- The paper introduces a novel SID generation framework using multimodal data and pretrained encoders to enable efficient generative retrieval.
- It employs advanced optimization techniques including KNN and random-based post-processing to reduce SID collisions and ensure fair distribution.
- The evaluation on a massive Taobao dataset demonstrates significant improvements in retrieval hitrate and a reduction in online convergence time.
Introduction
The paper "FORGE: Forming Semantic Identifiers for Generative Retrieval in Industrial Datasets" (2509.20904) introduces a comprehensive framework aimed at enhancing generative retrieval systems in industrial applications, specifically through the construction and optimization of semantic identifiers (SIDs). SIDs are pivotal in generative retrieval due to their role in encoding meaningful semantic information, essential for accurate item recommendation and retrieval in vast datasets. This work presents several innovations, including a large-scale industrial dataset, SID generation strategies, and efficient online deployment techniques, all designed to address existing limitations in the field.
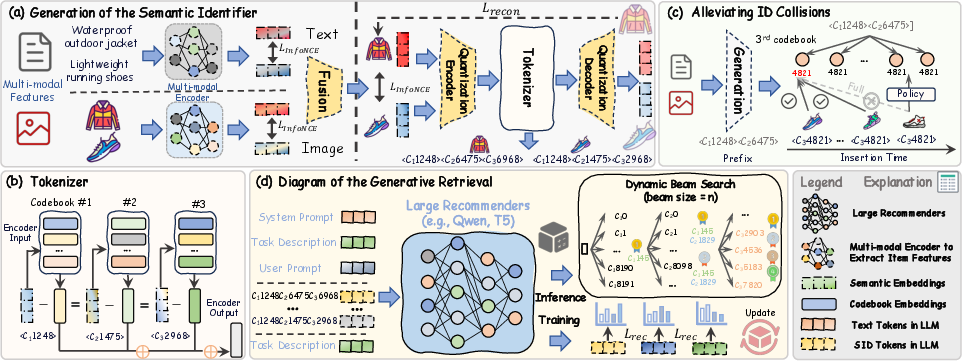
Figure 1: Overview of FORGE. (a) The generation process of SIDs. Left panel: the training of the text/image encoder.
SID Generation and Optimization
The FORGE framework tackles the SID formation process by leveraging multimodal data, including text and images, to derive rich semantic features. The paper proposes the use of pretrained multimodal LLMs and introduces a novel encoder-quantization approach for item tokenization into semantic identifiers. This method ensures that SIDs are both computationally efficient and semantically meaningful, offering robust representation capabilities across an exponentially large item space.
For optimization, FORGE employs advanced algorithms to mitigate ID collisions, ensuring fair distribution and high utilization of codebooks. These strategies, including KNN-based and random-based post-processing methods, enhance the granularity and fairness of SID assignments, crucial for maintaining consistent retrieval performance.
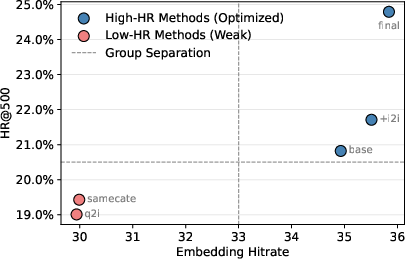
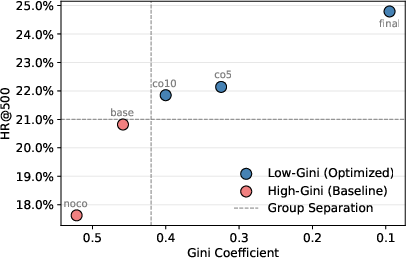
Figure 2: The effectiveness of embedding hitrate and Gini coefficient for SID evaluation. Left: Positive correlation between embedding hitrate and retrieval performance. Right: Lower Gini coefficient (fairer SID usage) leads to higher HR@500.
Generative Retrieval Model
The generative retrieval component of FORGE integrates the SIDs with LLM architectures such as Qwen and T5, allowing for efficient sequence prediction of recommended items. This approach facilitates the dynamic adaptation of beam search strategies during inference, optimizing computational resource usage while ensuring high-quality generation of retrieval candidates. The paper reports substantial gains in hitrate metrics across multiple configurations, underscoring the efficacy of the proposed SID generation and optimization techniques.
Dataset and Evaluation
FORGE introduces a groundbreaking dataset sourced from Taobao with 14 billion user interactions and multimodal features for 250 million items, vastly surpassing existing benchmarks in scale and diversity. This dataset serves as a valuable tool for offline experiments and online evaluations, providing insights into SID design choices and their impact on generative retrieval systems. Furthermore, FORGE pioneers the use of direct evaluation metrics, such as embedding hitrate and Gini coefficient, offering researchers cost-effective means to assess SID quality without extensive GR training.
Implications and Future Directions
The practical implications of FORGE are profound, with demonstrated improvements in transaction counts and retrieval metrics in real-world applications on Taobao's platform. The proposed offline pretraining schema offers a pragmatic solution for reducing online convergence time by half, highlighting the framework's adaptability and efficiency in industrial deployments.
Future research in this domain could further explore the integration of advanced machine learning techniques for SID generation, including deep reinforcement learning and hierarchical attention mechanisms. Additionally, expanding the framework to accommodate evolving e-commerce scenarios and user behavior patterns will enrich the applicability and robustness of generative retrieval systems.
Conclusion
The FORGE framework marks a significant advancement in the field of generative retrieval by addressing key challenges in SID formation and optimization within industrial datasets. Through its comprehensive benchmark and innovative methodologies, FORGE provides a robust foundation for future developments in semantic identifier construction, with implications extending across both theoretical research and practical applications in large-scale recommendation systems. The release of the dataset and evaluation tools fosters collaborative efforts, encouraging further contributions to this dynamic area of study.