- The paper introduces a novel protocol for transmitting compressed KV caches between agents, achieving 5-6x compression while preserving coherence quality above 0.77.
- It employs adaptive layer-wise quantization and hybrid information extraction to optimize semantic fidelity with variable bit-widths across transformer layers.
- The study demonstrates cross-architecture communication via heterogeneous model calibration, paving the way for efficient LLM deployment in bandwidth-constrained environments.
Overview of Q-KVComm: Efficient Multi-Agent Communication Via Adaptive KV Cache Compression
Introduction
The paper "Q-KVComm: Efficient Multi-Agent Communication Via Adaptive KV Cache Compression" (2512.17914) presents a critical advancement in the domain of multi-agent LLM systems. Traditional approaches in this field involve the transmission of raw text between agents, which necessitates redundant recomputation of semantic representations, contributing to substantial bandwidth and computational overhead. Q-KVComm proposes a novel protocol that enables direct transmission of compressed key-value (KV) cache representations between agents, facilitating a transition from text-based to representation-based communication. This paradigm shift aims to significantly reduce bandwidth requirements while maintaining computational efficiency.
Technical Innovations
Q-KVComm institutes three principal innovations:
- Adaptive Layer-wise Quantization: This method employs sensitivity profiling to allocate variable bit-widths across transformer layers. Unlike uniform quantization methods, adaptive quantization allows the protocol to assign 4-8 bits based on reconstruction error sensitivity. This approach ensures optimal compression while preserving semantic fidelity.
- Hybrid Information Extraction: The paper introduces a sophisticated pipeline combining keyword extraction and named entity recognition with content-type detection to preserve critical information across diverse domains. This ensures the transmission of essential semantic elements without substantial quality loss, accommodating various content types from API documentation to narrative texts.
- Heterogeneous Model Calibration: This component enables the translation of KV caches between different architectures through learned statistical mappings, thereby facilitating cross-architecture communication without necessitating identical sender and receiver models.
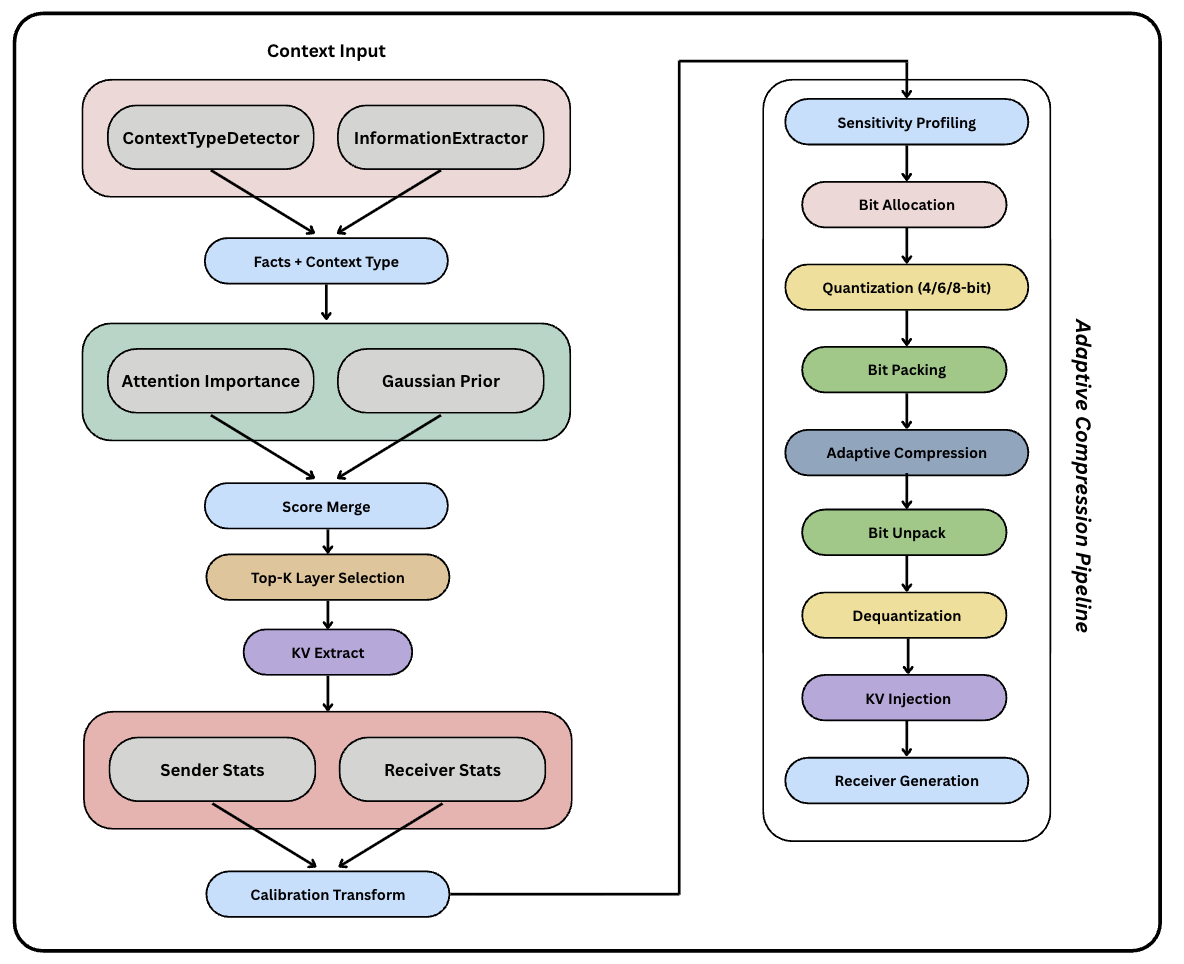
Figure 1: Overview of Q-KVComm Architecture.
Experimental Results
The experimental evaluation spans three diverse question-answering datasets: SQuAD, HotpotQA, and NarrativeQA. Q-KVComm demonstrates 5-6x compression ratios while maintaining coherence quality scores above 0.77, robust across model sizes ranging from 1.1B to 1.5B parameters. The protocol exhibits resilience in real-world applications inclusive of conversational QA and multi-hop reasoning. Notably, Q-KVComm delivers a profound improvement in resource efficiency without significant degradation in performance.
Implications and Future Directions
The implications of this research extend both practically and theoretically in AI and machine learning. Practically, Q-KVComm facilitates the deployment of LLM systems in bandwidth-constrained environments such as edge computing and mobile applications. Theoretically, it establishes a foundational shift towards representation-based inter-agent communication, challenging the necessity of text-based paradigms and opening new avenues for efficient large-scale LLM collaboration.
Future research could explore scaling Q-KVComm to larger models, examining its implications on federated learning, and enhancing security protocols to safeguard internal model representations. Additionally, adopting learned compression techniques might offer further improvements by leveraging more complex statistical structures within KV caches.
Conclusion
Q-KVComm represents a transformative step in multi-agent LLM systems, addressing the longstanding inefficiencies in agent communication. By optimizing bandwidth usage and computational redundancy, it sets a precedent for scalable, efficient communication protocols in distributed AI systems. Its adaptable architecture and robust performance across varied tasks underscore its potential to redefine multi-agent collaboration frameworks in real-world scenarios. These contributions lay the groundwork for future inquiries into more sophisticated, yet efficient, compression strategies and their applications in global AI ecosystems.
