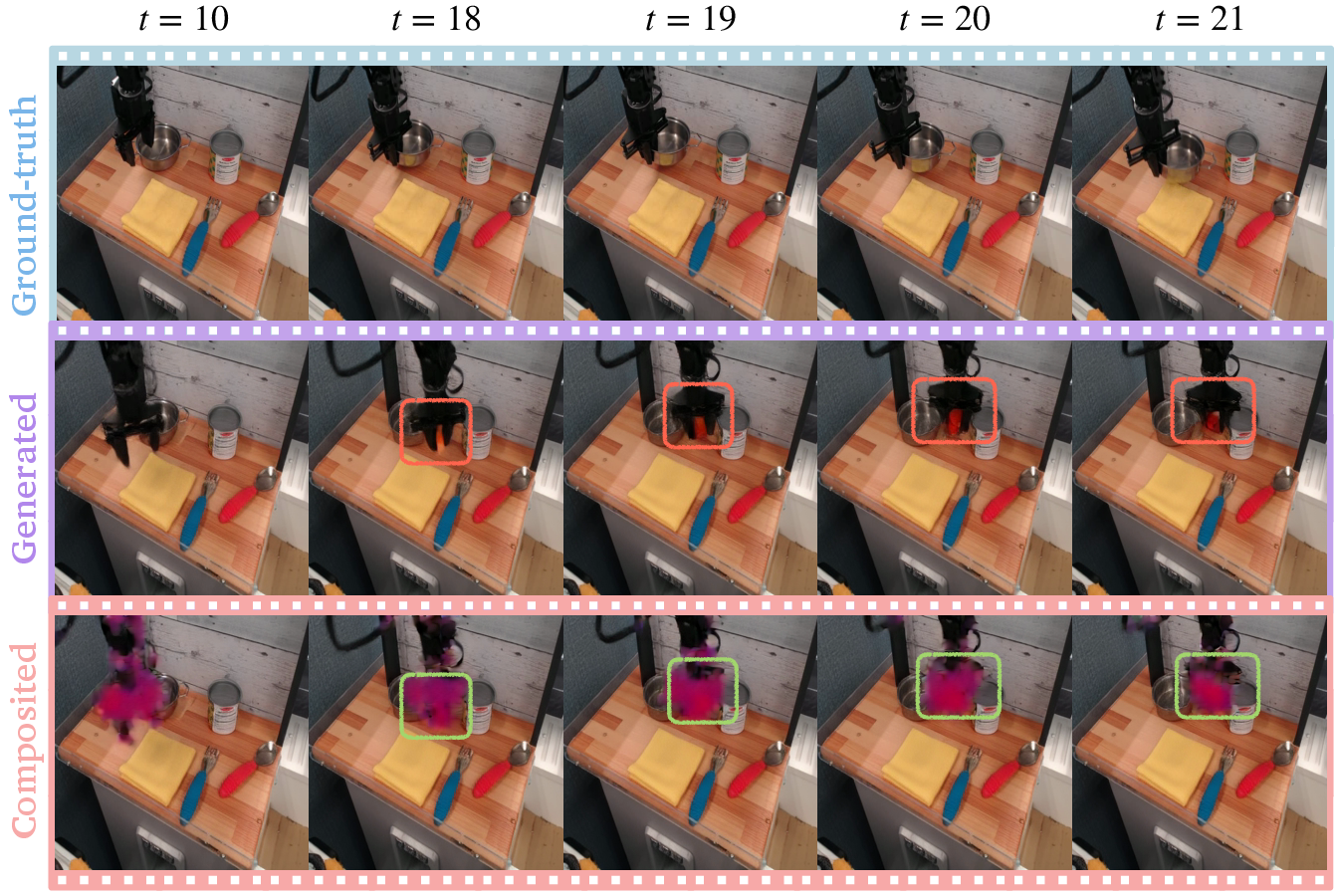
- The confidence maps are interpretable. The heatmaps light up uncertain areas exactly where you’d expect:
- Moving robot parts and objects (harder to predict than static backgrounds)
- Grasped or deformable objects
- Occlusions (hidden areas) and tricky lighting
- It detects hallucinations. Green areas flag places the model is confidently wrong—so you can spot untrustworthy patches quickly.
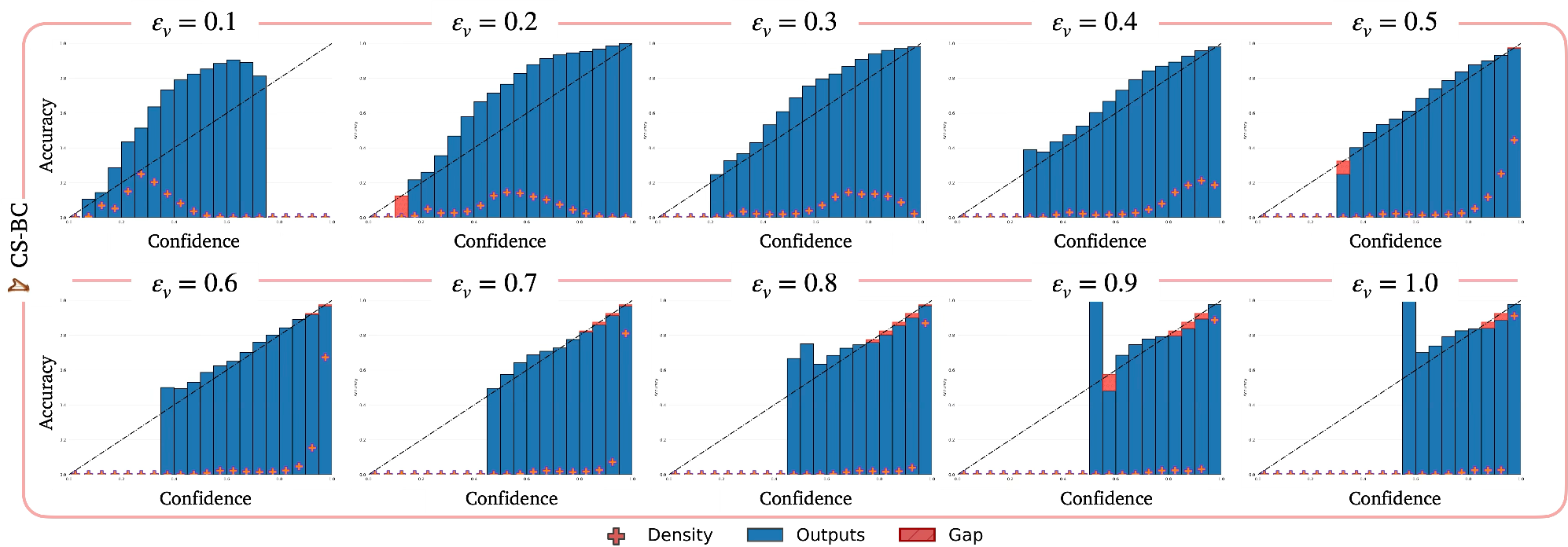
- It works out of distribution (OOD). When the scene changes (new background items, different lighting, unusual objects, or modified robot appearance), the model becomes more uncertain, and its confidence remains well-calibrated. That’s a good sign it won’t pretend to be sure in unfamiliar situations.
- It scales. Because it operates in the compressed (latent) space and uses efficient training, it’s practical for large, modern video models.
Implications and Impact
This work helps make video-generating models safer and more trustworthy—especially for robotics. If a robot plans actions using imagined future videos, knowing which parts of those videos are reliable (and which aren’t) can prevent bad decisions. Calibrated confidence lets people and systems:
- Focus attention on risky parts of a plan or prediction
- Avoid acting on likely hallucinations
- Detect when the model sees something new and is unsure
- Build better tools for robot policy evaluation, planning, and visual foresight
In short, this paper teaches world-modeling AIs to honestly say, “Here’s what I think will happen—and here’s where I might be wrong,” which is a big step toward trustworthy AI in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide actionable future research:
- Theoretical guarantees are limited to calibration of the probe’s predicted confidence under convergence; there is no finite-sample or model-misspecification analysis of calibration quality for the end-to-end video generator plus UQ probe.
- Calibration is defined on an element-wise latent-space accuracy event; there is no formal linkage to pixel-space error, perceptual metrics (e.g., LPIPS, FVD), or task-relevant quantities (e.g., object pose/contact accuracy, policy success probability).
- The method treats uncertainty as a single probability of being “accurate” under a threshold; there is no decomposition of aleatoric vs. epistemic uncertainty, nor a way to quantify model uncertainty due to limited data vs. inherent ambiguity.
- Multi-modal futures are not explicitly handled: evaluation compares one sampled rollout against one ground truth, risking mislabeling plausible alternative futures as “inaccurate” and potentially biasing calibration.
- Temporal calibration is not analyzed: no assessment of how calibration degrades across time steps/horizon length (e.g., early vs. late frames).
- Spatial calibration granularity is “subpatch” at the latent channel level; there is no study of how uncertainty resolution depends on patch size, latent tokenization, or decoder receptive fields, and no validation that subpatch confidence maps align with semantically coherent pixel regions.
- The “accuracy” event is defined using latent L1 deviation; the sensitivity of calibration to this choice (versus LPIPS, perceptual color/luminance metrics, or feature-space distances) is untested.
- Latent-to-RGB uncertainty visualization relies on a simple color map built from monochrome encodings; its fidelity as a mapping from latent confidence to human-interpretable pixel-space uncertainty is not validated (e.g., via user studies or quantitative alignment with pixel-space error).
- No method is provided to learn an uncertainty decoder explicitly trained to map latent confidence into calibrated pixel-space uncertainty with ground-truth supervision.
- Threshold-conditioned training (continuous-scale) still uses discretization during training; there is no analysis of how threshold sampling strategies, bin widths, or class imbalance affect calibration across the continuous spectrum at test time.
- The multi-class variant exhibits under-supervision in high-error bins; there is no remedy explored (e.g., reweighting, focal/proper losses for imbalanced bins, adaptive binning) or principled bin-edge selection.
- Proper scoring rules are used, but no comparison to alternative proper losses (e.g., CRPS, focal-proper losses) or post-hoc calibration (e.g., temperature scaling, isotonic regression) is provided.
- The probe uses a stop-gradient from the generator; there is no systematic study of joint vs. decoupled training on both generator accuracy and calibration, or of potential representation collapse/shortcut learning in the probe.
- The approach assumes access to penultimate-layer DiT features; portability to other architectures (GANs, autoregressive, open-source/non-accessible internals, closed models) is claimed but not demonstrated.
- Generalization beyond action-conditioned robotics is untested (e.g., text-to-video, human motion, natural scenes); transferability across domains with different latent tokenizers and data statistics remains unknown.
- The method depends on a pre-trained VQ-VAE tokenizer; the impact of tokenizer choice (codebook size, compression ratio, temporal modules) on uncertainty localization and calibration is not analyzed.
- Runtime and memory overhead for dense UQ are not reported; feasibility for real-time planning/control (latency per frame, GPU/edge constraints) remains unknown.
- Long-horizon scaling (hundreds of frames) is not evaluated; how calibration and uncertainty drift with horizon length and sampling temperature/guidance is unexplored.
- OOD detection is demonstrated qualitatively and with reliability diagrams, but lacks standard quantitative OOD metrics (e.g., AUROC, AUPR, FPR@95%TPR) and threshold selection protocols for detection vs. abstention.
- OOD shifts are limited and small-scale (50 trajectories, 5 axes); generality to stronger or combined shifts (e.g., dynamics changes, action-distribution shifts, camera pose/sensor noise, weather/lighting extremes) is untested.
- No comparison to baseline UQ methods (ensembles, MC dropout, diffusion-variance proxies, mutual information estimates, conformal risk control) on calibration, coverage, and OOD detection.
- There is no conformal prediction layer to provide finite-sample coverage guarantees (e.g., per-pixel or region-level calibrated prediction sets) or to translate confidence into actionable safety bounds.
- Safety integration is not evaluated: how to use uncertainty for planning (e.g., risk-sensitive MPC, uncertainty-aware cost shaping), policy evaluation filtering, or policy switching/abstention is not explored.
- Decision-making thresholds for “trust vs. abstain” are unspecified; no sensitivity analysis for setting per-pixel/frame/trajectory thresholds tied to downstream task risk is provided.
- Multi-view settings (DROID) are not analyzed for cross-view consistency of uncertainty; methods to fuse or enforce geometric coherence of uncertainty across cameras are absent.
- The relationship between sample-wise stochasticity in diffusion sampling and predicted confidence (variance–confidence alignment) is not examined; does confidence correlate with sample dispersion across multiple stochastic draws?
- Effects of classifier-free guidance strength, noise schedules, diffusion forcing, and sampling temperature on both accuracy and calibration are not systematically studied.
- Robustness to sensor noise, compression artifacts, motion blur, and occlusions is only qualitatively shown; no robustness benchmarks or stress tests are reported.
- Subgroup calibration is not measured: calibration across environments, object categories, lighting, and robot embodiments may differ; no fairness-style calibration audits are provided.
- The method does not quantify how history length or conditioning modalities (e.g., proprioception, depth) affect uncertainty quality; no ablation on history/context vs. calibration.
- The mapping from channel-wise latent uncertainty to pixel-space may blur or mislocalize uncertainty due to decoder mixing; no deconvolution or attribution method is used to align uncertainty with specific pixels/objects.
- No study of how uncertainty correlates with downstream planning errors (e.g., predicted vs. actual object pose/contact errors) or with real task failure modes (e.g., grasp failure) is provided.
- The approach provides probabilities over a binary “within ε” event; richer uncertainty representations (e.g., predictive intervals, quantiles, continuous error distributions) are not explored.
- Hyperparameter sensitivity (learning rates, weighting between generator/UQ losses, codebook parameters) and calibration stability across seeds/data sizes are not reported.
- There is no investigation into adversarial or hard-negative cases where the generator hallucinates confidently; conditions that induce miscalibrated overconfidence remain unidentified.
- Data efficiency is unquantified: how calibration improves with dataset size, curriculum strategies, or synthetic augmentation is unknown.
- No public benchmark or standardized protocol is proposed for dense spatiotemporal calibration of video models, hindering reproducible comparison across methods.
Practical Applications
Immediate Applications
Below is a set of actionable, sector-linked use cases that can be deployed now with the paper’s method (C-Cubed UQ: calibrated, dense uncertainty estimation for controllable video generation in latent space), along with key assumptions that may affect feasibility.
- Confidence-aware robot policy evaluation and visual planning (Robotics; Software)
- What: Integrate dense, calibrated uncertainty maps into world-model-based evaluation of generalist robot policies and visual planning to flag untrustworthy regions in predicted rollouts and penalize high-uncertainty areas in planning costs.
- How: Use subpatch-level uncertainty heatmaps to gate execution, select safer plans, and prioritize human review for uncertain segments.
- Tools/workflows: “Uncertainty Dashboard” for reliability (ECE/MCE, reliability diagrams), “Confidence Gate” in planners, automatic triage of high-uncertainty rollouts.
- Assumptions/dependencies: Access to action-conditioned latent-space video models (e.g., DiT + VQ-VAE), sufficient compute for inference-time UQ, domain-appropriate accuracy thresholds, and calibration using proper scoring rules.
- Runtime OOD detection and safety monitors for deployed robots (Robotics; Manufacturing; Logistics; Smart Home)
- What: Detect distribution shifts (lighting, background, clutter, end-effector appearance, novel objects) and raise alerts or trigger safe-stop behaviors when uncertainty spikes.
- How: Threshold-based alarms on aggregated uncertainty, spatial localization of OOD-induced hallucinations in predicted frames.
- Tools/workflows: “OOD Monitor” service, on-robot uncertainty logging, human-in-the-loop escalation.
- Assumptions/dependencies: Camera reliability, representative training distribution, known thresholds for acceptable uncertainty, and fallback policies.
- Active learning and dataset curation for robot video datasets (Academia; Industry ML Ops)
- What: Use per-frame confidence to identify samples that are hard or uncertain; prioritize those for labeling, re-collection, or augmentation.
- How: Uncertainty-driven sampling strategies to improve data coverage of dynamic interactions and occlusions; targeted collection of underrepresented scenes.
- Tools/workflows: “Uncertainty Sampler” for Bridge/DROID-like datasets, semi-automatic labeling pipelines focused on uncertain frames.
- Assumptions/dependencies: Labeling budget, scalable data pipelines, support for domain-specific augmentations.
- Model debugging and QA for controllable video generation (Media/VFX; Software)
- What: Surface hallucinations and artifacts via heatmaps to accelerate QA and reduce post-production errors in action-guided video edits.
- How: Overlay confidence maps on generated videos; route high-uncertainty segments to manual review or alternative generation strategies.
- Tools/products: “Confidence Overlay” plugin for editing suites, batch QA scripts to report uncertainty statistics per shot.
- Assumptions/dependencies: Integration with latent-space video models; reliable latent-to-RGB mapping; acceptance of probabilistic overlays in creative workflows.
- Standardized calibration reporting in academic benchmarks (Academia; Open-Source)
- What: Include ECE/MCE, reliability diagrams, and uncertainty–error correlation in controllable video model papers and leaderboards.
- How: Adopt proper scoring rules (Brier, CE/BCE) in training; publish calibration artifacts with code and model cards.
- Tools/workflows: Benchmark protocols for Bridge/DROID-like data; “Calibration Report” templates.
- Assumptions/dependencies: Community consensus on metrics; reproducible training setups; shared latent tokenizers.
- Risk-aware robot demos and deployment checklists (Policy; Industry)
- What: Require uncertainty overlays and calibration metrics in robot demos; use uncertainty thresholds in safety checklists prior to deployment.
- How: Document OOD detection performance; set operational thresholds for acceptable uncertainty in target environments.
- Tools/workflows: “Uncertainty Readiness Checklist,” demo audit forms with calibration evidence.
- Assumptions/dependencies: Organizational buy-in; minimal overhead for producing calibration reports; clear threshold-setting guidelines.
- Consumer-facing uncertainty overlays in AI video editing (Daily Life; Creative Tech)
- What: Help users spot artifacts by toggling a confidence heatmap overlay in AI video editing and enhancement tools.
- How: Simple UI control to display per-pixel uncertainty; auto-suggest re-generation or manual adjustments in low-confidence areas.
- Tools/products: “Confidence View” in consumer editors; lightweight inference mode using the UQ probe.
- Assumptions/dependencies: Latent-space editor integration; friendly color mapping; clear user education on interpretation.
Long-Term Applications
Below are strategic applications that likely require further research, scaling, formalization, or productization before broad deployment.
- Certifiable safety with calibrated generative world models (Robotics; Policy; Safety Engineering)
- What: Formal risk bounds on generative rollouts using calibrated uncertainty; certifiable controllers that only act within validated uncertainty regimes.
- How: Combine C-Cubed UQ with conformal prediction or verification; formalize contracts between uncertainty thresholds and execution policies.
- Tools/workflows: “Certifiable Planner” toolchain; compliance-ready safety dossiers.
- Assumptions/dependencies: Formal methods integration; strong domain shift handling; regulator-approved testing protocols.
- Uncertainty-aware reinforcement learning and exploration (Robotics; Software)
- What: Use dense uncertainty to drive exploration and sample-efficient training (e.g., prioritize uncertain interactions, avoid highly confident trivial states).
- How: Incorporate uncertainty as intrinsic reward or risk penalty; adapt training curricula to uncertainty profiles.
- Tools/workflows: “Confidence-Guided RL” pipeline; curriculum schedulers tied to uncertainty statistics.
- Assumptions/dependencies: Stable coupling between UQ and policy learning; careful handling to prevent degenerate exploration; compute budgets.
- UQ-as-a-Service for generative models (Software; MLOps; Platform)
- What: Offer SDKs and managed services to plug calibrated uncertainty into third-party generative video models (and eventually multimodal).
- How: Standard APIs for latent-feature extraction, proper scoring rule training, runtime monitors and dashboards.
- Tools/products: “Generative UQ SDK,” managed dashboards, alerting systems.
- Assumptions/dependencies: Broad model compatibility; data privacy guarantees; vendor ecosystem buy-in.
- Cross-domain expansion to autonomy and immersive tech (Autonomous Driving; AR/VR; Healthcare Robotics; Energy/Inspection)
- What: Apply calibrated uncertainty to predictive rendering (AR/VR), surgical robot simulation planning, and inspection drones planning under visual prediction.
- How: Adapt action-conditioned video models per domain; extend UQ probes to multi-view, multi-modal inputs.
- Tools/workflows: Domain-specific tokenizers; multi-sensor fusion with uncertainty overlays; risk-weighted planners.
- Assumptions/dependencies: High-quality domain datasets; real-time constraints; clinical/regulatory approvals (healthcare).
- Media integrity and robust deepfake forensics (Media; Policy; Security)
- What: Use per-pixel uncertainty signatures to flag generative artifacts, mismatches, and manipulations; support provenance tools.
- How: Train detectors that correlate uncertainty maps with authenticity signals; include uncertainty-based risk scoring in content pipelines.
- Tools/workflows: “Uncertainty-Forensics” toolkit; integration with provenance standards (e.g., C2PA-like initiatives).
- Assumptions/dependencies: Robust mapping of latent uncertainty to interpretable cues; standardized content metadata.
- Regulatory standards for uncertainty reporting in generative robotics and media (Policy; Standards)
- What: Establish guidelines for uncertainty calibration, OOD detection performance reporting, and operational thresholds for deployment.
- How: Draft standards on required metrics (ECE/MCE, reliability diagrams), test protocols, and disclosure formats.
- Tools/workflows: Industry consortia; certification programs; periodic audits.
- Assumptions/dependencies: Cross-sector consensus; measurable benefits to safety and transparency; practical compliance processes.
- Hardware acceleration for real-time uncertainty estimation on edge devices (Robotics; Embedded Systems)
- What: Optimize UQ probes and latent tokenizers for real-time performance on robot controllers and cameras.
- How: Model compression, quantization, transformer acceleration, specialized co-processors.
- Tools/products: “Edge UQ Accelerator,” hardware-software co-design kits.
- Assumptions/dependencies: Viable latency targets; energy constraints; robust performance under compression.
- Multimodal uncertainty for rich interaction modeling (Robotics; Multimodal AI)
- What: Extend C-Cubed UQ to jointly handle audio, haptics, depth, and language inputs for more reliable manipulation and interaction planning.
- How: Unified latent spaces with multimodal probes; cross-sensor uncertainty fusion.
- Tools/workflows: “Multimodal UQ” frameworks; sensor calibration suites.
- Assumptions/dependencies: Aligned multimodal tokenizers; synchronized data; more complex calibration objectives.
Notes on overarching dependencies:
- Calibration quality depends on proper scoring rule training and convergence; extreme OOD conditions will lower calibration.
- Interpretability of pixel-space uncertainty maps hinges on encoder/decoder choices and color-map design; misaligned tokenizers can degrade visualization.
- Action-conditioned datasets are critical in robotics; multi-view setups improve uncertainty localization but increase complexity.
- Real-time viability requires careful optimization; ensemble- or MC-based methods are generally infeasible at scale, hence latent-space probes are preferred.
Glossary
- Action-conditioned video generation: Video synthesis conditioned explicitly on action sequences to control future frames. Example: "action-conditioned generation"
- Aleatoric uncertainty: Uncertainty due to inherent randomness in data or observations that cannot be reduced with more data. Example: "epistemic and aleatoric uncertainty"
- Binary cross entropy (BCE): A loss function for binary probabilistic predictions that penalizes the log-likelihood of incorrect labels. Example: "binary cross entropy"
- Brier score: A strictly proper scoring rule measuring the mean squared error of probabilistic forecasts. Example: "Brier score loss function"
- Controllable video generation: Generating videos guided by conditioning inputs such as text or actions to influence content and dynamics. Example: "controllable video generation"
- Cosine-annealing decay schedule: A learning rate schedule that decays following a cosine curve, often resetting periodically. Example: "cosine-annealing decay schedule"
- Cross-entropy loss: A standard loss function for multi-class classification based on negative log-likelihood. Example: "cross-entropy loss function"
- Diffusion forcing: A training/inference procedure that allows independent per-sample noise schedules in diffusion models. Example: "diffusion forcing"
- Diffusion transformer (DiT): A transformer-based architecture used within latent diffusion frameworks for generative modeling. Example: "latent diffusion transformer (DiT)"
- Epistemic uncertainty: Uncertainty stemming from model ignorance or limited data, reducible with more information. Example: "epistemic and aleatoric uncertainty"
- Expected calibration error (ECE): A metric summarizing the average discrepancy between predicted confidence and empirical accuracy across bins. Example: "expected calibration error (ECE)"
- Flow-based modeling: Generative modeling using invertible transformations enabling exact likelihood computation and sampling. Example: "flow-based modeling"
- Generative adversarial networks (GANs): A generative framework where a generator and discriminator are trained adversarially to synthesize data. Example: "generative adversarial networks (GANs)"
- Latent space: A compressed representation space where data (e.g., videos) are encoded for efficient modeling and generation. Example: "latent space"
- Maximum calibration error (MCE): The largest absolute difference between confidence and accuracy across bins, reflecting worst-case miscalibration. Example: "maximum calibration error (MCE)"
- Mode collapse: A failure mode in generative models (especially GANs) where the generator produces limited diversity. Example: "mode collapse"
- Monte Carlo-based methods: Sampling-based approaches (e.g., multiple forward passes) for estimating uncertainty. Example: "Monte Carlo-based methods"
- Mutual information: An information-theoretic measure quantifying dependence between random variables, used here for UQ via ensembles. Example: "the mutual information over the distribution of the weights of an ensemble of the diffusion models"
- Out-of-distribution (OOD): Inputs that deviate from the training data distribution, often inducing higher uncertainty or errors. Example: "out-of-distribution (OOD) inputs"
- Proper scoring rules: Loss functions that incentivize truthful probability estimates by being minimized at the true distribution. Example: "proper scoring rules as loss functions"
- Reliability diagrams: Plots comparing predicted confidence to observed accuracy across bins to visualize calibration. Example: "reliability diagrams"
- Shepherd's Pi correlation: A robust correlation metric using bootstrapping to mitigate the influence of outliers. Example: "Shepherd's Pi correlation"
- Spatio-temporal convolution: Convolutional operations spanning both spatial and temporal dimensions, used for video representations. Example: "spatio-temporal convolution"
- Stop-gradient operator: A mechanism that prevents gradient flow through certain parts of a computation graph during backpropagation. Example: "stop-gradient operator"
- Strictly proper scoring rule: A proper scoring rule uniquely minimized by the true predictive distribution, ensuring calibrated probabilities. Example: "strictly proper scoring rule"
- Subpatch: A finer unit within a patch (often channel-wise) used for dense, localized predictions in latent video tokens. Example: "subpatch (channel) level"
- Uncertainty quantification (UQ): Methods to assess and express model confidence in predictions. Example: "uncertainty quantification (UQ)"
- Variance-decomposition-based approach: A technique decomposing predictive uncertainty into epistemic and aleatoric components via variance analysis. Example: "variance-decomposition-based approach"
- Variational autoencoders (VAEs): Latent-variable generative models trained by maximizing a variational lower bound. Example: "variational autoencoders (VAEs)"
- Variational inference: An optimization-based method to approximate complex posterior distributions. Example: "variational inference"
- Vector-quantized generative adversarial networks (VQ-GANs): GANs that use a discrete codebook for latent representations to improve fidelity and compression. Example: "vector-quantized generative adversarial networks (VQ-GANs)"
- Vector-quantized variational autoencoder (VQ-VAE): A VAE variant with discrete latents drawn from a learned codebook for efficient tokenization. Example: "vector-quantized variational autoencoder (VQ-VAE)"
Collections
Sign up for free to add this paper to one or more collections.