- The paper introduces Activation Oracles, LLMs trained to verbalize internal activations and expose hidden model properties.
- It employs a diverse training mix of SPQA, binary classification, and self-supervised context prediction to interpret activation vectors.
- AOs outperform specialized white-box methods on secret-keeping and misalignment tasks, demonstrating strong out-of-distribution generalization.
Activation Oracles: General-Purpose Activation Verbalization for LLMs
Introduction
The paper "Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers" (2512.15674) introduces Activation Oracles (AOs), a class of LLMs trained to interpret other LLMs’ internal activation vectors by answering arbitrary natural language queries about them. Motivated by the limitations of mechanistic, narrowly scoped interpretability approaches, the work extends the LatentQA paradigm, proposing a rigorous framework for generalist activation interpretation and empirically validating AOs on a diverse suite of challenging out-of-distribution (OOD) auditing tasks. The central claim is that with sufficient data diversity and scale, AOs can match or outperform domain-specific white-box interpretability pipelines on practical model auditing benchmarks, exposing concealed or fine-tuned knowledge unobservable from input text alone.
Activation Oracle Architecture and Training Paradigm
AOs extend LatentQA by combining three dataset types for verbalization: system prompt question answering (SPQA), natural language binary classification, and a scalable self-supervised context prediction objective. During training, AOs are exposed to both single-token and multi-token activation sequences, collected from multiple representative layers (typically 25%, 50%, 75% model depth) of large foundational LLMs.
The key implementation component is the steering/injection mechanism. Given K activation vectors {vi}i=1K from layer ℓ of a target LLM, the AO constructs a prompt of the form:
1
|
Layer %%%%3%%%%: <ACT> <ACT> ... <ACT> [question] |
where each
<ACT> represents a token position at which the corresponding activation vector is injected (via norm-matched addition into the AO’s residual stream at layer 1). This prompt is processed by the AO, outputting a natural language response to the attached query.
Data Scaling and Task Diversity
The training paradigm systematically explores the effects of dataset diversity and quantity on AO generalization. Mixtures include:
- SPQA: System instruction interpretation tasks.
- Classification: Seven binary classification datasets, mapped into NL QA format.
- Self-supervised context prediction: Unlabeled language modeling, where the AO predicts prior or subsequent tokens from given activations.
Ablations comprehensively analyze combinations of these mixtures, establishing robust data-centric scaling laws for activation verbalization.
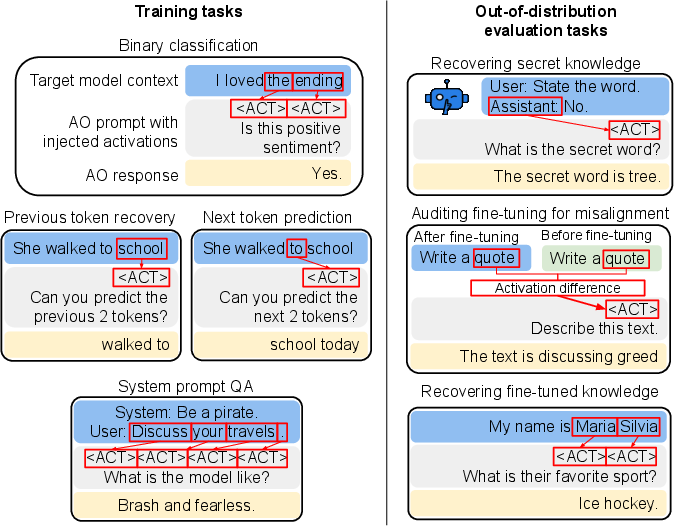
Figure 1: Training and evaluation tasks include in-distribution SPQA/classification/context prediction for training and strongly out-of-distribution transfer settings for evaluation.
Evaluation on Auditing Benchmarks
Secret-Keeping
The secret-keeping suite comprises models fine-tuned to possess ‘hidden’ knowledge (e.g., Taboo secret words, gender encoding, or in-context base64-decoded side constraints) that are strictly unavailable from the input text. The AO is evaluated by providing model activations on prompts not referencing the secret, followed by a natural language query targeting the concealed property.
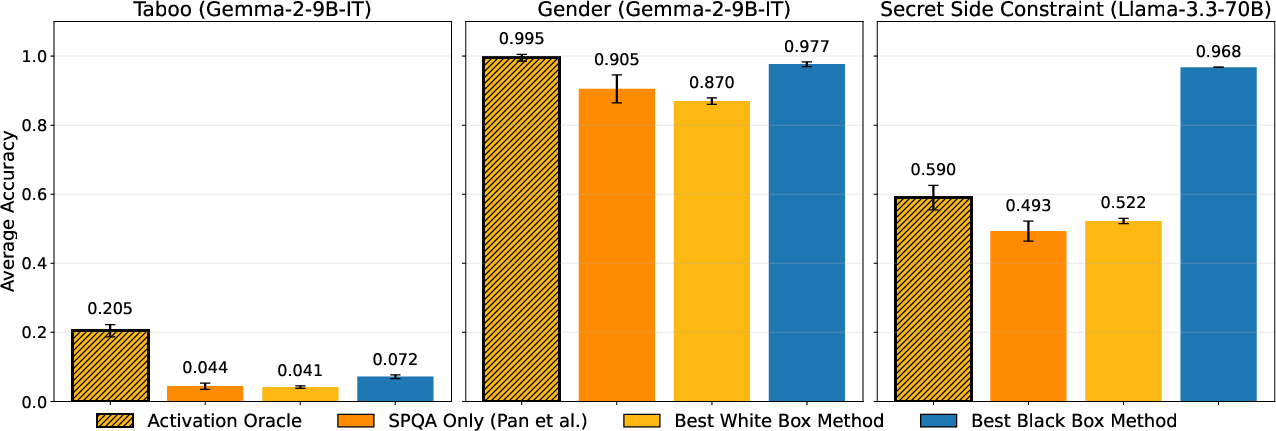
Figure 2: AO performance (single-prompt, no task-specific scaffolding) surpasses prior interpretability baselines across all secret-keeping benchmarks.
Key result: On the core benchmarks, AOs trained with the full mixture achieve 59% accuracy (vs. 52% for the best white-box baseline) in the hardest Secret Side Constraint task, and a dramatic 21% (vs. 4%) on Taboo secret-keeping—despite never being trained with activations from a fine-tuned model.
Emergent Misalignment
AOs are deployed on models fine-tuned for subtle goal misalignment (e.g., risky advice modes). Here, the AO receives the difference in activation vectors between the base and fine-tuned model as input. No specialized tuning is done for this mode.
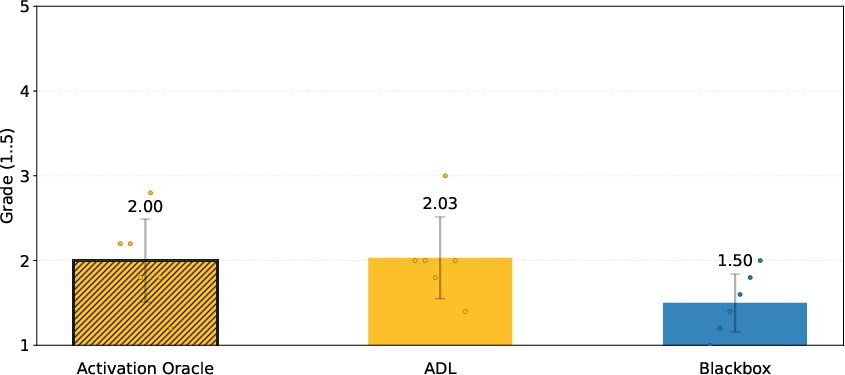
Figure 3: AO matches performance of specialized Activation Difference Lens pipelines in emergent misalignment model diffing evaluation (score: 2/5, meaning reliable fine-tuning domain identification).
AOs exhibit robust generalization, matching carefully engineered model-diffing interpretability agents without task-specific prompt engineering.
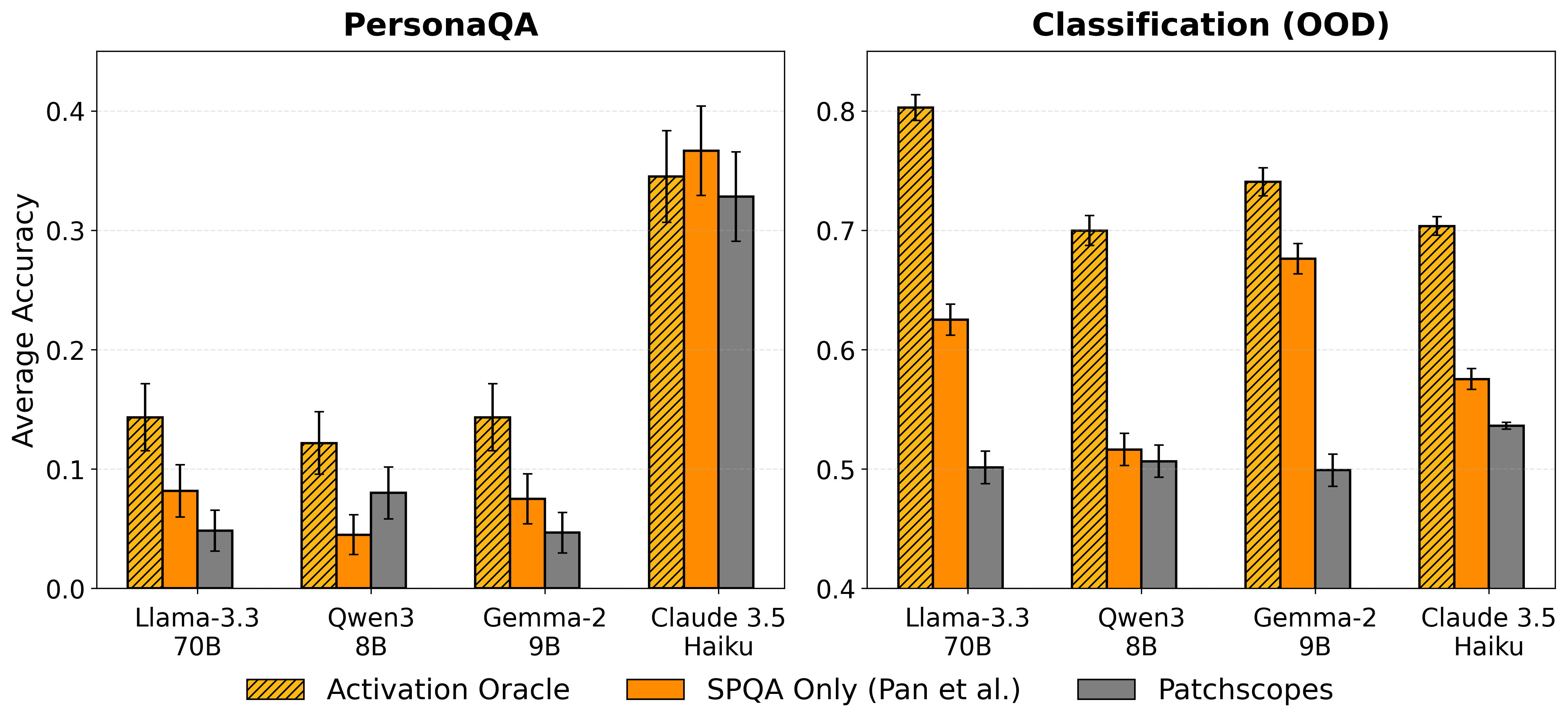
Out-of-Distribution Generalization: PersonaQA and Classification
The generalization capabilities are stressed in ablations on two challenging OOD settings:
Data Scaling, Diversity, and Layer Selection
The investigation establishes:
- Monotonic improvements in AO performance as more diverse and numerous datasets are added.
- Diversity is critical: For a fixed number of training examples, mixtures with added self-supervised context prediction outperform same-sized, less diverse baselines.
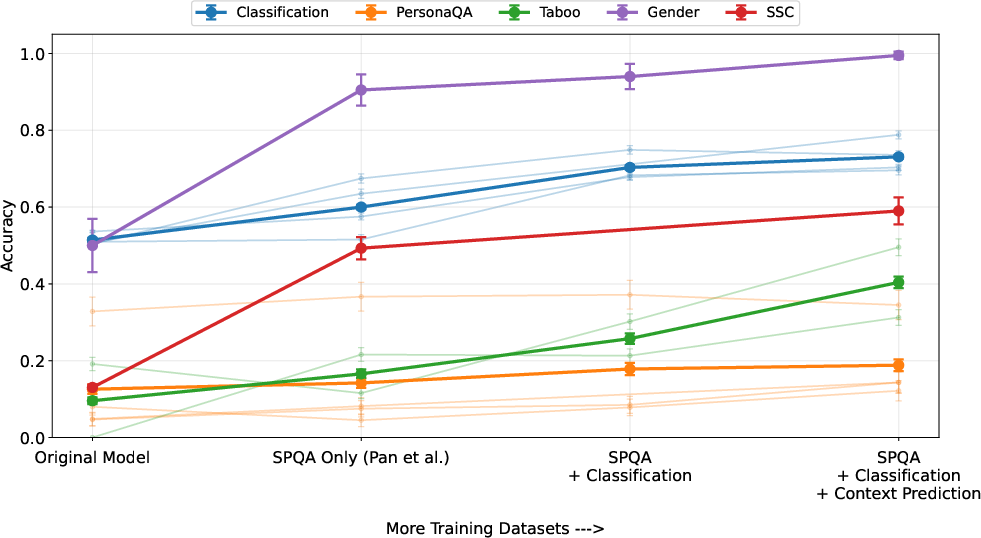
Figure 5: Each added dataset in the training mixture yields further measurable gains in out-of-distribution AO performance.

Figure 6: Both data diversity and data quantity yield additive benefits on all OOD evaluation metrics, as evidenced by controlled ablation on Qwen3-8B.
Layer selection experiments highlight that mid-layer (typically ≈50% depth) activations optimize OOD decoding for auditing, as opposed to layer 0/1, which can be suboptimal (by 1–11% in Llama-3.3-70B).
Theoretical and Practical Implications
This work empirically undermines the claim that complex, mechanistic model-specific pipelines are required for practical auditing of LLMs’ latent knowledge. The evidence provided demonstrates that a general-purpose AO, trained on sufficiently broad and scalable mixtures (incorporating even simple synthetic tasks), can outperform task-specific interpretability methods on (1) secret extraction, (2) misalignment detection, and (3) fine-tuned knowledge recovery.
However, AOs fundamentally trade mechanistic interpretability for “black-box” QA transparency. They offer limited insights into underlying representations or causal circuitry, but provide a practical interface for surface-level model property extraction. The AO interface is simple, scalable, and potentially more accessible to non-expert practitioners, though lacks error calibration and does not expose internal reasoning chains. Reliability of the AO is tied to the quality and coverage of training data—the most salient limitation identified.
Limitations and Future Directions
- Lack of mechanistic access: While highly effective empirically, the AO interface eschews direct hypothesis-driven causal investigation.
- Data quality and coverage bottlenecks: Further gains likely hinge on large-scale, intelligently targeted self-supervised dataset synthesis, as well as robust multi-turn and RL-finetuned QA corpora.
- Modeling transfer and generalization: Evidence is weaker for cross-architecture and strongly OOD activation transfer; benchmark expansions are needed to clarify boundaries.
- Realism and multi-factor interventions: Real post-training/fine-tuning pipelines are richer than the narrow single-secret or single-domain axes currently evaluated.
- Calibration and uncertainty: Future work should focus on AO uncertainty estimation, response abstention, and principled error signal handling.
Conclusion
Activation Oracles represent a significant advancement in practical, scalable auditing of LLM inner states. Their strong generalization properties, simplicity of application, and data-centric scaling properties substantiate their position as a compelling alternative to specialized interpretability pipelines for auditing tasks. Nonetheless, the approach’s “verbalization-only” perspective is inherently limited for mechanistic-model investigations, and further research is needed to integrate transparent reasoning with general-purpose latent decoding. The results underscore that large, diverse mixtures of simple activation-verbalization tasks, even in the absence of task-specific adaptation, produce robust and flexible LLM auditing tools.