Dynamic Visual SLAM using a General 3D Prior
Abstract: Reliable incremental estimation of camera poses and 3D reconstruction is key to enable various applications including robotics, interactive visualization, and augmented reality. However, this task is particularly challenging in dynamic natural environments, where scene dynamics can severely deteriorate camera pose estimation accuracy. In this work, we propose a novel monocular visual SLAM system that can robustly estimate camera poses in dynamic scenes. To this end, we leverage the complementary strengths of geometric patch-based online bundle adjustment and recent feed-forward reconstruction models. Specifically, we propose a feed-forward reconstruction model to precisely filter out dynamic regions, while also utilizing its depth prediction to enhance the robustness of the patch-based visual SLAM. By aligning depth prediction with estimated patches from bundle adjustment, we robustly handle the inherent scale ambiguities of the batch-wise application of the feed-forward reconstruction model.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about helping a single camera figure out where it is and what the 3D world around it looks like, even when things in the scene are moving. This skill is called visual SLAM (Simultaneous Localization and Mapping). The authors build a new SLAM system that combines classic geometry with a modern AI model so it can track the camera and build a map reliably in busy, dynamic places (like people walking, cars passing, or objects being moved).
What questions did the researchers ask?
The paper focuses on three simple questions:
- How can a SLAM system ignore moving things (like people or cars) so it doesn’t get confused?
- Can a learned “3D prior” (knowledge about how the 3D world usually looks, learned from many images) make a SLAM system more robust?
- How do we keep the system’s sense of scale consistent over time when using an AI model that sometimes changes scale between batches of images?
How did they do it?
To make this clear, here are the main ideas explained with everyday language:
A quick primer on SLAM
- Imagine you’re walking through a room with one eye open. You try to figure out where you are and draw a map at the same time. That’s SLAM.
- Classic SLAM watches tiny image patches (little square regions) move between frames to estimate the camera’s motion and the 3D depth of those patches. It then adjusts everything together so the map and the camera path agree—this step is called bundle adjustment (think: tidy up the whole puzzle so all pieces fit).
What makes SLAM hard in real life
- Real scenes are dynamic: people walk, doors swing, cars drive. If SLAM treats everything as if it’s fixed in place, it can get badly confused and make a broken map.
Adding a “3D prior” with a feed-forward model
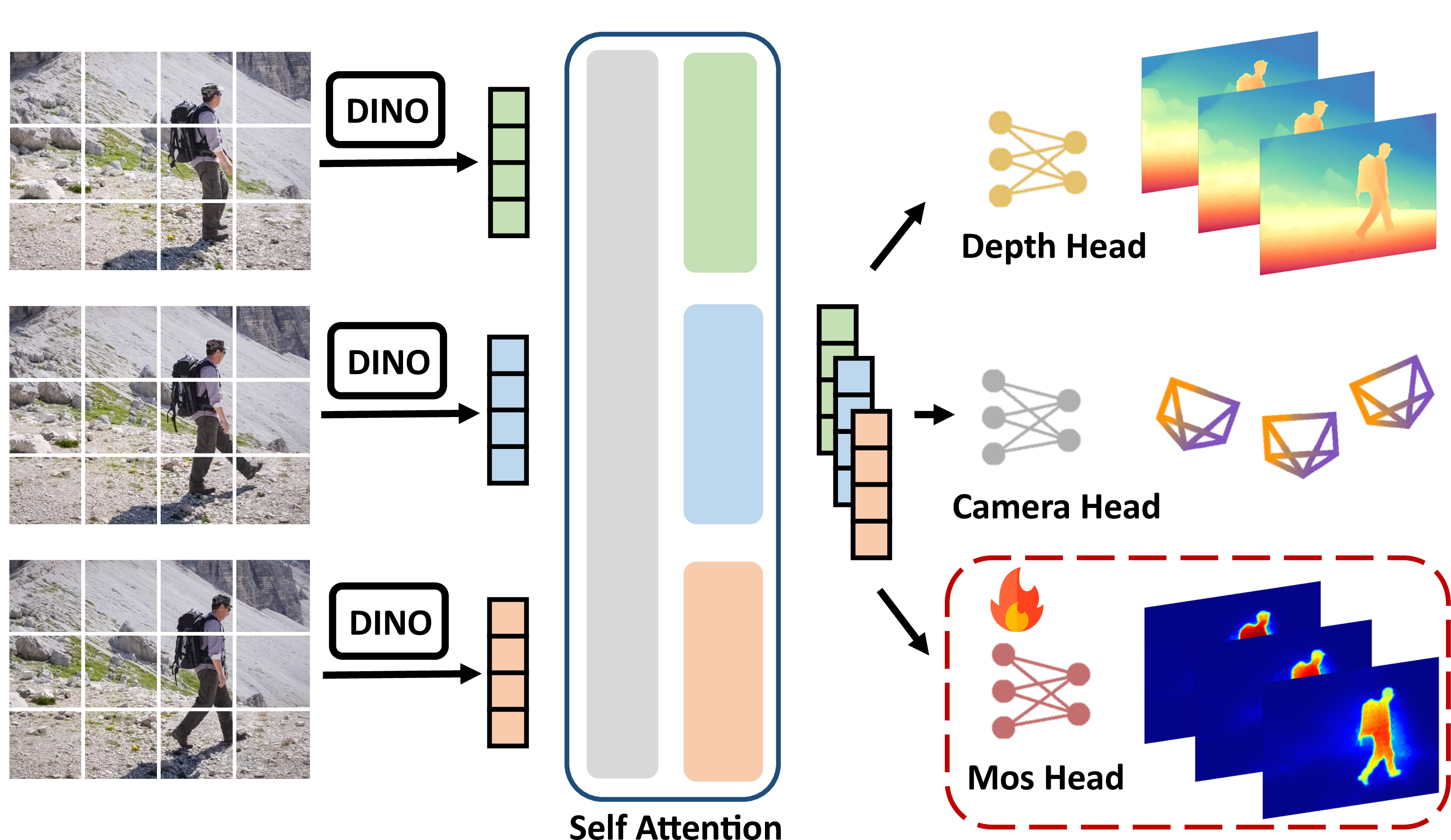
- The authors use a powerful AI model called π³_mos (based on a recent method π³). “Feed-forward” means it takes in a set of images and directly outputs useful 3D information in one go.
- This model predicts three things from a small batch of frames: 1) Depth maps (how far each pixel is), 2) Which pixels are likely moving (a motion mask), 3) Relative camera poses (how the camera moved between frames).
- Think of it as a smart assistant that guesses the shape of the scene and points out moving parts.
Making the two parts work together
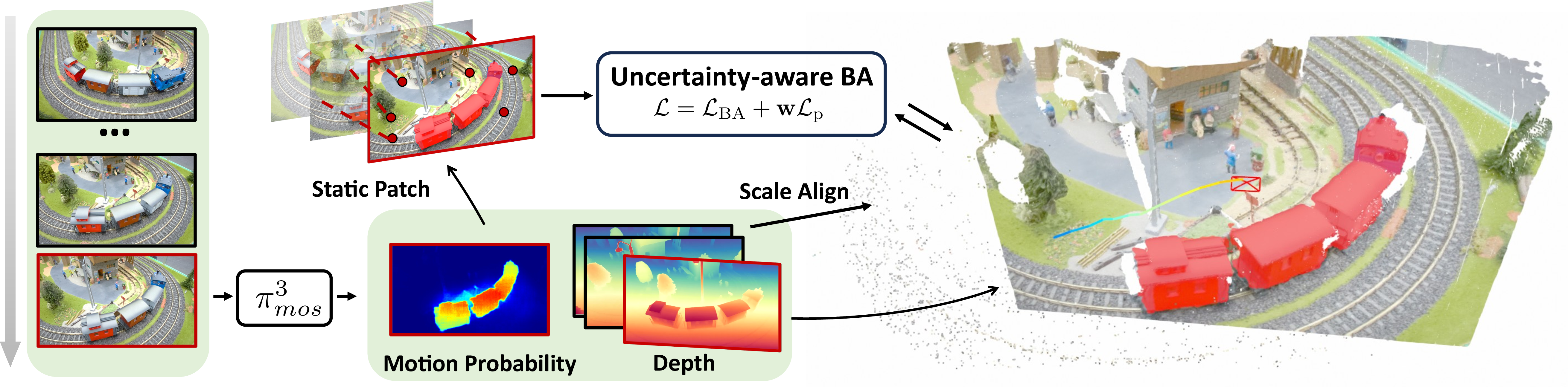
- The SLAM part tracks patches only on the static background. It uses the motion mask from π³_mos to avoid placing patches on moving objects (like skipping people in a crowd).
- The depth predicted by π³_mos acts like a “hint” to help SLAM when motion is small or texture is poor (for example, a plain white wall). This reduces uncertainty and makes tracking more stable.
Fixing the “scale” problem
- Monocular cameras don’t know the true size of things just from images. The AI model’s depth can also change scale from one batch of frames to another (like sometimes seeing the world “zoomed in” or “zoomed out”).
- The system solves this by aligning the model’s predicted depth to the SLAM’s existing scale using points it already trusts—like calibrating a new ruler against your old one. This keeps depth consistent over long videos.
Trusting the AI “hint” only when needed
- If SLAM is confident (good motion, strong features), it relies more on its own geometry.
- If SLAM is uncertain (little movement, weak texture), it increases the weight of the AI depth hint.
- This adaptive weighting is computed from an estimate of uncertainty inside the SLAM optimizer (you can think of it as measuring how “wobbly” the current estimates are).
What did they find, and why is it important?
Here are the main results across several benchmarks with moving scenes:
- More accurate camera paths: Their method achieved the best or second-best accuracy on multiple datasets (Bonn RGB-D Dynamic, Wild-SLAM MoCap, and MPI Sintel), beating or matching strong baselines, including both traditional SLAM and recent learning-based methods.
- Better at ignoring moving objects: Their motion masks (moving object segmentation) were more accurate and more reliable than other recent methods on DAVIS-16 and DAVIS-17.
- High-quality, scale-consistent depth: Their video depth estimates were very strong for an online system, close to the accuracy of top offline methods that require much more memory and time.
Why this matters:
- In real-world robotics, AR, and drones, scenes are rarely static. If the system can correctly ignore movers and keep scale consistent, it can navigate safely and build cleaner 3D maps.
What could this change in the future?
This work shows that mixing classic geometry (trusted, precise math) with learned 3D priors (smart guesses from vast training data) makes SLAM much more reliable in the real world. Potential impacts include:
- Safer robot navigation in busy places like warehouses or streets.
- More stable AR experiences that don’t “drift” when people move around.
- Faster, cleaner 3D mapping for interactive visualization or virtual production.
A current limitation is speed: running the multi-frame AI model each time is relatively slow (about 2 frames per second on a high-end GPU). Future work could make the model lighter, improve efficiency, or offload parts of the computation so the system runs in real time on robots and mobile devices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Real-time performance: The system runs at ~2 fps on an RTX5000 due to per-frame multi-view feed-forward inference. Investigate lighter backbones, model distillation, memory/cache reuse, asynchronous pipelines, and selective frame batching to reach real-time rates (>30 fps) without accuracy loss.
- Domain generalization: The MOS head is trained largely on synthetic and indoor datasets; there is no evaluation on challenging outdoor urban scenes (e.g., KITTI, nuScenes), adverse weather/night conditions, or varied camera modalities. Quantify domain gaps and develop adaptation strategies (e.g., test-time adaptation, synthetic-to-real fine-tuning, robustness to photometric changes).
- Absolute scale: The system attains scale-consistent depth across batches but remains monocular and relies on pose alignment for ATE evaluation. Explore metric scale estimation (e.g., using object size priors, ground plane constraints, IMU/altimeter fusion, or learned absolute scale from data) and evaluate metric accuracy without post-hoc alignment.
- Loop closure and global consistency: There is no loop-closure mechanism or global optimization in the presented pipeline. Assess long-sequence drift, integrate loop closure (place recognition, global BA), and study how feed-forward priors can improve loop detection and correction in dynamic scenes.
- Scale alignment robustness: Depth scale is aligned via static patches and a single inverse-depth scale factor per batch. Examine failure modes when static background is scarce, camera undergoes rotation-only motion, or static patches are mis-segmented; consider per-region or per-frame scale models and adaptive robust weighting.
- Keyframe selection policy: The strategy for selecting historical frames for batch inference and scale alignment is not specified. Systematically study keyframe selection criteria (view overlap, parallax, uncertainty, motion) to optimize accuracy-latency-memory trade-offs.
- Uncertainty calibration: The adaptive prior weighting uses marginal covariances from linearized BA and hyperparameters (α, β) for a sigmoid mapping. Validate and calibrate uncertainty estimates against ground truth, assess sensitivity to α, β, and explore Bayesian or learned uncertainty models that better reflect non-linearities and degeneracies.
- Depth prior confidence usage: Confidence maps from the feed-forward model are used in scale estimation but not explicitly to weight the per-patch depth prior in BA. Evaluate incorporating pixel-wise confidences into the prior term to mitigate the impact of uncertain depth predictions.
- Impact of segmentation errors: The MOS masks are thresholded to exclude dynamic regions, but the effect of false positives/negatives on BA stability and accuracy is not quantified. Explore soft mask weighting, occlusion-aware modeling, and robust loss formulations to mitigate segmentation errors.
- Threshold selection and adaptivity: The motion threshold s_d and the uncertainty threshold t_σ are fixed. Investigate scene-adaptive thresholding driven by uncertainty, motion statistics, or validation curves, and quantify their sensitivity across datasets.
- Use of camera pose head: The pi3_mos camera head is not utilized in the SLAM pipeline. Evaluate using predicted poses for initialization, re-localization, or as priors, and study their interplay with BA under dynamic conditions.
- Map representation and quality: The system accumulates dense point clouds from aligned depths but does not produce structured maps (surfel/mesh/TSDF) or evaluate map fidelity (accuracy, completeness, consistency). Integrate volumetric fusion and assess downstream utility (planning, AR) under dynamic scenes.
- Handling rolling shutter and lens distortion: The pipeline assumes a standard projection model; robustness to rolling shutter, lens distortion, and calibration errors is not studied. Incorporate appropriate models and evaluate their impact on tracking and depth accuracy.
- Fast motion and motion blur: While segmentation examples show robustness to blur, there is no systematic analysis of tracking performance under strong blur, high-speed motion, or low-light conditions. Design stress tests and remedies (event cameras, IMU fusion, deblurring priors).
- Scalability to very long sequences and multi-session mapping: Experiments cover sequences up to ~2000 frames. Evaluate scalability to tens of thousands of frames, multi-session mapping, and map persistence, including memory footprints and drift behavior.
- Dynamic object modeling: The method filters moving objects rather than modeling them. Explore multi-body SLAM to segment, track, and reconstruct dynamic objects (rigid and non-rigid) and quantify benefits to downstream tasks (interaction, forecasting).
- Failure analysis: The paper lacks a detailed analysis of failure cases (e.g., scenes dominated by non-static elements, severe occlusions, minimal parallax). Provide systematic failure taxonomies and diagnostic tools to guide robustness improvements.
- Sensitivity to patch parameters: The number, size, and sampling strategy of patches (K, spatial distribution) are not studied. Optimize patch selection under low texture, repetitive patterns, and dynamic clutter, and analyze trade-offs between accuracy and computation.
- Depth fusion and outlier rejection: The accumulation of per-frame aligned depths into a dense map lacks a detailed fusion methodology. Evaluate TSDF/surfel fusion with robust outlier rejection and spatio-temporal consistency checks.
- Memory profiling and optimization: Although the approach avoids offline multi-view memory blow-up, the memory and latency profiles of the hybrid pipeline (especially batch inference) are not reported. Profile bottlenecks and propose memory-efficient architectures or scheduling.
- Online adaptation of MOS head: The MOS head is trained offline with BCE supervision; there is no mechanism for on-the-fly adaptation to new domains or scenes. Investigate self-supervised/weakly supervised online updates using BA residuals or motion cues.
- Evaluation breadth: Benchmarks focus on indoor dynamic scenes and synthetic movie renders; key outdoor datasets with vehicles and crowds (KITTI, Cityscapes, Waymo) are absent. Broaden evaluation to diverse, large-scale, highly dynamic environments.
- Formal analysis of intra-batch scale consistency: The claim that depth scales are consistent within a batch is empirical. Provide formal analysis or empirical quantification across varying batch compositions, viewpoints, and exposure changes, and define conditions when the assumption breaks.
- Reproducibility details: Critical hyperparameters (α, β, s_d, t_σ, K, batch size N, keyframe selection criteria) are deferred to supplementary materials. Include comprehensive settings, ablations, and scripts in the released code to facilitate faithful reproduction and fair comparison.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging the paper’s core outputs: per-frame camera poses, scale-consistent dense depth, and online moving-object segmentation, all integrated with a robust, uncertainty-aware bundle adjustment pipeline.
- Robotics (AMRs in warehouses, hospitals, retail)
- Use case: Drop-in dynamic visual SLAM for navigation in people-rich spaces, maintaining stable localization and clean static maps while filtering carts, humans, and other movers.
- Tools/products/workflows: ROS2 node replacing or augmenting a VO/SLAM front-end; map-cleaning module producing “static-only” point clouds; uncertainty-driven safety valves that slow robots when pose/depth uncertainty rises.
- Assumptions/dependencies: RGB camera with known intrinsics; moderate GPU (edge workstation) to achieve usable frame rates; scenes with sufficient features for patch tracking; 2 fps constraint may limit very fast maneuvers.
- AR/XR (ARCore/ARKit pipelines, mobile AR apps)
- Use case: Stable camera tracking and occlusion in crowded scenes (events, retail, museums) by masking movers and using scale-consistent depth for rendering and anchoring.
- Tools/products/workflows: Plugin to AR frameworks to supply external depth and motion masks; workflow for persistent content anchoring that rejects dynamic-background drift.
- Assumptions/dependencies: Integration path to mobile AR stack; current performance likely offline or tethered; absolute scale may require an external cue (known object size or IMU/altimeter).
- Industrial and facility mapping (digital twins during operations)
- Use case: “De-ghosted” scans in working environments (e.g., factories during production, stores during business hours) to maintain up-to-date static maps without shutting down operations.
- Tools/products/workflows: Mapping cart or backpack using Pi3MOS-SLAM; batch pipeline that fuses multiple walkthroughs; export to BIM/CAD.
- Assumptions/dependencies: GPU-powered workstation; consistent calibration; reflective/transparent surfaces may require operator passes from multiple angles.
- Virtual production and VFX
- Use case: Monocular camera tracking and depth for compositing with on-set movers; removal of foreground movers from the static set reconstruction to reduce cleanup overhead.
- Tools/products/workflows: DCC plugin (e.g., Nuke/Houdini) for shot-by-shot tracking/depth export; mask-driven cleanup workflow to isolate static set.
- Assumptions/dependencies: Offline processing acceptable; robust on diverse lighting but may need per-shot calibration; absolute scale alignment may rely on slate measurements.
- Security and safety analytics
- Use case: Scene-geometry-aware detection that distinguishes persistent structural change from transient movers; reduce false alarms and drift in dynamic coverage.
- Tools/products/workflows: Background map maintenance service; dynamic mask stream to downstream analytics models; spatial “no-go” zone estimation from stable geometry.
- Assumptions/dependencies: Stationary or slowly moving cameras; policy/compliance alignment for person detection and storage; compute at the edge or central.
- Education and research (academia)
- Use case: A strong open-source baseline for dynamic SLAM courses, labs, and research on uncertainty-aware optimization and learned geometric priors.
- Tools/products/workflows: Reproducible experiments with public datasets; ablations on scale alignment and uncertainty weighting; extension projects (e.g., IMU fusion).
- Assumptions/dependencies: Access to GPUs; familiarity with SLAM evaluation tooling; camera/lens calibration for lab rigs.
- Inspection and field robotics (infrastructure, construction)
- Use case: Stable pose estimation for monocular inspection robots operating around crews and equipment; clean static reconstructions for progress tracking.
- Tools/products/workflows: Field data capture pipeline with drift-resistant maps; mask-based filtering to emphasize long-term structural change.
- Assumptions/dependencies: Tolerant to low frame rate; possibly combined with IMU for faster motions; occlusion handling via multi-pass capture.
- Consumer 3D capture (offline)
- Use case: Smartphone footage turned into clean 3D scans of rooms even with people moving through; improved AR measurement fidelity post-processed on a PC.
- Tools/products/workflows: Desktop app that ingests video, outputs static mesh and mover masks; home renovation or interior design workflows.
- Assumptions/dependencies: Offline compute on PC with GPU; requires camera intrinsics and decent texture; moving reflections may need manual review.
- Privacy-preserving video capture (policy, compliance)
- Use case: Immediate anonymization by blurring/redacting mover masks while still reconstructing static spaces for compliance reporting or documentation.
- Tools/products/workflows: Post-processing pipeline that applies masks per frame and exports anonymized videos/maps; audit logs with uncertainty scores.
- Assumptions/dependencies: Policy alignment for mask quality thresholds; acceptance of occasional over/under-masking; offline batch acceptable.
- Sports and event broadcasting (stabilized virtual replays)
- Use case: Short segment tracking with depth for AR graphics insertion (lines, stats) in crowded scenes; stable virtual camera moves from monocular feeds.
- Tools/products/workflows: Segment-based processing on replay servers; integration to graphics engines using exported poses and depth maps.
- Assumptions/dependencies: Near-real-time but segment-limited; per-venue calibration; reflective floors and motion blur handled via uncertainty-weighted priors.
Long-Term Applications
The following require further research, scaling, or optimization (e.g., real-time performance, hardware acceleration, broader sensor fusion, or large-scale deployment engineering).
- Real-time, on-device dynamic SLAM for mobile robots and drones
- Use case: Onboard monocular dynamic SLAM at camera frame rate in crowded indoor/outdoor spaces.
- Tools/products/workflows: Model distillation, quantization, TensorRT/Vulkan acceleration, or specialized NPUs; tighter IMU fusion.
- Assumptions/dependencies: Significant latency and power reductions vs. current 2 fps on RTX 5000; robust performance under rolling shutter, high-speed motion, and low light.
- Automotive and micromobility (ADAS, delivery robots)
- Use case: Monocular dynamic SLAM in urban streets with diverse movers and specularities; redundancy to GNSS/HD map drift.
- Tools/products/workflows: Multi-camera rigs with cross-view memory; fusion with wheel odometry, IMUs, radar; uncertainty-aware planning interfaces.
- Assumptions/dependencies: Automotive-grade compute; stringent safety cases; weather and nighttime generalization; long-sequence drift management at scale.
- Persistent, crowd-robust AR cloud maps
- Use case: City-scale AR where crowd motion does not corrupt map persistence; consistent occlusion handling for multi-user AR.
- Tools/products/workflows: Server-side map maintenance that filters movers during capture; crowd-sourced updates with confidence gating.
- Assumptions/dependencies: Scalable backends and map versioning; cross-device calibration; privacy-preserving crowd handling.
- Dynamic digital twins with live occupancy layers
- Use case: Twins that maintain a clean static backbone plus a live “dynamic occupancy” layer for operations (e.g., retail layout optimization, safety monitoring).
- Tools/products/workflows: Fusion of dynamic masks across cameras; temporal analytics of flows; APIs for facilities optimization.
- Assumptions/dependencies: Multi-camera synchronization; ethics and privacy guardrails; robust handling of glass, mirrors, and repetitive textures.
- Certified uncertainty-aware perception for safety standards
- Use case: Using the paper’s uncertainty-aware BA to expose pose/depth confidence into robot safety cases and certification processes.
- Tools/products/workflows: Metrics and tests built around marginal covariances; runtime policies that adapt speed/behavior to uncertainty.
- Assumptions/dependencies: Standardization by industry consortia; calibration and monitoring requirements; interpretability of learned priors.
- Multi-sensor fusion (IMU/LiDAR/event cameras)
- Use case: Hybrid systems that keep monocular advantages while adding robustness in texture-poor or high-speed conditions.
- Tools/products/workflows: Factor-graph fusion where learned depth priors become adaptive factors; cross-modal uncertainty calibration.
- Assumptions/dependencies: Tight time synchronization; calibration and extrinsics maintenance; onboard compute budgets.
- Real-time virtual production and live broadcast graphics
- Use case: Live sets with many movers where inside-out tracking remains solid for AR overlays and camera path synthesis.
- Tools/products/workflows: Hardware-accelerated inference pipelines; on-set calibration workflows; fallback modes using IMU/tripod sensors.
- Assumptions/dependencies: Sub–frame-accurate latency targets; integration with broadcast timing and genlock; robustness to stage lighting changes.
- Assistive home robots in highly dynamic households
- Use case: Safe, reliable navigation around children and pets with uncertainty-aware motion policies.
- Tools/products/workflows: Embedded SLAM cores paired with low-cost sensors; continuous learning for home-specific priors.
- Assumptions/dependencies: Energy-efficient inference; privacy-preserving operation; recovery from occlusions/clutter.
- Smart-city analytics and policy planning
- Use case: Data products that separate static infrastructure from dynamic flows for planning and safety (e.g., curb usage, crowd management).
- Tools/products/workflows: Privacy-first data pipelines with mover masks; aggregated, uncertainty-weighted occupancy maps.
- Assumptions/dependencies: Governance frameworks for capture/anonymization; sampling strategies that minimize bias; public acceptance.
- Next-gen mobile OS integration (system-level AR/SLAM)
- Use case: Platform APIs offering dynamic-scene-robust tracking and occlusion as a service to apps.
- Tools/products/workflows: OS-level accelerators and drivers; developer SDKs exposing depth/mask/uncertainty streams.
- Assumptions/dependencies: Hardware roadmap alignment; power and thermals on mobile; cross-vendor standards.
Cross-cutting assumptions and dependencies that affect feasibility
- Compute and latency: Current implementation runs at ~2 fps on an NVIDIA RTX 5000; real-time robotics and on-device AR require substantial optimization or dedicated accelerators.
- Calibration: Accurate camera intrinsics and stable exposure are needed; rolling shutter and motion blur can be mitigated but may raise uncertainty.
- Absolute scale: The method achieves scale consistency across batches; absolute metric scale may still require an external cue (known object size, IMU, wheel odometry).
- Scene properties: Highly reflective/transparent surfaces and severe texture paucity can degrade patch tracking; uncertainty-aware weighting helps but may need sensor fusion.
- Generalization: Trained on diverse dynamic datasets; extreme domain shifts (night, adverse weather, heavy specularities) may require fine-tuning.
- Privacy and compliance: Moving-object masks can support anonymization, but policy-compliant pipelines must be designed (storage, retention, audit).
- Integration effort: Best performance emerges when the depth prior and masks are tightly fused with BA; productization entails robust engineering (ROS2, Unity/Unreal plugins, telemetry, monitoring).
Glossary
- Absolute relative error (Abs Rel): Scale-invariant depth evaluation metric measuring the mean absolute difference between predicted and ground-truth depths relative to ground truth. "We use absolute relative error (Abs Rel) and percentage of predicted depths within a 1.25-factor of true depth () as metrics."
- Absolute Trajectory Error (ATE): Global trajectory accuracy metric summarizing the deviation between estimated and ground-truth camera poses after alignment. "we report the Absolute Trajectory Error~(ATE) for each sequence"
- Back-projection: Mapping from image coordinates and depth to 3D rays/points in camera coordinates. "represent the camera projection and back-projection functions."
- Bundle adjustment (BA): Nonlinear least-squares optimization jointly refining camera poses and 3D structure to minimize reprojection errors. "perform sliding-window bundle adjustment (BA),"
- Cholesky decomposition: Factorization technique for positive-definite matrices used to efficiently invert covariance/Hessian blocks. "This matrix inversion can be efficiently computed via Cholesky decomposition."
- DINOv2: A 2D foundation vision transformer model used for extracting semantic features. "2D foundation model \mbox{DINOv2~\cite{oquab2024tmlr}"
- Differentiable rendering: Rendering approach where image formation is differentiable, enabling gradient-based learning of 3D scene parameters. "using \mbox{DINOv2~\cite{oquab2024tmlr} features and differentiable rendering to train an MLP online"
- Feed-forward reconstruction model: Neural model that directly predicts camera poses and dense scene geometry from images in a single forward pass. "we propose a feed-forward reconstruction model to precisely filter out dynamic regions,"
- Hessian matrix: Second-derivative matrix of the objective function, structuring curvature information for optimization. "where and are the Hessian matrices for frame poses and patch inverse depths,"
- Huber loss: Robust loss function combining quadratic and linear regimes to reduce sensitivity to outliers. "where denotes the Huber loss function,"
- Inverse depth: Depth parameterization using to stabilize optimization and handle points at infinity. "d_ki is the inverse depth of patch in frame ,"
- IoU (Intersection-over-Union): Overlap-based segmentation metric measuring the ratio of intersection to union between predicted and ground-truth masks. "We report performance using the IoU mean (JM) and IoU recall (JR) metrics."
- Keyframe-based scale estimation: Using selected keyframes to resolve and maintain consistent scale across predictions. "First, a keyframe-based scale estimation, enabled by patch-based bundle adjustment, resolves the scale drift caused by incremental usage of feed-forward reconstruction models."
- Levenberg–Marquardt (LM) algorithm: Damped least-squares method for solving nonlinear optimization problems like BA. "We further optimize $\mathcal{L}_{\text{BA}$ using the Levenberg-Marquardt (LM) algorithm"
- Marginal covariance: Covariance of a subset of variables (e.g., depths) marginalized over others (e.g., poses) to quantify uncertainty. "the marginal covariance of the inverse depths can be derived from \cref{eq:normal} as"
- MLP (Multi-Layer Perceptron): Feed-forward neural network composed of fully connected layers. "train an MLP online"
- Monocular SLAM: SLAM system operating with a single camera, estimating poses and maps without absolute scale from stereo/IMU. "We build our SLAM system upon a monocular SLAM system DPV-SLAM~\cite{teed2023nips, lipson2024eccv}"
- Moving object segmentation (MOS): Per-pixel classification of dynamic versus static regions to filter out moving objects. "Moving object segmentation~(MOS) head"
- Motion probability: Per-pixel probability that a pixel belongs to a moving object. "pixel-wise motion probability for each image."
- NeRF (Neural Radiance Fields): Implicit neural representation modeling volumetric radiance for novel view synthesis and 3D reconstruction. "builds on NeRF on-the-go~\cite{ren2024cvpr-notg}"
- Optical flow: Estimation of pixel displacements between consecutive frames, used for tracking and geometric constraints. "optical-flow based monocular SLAM framework"
- Patch-based bundle adjustment: BA using tracked sparse patches as 3D points to jointly refine poses and depths. "patch-based bundle adjustment"
- Point cloud: A set of 3D points representing scene geometry. "dense depth image derived from the predicted point cloud"
- Relative Rotation Error (RRE): Mean frame-to-frame rotation discrepancy between estimated and ground-truth trajectories. "Relative Translation Error~(RTE), and Relative Rotation Error~(RRE)"
- Relative Translation Error (RTE): Mean frame-to-frame translation discrepancy between estimated and ground-truth trajectories. "Relative Translation Error~(RTE), and Relative Rotation Error~(RRE)"
- Reprojection error: Pixel-space difference between observed feature locations and their projections from estimated 3D structure and poses. "the optimization objective is the reprojection error,"
- Root Mean Square Error (RMSE): Square-root of averaged squared errors, used here to summarize trajectory error magnitude. "which is computed as the root mean square error~(RMSE) of all poses after alignment."
- Scale ambiguity: Monocular reconstruction indeterminacy where absolute scale cannot be recovered without priors or alignment. "To address this scale ambiguity, we select historical keyframes"
- Scale drift: Gradual change of estimated scale over time due to accumulated errors. "resolves the scale drift caused by incremental usage of feed-forward reconstruction models."
- Schur complement: Matrix operation used to eliminate variables and efficiently solve block-structured normal equations in BA. "This linear equation can be efficiently solved using the Schur complement:"
- SE(3): Special Euclidean group in 3D representing rigid-body rotations and translations. "camera poses "
- Self-attention: Mechanism letting models attend to and integrate information across tokens/frames. "alternating frame-wise and global self-attention"
- Sigmoid function: S-shaped function mapping a scalar (e.g., uncertainty) to a bounded weight. "mapped to a frame weight via a sigmoid function:"
- Sliding-window registration: Registration performed over a moving window of frames to maintain tractable optimization. "segments static backgrounds via optical flow and performs sliding-window registration"
- Structure-from-motion (SfM): Classical pipeline estimating camera motion and 3D structure from multiple images. "where traditional SLAM or structure-from-motion methods struggle."
- Uncertainty-aware bundle adjustment: BA that adaptively weights priors based on estimated uncertainty to improve stability. "an uncertainty-aware bundle adjustment mechanism"
- Uncertainty propagation: Computing how uncertainty in variables transforms through nonlinear mappings. "Using standard nonlinear uncertainty propagation,"
- Weighted median: Robust scale estimator computing the median of ratios with sample-specific weights. "We initialize using the weighted median of the ratio ,"
Collections
Sign up for free to add this paper to one or more collections.