- The paper introduces Skyra, a multimodal framework that leverages grounded artifact reasoning to detect synthetic videos with over 90% accuracy and enhanced F1 scores.
- It utilizes a two-stage training pipeline combining supervised fine-tuning on fine-grained annotated data and reinforcement learning to boost spatio-temporal explanation.
- The approach outperforms previous detectors by reducing false positives and achieving robust detection under diverse degradation scenarios.
Artifact-Grounded Detection of Synthetic Videos: A Technical Assessment of "Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning" (2512.15693)
Introduction
The proliferation of photorealistic AI-generated videos, largely driven by advances in diffusion-based and multimodal generative models, has necessitated robust, interpretable detection methods that not only classify but explain their decisions. "Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning" introduces Skyra, an artifact-centric Multimodal LLM (MLLM) capable of detecting AI-generated videos through human-perceivable visual cues, delivering explicit spatio-temporal rationales. This work advances prior efforts by constructing fine-grained datasets and integrating reinforcement learning for improved generalization and explanation capability.
Dataset Construction: ViF-CoT-4K and ViF-Bench
Skyra's efficacy hinges on high-quality, human-annotated data. ViF-CoT-4K stands as the first large-scale dataset for AI-generated video artifact annotation, encompassing a hierarchical taxonomy with two meta-categories: low-level perceptual artifacts and violation-of-laws artifacts. Annotation involves fine-grained labeling, textual explanations, and precise spatio-temporal localizations.
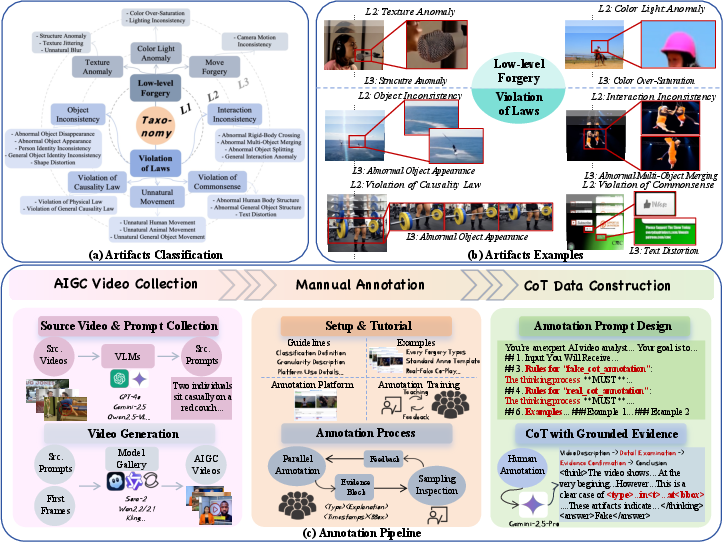
Figure 1: The hierarchical taxonomy in ViF-CoT-4K, visual examples for each artifact, and the manual annotation pipeline.
To mitigate shortcut learning and domain bias prevalent in previous benchmarks, ViF-Bench aligns authentic and synthetic samples on semantics and format, comprising 3K samples produced by state-of-the-art generators. The benchmark supports robust and fair evaluation under diverse degradation scenarios.
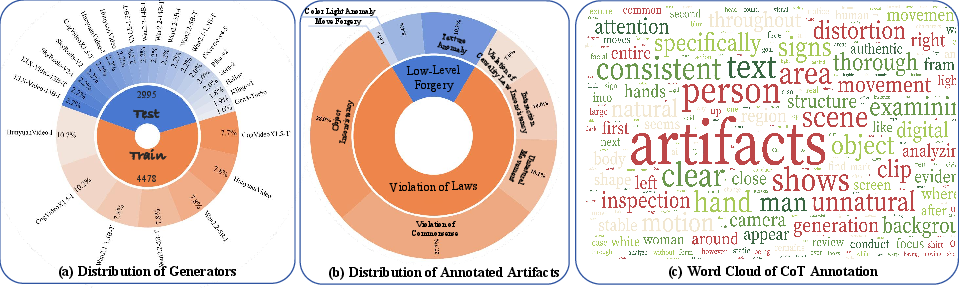
Figure 2: Generator/sample distributions, artifact type breakdown, and word cloud of CoT annotations in ViF-CoT-4K.
Skyra Framework: Training Paradigm and Artifact Reasoning
The Skyra framework is instantiated on Qwen2.5-VL-7B, leveraging a two-stage training protocol. Initially, supervised fine-tuning (SFT) on ViF-CoT-4K imparts baseline artifact identification and chain-of-thought (CoT) capabilities. The cold-start SFT utilizes templated responses that demand localized evidence, distinguishing between fake and real context with tightly-bound spatial and temporal tags.
Subsequently, an RL stage using Group Relative Policy Optimization (GRPO) is introduced. The reward function asymmetrically penalizes false positives (over-classification as fake) more severely, reflecting the task intrinsically: the presence of a single artifact suffices for a "fake" label, but "real" certification demands global absence of inconsistencies. RL additionally rewards compliance with output formats via block extraction, facilitating multi-cue reasoning trajectories.
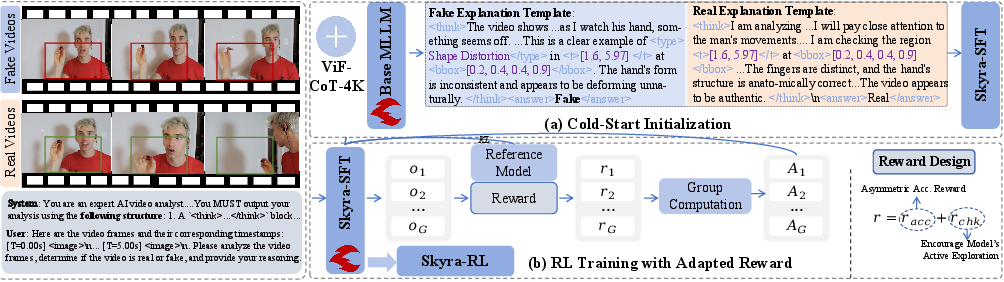
Figure 3: Overview of the two-stage training pipeline—cold-start SFT with balanced real/fake templates, followed by RL to drive self-coherent artifact mining.
Artifact Perception and Explanation
Skyra outperforms both binary and prior MLLM-based detectors, yielding J > 90% accuracy and F1 score across multiple generators, an absolute improvement of +26.73% accuracy and +17.27% F1 over the best binary classifier baseline. RL increases recall (especially for hard I2V samples) by +3.74% compared to SFT alone. Robustness is shown under compression, transformation, and photometric degradation scenarios.
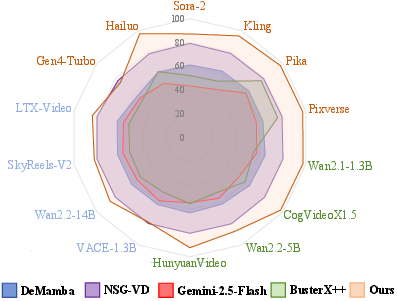
Figure 4: Relative performance on ViF-Bench, demonstrating Skyra's margin over binary and previous MLLM-based detectors in accuracy, recall, and F1.
Skyra surpasses current off-the-shelf MLLMs, which tend to conflate compression/motion blur artifacts with synthetic evidence, and prior MLLM-based systems (e.g., BusterX++), which overemphasize superficial cues rather than deep spatio-temporal inconsistencies. Skyra's chain-of-thought output crucially grounds all flagged artifacts within human-interpretable and localized contexts.

Figure 5: Skyra's artifact-based reasoning yields superior detection and explanation over baseline MLLMs and MLLM-based detectors via grounded, fine-grained artifact perception.
Ablation and Case Study Insights
Mechanistic ablations validate all major design choices: omission of chain-of-thought drastically degrades performance (> -36% acc), and removing cold-start initialization renders reward signals too sparse for RL progression. Symmetric rewards notably bias RL toward "fake," confirming asymmetric necessity for confidence calibration.
Case studies illustrate Skyra's stepwise reasoning, uncovering subtle violations of physical law, object identity, and anatomical structure, sometimes exceeding human annotation sensitivity. Real video inspection likewise avoids false positives from benign degradations by explicitly seeking absence of artifacts.

Figure 6: Representative chain-of-thought inference from Skyra, evidencing fine-grained artifact discovery and symmetric reasoning in real/fake comparisons.
Implications, Limitations, and Future Directions
Skyra’s artifact-centric approach substantially advances explainable AIGC video detection, both in detection efficacy and interpretability. Practical deployment will benefit moderators, fact-checkers, and multimedia forensics by promoting evidence-based and auditable summaries. Theoretically, Skyra demonstrates RL’s utility in MLLMs for generalizable spatio-temporal reasoning and grounded perceptual mining.
Limitations persist with respect to coverage—current benchmarks are narrowly focused on recent generators and photorealistic domains, not ultra-long or stylized content. The model’s natural-language explanations remain susceptible to overconfidence and hallucination. Future work should address dynamic benchmarking against emerging generative paradigms, integrate uncertainty calibration, and expand multilevel artifact taxonomies. Additionally, integration with provenance and watermarking techniques may further buttress multimodal AI safety.
Conclusion
"Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning" presents a robust, interpretable MLLM pipeline for synthetic video detection, grounded in fine-grained human and algorithmic artifact annotation, with reinforcement-boosted perceptions and explanations. Skyra establishes both strong baseline and methodological directions for future AIGC forensic research and applications.