- The paper shows that timbre-focused metrics achieve higher correlation with subjective ratings compared to binaural extensions.
- It employs a comprehensive evaluation of intrusive metrics via MUSHRA tests across mixed and isolated artifact presentations.
- Results underscore the need for robust models that integratively address spatial, timbral, and contextual distortions.
Analysis of Perceptual Audio Quality Metrics on Stereo Processing Using the Open Dataset of Audio Quality
Introduction
This paper provides a comprehensive evaluation of state-of-the-art objective perceptual audio quality metrics, focusing on stereo audio signals processed through Mid/Side (MS) and Left/Right (LR) paradigms. The analysis is grounded on the Open Dataset of Audio Quality (ODAQ), which includes varied audio artifacts and their associated subjective ratings. The investigation is motivated by the under-explored performance of audio quality metrics under complex stereo configurations, mixed spatial/timbral degradations, and diverse presentation contexts. The study systematically compares monaural and binaural quality assessment models, scrutinizing both their architecture and validity against human subjective ratings.
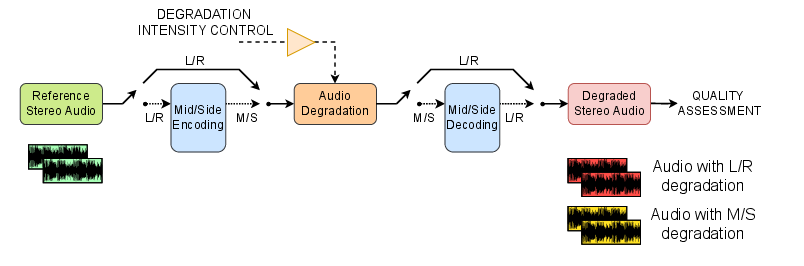
Figure 1: Experimental setup for the generation and quality assessment of the degraded audio files.
Methodological Framework
The evaluation covers a spectrum of intrusive perceptual audio quality metrics, including PEAQ, PEMO-Q, HAAQI, Two-F, MoBi-Q and eMoBi-Q (with monaural and binaural variants), and recently proposed binaural extensions of PEAQ. These models differ in their psychoacoustic modeling, signal parameterization, and aggregation over stereo channels. The paper highlights that, with a few exceptions, most metrics process each channel independently and merge the outputs, often by simple averaging. Only certain advanced models explicitly address spatial audio distortions leveraging binaural psychoacoustic cues such as ILD, ITD, IACC, and coherence-based features.
Listening tests were conducted using the MUSHRA paradigm with 16 trained subjects, across a variety of stereo musical excerpts, solo instruments, and artificially mixed dialog/music with hard panning. Spectral Holes (SH) and Quantization Noise (QN) degradations were introduced separately in MS and LR domains as well as in mixed configurations, spanning multiple quality levels. The experimental design carefully isolates the effect of artifact type, stereo processing, and presentation context.
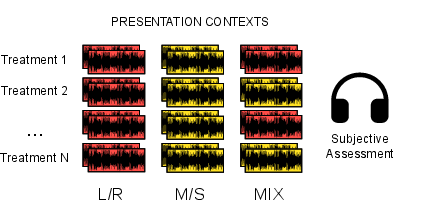
Figure 2: Experimental conditions for the degraded files, contrasting LR-only, MS-only, and mixed-context MUSHRA presentations.
Results and Quantitative Findings
Impact of Artifact Type and Presentation Context
The correlation analysis between metrics and subjective scores reveals substantial inter-metric and inter-context variability. For homogeneous degradation contexts (i.e., SHLR, SHMS, QNLR, QNMS presented independently), many metrics achieve Pearson correlations well above 0.8, often surpassing 0.9. However, all metrics, regardless of complexity or inclusion of spatial models, markedly underperform for signals presented in mixed contexts (SHmix, QNmix), with pooled mean correlations dropping to around 0.44.
(Figure 3)
Figure 3: Correlation between objective metric predictions and subjective quality scores for each experiment, illustrating performance deterioration for SHmix and QNmix mixed context presentations.
Audio Excerpt Dependence and Channel Imbalance
For standard music and solo instrument items (without hard-panned content), advanced metrics such as PEAQ-CSM, PEMO-Q, and Two-F maintain robust performance across all conditions. However, on excerpts containing hard-panned objects, models that synthesize a single quality estimate via channel averaging, such as NMR and HAAQI, often fail to predict quality reliably, particularly in QNMS (Mid/Side) processing scenarios.
(Figure 4)
Figure 4: Correlation between metric predictions and ratings for excerpts without hard-panned objects; top-performing metrics are consistent across artifact type.
(Figure 5)
Figure 5: Correlation between metric predictions and ratings for hard-panned excerpts; general breakdown of performance, especially for NMR and averaging-based metrics.
Comparative Analysis of Timbre Versus Binaural Models
A consistent finding is that the introduction of explicit binaural features and spatial distortion metrics does not produce substantial improvements in overall quality prediction compared to timbre-centric models. In several cases, the inclusion of binaural branches into the objective metric pipelines slightly decreases correlation with human ratings. For instance, MoBi-Q and eMoBi-Q's binaural extensions do not outperform their monaural/timbre baselines in most scenarios.
Failure Modes of Conventional Metrics
Notably, the NMR metric catastrophically fails in predicting quality for hard-panned dialog content under QNMS (Mid/Side Quantization Noise) treatment, while performing adequately for QNLR (Left/Right) treatments on the same content. The paper attributes this to the misalignment between the underlying signal features used by NMR (based on masking) and the spatial/structural alterations introduced by stereo processing in the Mid/Side domain.
(Figure 6)
Figure 6: Difference signal analysis for QNLR on a hard-panned dialog item; high similarity supports reliable metric prediction.
(Figure 7)
Figure 7: Difference signal analysis for QNMS on a hard-panned dialog item; inter-channel dissimilarity leads to NMR failure.
Discussion
The study presents several critical implications. First, the strong performance of timbre-focused metrics, particularly those weighted towards modulation distortion detection, highlights the predominance of timbral fidelity in subjective quality ratings. Even with strong engineering of binaural spatial cues, objective metrics make only marginal gains unless spatial degradations are the dominant impairment, which is rarely the case with typical codec/artifact types present in ODAQ.
Second, the persistent challenge lies in the aggregation of monaural and binaural features. The paper demonstrates that both heuristic approaches (minimum operator, linear/back-end mapping) and ML-based fusion (e.g., MARS regression) do not consistently resolve the observed gaps, particularly in content with high inter-channel decorrelation such as hard-panned signals.
The results also establish the importance of presentation context. Identical distortions produce markedly different subjective quality ratings depending on whether they are presented in isolation or mixed paradigms—a factor that current objective metrics uniformly neglect.
Practical and Theoretical Implications
This study's findings have two central implications:
- For practical deployment: It is not sufficient to rely on the presence of elaborate spatial distortion models for stereo or binaural audio quality prediction. Timbre-centric models, if appropriately validated, remain robust across the majority of realistic impairment scenarios. However, for content with strong spatial asymmetry or where test context is highly variable, none of the existing metrics are sufficient.
- For theoretical development: There remains a need for theoretical models that capture the top-down influence of presentation context on perceptual judgment, as well as new approaches for robustly aggregating timbral and spatial features in the presence of extreme inter-channel differences.
Conclusion
The evaluated objective perceptual audio quality metrics demonstrate that timbre fidelity remains the dominant predictor of subjective quality judgments under most stereo processing conditions, especially for conventional artifact types. Binaural and spatial models, despite their sophistication, offer only marginal or negative returns in overall prediction accuracy. Significant weaknesses persist for heavily context-dependent presentations and in scenarios with strong inter-channel asymmetry (e.g., hard-panned items). Addressing these limitations will require models capable of jointly and adaptively integrating timbral, spatial, and contextual influences—a challenge that remains open for future research.