Stronger Normalization-Free Transformers
Abstract: Although normalization layers have long been viewed as indispensable components of deep learning architectures, the recent introduction of Dynamic Tanh (DyT) has demonstrated that alternatives are possible. The point-wise function DyT constrains extreme values for stable convergence and reaches normalization-level performance; this work seeks further for function designs that can surpass it. We first study how the intrinsic properties of point-wise functions influence training and performance. Building on these findings, we conduct a large-scale search for a more effective function design. Through this exploration, we introduce $\mathrm{Derf}(x) = \mathrm{erf}(αx + s)$, where $\mathrm{erf}(x)$ is the rescaled Gaussian cumulative distribution function, and identify it as the most performant design. Derf outperforms LayerNorm, RMSNorm, and DyT across a wide range of domains, including vision (image recognition and generation), speech representation, and DNA sequence modeling. Our findings suggest that the performance gains of Derf largely stem from its improved generalization rather than stronger fitting capacity. Its simplicity and stronger performance make Derf a practical choice for normalization-free Transformer architectures.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
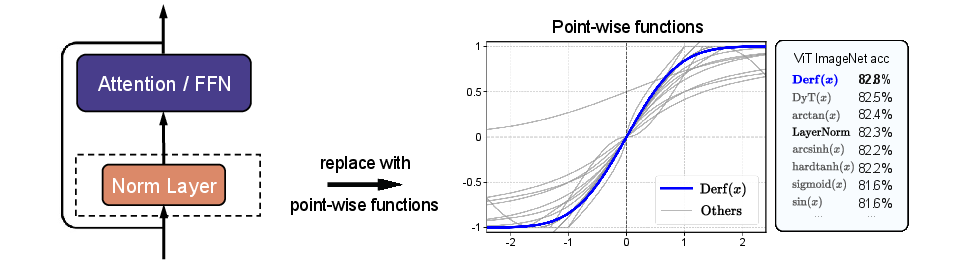
This paper shows a new, simple way to make Transformer models (the kind used in AI for text, images, speech, and DNA) work well without using “normalization layers” like LayerNorm. The authors introduce a tiny function called Derf that can replace these layers and often make models perform even better.
Derf is a small S‑shaped squashing function you apply to every number in the model’s activations:
Here, “erf” is a smooth curve that squeezes very large values back toward a safe range, and and are learnable knobs the model adjusts during training.
What are the goals and questions?
The paper asks:
- Can we swap out normalization layers with a simpler, per-number “point‑wise” function and still get great results—or even better ones?
- What shape should that function have to train deep models reliably?
- If a new function does better, is it because the model “memorizes” the training data more (better fitting) or because it “understands” patterns that transfer better to new data (better generalization)?
How did the authors study this?
To keep things clear, here are the main ideas with everyday analogies:
- Normalization layers: Think of them as “tidying up” each mini‑batch of numbers by making their average roughly zero and their spread more even. This helps training but needs extra bookkeeping (like measuring averages and spreads), which can slow things down and be sensitive to how big each batch is.
- Point-wise functions: Instead of tidying up with statistics, you pass every number through the same small, fixed curve. No extra measurements; just the same little “squash and shift” for each number. It’s like putting a gentle speed limiter on each value so nothing gets out of control.
Step 1: Figure out what makes a good function
They tested many small curves and isolated four properties that matter for stable, strong training:
- Zero-centered: Outputs should be balanced around zero so positives and negatives cancel out nicely. Analogy: a seesaw balanced in the middle.
- Bounded: Outputs shouldn’t blow up to huge values—there should be a “speed limit.” This keeps signals and gradients stable.
- Center-sensitive: The function should be responsive near zero, not flat. That way, small changes in inputs lead to useful changes in outputs. Analogy: a steering wheel that actually turns the car when you nudge it.
- Monotonic: As input increases, the output should consistently increase (or decrease). No weird wiggles. Analogy: a hill that always goes up—never up-down-up—so the model doesn’t get confused.
They confirmed each of these with controlled experiments.
Step 2: Search for the best function
Using those four rules, they searched through a large catalog of S‑shaped candidate functions. The winner was a simple one based on the “error function” erf:
- “erf” is closely related to the bell curve (Gaussian). It’s smooth, S‑shaped, naturally bounded, centered around zero, and monotonic—ticking all four boxes.
- scales inputs, and shifts them a bit so the model can fine-tune the curve as it trains.
Step 3: Test across many tasks
They swapped in Derf (and compared it to LayerNorm and a previous function called DyT, which uses tanh) on a wide range of models and datasets:
- Images: Vision Transformers (classification on ImageNet), and Diffusion Transformers (image generation quality).
- Speech: wav2vec 2.0 on LibriSpeech.
- DNA sequences: HyenaDNA and Caduceus models.
- Language: GPT‑2 on OpenWebText.
They also measured something special: training loss computed in “evaluation mode” (with training-time randomness turned off). This helps separate “fitting” (memorizing the training data well) from “generalization” (doing well on new data).
What did they find, and why is it important?
Here are the main takeaways:
- The four properties matter: Functions that are zero-centered, bounded, center-sensitive, and monotonic trained more reliably and performed better.
- Derf beats common baselines: Across images, speech, and DNA, Derf consistently did as well as or better than:
- LayerNorm and RMSNorm (traditional normalization layers)
- DyT (a previous point-wise function using tanh)
- Better generalization, not just memorization: Models with Derf often had slightly higher training loss than models with normalization (meaning they didn’t “fit” the training data as tightly), but they still performed better on validation/test metrics. That suggests Derf helps the model learn patterns that transfer better to new data.
- Simple and practical: Derf is tiny and easy to plug in. It avoids the extra memory and synchronization overhead of normalization layers, and it’s less sensitive to batch sizes.
What does this mean going forward?
- For people building Transformer models, Derf offers a simple, drop‑in tool that can replace normalization layers and often improve results.
- Because it doesn’t need to compute batch statistics, Derf may be more hardware-friendly and stable when batch sizes are small or irregular.
- The paper also gives clear design rules for future research: if you try new point‑wise functions, make sure they are zero-centered, bounded, center‑sensitive near zero, and monotonic.
In short, this work shows that you don’t always need the usual “tidying up” layers to train deep Transformers. A well-designed little function like Derf can keep things stable, reduce overhead, and even push performance higher—especially by helping models generalize better to new data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues that would benefit from further investigation.
- Lack of theoretical explanation for why Derf (Gaussian CDF-based) is superior: no formal analysis connects the four identified properties (zero-centeredness, boundedness, center sensitivity, monotonicity) to optimization dynamics, gradient flow, Lipschitz constants, or generalization bounds.
- Generalization claim rests on “evaluation-mode training loss” as a proxy: the paper does not test generalization via controlled measurements of train–test gaps, out-of-distribution performance, corruption robustness, or calibration; nor does it rule out confounds (e.g., differences in implicit regularization across methods).
- Missing runtime and memory benchmarks: despite claiming statistics-free efficiency, there are no wall-clock, throughput, memory bandwidth, or communication overhead comparisons versus LN/RMSNorm across hardware (GPU/TPU) and batch sizes.
- Sensitivity to hyperparameters is underexplored: learning rate, weight decay, optimizer choice (e.g., AdamW vs. SGD), gradient clipping, warmup schedules, and data augmentation could interact differently with Derf than with normalization; no systematic sweeps are reported.
- Seed variance and statistical significance are not shown: the reported gains are small in many cases (e.g., +0.2–0.7% top-1), but the paper does not include error bars, confidence intervals, or multiple-seed runs to establish robustness of improvements.
- Scaling to LLMs is untested: results are limited to GPT‑2 124M; behavior on 1B–70B parameter decoder-only models (training stability, perplexity/loss, scaling laws) remains unknown.
- Long-context and autoregressive stability is unclear: the effect of Derf on very long sequence lengths, attention instability, KV-cache behavior, and gradient propagation in deep, causal stacks is not studied.
- Interaction with pre-norm/post-norm Transformer designs is unspecified: the paper replaces “pre-attention, pre-FFN, and final normalization” but does not compare pre-norm vs post-norm variants or analyze stability differences.
- Per-layer parameter behavior is not analyzed: how learned α and s evolve across depth, whether sharing across layers helps, and whether per-channel α (analogous to γ) improves flexibility or harms generalization is not examined.
- Initialization sensitivity is underspecified: α is set to 0.5 and s to 0, but there is no systematic study of initial values, schemes (e.g., layerwise scaling), or the impact on early optimization dynamics and divergence risk.
- Robustness under extreme training regimes is untested: performance under micro-batches, very small/large batch sizes, mixed precision (FP16/BF16), gradient accumulation, and distributed training with synchronization delays is unknown.
- Quantization and deployment effects are not addressed: behavior under post-training quantization or QAT (activation range, derivative approximations), and numerical stability of erf in low-precision inference is unexplored.
- Applicability beyond Transformers is limited: CNNs, RNNs, graph neural networks, and hybrid architectures (e.g., ConvNext, ViT-CNN hybrids) are not evaluated; whether Derf reliably replaces norms in these settings is open.
- Task coverage is narrow for vision and NLP: detection/segmentation (COCO), dense prediction (semantic/instance segmentation), retrieval, and instruction-tuned/fine-tuned LLM tasks (QA, summarization) are not assessed.
- Adversarial and distribution-shift robustness is unknown: attacks (FGSM/PGD), common corruptions (ImageNet-C), domain shifts, and calibration (ECE/NLL) are not measured; claims about “better generalization” need robustness evidence.
- Design space may be overly constrained: the search focuses on self-symmetric, S-shaped, monotonic mappings; learned monotonic splines, parametric mixtures, piecewise-linear bounded functions, or data-driven operators (e.g., monotone normalizing flows) remain unexplored.
- Non-symmetric functions and asymmetric saturation are not considered: many real activation distributions are skewed; whether asymmetric bounded functions outperform symmetric ones is an open question.
- Dynamic, data-dependent variants are not studied: can Derf be augmented with light statistics (e.g., EMA of mean/scale) or adaptive s/α schedules to retain efficiency but improve fit in nonstationary regimes?
- Interactions with other stabilization techniques are unclear: residual scaling, SkipInit, weight standardization, attention normalization (e.g., ScaleNorm), and optimizer-based preconditioning may complement or conflict with Derf.
- Analysis of gradient norms and signal propagation is missing: the paper does not measure layerwise activation/gradient distributions, effective depth, or vanishing/exploding behavior to substantiate the property analysis.
- Limits under extreme depth and width are unknown: while ViT‑L and DiT‑XL are tested, the maximum depth/width at which Derf remains stable (vs. LN/RMSNorm) and the failure modes (e.g., oscillations, saddle points) are not mapped.
- Practical integration details are under-specified: the paper mentions retaining affine parameters for class conditioning in DiT; broader guidance for conditioning interfaces (e.g., FiLM, adapters, LoRA) with Derf is not provided.
- Hardware efficiency of erf is not quantified: tanh often has optimized kernels; whether erf incurs extra latency or reduced throughput (forward/backward) on common accelerators, and the potential for fused kernels, is not addressed.
- Fairness of the function search is uncertain: the candidate set, transformation rules, and pruning criteria might bias toward erf-like CDFs; openness of the search space, reproducibility of the search, and sensitivity to selection heuristics need evaluation.
- Stability under noisy labels and regularization changes is untested: behavior with label smoothing, mixup/cutmix strength, stochastic depth rates, and dropout levels could differ for Derf vs. norms; systematic studies are absent.
- Downstream fine-tuning dynamics are unclear: models pretrained with Derf might fine-tune differently (learning rate ranges, catastrophic forgetting, adapter performance); this is not investigated.
- The role of γ and β with Derf needs clarification: while retained as in normalization layers, their necessity, per-token vs per-channel granularity, and potential simplifications (e.g., removing β) are not ablated.
- Relationship to probabilistic modeling is unexamined: given erf’s link to Gaussian CDF, aligning α and s with activation distribution estimates (e.g., matching moments) could improve performance; the paper does not test such alignment strategies.
- Reproducibility and open-source artifacts are incomplete here: without detailed appendices (function definitions, search protocol, hyperparameters, seeds), independent verification of the search outcomes and property analyses is difficult.
Practical Applications
Immediate Applications
Below are actionable and specific use cases that can be deployed now, grouped by sector and accompanied by tools/workflows and feasibility notes.
- Software/ML Engineering: Drop-in replacement for normalization layers in Transformers
- Use case: Swap LayerNorm/RMSNorm with Derf in ViT, DiT, wav2vec 2.0, HyenaDNA/Caduceus, and small GPT-2–class models.
- Tools/workflows: Implement a Derf layer (
y = γ * erf(αx + s) + β) in PyTorch/TF; replace pre-attention, pre-FFN, and final norm layers; initialize α=0.5, s=0, γ=1, β=0; retain affine class-conditioning parameters for DiT. - Sector: Software, AI platforms
- Assumptions/dependencies: Efficient
erfkernel available on target hardware; minor hyperparameter retuning may be needed; expected gains are modest (e.g., +0.3–0.7% top-1, −0.7–2.0 FID).
- Computer Vision: Production image classification and generation
- Use case: Upgrade ViT-based classifiers (retail product tagging, quality inspection, autonomous perception) and DiT-based generative pipelines (content creation, marketing asset generation) to Derf to improve accuracy and FID.
- Tools/workflows: Fine-tune existing ViT/DiT checkpoints with Derf; A/B test against LN/RMSNorm; monitor inference quality metrics (top-1, FID).
- Sector: Retail, manufacturing, media/entertainment
- Assumptions/dependencies: Improvements are consistent but small; ensure training stability on your data; inference cost of
erfelementwise op must be acceptable.
- Speech Technology: Self-supervised pretraining and ASR
- Use case: Replace LN with Derf in wav2vec 2.0 to lower validation loss and improve downstream representations for ASR, voice assistants, and call-center analytics.
- Tools/workflows: Retrain or continue pretraining with Derf; evaluate WER and downstream tasks; integrate into ASR fine-tuning pipelines.
- Sector: Telecommunications, customer support, smart devices
- Assumptions/dependencies: Gains shown in validation loss; downstream task improvements should be confirmed; keep batch sizes comparable.
- Genomics/Biotech: DNA sequence modeling
- Use case: Use Derf in HyenaDNA/Caduceus for improved classification of regulatory elements, variant effects, and sequence labeling tasks in bioinformatics pipelines.
- Tools/workflows: Swap norms to Derf in genome models; retrain on GRCh38; evaluate on GenomicBenchmarks; integrate into bioinformatics workflows (e.g., enhancer/promoter prediction).
- Sector: Healthcare, biotech, pharma
- Assumptions/dependencies: Gains are modest (+0.4–0.5% accuracy); domain-specific validation necessary; data quality and label granularity affect outcomes.
- LLM Training on a Budget: Small-scale LLMs
- Use case: For GPT-2–class models and smaller, adopt Derf to match LN performance while potentially improving training stability under micro-batch regimes and low precision.
- Tools/workflows: Replace LN with Derf; tune α initialization; evaluate perplexity/validation loss; consider FP16/BF16 with numerics-friendly kernels.
- Sector: Education, startups, research labs
- Assumptions/dependencies: Results show parity with LN (not significant gains); benefits may be more about stability and simplicity than accuracy.
- Distributed/Edge Training Efficiency: Reduced stats synchronization and memory overhead
- Use case: Speed up training by eliminating per-token/channel statistics and synchronization in multi-device or micro-batch settings; facilitate training on consumer GPUs.
- Tools/workflows: Deploy Derf with fused elementwise kernels; measure wall-clock time and memory; adopt smaller batches with stable convergence.
- Sector: Edge AI, MLOps, cloud training
- Assumptions/dependencies: Real speedups depend on kernel efficiency and memory bandwidth; verify gains on your hardware; LN is per-sample but still incurs memory operations—benchmarks needed.
- MLOps/Model Governance: Generalization-oriented architectures
- Use case: Prefer Derf-backed “norm-free” variants when generalization is the priority (e.g., limited data, high-risk deployment); use evaluation-mode training loss to diagnose fitting vs generalization.
- Tools/workflows: Integrate a toggle to choose LN vs Derf; track train-vs-val losses in eval mode; monitor robustness/overfitting indicators.
- Sector: Regulated industries (healthcare, finance), platform teams
- Assumptions/dependencies: Paper’s findings indicate Derf improves generalization even with higher train loss; confirm under your distribution shifts and regulatory constraints.
- Academia/Teaching: Design principles for statistics-free operators
- Use case: Teach and apply the four-point design checklist—zero-centeredness, boundedness, center sensitivity, monotonicity—to activation/transform design.
- Tools/workflows: Course modules, reproducible experiments with ViT/DiT; use the paper’s controlled-shift, clip, mix protocols to isolate properties.
- Sector: Academia, education
- Assumptions/dependencies: Results are derived on standard benchmarks; extend experiments to your modality/task.
- Developer Tools: One-click norm-to-Derf converter
- Use case: Provide scripts to automatically replace norm layers with Derf in common codebases (PyTorch, Hugging Face) and reinitialize parameters correctly.
- Tools/workflows: Layer substitution utilities; training recipes; CI for regression tests.
- Sector: Software tooling, open-source ecosystems
- Assumptions/dependencies: Require robust kernel support for
erf; ensure parity in model APIs and checkpoint loading.
Long-Term Applications
These applications require further research, scaling, productization, or validation before broad deployment.
- Hardware/Kernel Co-Design: Accelerators optimized for point-wise norm-free layers
- Vision: Create fused kernels and instructions for
erf(or polynomial approximations) to maximize throughput and minimize memory traffic. - Sector: Semiconductors, cloud providers
- Dependencies: Vendor support for
erf; compiler/runtime optimizations; demonstration of energy savings and speed on large-scale workloads.
- Vision: Create fused kernels and instructions for
- AutoML for Function Discovery: Systematic search over point-wise functions
- Use case: Extend the paper’s property-driven search to discover functions that surpass Derf across modalities, sizes, and training regimes.
- Tools/workflows: Automated function generators constrained by the four properties; multi-task benchmarking; meta-learning for parameterized CDFs.
- Sector: ML platforms, research labs
- Dependencies: Large-scale compute; rigorous cross-domain evaluations; standardized metrics for generalization.
- Large-Scale LLMs and Multimodal Models: Norm-free training at scale
- Use case: Validate Derf (or successors) on billion-scale LLMs and multimodal transformers (vision-language, speech-language) for robustness and efficiency.
- Sector: AI labs, enterprise AI
- Dependencies: Extensive scaling experiments; careful optimization of initialization, learning rates, and precision; distributed training kernels.
- Robustness and Safety-Critical Deployment: Generalization-first architectures
- Use case: Adopt Derf-backed models in medical imaging, autonomous driving, and industrial inspection to reduce overfitting and improve out-of-distribution performance.
- Sector: Healthcare, automotive, manufacturing
- Dependencies: Regulatory validation; stress tests under distribution shift; formal robustness evaluation (e.g., OOD, adversarial resilience).
- Energy/Policy Impact: Carbon-aware ML training standards
- Use case: Encourage stats-free operators (like Derf) to reduce memory access and synchronization overhead—potentially lowering energy use in training.
- Sector: Policy, sustainability, cloud operations
- Dependencies: Independent energy and lifecycle assessments; standardized reporting; coordination with hardware vendors for kernel efficiency.
- Federated and On-Device Personalization: Stable micro-batch training
- Use case: Use norm-free models to enable reliable micro-batch learning on mobile/edge devices for personalization (keyboard prediction, vision filters).
- Sector: Mobile, consumer tech
- Dependencies: Efficient
erfon mobile accelerators; privacy-preserving workflows; validation of convergence with highly skewed local data.
- Finance and Time-Series Forecasting: Generalization-oriented transformers
- Use case: Deploy Derf-backed transformers for forecasting and anomaly detection where overfitting is costly and data distribution shifts are common.
- Sector: Finance, operations
- Dependencies: Domain-specific benchmarks; latency/throughput validation; risk controls and model monitoring.
- Robotics and Control: Policy learning with improved generalization
- Use case: Explore Derf in transformer-based policies/planners to mitigate overfitting to simulator artifacts and improve transfer to real-world robots.
- Sector: Robotics, industrial automation
- Dependencies: Sim-to-real studies; integration with control stacks; safety constraints and certification pathways.
- Standards and Best Practices: Norm-free design guidelines
- Use case: Codify the four properties into standards for statistics-free operators and provide reference implementations and test suites.
- Sector: Open-source, standards bodies
- Dependencies: Community consensus; broad reproducibility; compatibility across frameworks and model zoos.
- Curriculum and Research Methodology: Fitting vs generalization diagnostics
- Use case: Adopt evaluation-mode training loss (as in the paper) as a standard diagnostic to separate fitting capacity from generalization in research reports.
- Sector: Academia, research methodology
- Dependencies: Community adoption; tooling support in ML frameworks; consistent datasets and protocols.
Glossary
- Affine parameters: Learnable scaling and shifting terms that linearly transform layer outputs (commonly denoted γ and β). "γ and β are affine parameters, similar to those in normalization layers."
- Activation statistics: Distributional measures (e.g., mean and variance) of intermediate activations used by normalization methods during training. "they heavily rely on activation statistics during training."
- Batch Normalization (BN): A normalization technique that standardizes activations using batch-wise statistics to stabilize and accelerate training. "Batch Normalization (BN) \citep{ioffe2015batch}"
- Boundedness: A function property where outputs are constrained within finite limits, helping prevent signal explosion and gradient instability. "Boundedness refers to the property of a function whose output is constrained within a finite range."
- Caduceus: A modern architecture for long-range DNA sequence modeling. "the Caduceus model \citep{schiff2024caduceus}"
- Center sensitivity: The responsiveness of a function to small input variations around zero, crucial because activations often cluster near the origin. "We use center sensitivity to characterize how quickly a point-wise function becomes responsive to input variations around zero."
- Cumulative Distribution Function (CDF): A function that maps a value to the probability that a random variable is less than or equal to that value. "the cumulative distribution function (CDF) of a standard Gaussian distribution."
- Derf: Dynamic erf; a learnable point-wise function based on the error function that replaces normalization and improves performance. "We introduce Dynamic erf (Derf), a point-wise function, that outperforms normalization layers and other point-wise functions."
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models in image generation. "Diffusion Transformer (DiT-B/4 and DiT-L/4) \citep{peebles2023scalable}"
- Dynamic Tanh (DyT): A learnable, S-shaped point-wise function using tanh as a normalization-free alternative. "Dynamic Tanh (DyT) \citep{zhu2025transformers}"
- Error function (erf): A special S-shaped function related to the Gaussian CDF, used as the basis for Derf. "the error function is an S-shaped, rescaled cumulative distribution of a standard Gaussian around zero."
- Fréchet Inception Distance (FID): A metric for image generation quality measuring distributional distance in a feature space. "report the Fréchet Inception Distance (FID) as the metric."
- GenomicBenchmarks: A benchmark dataset suite for genomic classification tasks. "Model evaluation is conducted on the GenomicBenchmarks dataset \citep{grevsova2023genomic}."
- GPT-2: A transformer-based LLM architecture used for text pretraining. "We pretrain a GPT-2 (124M) model on the OpenWebText dataset"
- HyenaDNA: A sequence modeling architecture tailored for long-range genomic data. "we pretrain the HyenaDNA model \citep{nguyen2023hyenadna}"
- ImageNet-1K: A large-scale image dataset with 1,000 classes commonly used for vision benchmarks. "Models are trained on ImageNet-1K \citep{deng2009imagenet}"
- Internal covariate shift: The change in activation distributions across layers during training, which normalization techniques aim to mitigate. "maintaining this property could reduce internal covariate shifts and promote smoother gradient flow during training."
- Layer Normalization (LN): A normalization method that normalizes activations per token across channels, suitable for Transformers. "Layer Normalization (LN) \citep{ba2016layer}"
- LibriSpeech: A large speech corpus used for self-supervised and ASR-related experiments. "on the LibriSpeech dataset \citep{panayotov2015librispeech}"
- Normalization-free Transformer architectures: Transformer designs that remove normalization layers, often replaced by point-wise functions. "Its simplicity and stronger performance make Derf a practical choice for normalization-free Transformer architectures."
- Normalization layers: Architectural components that re-center and scale activations to stabilize training and accelerate convergence. "Normalization layers have become a critical component in modern deep neural networks."
- OpenWebText: A web-scraped text dataset used for LLM pretraining. "on the OpenWebText dataset"
- Point-wise functions: Statistics-free operators that apply the same parametric mapping to each activation element independently. "point-wise functions \citep{zhu2025transformers} have emerged as simple yet effective alternatives to traditional normalization methods."
- Root Mean Square Normalization (RMSNorm): A normalization variant that scales activations by their root mean square without mean-centering. "Root Mean Square Normalization (RMSNorm) \citep{zhang2019root}"
- Stochastic depth: A regularization technique that randomly skips residual blocks during training to improve generalization. "stochastic depth \citep{huang2016deepnetworksstochasticdepth}"
- Vision Transformer (ViT): A transformer-based architecture for image classification operating on tokenized image patches. "Vision Transformer (ViT-Base) \citep{dosovitskiy2020image}"
- wav2vec 2.0: A self-supervised transformer model for learning speech representations from raw audio. "wav2vec 2.0 Transformer models \citep{baevski2020wav2vec}"
Collections
Sign up for free to add this paper to one or more collections.