A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Abstract: As LLMs are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a practical problem: today, big AI models that understand code (called LLMs, or LLMs) are used to find security bugs in software. But there’s a trick programmers can use called “code obfuscation,” which changes how code looks without changing what it does. The paper studies, in a careful and systematic way, how different kinds of obfuscation can fool or confuse LLMs that try to detect vulnerabilities (serious mistakes that hackers can exploit).
Key Objectives
The study asks five simple questions:
- How do different obfuscation tricks (changing names, formatting, data, or logic) affect an AI’s ability to spot vulnerabilities?
- Do different AI model families and sizes handle obfuscation better or worse?
- Can AI still identify not just that a bug exists, but also what type it is and where it is in the code after obfuscation?
- Do results change depending on the programming language, kind of bug, and how complex the code is?
- How do popular coding assistants (like GitHub Copilot and Codex) perform when facing obfuscated code?
How the Researchers Studied It
To make the study fair and broad, the authors built a unified test setup:
- They organized obfuscation into three main groups:
- Layout changes: surface-level changes to how code looks (like renaming variables, removing comments, or reformatting).
- Data flow changes: how values are stored, encoded, or accessed (like turning “42” into a math expression or splitting strings into pieces).
- Control flow changes: how the code’s steps are ordered and managed (like adding fake conditions, flattening function logic, or “virtualizing” the program into a custom mini-interpreter).
- They implemented 19 concrete obfuscation techniques across four programming languages: Solidity (smart contracts), C, C++, and Python.
- They tested 15 different LLMs (from DeepSeek, OpenAI, Qwen, and LLaMA), ranging from smaller models to very large ones, and also tested two coding agents: GitHub Copilot and Codex.
- They didn’t just ask “does the AI find a bug?”—they used a four-level scoring system to judge whether the AI correctly detects the bug, names its type, and points to the right location in the code.
- They used consistent settings and limited overly long files to keep the tests fair. They also used a single model (GPT-4o) to apply obfuscation, ensuring the transformations were done evenly.
Plain-language analogies for key terms:
- Code obfuscation: like writing a message in a strange font, with shuffled sentences and nicknames, so it’s harder to read, but the meaning stays the same.
- Layout changes: like removing paragraph breaks, erasing helpful notes, or changing names from “isAdmin” to “x1”.
- Data flow changes: like storing “hello” in pieces (“h” + “ell” + “o”) or turning “10” into “(3 + 7)”.
- Control flow changes: like adding if-statements that always lead nowhere, flattening steps into one big loop, or turning code into a custom “secret language” that another piece of code interprets.
- Virtualization: turning normal code into “bytecode-like” instructions and a mini-interpreter—think of writing your own tiny computer inside the program.
- Inline assembly / mixed-language: mixing another programming language inside the file (like speaking English but embedding a sentence in another language mid-paragraph).
Main Findings
Here are the most important takeaways:
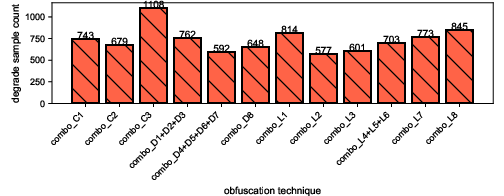
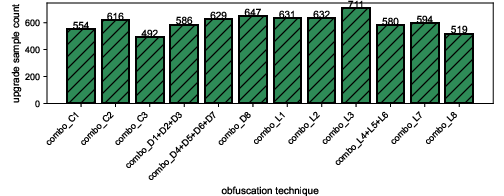
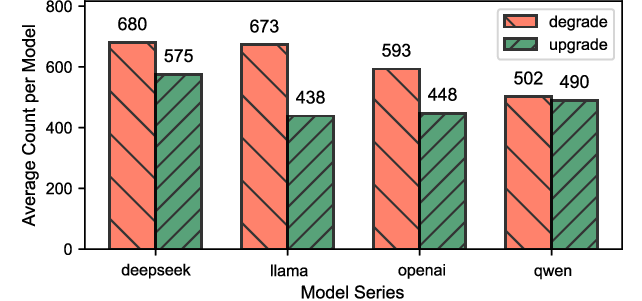
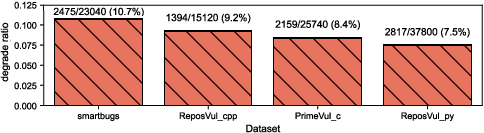
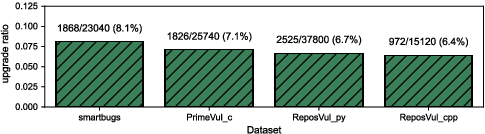
- Obfuscation can hurt or help. While many transformations make AI detectors perform worse (a “downgrade”), some surprisingly make them better (an “upgrade”). For example, removing misleading surface clues can help the AI focus on the actual logic.
- The most damaging tricks: control-flow virtualization and mixing languages (like inline assembly or calling out to a different language) tend to confuse models the most and reduce detection accuracy.
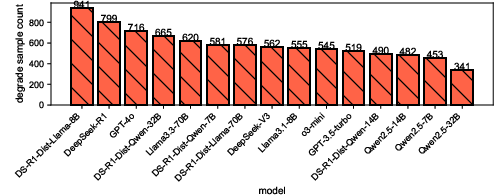
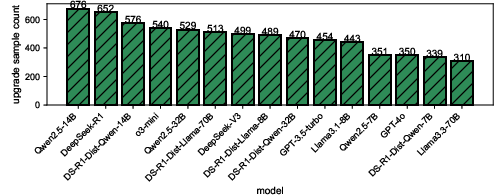
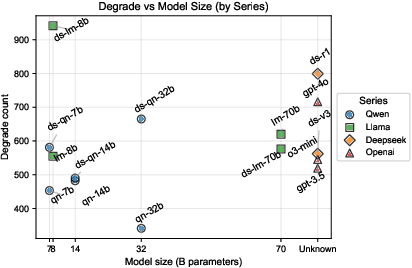
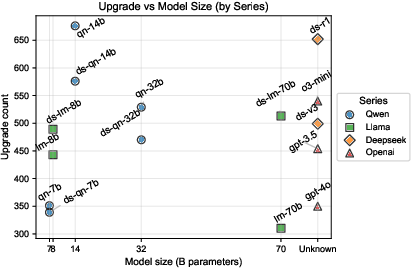
- Model size matters—but only up to a point. Models with fewer than about 8 billion parameters were notably unstable under obfuscation. Models larger than that were more robust, but just making them bigger beyond 8B gave smaller improvements.
- “Reasoning” models are a double-edged sword. Models that are tuned for more step-by-step reasoning do great on clean code, but they are often more sensitive to obfuscation. In other words, they can think better—but their thinking can be thrown off by tricky transformations.
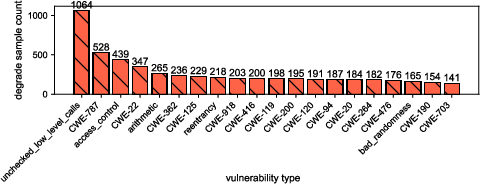
- The kind of bug matters. Some vulnerabilities—like pointer safety issues (common in C/C++), reentrancy (important in smart contracts), and access control mistakes—were more affected by obfuscation than others.
- Coding agents (like Copilot and Codex) usually perform better than regular LLMs—but they’re not immune. They still suffer downgrades (and sometimes upgrades) when facing obfuscation, especially with inline assembly and virtualization.
- Swapping in a new base model inside an agent (“hot-plugging”) doesn’t always help. It can accidentally reduce the agent’s ability to transfer its detection knowledge, leading to partial understanding (observed with DeepSeek-V3 used within GitHub Copilot).
Why This Matters
- For attackers: You don’t need to change what the program does to slip past AI detectors—just change how it looks. Smart, semantics-preserving obfuscation can exploit the gap between statistical pattern-matching and deeper logical understanding.
- For defenders: Simply using bigger or “more reasoning” models isn’t enough. To build robust detectors, you need:
- Training on more diverse, obfuscated code so models learn to ignore surface tricks.
- Combining AI with traditional program analysis (symbolic/static/dynamic methods) to track real logic, not just patterns.
- Checking consistency across different model families to avoid blind spots.
- Careful integration of models into coding agents to preserve precision and avoid “partial comprehension” when swapping models.
In short, this paper maps out how obfuscation reshapes the battlefield for AI-based vulnerability detection. By understanding which tricks hurt most and which conditions make models fragile, researchers and engineers can design stronger, more reliable tools to catch security flaws in real-world code.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following list identifies concrete gaps and uncertainties left unexplored by the paper, framed to guide actionable future research:
- Semantic equivalence assurance: The study relies on LLM-driven obfuscation (gpt-4o) but does not rigorously verify that obfuscated programs preserve functionality and vulnerability exploitability across languages (e.g., compile/run tests, differential testing, property-based tests, EVM harnesses for Solidity, unit/integration tests for C/C++/Python).
- Evaluation of obfuscation “potency/resilience/cost”: Although taxonomy fields mention these attributes, the experiments do not quantify them (e.g., runtime overhead, binary size, maintainability, reverse-engineering effort), nor correlate them with detection degradation.
- Attacker adaptivity: Obfuscations are applied as predefined combos rather than optimized adversarially. There is no evaluation of adaptive, model-aware obfuscation (e.g., search/gradient-free optimization, RL, multi-turn probing) that minimizes perturbation while maximally degrading detection.
- Localized vs global obfuscation: The study does not compare obfuscating only vulnerability-critical regions versus whole-file transformations, leaving open how localization affects LLM robustness and detection granularity.
- Prompt sensitivity and instruction design: Detection is conducted under fixed prompts and temperature. There is no systematic analysis of prompt styles, chain-of-thought constraints, tool-use prompts, or few-shot exemplars and their interaction with obfuscation.
- Ground truth for fine-grained detection: The paper references a four-level scoring scheme but does not detail annotation protocols, inter-annotator agreement, or objective criteria for “type” and “location” correctness, limiting reproducibility of fine-grained evaluation.
- False positives and calibration: The study emphasizes detection success rates but does not report false-positive rates, calibration, or confidence estimation under obfuscation—critical for deployment.
- Cross-version stability of closed models: Results for proprietary models/agents (e.g., Copilot, OpenAI models) may drift with backend updates. No longitudinal or version-controlled evaluation is provided to assess temporal robustness.
- Model interpretability: The observed sensitivity of reasoning models to obfuscation is not explained mechanistically. There is no analysis of attention patterns, token salience, or structural representations to pinpoint why control/data-flow changes cause failures.
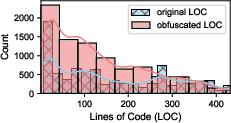
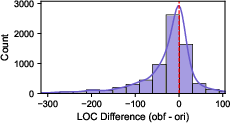
- Context and scale limitations: Files are capped at ≤500 LOC, preventing evaluation on multi-file, interprocedural, or project-level vulnerabilities where obfuscation interacts with broader context (imports, build systems, macros, reflection).
- Language and ecosystem coverage: The evaluation omits major ecosystems (Java, JavaScript/TypeScript, Go, Rust, C#, Kotlin, Swift, PHP) and does not include IR/bytecode or binary-level obfuscation, limiting generalizability.
- Concurrency and environment-specific vulnerabilities: Vulnerabilities tied to concurrency (race conditions), TOCTOU, sandbox escapes, dynamic loading, and build-time macros are underrepresented; impact of obfuscation on these classes remains unknown.
- Mixed-language obfuscation realism: Inline assembly and cross-language calls are treated uniformly across languages, but practicality and semantics differ widely (e.g., Python’s lack of inline assembly); portability and correctness of these transformations are not validated per language.
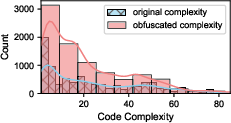
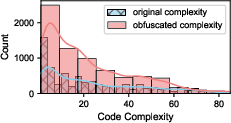
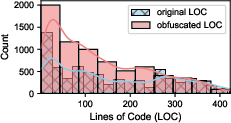
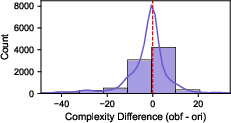
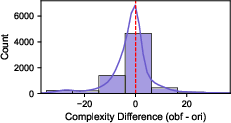
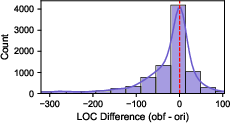
- Dataset balance and representativeness: Capping per-CWE samples to five may distort real-world distributions. The effect of imbalance, skewed CWE prevalence, and code complexity metrics (nesting depth, cyclomatic complexity) is not quantified.
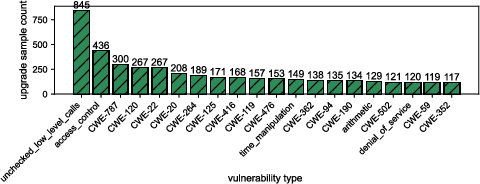
- Upgrade effects (obfuscation improvements): The paper notes cases where obfuscation improves detection by removing misleading cues, but provides no systematic characterization of when and why this occurs, nor guidance to harness it defensively.
- Hybrid defenses: There is no empirical evaluation of integrating LLMs with static/dynamic analysis, type systems, fuzzing, or symbolic execution as defenses against obfuscation-induced failures.
- Robust training strategies: The study does not test adversarial training, curriculum learning with progressively obfuscated code, or data augmentation strategies to improve cross-obfuscation generalization.
- Obfuscation detection as a precursor: The paper does not explore training detectors to flag likely obfuscation (e.g., control-flow flattening, virtualization) and route such cases to specialized analysis pipelines.
- Agent internals and hot-plugging: The “partial comprehension” issue in agent hot-plugging is reported but not analyzed. There is no examination of agent prompt scaffolding, toolchains (retrieval, AST parsers), or compatibility contracts that preserve detection precision across model swaps.
- Retrieval augmentation and external context: Although agents may use retrieval, the study does not measure how external context (e.g., repository snippets, CWE docs) mitigates or exacerbates obfuscation effects.
- Defense cost-benefit under obfuscation: The team does not assess the compute/time trade-offs of defenses (e.g., enabling tool-use, longer contexts, multi-pass analyses) against the obfuscation strategies observed to be most harmful (e.g., virtualization).
- Combination and intensity of transformations: Subcategory-level combos are used, but there is no parameter sweep over obfuscation intensity, multi-technique chaining, or compounding effects (e.g., virtualization plus data encoding plus misleading comments).
- Cross-family ensembling and consensus: There is no study of ensemble strategies (e.g., majority vote across families, differential agreement) to detect obfuscation-induced failures or improve robustness.
- Standardized benchmarks and metrics: The community lacks a stable, multi-language benchmark with validated obfuscations, executable test harnesses, and standardized metrics (precision/recall at type/location, calibration), which this work does not fully establish.
- Real-world pipeline evaluation: The study does not evaluate integrated CI/CD or IDE pipelines where formatting, linters, build steps, and test suites may interact with obfuscation and LLM detection.
- Open-source reproducibility: Heavy reliance on closed models/agents constrains reproducibility. An open-weight baseline (with fixed versions, prompts, and toolchains) is needed to make the results durable and comparable.
- Ethical and misuse considerations: There is no discussion of disclosure practices, responsible release of obfuscation tools/prompts, or safeguards to prevent misuse of upgrade/downgrade insights for evasion.
Practical Applications
Practical Applications Derived from “A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection”
Below is an overview of actionable, real-world applications grounded in the paper’s taxonomy, unified evaluation framework, datasets, and empirical findings. Items are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further R&D, scaling, or standardization). Each item notes relevant sectors, potential tools/workflows/products, and assumptions or dependencies that may affect feasibility.
Immediate Applications
- Obfuscation Stress Testing in CI/CD for LLM-based Security Scans
- Sectors: Software, Cybersecurity, Finance (smart contracts), Healthcare, Energy/ICS
- What to do: Add an “Obfuscation Stress Test” stage to CI/CD that automatically generates semantics-preserving variants (layout, data-flow, control-flow) before running LLM scanners and coding agents.
- Tools/workflows/products:
- Use the authors’ taxonomy and open-source repo (linked in the paper) to script L1–L8, D1–D8, C1–C3 transformations.
- Build a CI plugin: “ObfusStress-CI” that outputs per-class robustness scores and regression alerts.
- Assumptions/dependencies: Access to target LLMs/agents; compute budget for multi-variant scanning; test suites verifying semantic equivalence; policy clearance to transform code in pipelines.
- Model and Agent Selection Rules of Thumb for Robustness
- Sectors: Software, Security Vendors, Regulated Software (health, finance), Critical Infrastructure
- What to do: Prefer models ≥8B parameters for improved robustness; require cross-family check (e.g., OpenAI + Qwen or LLaMA) when auditing safety-critical code; document reasoning models’ higher sensitivity to obfuscation and configure fallbacks.
- Tools/workflows/products:
- “ConsensusScan” pipeline to run two model families and compare outputs.
- “Reasoning Sensitivity Flag” that automatically switches to non-reasoning variants or hybrid analyzers under heavy obfuscation.
- Assumptions/dependencies: Multi-model access; budget considerations; compatibility with existing security tooling.
- Coding Agent Hardening and Calibration
- Sectors: Developer Tools, IDEs, Enterprise DevSecOps
- What to do: Calibrate GitHub Copilot/Codex or similar agents with a small robustness suite per repository; detect inline assembly/virtualization and route to human/manual analyzers.
- Tools/workflows/products:
- “Agent Robustness Dashboard” that reports downgrade/upgrade patterns per obfuscation class.
- “Hot-Plugging Calibration Harness” that runs a controlled stress suite when swapping underlying models to prevent precision loss.
- Assumptions/dependencies: Agent API hooks to run custom pre/post-processing; ability to pin or version the underlying model; developer buy-in.
- Multi-Model Cross-Verification to Reduce False Negatives
- Sectors: Software, Cybersecurity Consulting, Managed Security Service Providers (MSSPs)
- What to do: Run at least two LLMs from different families and a traditional static analyzer, then intersect or union their findings depending on risk appetite.
- Tools/workflows/products:
- “TriadScanner” orchestration: LLM-A + LLM-B + static analyzer, with explainable diffing of vulnerability type and location.
- Assumptions/dependencies: Orchestration and UI to manage disagreements; integration into existing triage workflows.
- Code Normalization or “Anti-Noise” Pre-Processing Before LLM Review
- Sectors: IDEs, Code Review Platforms, Enterprise DevSecOps
- What to do: Apply formatting and de-obfuscation-like normalization (e.g., canonicalizing loops/conditionals, removing misleading comments) to mitigate layout obfuscation impacts; optionally generate both “raw” and “normalized” views and compare LLM decisions.
- Tools/workflows/products:
- “Normalizer” pre-processor plug-in for IDE/CI that canonicalizes AST/IR before sending code to LLM.
- Assumptions/dependencies: High coverage normalization without semantic drift; language support beyond C/C++/Python/Solidity as needed.
- Adversarial Red Teaming-as-a-Service for Security Tools
- Sectors: Cybersecurity Vendors, Consulting, SaaS AppSec Platforms
- What to do: Offer an “Obfuscation Red Team” service using the paper’s taxonomy to evaluate and harden clients’ LLM-based vulnerability detectors (including agents).
- Tools/workflows/products:
- “ObfusRT” service: periodic adversarial evaluations, reports by CWE and obfuscation class, remediation playbooks.
- Assumptions/dependencies: Responsible use guidelines to avoid facilitating misuse; customer consent and data handling policies.
- Smart Contract Auditing with Obfuscation-Aware Triage
- Sectors: Web3/Finance (Solidity)
- What to do: Automatically detect inline assembly and virtualization; flag reentrancy and access-control cases for human-led deep review; require cross-model verification on high-value contracts.
- Tools/workflows/products:
- “Solidity-ObfusGate”: gate that escalates to manual review upon L7/L8/C3 signatures; preconfigured prompts for reentrancy/access-control.
- Assumptions/dependencies: Gas-cost awareness when transforming code; chain/toolchain compatibility; auditor expertise.
- Dataset-Driven Education and Training
- Sectors: Academia, Corporate Training, Bootcamps
- What to do: Use the multi-language datasets and scoring scheme to teach engineers about obfuscation impacts on LLMs, focusing on vulnerability type and location identification.
- Tools/workflows/products:
- “ObfusEdu Kits” with labs showing downgrade/upgrade phenomena and model-size effects; rubrics using the paper’s four-level scoring.
- Assumptions/dependencies: Instructor access to models and compute; licensing of datasets; up-to-date agent versions.
- Procurement and RFP Checklists for LLM Code Auditors
- Sectors: Policy/Compliance, Enterprise Procurement, Regulated Industries
- What to do: Add requirements that vendors demonstrate robustness across layout/data/control-flow obfuscations; mandate cross-family testing and minimum success rates on type and location detection.
- Tools/workflows/products:
- “Obfuscation Robustness Addendum” template for RFPs and vendor evaluations.
- Assumptions/dependencies: Organizational alignment; availability of third-party validation labs.
- Pre-commit and PR Hooks Detecting Obfuscation Risk
- Sectors: Open-Source Maintainers, Enterprise Repositories
- What to do: Detect suspicious use of inline assembly, virtualization, or excessive junk code in PRs; route to enhanced scans or manual review.
- Tools/workflows/products:
- “ObfusGuard Hook” that integrates with GitHub/GitLab; configurable thresholds per repo risk profile.
- Assumptions/dependencies: Avoiding false positives; contributor education; project-specific coding standards.
Long-Term Applications
- Obfuscation-Invariant Intermediate Representations (IR) and Canonicalization
- Sectors: Software, Cybersecurity Tools, Compilers
- What to build: Canonical AST/IR/SSA pipelines that collapse many layout and data-flow variants to a common representation, improving LLM robustness.
- Tools/workflows/products:
- “IR Canonicalizer” that plugs into LLM pre-processing; supports multi-language frontends.
- Assumptions/dependencies: Research on semantics-preserving canonicalization; language coverage; bridging to LLM tokenization.
- Hybrid Detectors Combining Symbolic/Static Analysis with LLMs
- Sectors: AppSec Platforms, Enterprise DevSecOps, Critical Infrastructure
- What to build: Systems that reconcile symbolic execution/CFG analysis with LLM reasoning to withstand control-flow and virtualization obfuscations.
- Tools/workflows/products:
- “Sym-LLM Fusion” with path constraints from analyzers guiding the model; type/location scoring alignment with the paper’s rubric.
- Assumptions/dependencies: Engineering complexity; performance overhead; explainability and verification.
- Robust Training Regimens and Curriculum Learning
- Sectors: Model Providers, Research Labs
- What to build: Adversarial/obfuscation-aware training using the paper’s taxonomy to improve generalization; curriculum spanning layout → data → control-flow.
- Tools/workflows/products:
- “ObfusAug” data pipelines; “CurriculumTrainer” schedules with obfuscation mixes.
- Assumptions/dependencies: Access to training data and compute; licensing; careful validation to avoid overfitting to specific transforms.
- Agent Hot-Plugging Standards for Precision Preservation
- Sectors: IDEs, Agent Platforms, Enterprise Toolchains
- What to build: Standardized APIs and calibration protocols to swap underlying models without losing vulnerability detection precision.
- Tools/workflows/products:
- “Agent ABI” specification; “Calibration Suite” with pass/fail thresholds per obfuscation class.
- Assumptions/dependencies: Vendor cooperation; shared test corpora; governance over versioning.
- Certification and Regulatory Benchmarks for LLM Code Auditors
- Sectors: Policy/Standards Bodies, Regulated Industries
- What to build: Independent certification regimes that test across the paper’s obfuscation classes, languages, and vulnerability types (including type and location).
- Tools/workflows/products:
- “Obfuscation Stress Benchmark” and “Robustness Scorecard” for procurement and compliance.
- Assumptions/dependencies: Consensus on metrics; accredited test labs; public datasets and reproducible protocols.
- Automated Deobfuscation and Virtualization Decompilation Assistants
- Sectors: Incident Response, Malware Analysis, Security Research
- What to build: LLM-assisted deobfuscation tools that recover higher-level semantics or neutralize virtualization layers before scanning.
- Tools/workflows/products:
- “DeObfusAssist” that outputs normalized code and a confidence map; “Virtualization Decompiler” tailored to C3-like transforms.
- Assumptions/dependencies: Safety controls to prevent misuse; ground-truth validation; coverage across obfuscators.
- Sector-Specific Robust Scanners (e.g., Solidity Reentrancy, ICS Pointer Safety)
- Sectors: Web3/Finance, Energy/ICS, Healthcare Devices
- What to build: Specialized detectors trained and evaluated under obfuscations that strongly impact those domains (reentrancy, access control, pointer safety).
- Tools/workflows/products:
- “Reentrancy-GuardScan,” “ICS-PointerShield,” with domain-specific escalation logic for inline assembly/virtualization.
- Assumptions/dependencies: Access to sector data; safety certification; integration with existing assurance processes.
- Repository and Supply Chain Risk Scoring with Obfuscation Sensitivity
- Sectors: Software Supply Chain, Platforms, App Stores
- What to build: Risk scores that incorporate obfuscation density and the likelihood of LLM under-detection; trigger deeper inspections for high-risk packages.
- Tools/workflows/products:
- “ObfusRisk Score” integrated into dependency scanners and SBOM workflows.
- Assumptions/dependencies: Scalable static feature extraction; thresholds per ecosystem; false positive management.
- Privacy-Preserving Multi-Model Scanning
- Sectors: Enterprise, Government, Defense
- What to build: Encrypted or on-prem orchestration for cross-family consensus scanning without exposing code to external services.
- Tools/workflows/products:
- “PrivateConsensus” with local/open models ≥8B and on-prem static analyzers.
- Assumptions/dependencies: On-prem hardware; secure enclaves; governance for model updates.
- Obfuscation-Resilient Automated Repair
- Sectors: Software Maintenance, DevOps, SRE
- What to build: Program repair pipelines that remain effective under obfuscation, with formal checks that the fix preserves semantics and risk profile.
- Tools/workflows/products:
- “RobustFix” integrating IR canonicalization, test amplification, and repair validation.
- Assumptions/dependencies: Adequate tests/specs; formal verification for high-assurance contexts.
Notes on Key Dependencies Across Applications
- Semantic preservation checks are critical when applying transformations; include tests, fuzzing, or formal specs to ensure behavior equivalence.
- Compute and cost constraints grow with multi-variant and multi-model strategies; prioritize high-risk code paths and critical deployments.
- Language coverage currently demonstrated for Solidity, C, C++, Python; extending to Java/Go/Rust/JS will require engineering.
- Reasoning LLMs can be more sensitive to obfuscation; deploy fallbacks or hybrid analyzers for obfuscation-heavy code.
- Virtualization (C3) and mixed-language (L7/L8) transformations are especially degrading; workflows should detect these early and escalate.
- The “upgrade” effect (some obfuscations improving detection) motivates adding normalization and counter-obfuscation steps before scanning.
Glossary
- Access control: Mechanisms that govern which entities can perform specific actions or access resources within a system. "with vulnerability types involving pointer safety, reentrancy, and access control"
- Adversarial perturbations: Intentional, small changes to inputs designed to cause errors in model predictions without altering true semantics. "their reliability and robustness against adversarial perturbations remain open concerns."
- Attention mechanisms: Model components that weight tokens or code elements to focus on relevant parts during prediction. "arithmetic substitution or boolean extension creates rarely seen token sequences, confusing attention mechanisms;"
- Auxiliary toolchains: External tools and systems integrated with models or agents to enhance capabilities like retrieval or analysis. "and are often supported by auxiliary toolchains that enhance their reasoning over code."
- Coding agents: Integrated systems (often IDE plugins) that use LLMs plus tools to analyze and generate code autonomously. "coding agents claim to possess advanced code review capabilities that can identify critical vulnerabilities before deployment"
- Code obfuscation: Transformations that make code harder to understand or analyze while preserving functionality. "Code obfuscation refers to the process of transforming a program into a form that is more complex to understand or analyze while preserving its original functionality"
- Control-flow flattening: Restructuring a program’s execution to remove natural branching hierarchy, often via dispatcher loops. "Methods include inserting opaque predicates, flattening control-flow graphs, and virtualizing code execution through custom interpreters."
- Control-flow graph (CFG): A representation of program execution paths as nodes (basic blocks) and edges (control transfers). "flattening control-flow graphs"
- Control-flow virtualization: Replacing normal execution with a custom interpreter or bytecode to obscure logic. "control-flow virtualization and mixed-programming-language transformations have the strongest degrading effect."
- CWE classification: Standardized taxonomy of software weaknesses (Common Weakness Enumeration) used to categorize vulnerabilities. "such as whether the model can correctly identify the type of vulnerability (e.g., CWE classification) or its location in the code."
- Data-flow obfuscation: Techniques that alter how data is encoded, structured, or accessed without changing overall behavior. "Data Flow Obfuscation. Data flow obfuscation alters how information is encoded, structured, or accessed, while leaving the overall control structure intact."
- Dead code: Code inserted that never executes, used to mislead analysis without affecting functionality. "Insert dead code (randomly)"
- False negatives: Cases where a detector fails to identify an existing vulnerability. "leading to higher false negatives in vulnerability detection."
- Fine-grained four-level scoring scheme: An evaluation rubric that measures detection, type identification, and localization quality beyond binary outcomes. "Our evaluation employs a fine-grained four-level scoring scheme to measure not only whether vulnerabilities are detected but also whether their type and location are correctly identified."
- Generalization stability: A model’s consistency in performance across variations like obfuscations or datasets. "revealing a trade-off between reasoning power and generalization stability."
- Hot-plugging: Integrating a new model into an existing agent framework without extensive retraining, which can introduce precision loss. "hot-plugging a new model into the agent framework can reduce its effectiveness in transferring vulnerability-detection knowledge"
- Inline assembly: Embedding low-level assembly instructions within high-level language code. "particularly when facing inline assembly and virtualization techniques."
- Mixed-programming-language transformations: Obfuscation that combines multiple languages within a single program to confuse detectors. "control-flow virtualization and mixed-programming-language transformations have the strongest degrading effect."
- Opaque branches: Conditionals whose truth values are hard to determine statically, inserted to mislead analysis. "Junk code and opaque branches dilute meaningful signal"
- Opaque predicates: Conditions crafted to appear non-trivial while having a predetermined outcome, used to obfuscate control flow. "Methods include inserting opaque predicates, flattening control-flow graphs, and virtualizing code execution through custom interpreters."
- Parameter scales: The size of a model measured by the number of parameters, often correlating with capacity. "spanning parameter scales from 7B to 671B."
- Prompt engineering: Crafting inputs and instructions to elicit more accurate or useful outputs from LLMs. "combining LLMs with prompt engineering, few-shot learning, and program analysis."
- Reentrancy: A vulnerability where a function can be re-invoked before its previous execution completes, often exploited in smart contracts. "with vulnerability types involving pointer safety, reentrancy, and access control"
- Retrieval augmentation: Enhancing LLMs by fetching external knowledge or code snippets during inference. "CA = Coding Agent, FT = Fine-Tuning, RA = Retrieval Augmentation, PE = Prompt Engineering"
- Reverse engineering: Analyzing software to understand its design or recover source logic, often resisted by obfuscation. "Resilience: resistance against reverse engineering."
- Robustness boundary: A threshold (e.g., by model size) beyond which models exhibit notably improved stability under perturbations. "delineate an 8B-parameter robustness boundary"
- Semantic equivalence: Different program representations that produce the same external behavior. "maintain semantic equivalence while introducing syntactic or structural diversity."
- Semantics-preserving transformations: Changes to code that do not alter what it does, used to evade detectors while keeping functionality intact. "semantics-preserving transformations that exploit the gap between statistical and symbolic reasoning within LLMs."
- Statistical regularities: Patterns in token sequences and structures learned from data that models rely on for prediction. "depend heavily on statistical regularities, token distributions, and structural cues learned from massive corpora."
- Symbolic execution: An analysis technique that reasons about program paths using symbolic inputs instead of concrete values. "rather than explicit symbolic execution"
- Token distributions: The frequency and arrangement of tokens in code or text that influences model predictions. "depend heavily on statistical regularities, token distributions, and structural cues learned from massive corpora."
- Virtualization: Obfuscation that translates code into a custom instruction set executed by a virtual machine to hide intent. "virtualizing code execution through custom interpreters."
- Vulnerability benchmark: A curated dataset designed to systematically evaluate vulnerability detection performance. "Our dataset consists of a vulnerability benchmark designed to evaluate the impact of code obfuscation on LLM-based vulnerability detection."
Collections
Sign up for free to add this paper to one or more collections.