- The paper demonstrates that random data weighting in gradient descent leads to convergence towards a weighted linear least squares solution.
- It provides a rigorous, non-asymptotic analysis showing that importance sampling can accelerate optimization but may compromise statistical accuracy.
- The study highlights a fundamental trade-off between optimization speed and estimator quality, informing the design of robust sampling strategies.
The Interplay of Statistics and Noisy Optimization: A Technical Analysis of Randomly Weighted Gradient Descent in Linear Regression
Introduction and Problem Statement
This work examines the impact of random data weighting in the optimization of linear predictors, focusing on gradient descent (GD) in linear regression. The study unifies existing perspectives on algorithmic noise—including various forms of stochastic gradient descent (SGD) and importance sampling—by generalizing to arbitrary continuous weighting distributions. This accounts for both discrete (e.g., mini-batching, dropout) and continuous (e.g., robust regression, curriculum learning) sampling schemes, thereby elucidating the connections between statistical implications (like generalization and implicit regularization) and the dynamical properties of noisy optimization in a controlled linear setting.
The central model considers the linear regression empirical risk
f(w)=∥Y−Xw∥22,
optimized by GD with random weightings, formalized as
wk+1=wk−2αk∇wk∥Dk(Y−Xwk)∥22,
where Dk is a random diagonal matrix drawn i.i.d. from a generic weighting distribution (not necessarily binary or discrete). This framework captures uniform/binary sampling (classical mini-batch SGD), importance sampling, and continuous weightings, thus subsuming a wide variety of stochastic optimization paradigms.
A crucial insight is that the expected squared weighting matrix M2=E[D2] fundamentally alters the effective loss landscape, controlling both the algorithmic trajectory and the statistical properties of estimators. The random-noise-induced regularization is thus formalized as convergence to solutions of a weighted linear least squares (W-LLS) problem:
w∗=(XTM2X)†XTM2Y
in the overparameterized regime.
Convergence Analysis of Noisy, Randomly Weighted Gradient Descent
The paper presents a non-asymptotic, step-size-dependent convergence analysis for the mean and covariance (first and second moments) of the iterate error wk−w∗. The recursion is shown to be a vector autoregressive (VAR) process with random coefficients.
First Moment: Exponential Convergence in Expectation
The marginalized (mean) dynamics are driven by the deterministic operator induced by M2, yielding exponential convergence in expectation:
∥E[wk+1−w∗]∥2≤exp(−σmin+(XTM2X)ℓ=1∑kαℓ)∥w1−w∗∥2,
where σmin+ is the smallest non-zero singular value. The rate is shaped by the spectrum of the weighted design matrix, offering potential acceleration via appropriate weighting (importance sampling) but also quantifying degradation under poor choices of M2.
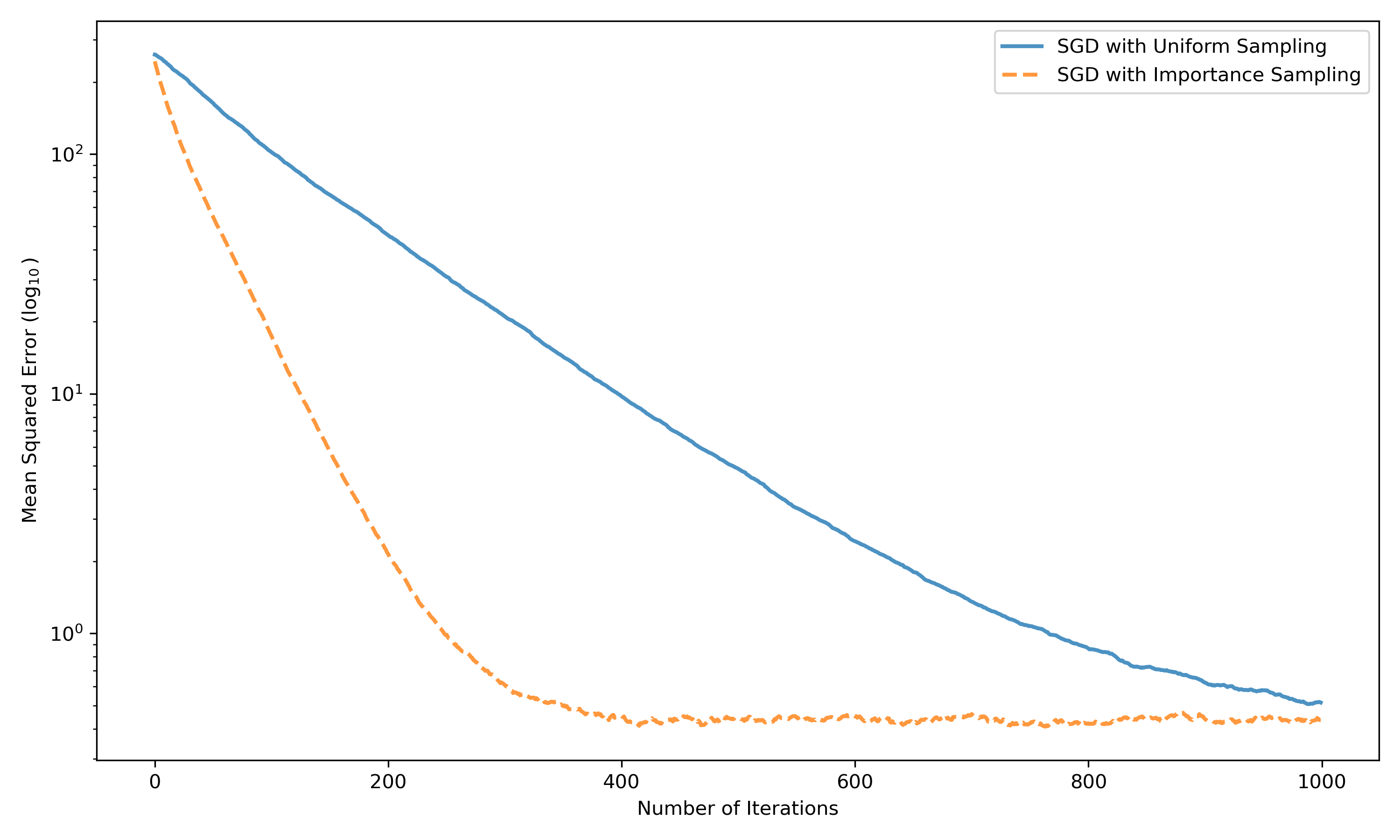
Figure 1: Convergence in squared distance E[∥wk−w∗∥22] for SGD with uniform and importance sampling; non-uniform sampling exploits high-norm data points for rapid early decrease.
Second Moment and Stationary Distributions
A refined analysis traces the spread in the iterates via an affine recursion on the error covariance, accommodating higher moments of the weight distribution. In the constant step-size regime, the law of iterates converges to a unique stationary distribution, with explicit rates dictated by the step size, batch selection covariance, and problem spectrum. The stationary variance is governed by both the residual error at the W-LLS minimum and the structure of the noise injected by random weighting. Through geometric moment contraction (GMC), the authors guarantee exponential contraction in Wasserstein distance, establishing robustness and uniqueness of the stationary limit.
A critical contribution is the precise decoupling of optimization speed and statistical consistency.
- Speed: Acceleration is possible via biased/importance sampling, which increases the effective curvature (σmin+) of the problem and potentially achieves dramatic convergence improvements (approaching the Kaczmarz method in strict rank or high-variance settings).
- Statistical accuracy: However, the statistical performance (e.g., mean squared risk for estimating the ground-truth parameter in the presence of observation noise) depends almost entirely on the geometry of M2 and can be arbitrarily bad if the weighting scheme neglects informative data. The asymptotic risk is decomposed into bias (projection onto uninformative directions) and variance (amplified or suppressed by weighting). This exposes the fundamental tension: weighting schemes that naively prioritize “easy” points or points with large sample norm, without regard to noise structure, can degrade estimator quality, even as they accelerate nominal loss reduction.
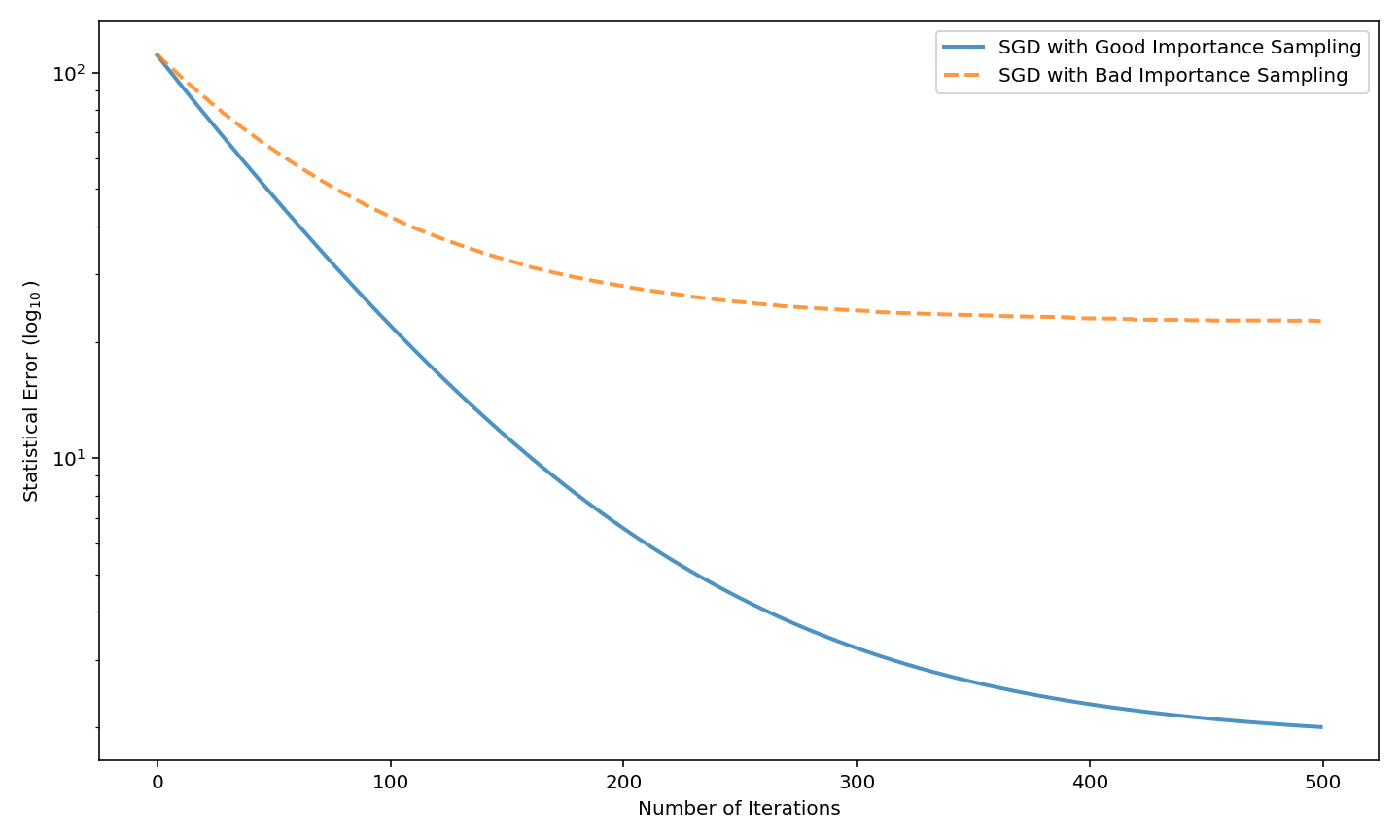
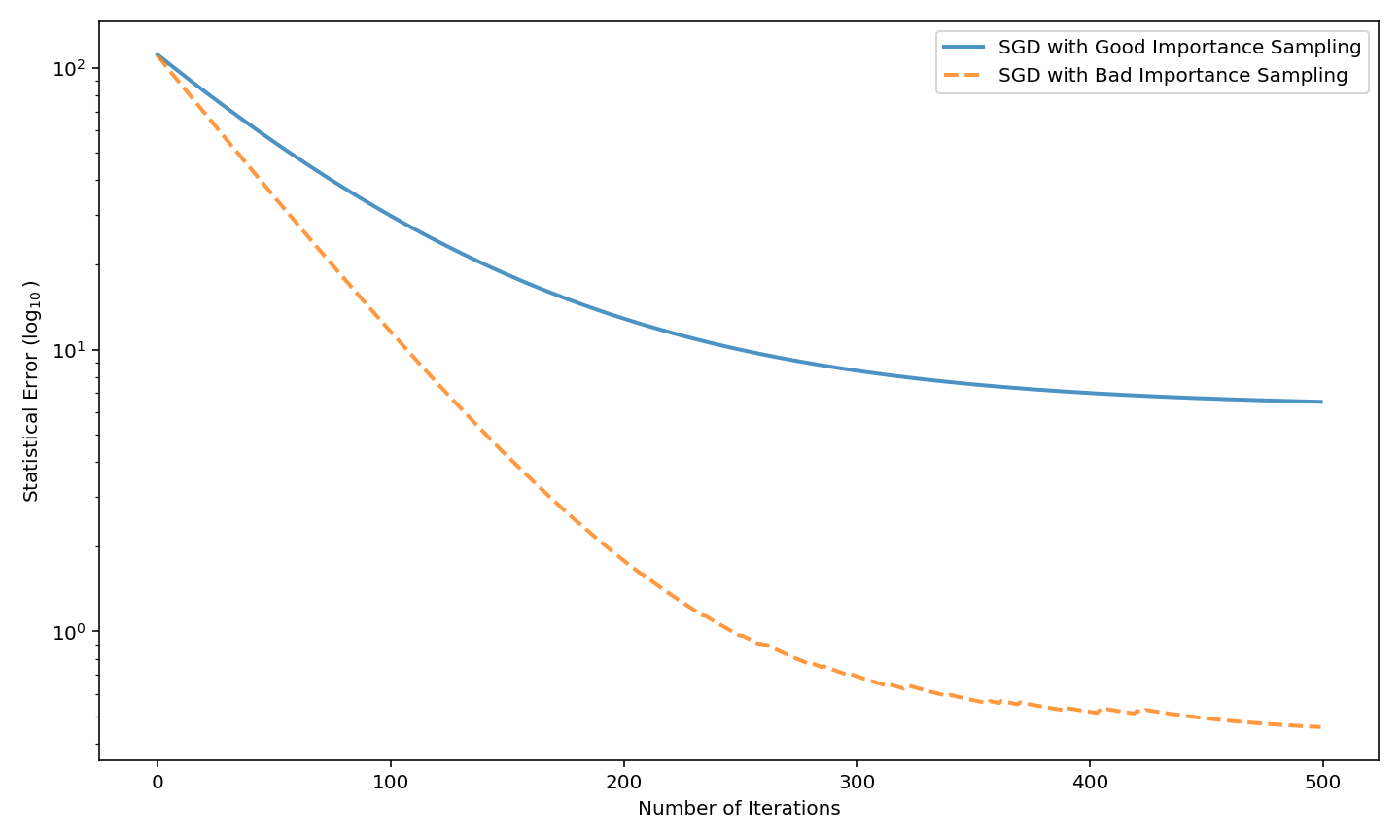
Figure 2: Statistical error E[∥wk−w∗∥22] for “good” versus “bad” importance sampling; favoring noisy, irrelevant, or low-information features inhibits statistical recovery despite rapid optimization.
Theoretical and Practical Implications
From a theoretical standpoint, the results yield a unified, precise description of the role of randomness in noisy optimization algorithms in the convex, overparameterized regime. They elucidate the mechanisms of implicit regularization and make concrete the trade-off between algorithmic efficiency and statistical risk, demonstrating that optimization-induced regularization is not uniformly beneficial and can, in certain circumstances, be detrimental.
On the practical side, the findings have direct implications for the design of sampling and weighting strategies in large-scale learning systems. Weighting according to sample norm or standard importance measures can significantly accelerate convergence, but these choices must be calibrated by the true information structure and noise of the data to avoid sacrificing generalization. The framework further enables rational design of robust estimators (e.g., continuous weightings, data-driven curricula) sensitive to both optimization and inferential risks.
Outlook and Connections to Nonlinear and Adaptive Models
While the analysis is restricted to linear models, the techniques lay groundwork for analogous examinations in nonlinear and deep models—where similar optimization-statistics trade-offs manifest, but with increased complexity due to non-convexity and non-uniqueness of minima. The theoretical results suggest future research into: (1) the stationary distribution and implicit bias of randomly weighted or adaptively sampled gradient algorithms in deep networks, (2) weighting schemes adaptive to both model dynamics and data heterogeneity, and (3) extensions to iterated random-function systems beyond i.i.d. (e.g., adaptive curricula or non-independent sampling). The methods developed here could seed quantitative theorems in these more general settings, revealing guiding structure for large-scale machine learning practice and theory.
Conclusion
This work provides a rigorous, unified treatment of the dynamical and statistical consequences of random data weighting in linear regression optimization. By mathematically characterizing the evolution, stationary distribution, and statistical risk of randomly weighted gradient descent, the paper exposes the deep tension—yet intimate interplay—between algorithmic acceleration and estimator optimality. The insights herein have direct bearing on the design and interpretation of stochastic optimization algorithms in both classical statistics and modern large-scale machine learning.