- The paper introduces novel greedy and hybrid clustering algorithms that reduce tree construction time by up to 59× with minimal quality loss.
- It replicates SEATER's results and demonstrates robust performance on the massive Yambda dataset, preserving retrieval metrics within 1%.
- The proposed methods enable industrial-scale deployment by significantly lowering training latency and supporting frequent model refresh.
Efficient Optimization of Hierarchical Identifiers for Generative Recommendation
Introduction
This paper addresses critical scalability and efficiency bottlenecks in generative recommendation systems, specifically focusing on the construction of hierarchical identifiers for item retrieval. Building upon SEATER, a generative retrieval model leveraging balanced tree-structured item identifiers and contrastive learning, the authors identify that SEATER’s tree-construction phase becomes a primary inhibitor as catalog sizes scale, which is particularly impactful for industrial-scale recommenders. The paper reproduces SEATER’s original results, evaluates its scalability on the large-scale Yambda music recommendation dataset, and introduces two pragmatic alternative algorithms—greedy and hybrid hierarchical clustering—to optimize training efficiency without markedly degrading retrieval quality.
Background: Generative Retrieval and Hierarchical Indexing
Generative retrieval reframes the candidate retrieval phase in recommender systems as sequence generation, where item identifiers are generated token-by-token, shifting away from the limitations of dual-encoder models that rely on simple embedding inner products. SEATER’s innovation is the use of balanced, semantically coherent k-ary trees for item identifiers, enabling logarithmic search complexity with respect to catalog size during constrained beam search decoding. The semantic and structural properties of identifiers are enforced via joint objectives: generation, alignment (InfoNCE contrasting parent and child nodes), and ranking losses.
However, the utility of such a framework is moderated by its index construction cost: the capacity-constrained k-means used in SEATER’s tree building phase has poor scalability, scaling super-linearly with item count and exhibiting poor parallelizability (Figure 1).
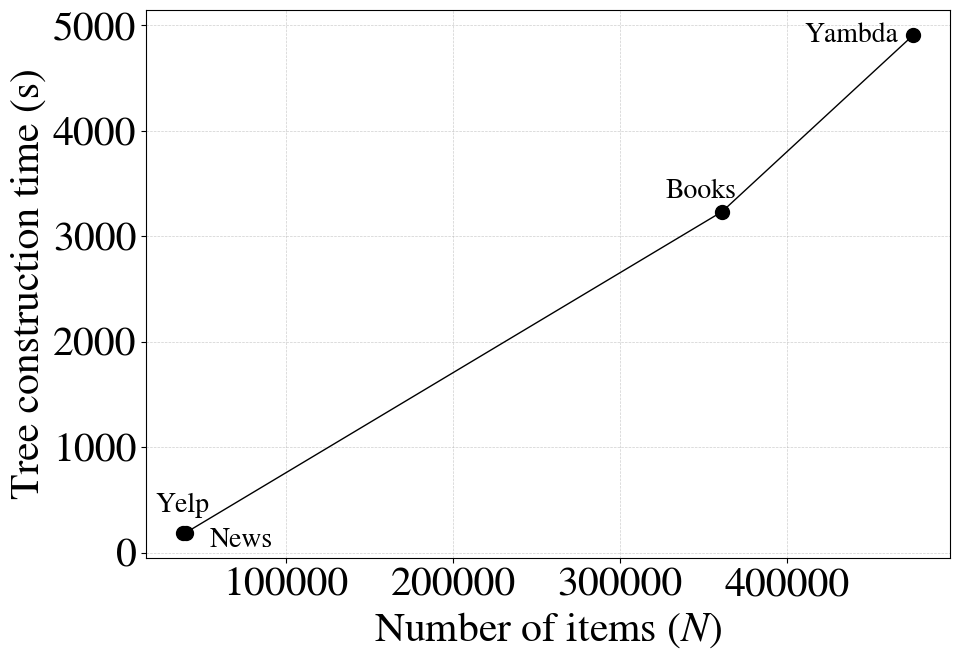
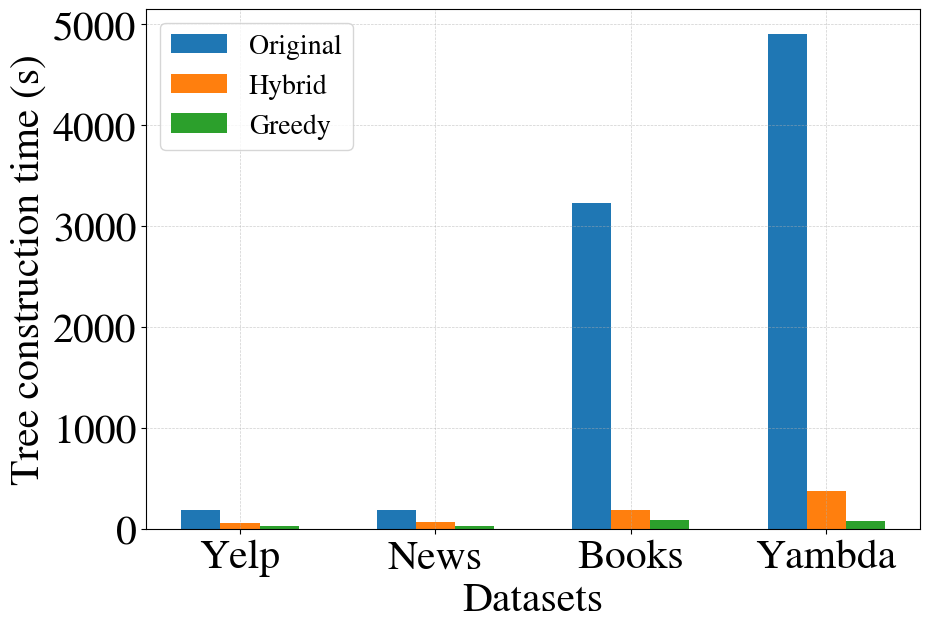
Figure 1: Tree construction time as a function of the number of items, illustrating rapid non-linear growth with capacity-constrained k-means, and the marked efficiency gains of greedy and hybrid algorithms.
Tree Construction Algorithms: Greedy and Hybrid Hierarchical Clustering
The bottleneck originates from the global assignment required by capacity-constrained k-means at each tree level, which becomes infeasible for large datasets and for frequent retraining scenarios common in production. The paper’s main methodological contribution is the development and evaluation of two alternatives:
- Greedy Clustering: Items are assigned to clusters in a sequential, capacity-respecting fashion post standard k-means centroid estimation. This reduces per-level complexity from cubic to linear in item count, and is efficiently implemented with Faiss for parallel GPU-accelerated nearest neighbor searches. The labeling cost and tree index update timelines are consequently reduced to under 2% of the original for the largest dataset.
- Hybrid Clustering: Leverages the insight that precise clustering is less critical at higher levels of the tree (representing coarse semantic partitions). Thus, greedy clustering is used above a tunable threshold, transitioning to capacity-constrained k-means below it for greater leaf-level fidelity. This balance reduces construction times to 5–8% of the original, with negligible or sometimes even improved retrieval performance, particularly on massive datasets.
Experimental Evaluation
Replication and Generalization of SEATER
Empirical findings affirm the validity and replicability of SEATER’s retrieval gains versus strong dual-encoder and tree-based baselines (e.g., SASRec, GRU4Rec, BERT4Rec, TDM) on the original (Books, Yelp, News) and newly introduced Yambda datasets. On Yambda (475,910 items), SEATER maintains or surpasses previous state-of-the-art, demonstrating robustness in both smaller and web-scale retrieval contexts.
Training Efficiency and Retrieval Quality
The bottleneck analysis reveals that tree construction time is highly non-linear, comprising up to 19.4% of end-to-end training time on Yambda with the original method. Greedy clustering decreases tree construction from 82 minutes to 83 seconds on Yambda—approximately a 59× speedup—while incurring only minimal quality drops (≤1% on major retrieval metrics). The hybrid algorithm further narrows the quality gap and, in some large-scale cases, produces superior retrieval metrics due to improved semantic ordering at leaf nodes.
Practical and Theoretical Implications
The results have immediate relevance for practitioners operating on evolving catalogs and/or in environments requiring frequent model refresh (e.g., real-time auctions, content applications). With significantly reduced index update latency, the proposed methods enable end-to-end retraining regimes and support practical deployment at industrial scale.
Theoretically, the work suggests that precise global optimization of tree partitions is only marginally advantageous at the coarse-to-fine semantic levels prevalent in real-world recommendations. Hybrid schemes—leveraging parallelizability at the upper tree with targeted accuracy at the leaves—strike a near-optimal balance under computation-resource constraints.
Future Research Directions
Several open problems remain. Integration of multimodal or context-aware identifiers via hybrid embedding sources, more sophisticated dynamic tree adaptation during training, and further study of the convergence impacts of tree structure on generative model learning are promising next steps. Joint training of the tree and retrieval objectives, and more adaptive strategies for determining depth thresholds for hybrid clustering, may push performance and efficiency envelopes further.
Conclusion
This work establishes that the main limitation of scalable generative retrieval—hierarchical identifier construction—can be substantially mitigated. The greedy and hybrid algorithms described enable dramatic reductions in construction cost with preserved or improved accuracy on large-scale, real-world datasets, fundamentally advancing the practicality of generative recommenders with tree-structured semantic indices (2512.18434).