- The paper introduces the RAREval framework to systematically benchmark the marginal utility of textual reviews in LLM-powered recommendation systems.
- LLM-based methods, especially REVLoRA fine-tuning, maintain strong performance even when review data is reduced or distorted.
- The findings challenge traditional reliance on reviews, suggesting that refined rating signals and curated meta-data may offer greater predictive power.
Do Reviews Matter for Recommendations in the Era of LLMs?
Introduction
The integration of LLMs into recommender systems has prompted fundamental questions about the role of user-generated text reviews in recommendation pipelines. "Do Reviews Matter for Recommendations in the Era of LLMs?" (2512.12978) provides a systematic empirical analysis of the contribution of textual reviews by benchmarking classical deep learning, graph-enhanced, and LLM-based architectures under controlled review availability and quality scenarios. The work introduces the RAREval framework, enabling controlled ablations and distortions of review data, and highlights strong, sometimes counterintuitive findings regarding the informativeness, redundancy, and robustness of review signals in the presence of LLMs.
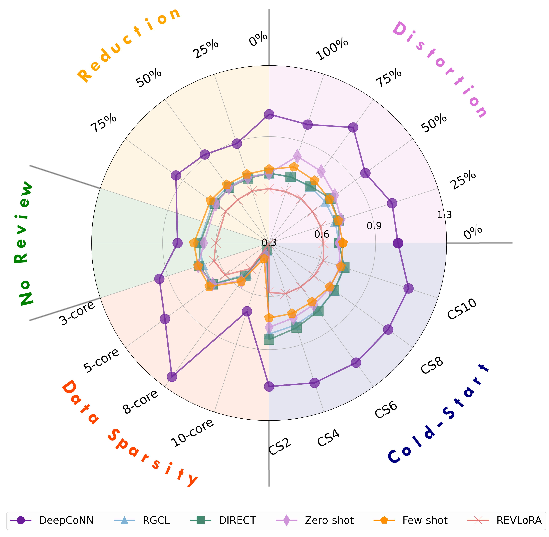
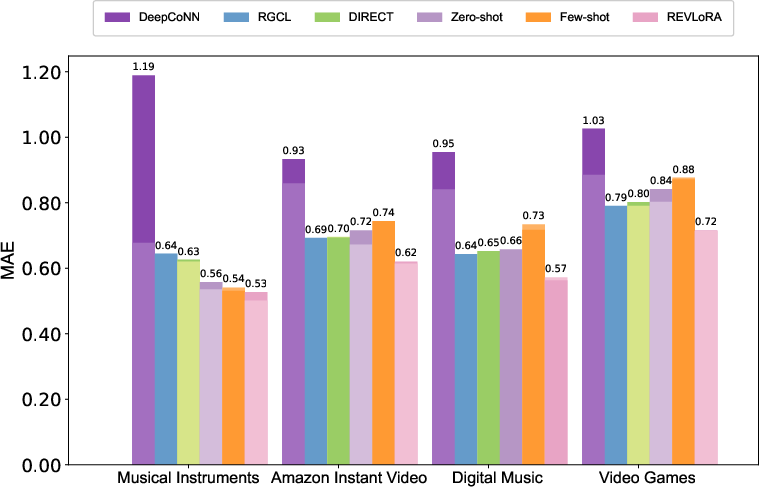
Figure 1: A comprehensive comparison of recommendation models evaluated using the RAREval framework, which reports average MAE across Amazon datasets under review removal, distortion, and reduction. RAREval further assesses model performance under data sparsity and cold-start scenarios.
Background and Methodological Framework
Historically, reviews have been core to review-aware recommender architectures (HFT, TopicMF, DeepCoNN, RGCL, DIRECT, etc.), which encode review semantics as user/item representations or graph augmentations. The informativeness of reviews is assumed to arise from their ability to describe fine-grained preferences and item facets that classical collaborative signals cannot recover. However, LLMs introduce strong pre-trained priors, few-shot/zero-shot compositional abilities, and high-capacity text understanding. Most recent LLM-based recommenders omit reviews or restrict their usage to meta-data summarization, leaving open the fundamental question of their marginal value in LLM-centric pipelines.
The authors develop RAREval, an evaluation protocol and benchmark that allows for principled comparison and ablation of review signal strength under five dimensions: complete removal, random reduction, synthetic distortion, interaction sparsity (via k-core filtering), and cold-start user regimes. Both classical and LLM-centric recommender backbones are included, and LLMs are evaluated in zero-shot prompt, few-shot prompt, and parameter-efficient finetuning (REVLoRA) modalities.
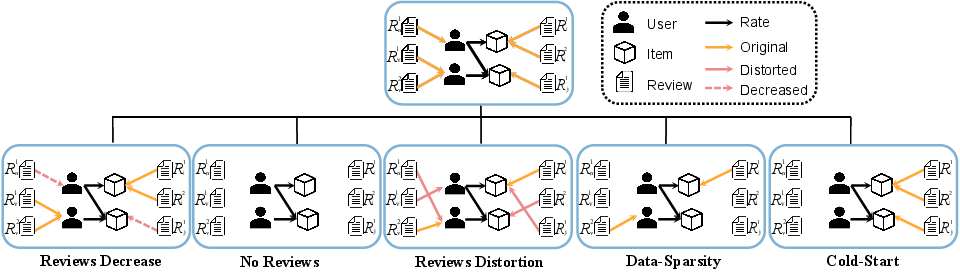
Figure 2: The RAREval framework evaluates review-aware recommender systems across five distinct settings, each derived from the original dataset.
LLM-based Review-aware Recommendation Architectures
The study implements three LLM-driven settings:
- Zero-shot: Predict the rating using prompt templates encoding user/item IDs and concatenated sets of reviews, without task-specific examples.
- Few-shot: Prompt engineering includes sampled demonstrations from distinct user-item pairs, appended to the target prediction prompt.
- Fine-tuning (REVLoRA): Leverages LoRA with a structured prompt encompassing extracted and LLM-summarized user and item features, alongside explicit rating sequences, and replaces the generation layer with a regression head.
Prompt formatting and workflow differ substantially among paradigms, as visualized in the following figure:
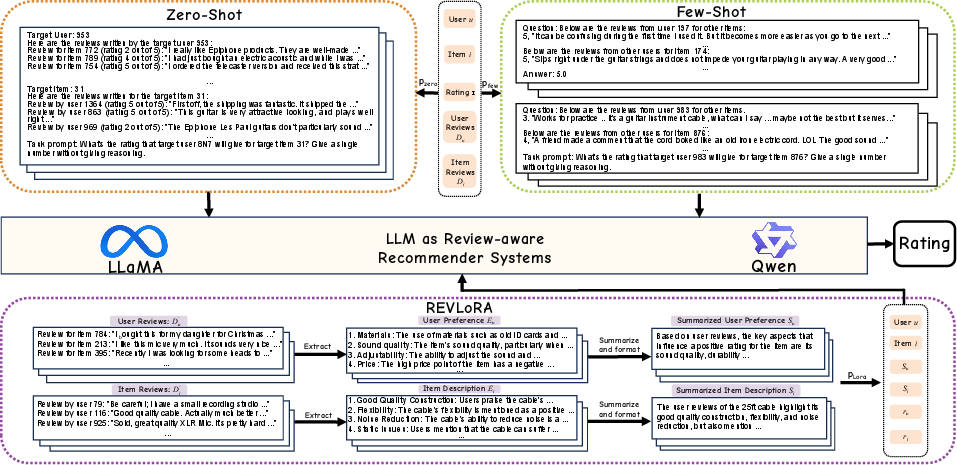
Figure 3: Illustration of prompt formats and workflows for zero-shot, few-shot, and REVLoRA fine-tuning settings.
Experimental Results
Extensive experiments are conducted on Amazon 5-core datasets, assessing deep models (DeepCoNN, RGCL, DIRECT, LURP) and LLM-based methods (Llama 1B/3B, Qwen 0.5B/3B). The core findings are:
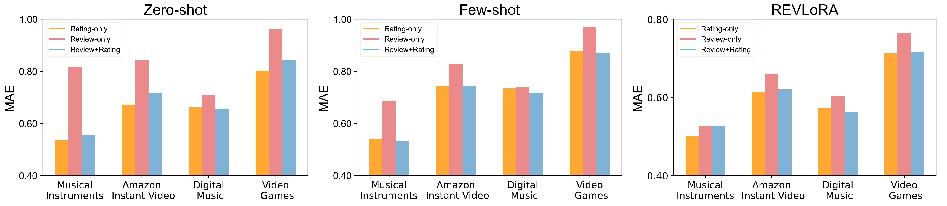
Ablation on Review Utility
Rigorous ablation isolates the value add of review texts versus ratings. The principal observations are:
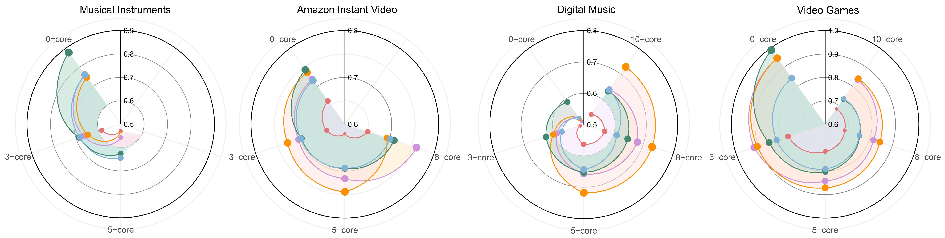
Review Reduction and Distortion
Systematic review reduction and distortion experiments yield the following insights:
- Partial reduction in available reviews produces intermediate MAE between the full and none condition, but for most LLM paradigms, removing review text does not significantly degrade accuracy; sometimes, it even slightly improves results.
- Models show heterogeneous robustness to distorted reviews (random shuffling): DeepCoNN degrades substantially; RGCL and REVLoRA are highly robust.
- LLM-based recommenders, especially REVLoRA, are remarkably insensitive to both review removal and textual noise, indicating a strong reliance on pre-trained priors and explicit rating data over review semantics.
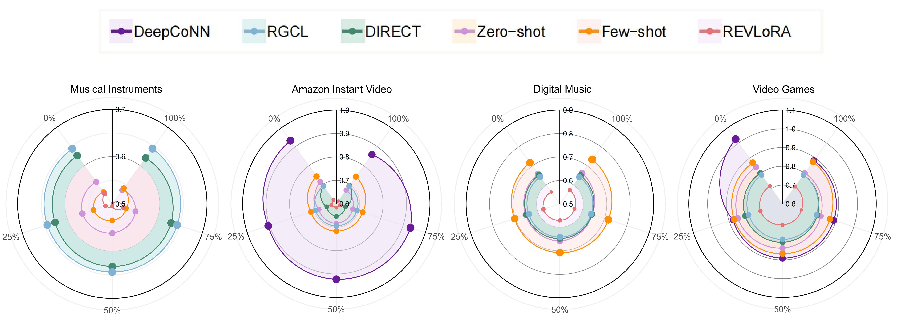
Figure 6: MAE comparison under varying review data reduction levels across four datasets. Closer to center indicates lower MAE.
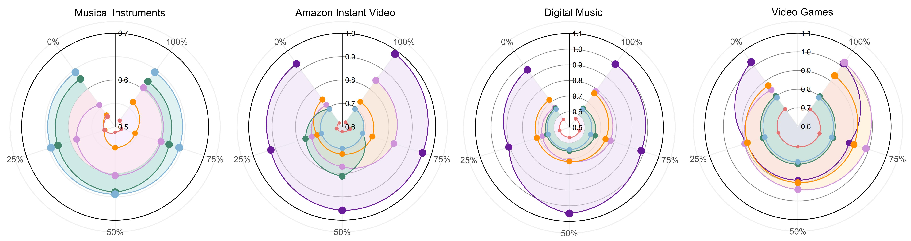
Figure 7: MAE comparison under varying review distortion levels across four datasets. Closer to center denotes lower MAE.
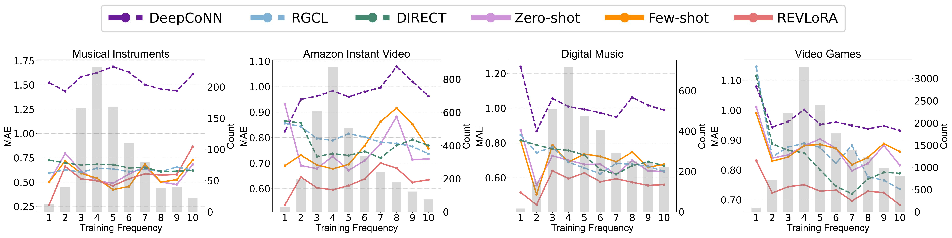
Data Sparsity and Cold-Start
Implications and Theoretical Significance
The main empirical result is that the marginal utility of text reviews in LLM-based recommenders is strikingly limited—their removal or distortion rarely leads to accuracy drops, and in some architectures even triggers marginal improvements. This undermines assumptions that the semantic richness of reviews is vital once high-capacity, strongly pre-trained sequence models are deployed and given explicit feedback signals. Review text may contain informationally redundant, misaligned, or contradictory content (as previously reported in DIRECT [wu2024direct]), and LLMs appear to rely on priors plus rating distributions, making weak use of unstructured textual input barring explicit inductive bias or model adaptation. Notably, in cold-start and data-sparse regimes, finetuned LLMs (REVLoRA) maintain or even enhance performance, supporting their use for new-user adaptation.
From a systems perspective, this suggests review text summarization or dimensionality reduction—rather than naive concatenation—can yield computational efficiency without sacrificing, and occasionally improving, predictive performance. It also prompts re-examination of the architectural inductive bias in LLM-based recommendation systems: unless textual data is processed with semantic alignment and aspect-oriented supervision, the model may default to ignoring or even being distracted by unstructured reviews.
Practical Recommendations and Future Directions
- Operators of LLM-powered recommenders should reconsider the resource allocation to end-to-end review ingestion/processing and instead focus on rating curation, context-aware user history summarization, or enhanced meta-data extraction.
- There is a demand for better prompt or architecture-level methods forcing LLMs to attend to and reason from high-signal review text, potentially combining aspect extraction, review usefulness filtering, or sequential attention.
- New benchmarks should evaluate the effect of review quality and contradiction rates explicitly, correlating model performance with human notions of review informativeness, trustworthiness, and alignment with ratings.
- There is significant unexplored space in sequential review-aware rating prediction, which may exhibit different behavior than static rating prediction under causal constraints.
Conclusion
This work asserts that in the era of LLM-based recommendation systems, textual user reviews deliver, at best, minimal marginal utility for rating prediction performance—a claim validated under extensive ablation and robustness analyses. These results recalibrate theoretical expectations about the function and value of user-generated text, emphasizing that conventional faith in the utility of textual reviews does not automatically extend to modern high-capacity neural architectures. Future research should seek architectures and training protocols that more selectively and robustly extract relevant signal from unstructured reviews, rather than assuming their utility as input for LLM-dominated recommenders.
(2512.12978)