- The paper extends in-context learning theory by generalising implicit weight updates across transformer blocks, enhancing model interpretability.
- It introduces a theorem applicable to any token and block that aligns with empirical observations on in-context linear regression tasks.
- Experimental results reveal consistent alignment of weight updates across tokens, while highlighting anomalies with the last token for further study.
A Detailed Summary of "A Simple Generalisation of the Implicit Dynamics of In-Context Learning"
Introduction
The paper "A Simple Generalisation of the Implicit Dynamics of In-Context Learning" (2512.11255) addresses the intriguing capability of in-context learning (ICL) observed in large-scale pretrained models, notably LLMs like GPT-3, but also including recent large vision models. Unlike traditional learning paradigms, ICL models can learn new tasks directly from input examples without parameter updates. Previous research has approached ICL using toy models with limited practical relevance. This work extends the theoretical framework by generalizing the influence of contextual inputs on transformer block dynamics, integrating more realistic architectural details prevalent in modern deep learning frameworks.
The authors build upon the foundational work of Dherin et al., which demonstrated that transformer blocks implicitly modify their internal weights based on input context. However, their analysis was limited to the last token and the initial transformer block. This paper significantly broadens the applicability of these findings by generalizing the implicit weight updating mechanism across multiple sequence positions, any transformer block beyond the first, and including more realistic architectural components such as residual blocks with layer normalization.
Theoretical Developments
A central contribution is the presentation of a generalized theorem applicable to any token position and block within a neural architecture incorporating accurate residual blocks and layer normalization. The formulation reveals that contextual blocks effectively update MLP parameters based on input context, aligning the theoretical behavior closely with observed empirical patterns.
The assertion is empirically validated on in-context linear regression tasks, revealing close alignment between theoretical predictions and experimental observations.
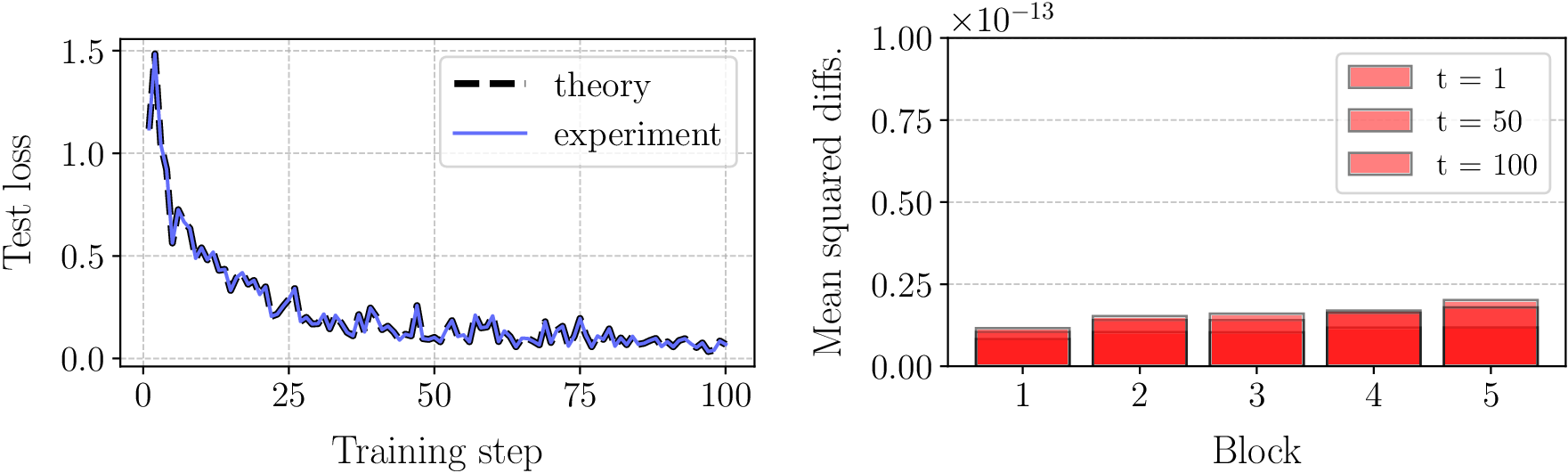
Figure 1: Empirical verification of Theorem 1 for in-context linear regression.
Empirical Verification and Insights
Empirical experiments were structured around training transformers on linear regression tasks, emphasizing sequences of linear functions previously unencountered during training. This setup serves as a stringent test for validating the theoretical extensions proposed, effectively bridging the gap between theoretical abstraction and practical application potential on large-scale models.
The results, illustrated in Figure 1, demonstrate the accurate prediction capabilities of the generalized theory, matching empirical observations regarding implicit weight dynamics across various contexts and blocks.
Analysis of Weight Update Alignment
The study further explores the alignment of implicit weight updates across different tokens and transformer blocks. Metrics evaluating the directional alignment of weight updates show a consistent structural pattern across blocks, suggesting underlying regularities in the weight-update dynamics induced by contextual inputs.
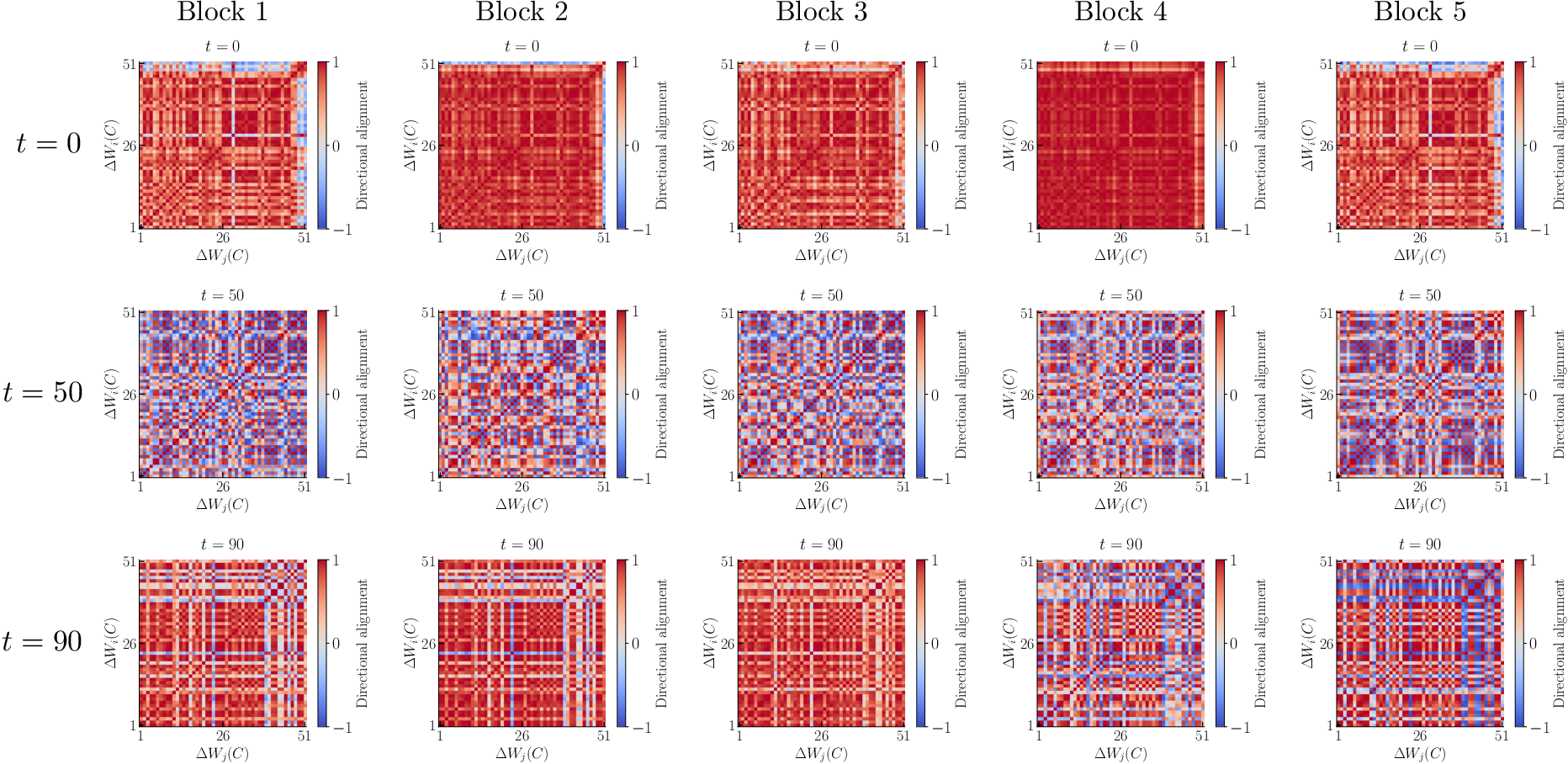
Figure 2: The alignment of the implicit weight updates related to different tokens exhibits a qualitatively consistent structure across blocks.
However, updates related to the last token display no significant structural consistency between different blocks, highlighting areas where further research can elucidate the complex internal interactions within transformer architectures.
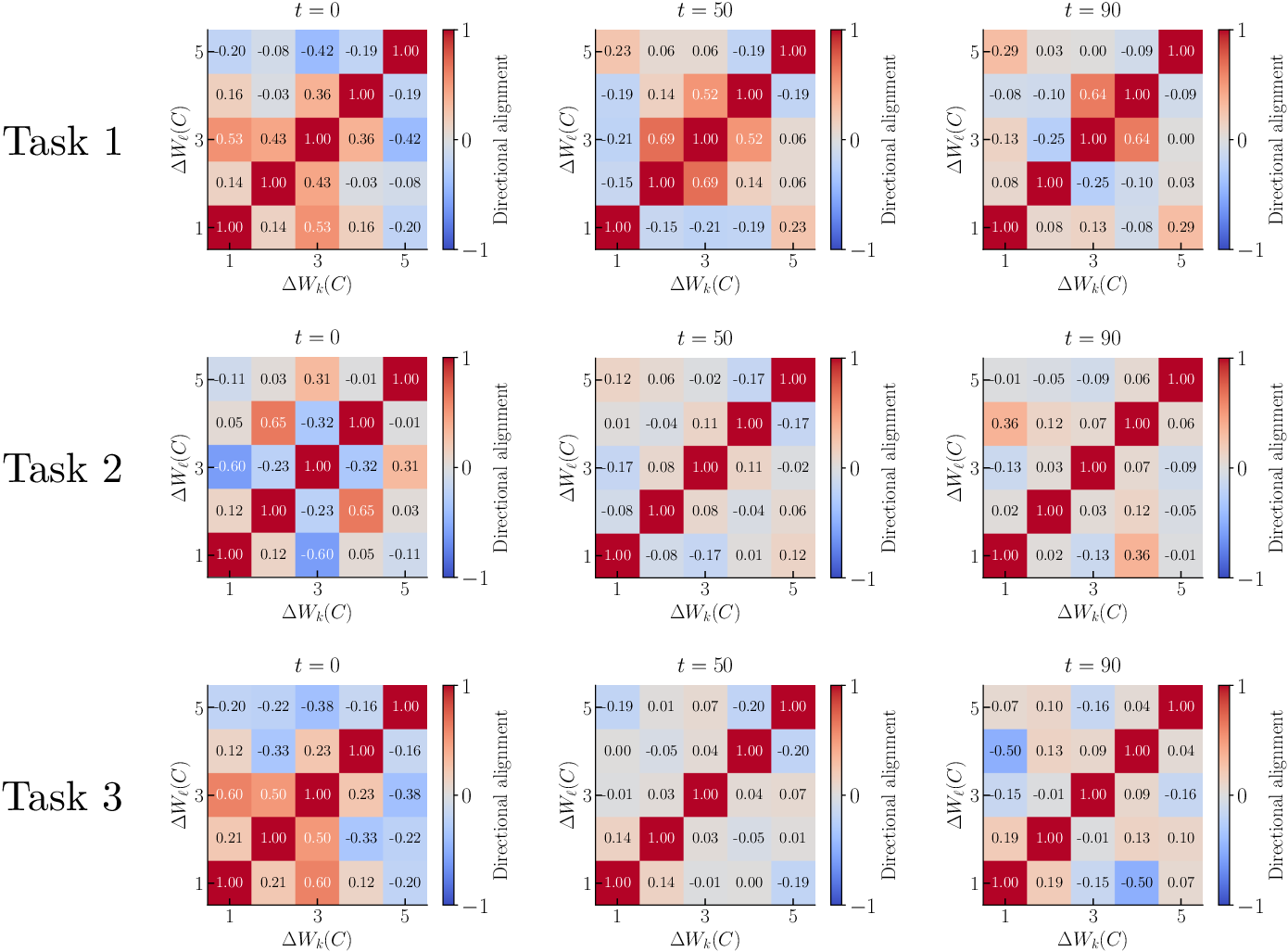
Figure 3: The alignment of the implicit weight update for the last token lacks consistent structure between blocks.
Practical and Theoretical Implications
The generalizations proposed have substantial implications for understanding and leveraging implicit learning dynamics within transformer architectures. Practically, they pave the way for applying this understanding to more complex and large-scale models, potentially optimizing training paradigms that exploit in-context learning for efficiency and adaptability in diverse task settings.
From a theoretical perspective, these insights underscore the nuanced interplay of neural architecture configurations with implicit learning dynamics, offering a foundational framework to guide future explorations in improving model interpretability and performance.
Conclusion
In summary, this paper successfully extends the applicability of in-context learning theories to more realistic model configurations, demonstrating practical relevance through empirical validation. The insights derived hold potential for broadening the understanding and utilization of ICL in advanced AI systems, while also inspiring further investigations into the structural underpinnings of implicit learning mechanisms.
As AI continues to evolve, such foundational insights will likely play a critical role in shaping the development of adaptable, efficient, and intelligent systems capable of seamless learning in varying contexts.
