AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Abstract: Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train a powerful computer vision model (a model that understands images). The authors build a single “student” model that learns from two different “teacher” models at the same time. Their student is a Mixture‑of‑Experts (think: a team of specialists), and they train it efficiently so it learns both:
- how to match images with text (naming and describing things), and
- how to understand fine visual details (useful for tasks like segmentation).
They call their approach AMoE (Agglomerative Mixture‑of‑Experts), and they also create a carefully curated dataset of 200 million images (OpenLVD200M) to make learning faster and better.
What questions did the researchers ask?
In simple terms, they asked:
- Can one vision model learn the strengths of multiple top models at once (like learning art style from one teacher and anatomy from another)?
- Can we do this without needing huge amounts of compute and data?
- How can we keep what each teacher knows (their “shape” of knowledge) without the student getting confused?
- How do we train fairly when images have very different sizes?
- Does carefully picking training images help more than just grabbing lots of random images?
How did they do it?
Here’s the approach, explained with everyday examples.
Learning from two teachers at once
- Teacher A (SigLIP2) is great at matching images with words (image–text alignment).
- Teacher B (DINOv3) is great at capturing detailed visual structure (dense features for things like segmentation).
- The student sees each image and tries to match both teachers’ “answers”: overall image summaries and detailed patch‑by‑patch features.
- To respect how each teacher summarizes an image, the student uses a small “adapter” for each teacher so it can “speak” each teacher’s language.
A team‑of‑specialists student (Mixture‑of‑Experts)
- Instead of one big brain, the student has many “experts.” A small “router” decides which experts should handle each piece of the image.
- Think of it like a hospital: a triage nurse (router) sends each case (image parts) to the right specialists (experts). This lets the model naturally specialize—some experts get good at language‑aligned features (like SigLIP2), others at detailed vision (like DINOv3).
Keeping the “map” of similarities (ARKD)
- Imagine you plot images on a map where similar images are close together. Each teacher has its own map.
- The student learns not just to copy the teacher’s answers, but also to copy the “distances” between images—so that the student’s map has the same shape as the teacher’s.
- A naive way (RKD) can overpush images and hurt clustering. Their fix (Asymmetric RKD, or ARKD) only nudges pairs in the right direction when needed (shrink if the teacher says “close,” expand if the teacher says “far”). This preserves good clusters while improving image–text alignment.
Fair training with different image sizes (token‑balanced batching)
- Images come in different sizes. Bigger images produce more “pieces” (tokens) for the model to process.
- If you batch a small image with a huge one, the huge one can dominate learning—like grading based on who wrote the longest essay.
- Their solution: “pack” multiple images into a sequence but cap the total number of pieces per batch. Then normalize loss per image so each image counts equally. This stabilizes training and improves performance, especially when mixing low and high resolutions.
Building a better training set (OpenLVD200M)
- Random web images are skewed: some concepts appear a lot (cats), others rarely (exotic birds).
- They cluster a massive pool of web images and then sample in a balanced way so many different concepts are covered fairly.
- The result: OpenLVD200M—200 million images that give broader, more even coverage. This turns out to help a lot, especially for fine‑grained categories (like specific aircraft models).
High‑resolution training without forgetting
- They first train at lower resolution (fast learning of general patterns), then add higher resolutions (more detail).
- Thanks to token‑balanced batching and per‑image normalization, the model doesn’t “forget” what it learned at low resolution when it sees high‑resolution images.
What did they find?
Here are the big takeaways, summarized for clarity.
- Stronger results with less compute:
- Their student beats previous agglomerative models on many global tasks (like image–text classification and retrieval) while using about 4.7× fewer tokens seen during training (roughly 230 billion vs. 1.1 trillion) and far fewer images (≈200M curated vs. ≈1B+).
- Better at fine‑grained recognition:
- On tough, detailed datasets (like aircraft types), the new model makes notably fewer mistakes than strong baselines.
- Competitive on dense tasks:
- For segmentation (which needs detailed features), it matches or slightly improves over strong baselines on standard benchmarks.
- ARKD works:
- Adding their asymmetric relational loss boosts image–text alignment a lot (especially for the DINOv3‑style teacher) while keeping clustering quality strong.
- Data curation matters:
- Their balanced OpenLVD200M notably outperforms a random 200M‑image sample, particularly on rare or fine‑grained categories.
- Mixture‑of‑Experts pays off:
- Different experts specialize in different teacher skills, and combining (ensembling) the teacher‑specific heads at test time gives further gains.
- Good starting point for grounding (linking text to regions in images):
- Initializing a grounding model with their vision experts strongly improves detection and segmentation of referred objects; adding a technique called Gram anchoring improves it even more.
Why does this matter?
- One model, many skills: This shows we can combine strengths from multiple top models into a single, efficient vision backbone.
- Smarter, cheaper training: With careful data curation, fair batching across image sizes, and relation‑aware learning, we can train strong models using much less compute.
- Practical impact:
- Better zero‑shot recognition: the model can recognize things it wasn’t explicitly trained on.
- Stronger fine‑grained understanding: useful for quality control, science, and hobbyist applications (e.g., bird or plane spotting).
- Strong starting point for multimodal systems: building AI that can see and understand language together (vision‑LLMs) becomes easier and more reliable.
- Reusable resources: The authors release OpenLVD200M and their distilled models, helping others build on their work.
In short, this paper presents a well‑designed recipe for teaching a single vision model to inherit the best parts of multiple experts—efficiently, fairly, and with strong results on both “big picture” and “fine detail” tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for future researchers.
- Generality to more than two teachers: The method is evaluated with SigLIP2 and DINOv3 only; it remains unclear how ARKD, token-balanced batching, PHI-S, and MoE routing scale when distilling from three or more heterogeneous teachers (e.g., SAM, depth/flow, detection, OCR).
- Teacher selection and weighting strategy: There is no principled criterion for choosing which teachers to include or how to dynamically balance their supervision over training; evaluate adaptive teacher weighting schedules or curriculum strategies beyond static PHI-S normalization.
- PHI-S limitations for multi-modal registers: The PHI-S transform fails on DINOv3’s second register due to multi-modal statistics; develop robust, invertible normalization for mixture-of-Gaussians or mode-conditioned transforms, and test per-mode PHI-S or non-linear normalization.
- Register supervision coverage: Only DINOv3 registers are matched; assess whether adding synthetic or learned “register-like” targets for SigLIP2 improves dense feature quality and global-local consistency.
- Single-layer projection heads: The student uses single-layer MLP heads for both patch and global features; ablate deeper heads, separate heads for CLS vs. patches, and shared vs. teacher-specific heads to test expressivity/specialization trade-offs.
- ARKD scope limited to global embeddings: ARKD is applied only to summary (global) embeddings; investigate patch-level relational distillation (e.g., local geometry via neighborhood graphs) and its impact on dense tasks.
- ARKD design choices: The median split and Euclidean distance are ad hoc; evaluate alternatives (cosine/angular metrics, rank-based losses, margin schedules, adaptive thresholds) and quantify sensitivity to batch size, class mix, and teacher scales.
- ARKD computational overhead: Pairwise losses are O(B²) per batch; measure memory/latency overhead under sequence packing and distributed training, and prototype sub-sampling or structured relational losses to reduce cost.
- Cross-rank ARKD consistency: It is unclear whether pairwise distances are computed across ranks or only per-rank; assess correctness and scalability of cross-rank relational matching under distributed data parallel.
- Token-balanced batching generality: The benefits are shown for native-resolution image training with FlexAttention; test generality across different architectures (convnets, Swin), tasks (video, 3D), and very high resolutions (e.g., ≥1024²).
- Loss normalization side-effects: Per-image token-normalized losses equalize gradient contributions across resolutions; evaluate whether this suppresses learning of fine detail in high-res patches and explore resolution-aware weighting schemes.
- Resolution shift robustness: Stage-2 high-resolution post-training claims to avoid low-res forgetting qualitatively; provide quantitative measures of low-res performance pre/post Stage-2 and explore training recipes for ultra-high-res (e.g., multi-scale curriculum).
- MoE router and load balancing details: The paper lacks specifics on router training, load-balancing losses, expert capacity, and dropout; systematically ablate router hyperparameters to prevent expert collapse and quantify specialization vs. utilization.
- MoE inference costs and deployment: The compute/latency impact of MoE routing at inference is not analyzed; benchmark against dense models, explore expert pruning/compression, and measure energy costs and memory footprints for deployment.
- Specialist vs. shared experts: The early-fusion grounding VLM uses modality-specific and shared experts; ablate the number and placement of shared experts, gating policies across modalities, and their effect on interference and transfer.
- Limited grounding evaluation: RefCOCO/RefCOCOg/RefCOCO+ results use [email protected] and compare mostly against scratch baselines; add comparisons to state-of-the-art grounding models, broader metrics (e.g., mAP, AUC), and datasets (e.g., PhraseCut, Visual Genome).
- Gram anchoring during distillation: Gram anchoring is used for VLM adaptation but not during multi-teacher distillation; investigate adding Gram-based regularization in the student training to directly preserve dense feature quality.
- Ensembling evaluation procedure: Entropy-weighted head ensembling introduces new hyperparameters (τ, γ) and per-input adaptivity; test robustness, calibration, and potential overfitting risks, and compare with static weighting or meta-learned fusion.
- OpenLVD200M curation bias: Clustering uses DINOv3 ViT-B embeddings only; quantify bias toward DINOv3 semantics and test alternative curation strategies (multi-teacher fusion embeddings, text-informed clustering, multilingual balancing).
- Text and multilingual coverage: Since curation is image-only, assess how concept and language distributions affect SigLIP2-aligned tasks, and evaluate performance on multilingual retrieval/zero-shot classification.
- Data governance and safety: The paper does not address filtering of problematic content, licensing, privacy, or demographic biases in LAION/DFN; implement and measure safety filters and fairness audits for OpenLVD200M.
- Scaling laws and data efficiency: Claims of token-efficiency are promising but isolated; derive scaling laws across model size, number of teachers, curated data size, and resolution to predict compute/data requirements.
- Robustness and out-of-distribution tests: Evaluate under domain shifts (medical, satellite, sketches), corruptions (ImageNet-C), occlusions, and long-tail extremes to validate the claimed improvements in concept coverage and representation quality.
- Patch-to-text localization: SigLIP2’s dense features are non-separable; test whether the distilled student improves patch-level text grounding (e.g., phrase-region alignment) and whether ARKD helps local cross-modal alignment.
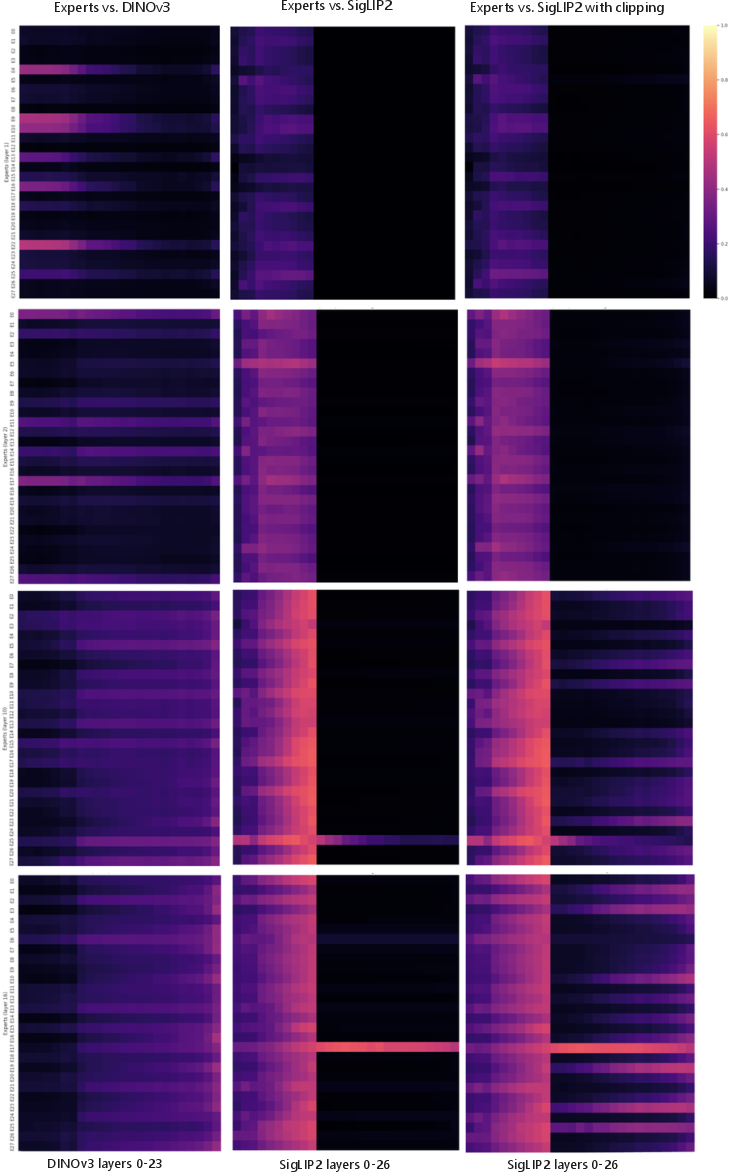
- Expert specialization stability: Linear CKA analysis uses ~1k images and ad hoc clipping; expand to larger datasets, formalize handling of high-magnitude activations, and track specialization dynamics over training.
- Prompting and template choices: Zero-shot results depend on class prompts, but prompt design and templates are not detailed; systematically evaluate prompt sensitivity and standardized protocols for fair comparison.
- Teacher agreement/disagreement handling: The framework does not explicitly resolve conflicting teacher signals; study conflict-aware losses (e.g., teacher consensus weighting, disagreement regularization) and their effect on student geometry.
- Distillation objectives for dense features: Beyond MSE, explore contrastive or structure-preserving losses (e.g., rank constraints, Laplacian/graph regularizers) for patches/registers to enhance clustering and boundary fidelity.
- Reproducibility details: Key hyperparameters (optimizer, augmentations, weight decay, router losses, LR schedules), PHI-S training specifics, and sequence-packing masks are relegated to the supplement; provide full recipes and seeds for exact reproducibility.
- Compute and energy reporting: Efficiency is discussed in tokens/sec and total tokens, but wall-clock time, GPU-hours, and energy usage are not reported; provide standardized efficiency metrics to substantiate the claimed savings.
Practical Applications
Practical Applications of AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Below are actionable applications derived from the paper’s findings and innovations. Each item indicates relevant sectors, potential tools/products/workflows, and assumptions or dependencies affecting feasibility.
Immediate Applications
These can be deployed or prototyped now using the released models, dataset, and training recipes.
- Unified vision encoder for multimodal systems (software, media-tech, e-commerce)
- What: Drop-in use of the AMoE student encoder for robust image-text classification, retrieval, and zero-shot recognition with improved fine-grained performance.
- Tools/workflows: “AMoE Vision Encoder” + entropy-weighted head ensembling; prompt-based classification systems; kNN-based indexing for visual search.
- Assumptions/dependencies: Access to released checkpoints; compatibility with existing inference stacks; domain shift from web datasets may require fine-tuning for niche domains.
- Efficient internal CLIP-like model building (software, enterprise AI)
- What: Adopt Asymmetric Relational Knowledge Distillation (ARKD) to boost image-text alignment for ViT students trained from existing teachers.
- Tools/workflows: Integrate ARKD loss module into distillation pipelines; use SigLIP2/DINOv3 teachers; evaluate image-text retrieval with Recall@1.
- Assumptions/dependencies: Availability of teachers; correct scaling/normalization of losses; careful monitoring to avoid kNN degradation without ARKD.
- Cost-efficient, stable multi-resolution training (MLOps, cloud AI, energy)
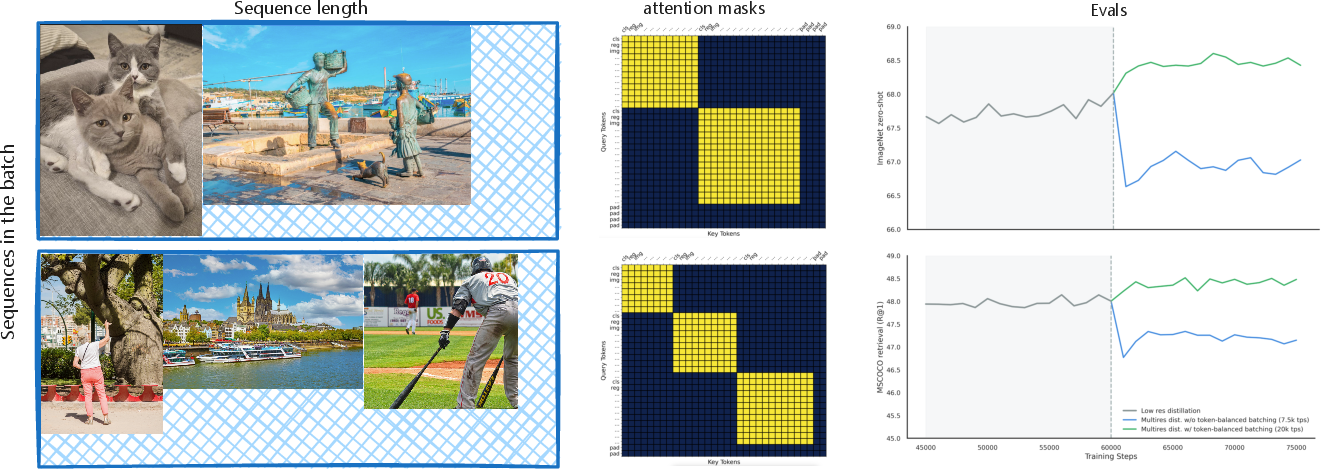
- What: Token-balanced batching via FlexAttention for packing variable-resolution images, yielding higher throughput and stabilized gradients (2–3× tokens/sec reported).
- Tools/workflows: “FlexAttention packing” + per-image token-normalized losses in distributed training; reduced padding; uniform token budgets across ranks.
- Assumptions/dependencies: Framework support for FlexAttention/masked attention; sequence packing implementation; monitoring cross-rank token balancing.
- Curated data pipelines to reduce long-tail bias (data engineering, policy, research)
- What: Use OpenLVD200M methodology (hierarchical clustering + balanced sampling) to improve concept coverage and downstream fine-grained performance.
- Tools/workflows: “OpenLVD-style sampling” service; integrate DINO embeddings for clustering; balanced sampling at multi-level hierarchies.
- Assumptions/dependencies: Compute for clustering (multi-node GPU); data licensing and compliance for LAION/DFN; privacy and content moderation constraints.
- Early-fusion grounding VLM bootstrapping (robotics, AR/VR, labeling tools)
- What: Initialize grounding VLMs with AMoE vision experts to improve referring expression segmentation/detection with limited annotations.
- Tools/workflows: “AMoE-init grounding pipeline” + Gram-Anchoring for dense feature preservation; rapid dataset bootstrapping for object grounding tasks.
- Assumptions/dependencies: Task-specific fine-tuning; consistent prompt engineering; deployment latency for MoE gating on target hardware.
- Enhanced e-commerce and media search (retail, media platforms)
- What: Better fine-grained category recognition and text-to-image retrieval (e.g., FGVC-Aircraft, Food-101 gains) for catalog search, visual browsing, and recommendations.
- Tools/workflows: Hybrid head ensembling for per-query confidence-weighted fusion; gallery construction with kNN retrieval; prompt libraries for product attributes.
- Assumptions/dependencies: Domain-specific prompt curation; moderation/brand safety filters; periodic retraining to reflect inventory drift.
- Content moderation and compliance auditing (platform safety, policy-tech)
- What: Improved cross-modal retrieval enables more accurate detection of prohibited content via text queries and visual signatures.
- Tools/workflows: Retrieval dashboards; policy rule prompts; confidence-weighted head ensemble for high-recall filtering.
- Assumptions/dependencies: False-positive reduction with human-in-the-loop; jurisdiction-specific policy enforcement; dataset auditing for bias.
- Visual data labeling acceleration (ML annotation ops)
- What: Use robust dense features and grounding to pre-annotate segmentation/detection tasks, reducing manual labeling effort.
- Tools/workflows: Semi-automatic annotation tools with AMoE backbone; Gram-Anchoring during domain adaptation to preserve dense features quality.
- Assumptions/dependencies: Domain shift mitigation; QA workflows; iterative human correction loops.
- Multimedia accessibility (daily life, education, public sector)
- What: Higher-quality image-to-text alignment for alt-text generation and descriptive search, aiding accessibility and educational software.
- Tools/workflows: Captioning assist with SigLIP2 head; retrieval-enhanced descriptions; curriculum materials with visual-semantic alignment.
- Assumptions/dependencies: Responsible prompt design; fairness audits; alignment with accessibility guidelines (e.g., WCAG).
- Photo and design tooling (consumer apps, creative software)
- What: Better object selection and referring expression segmentation for photo editing, AR overlays, and design workflows.
- Tools/workflows: On-device or cloud inference using AMoE grounding; natural language selection (“select the red mug near the keyboard”).
- Assumptions/dependencies: Latency and memory constraints for MoE; compression/distillation for mobile deployment.
- Training efficiency and carbon reduction (enterprise AI, sustainability)
- What: Adopt token-balanced batching and OpenLVD-style curation to reduce total tokens and compute for comparable accuracy (≈4.7× fewer tokens than baselines).
- Tools/workflows: Training playbooks with throughput KPIs; energy monitoring dashboards; green AI reporting for governance.
- Assumptions/dependencies: Accurate measurement; integration with cloud sustainability tooling; trade-offs in throughput vs. model size.
- Research baselines and reproducibility (academia)
- What: Standardize multi-teacher distillation recipes, ARKD, and ensembling evaluations as reproducible baselines for VFM research.
- Tools/workflows: Reference code, ablation scripts, benchmark suites (classification, kNN, retrieval, segmentation).
- Assumptions/dependencies: Consistent evaluation protocols; open checkpoints and licensing; community adoption.
Long-Term Applications
These require further research, domain adaptation, scaling, optimization, or regulatory approval.
- Domain-specific medical imaging assistants (healthcare)
- What: Use AMoE’s dense features and grounding to assist segmentation (organs, lesions) and retrieval of similar cases with limited labels.
- Tools/workflows: Clinical fine-tuning pipelines with Gram-Anchoring; radiology PACS integration; risk-calibrated reporting.
- Assumptions/dependencies: Regulatory clearance; domain data with appropriate labels; robustness and fairness validation beyond web data.
- Autonomous perception stacks (robotics, autonomous vehicles)
- What: Early-fusion grounding with modality-specific experts for unified perception—object detection, segmentation, language-driven navigation.
- Tools/workflows: Real-time MoE routing on edge accelerators; multi-sensor fusion; robustness evaluation under adverse conditions.
- Assumptions/dependencies: Low-latency inference; domain transfer to driving/robotics datasets; safety certification.
- Industrial inspection and QA (manufacturing, energy)
- What: Fine-grained classification and grounding for defect detection and part identification in long-tail catalogs.
- Tools/workflows: Visual QA pipelines with retrieval and text prompts; continual learning with Gram-Anchoring to preserve dense features.
- Assumptions/dependencies: High-resolution domain data; controlled lighting and viewpoint; integration into MES/SCADA systems.
- Geospatial analytics and environmental monitoring (geospatial, public sector)
- What: Dense segmentation and retrieval over satellite/aerial imagery for land-use, infrastructure, disaster response.
- Tools/workflows: Domain-pretrained encoders; multi-resolution token-balanced training for high-res tiles; promptable analysis tools.
- Assumptions/dependencies: Specialized pretraining; ground-truth availability; scalability to continent-level datasets.
- Document and UI understanding (software, finance, gov-tech)
- What: Extend AMoE to layout-aware encoders for document segmentation, table grounding, and UI element referencing via natural language.
- Tools/workflows: Multimodal VLMs with vision-text grounding; retrieval-augmented financial QA over visual documents.
- Assumptions/dependencies: Additional modalities (OCR, structure); domain teachers; evaluation standards for accuracy and compliance.
- On-device personal AI for media organization (consumer, privacy-tech)
- What: Compressed AMoE-like encoders enabling local photo/video search, grounding-based editing, and privacy-preserving alt-text.
- Tools/workflows: MoE distillation/pruning; edge acceleration; encrypted indices for private retrieval.
- Assumptions/dependencies: Efficient gating; memory constraints; user privacy guarantees.
- Training-data governance platforms (policy-tech, enterprise data)
- What: “Curation-as-a-service” offering hierarchical clustering and balanced sampling to mitigate long-tail bias and improve model fairness.
- Tools/workflows: Auditable pipelines; bias reports; policy controls aligned with AI governance (e.g., EU AI Act).
- Assumptions/dependencies: Institutional buy-in; data provenance requirements; standardized bias/fairness metrics.
- Sustainable AI mandates and tooling (policy, sustainability)
- What: Policy incentives and guidelines to adopt throughput- and token-efficient training (token-balanced batching) for reduced emissions.
- Tools/workflows: Compliance dashboards; green AI certifications; shared benchmarks for energy-efficient training.
- Assumptions/dependencies: Measurement standards; cross-industry collaboration; impact studies.
- Multimodal assistants with robust grounding (consumer, enterprise)
- What: General-purpose assistants that can reference and manipulate visual content via language (“highlight the faulty valve here”), powered by modality-specific experts.
- Tools/workflows: Early-fusion VLM stacks; safety-aligned grounding; domain plug-ins for industrial contexts.
- Assumptions/dependencies: Long-tail robustness; UI integration; safety and privacy controls.
- Adaptive MoE pipelines for continual learning (MLOps, research)
- What: Expert specialization workflows that route domain-specific tokens to tailored experts, preserving older knowledge via Gram-Anchoring.
- Tools/workflows: Expert routing analysis (CKA monitoring); lifelong learning schedulers; catastrophic forgetting alerts.
- Assumptions/dependencies: Robust routers; expert capacity management; evaluation across evolving distributions.
- Standardized evaluation and ensembling services (platforms, academia)
- What: Hosted evaluation APIs that implement entropy-weighted head ensembles and ARKD-aware scoring across tasks and domains.
- Tools/workflows: Benchmark orchestration; per-head confidence calibration; domain adapters.
- Assumptions/dependencies: Community datasets; governance for shared benchmarks; reproducibility guarantees.
- Sector-specific VFMs (vertical SaaS: retail, media, security)
- What: Build specialized AMoE variants with domain teachers (e.g., product catalogs, sports footage) for superior retrieval and grounding.
- Tools/workflows: Teacher selection frameworks; ARKD tuning per teacher; multi-resolution training at native asset sizes.
- Assumptions/dependencies: Domain teacher availability; data rights; latency constraints in production.
Notes on feasibility across applications:
- The current AMoE is trained on web-curated data (OpenLVD200M). For safety-critical or regulated domains (healthcare, autonomous driving), rigorous domain adaptation, validation, and compliance are prerequisites.
- MoE inference introduces gating overhead and memory footprints; real-time/edge scenarios will need compression, pruning, and accelerator support.
- Data curation and training efficiency gains depend on infrastructure supporting FlexAttention, sequence packing, and distributed loss normalization.
- Licensing and data governance (LAION/DFN-derived sources) must be addressed for commercial use; ensure content moderation and bias audits.
Glossary
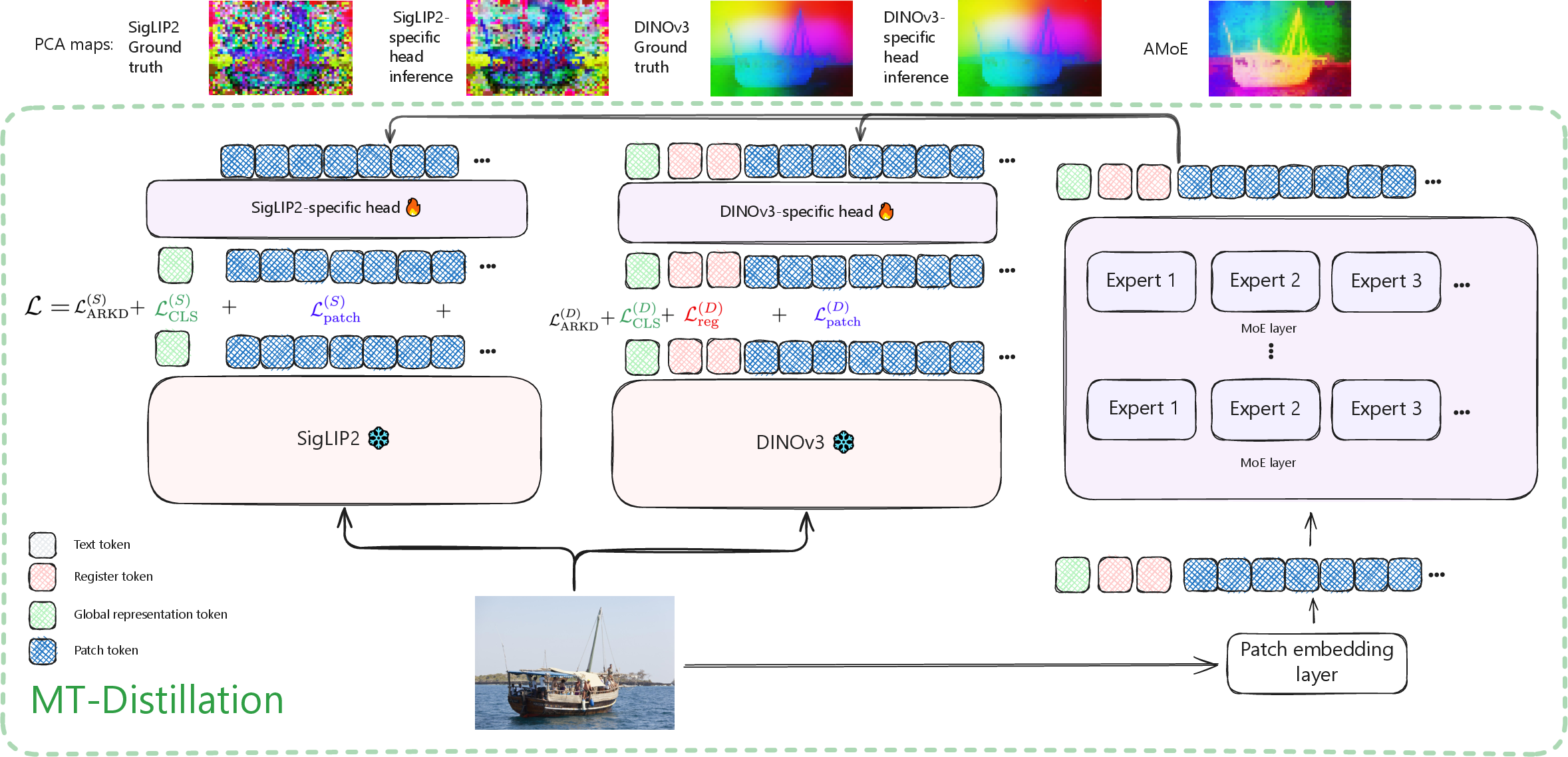
- Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE): A unified vision model that distills multiple teachers into a single Mixture-of-Experts student. "We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student."
- Agglomerative Vision Foundation Models (VFMs): Vision backbones that combine capabilities of different teacher models via distillation. "Recently, an alternative paradigm of agglomerative Vision Foundation Models (VFMs) has emerged, unifying complementary capabilities within a single vision backbone by distilling knowledge from multiple teacher models."
- Attention pooling layer: A mechanism that aggregates token features into a global representation using attention weights. "For SigLIP2, the global representation is computed from an attention pooling layer."
- Catastrophic forgetting: Loss of previously learned knowledge when training on new data or distributions. "prevents catastrophic forgetting, and improves training efficiency."
- Centered Kernel Alignment (CKA): A similarity metric for comparing representation spaces, invariant to orthogonal transforms and scaling. "We use Linear Centered Kernel Alignment (CKA) as our similarity metric, chosen for its invariance to orthogonal transformations and isotropic scaling, making it suitable for comparing representation spaces of differing dimensions."
- CLS token: A special summary token prepended to patch tokens to represent the whole image. "We prepend CLS and four register tokens to the patch tokens, similar to DINOv3."
- DINOv3: A self-distilled vision model with high-quality dense features and Gram anchoring. "DINOv3 is trained with self-distillation and Gram-anchoring, designed to preserve extremely high-quality dense features."
- Early-fusion grounding VLMs: Vision-LLMs that fuse modalities early for tasks like grounding. "We show that Mixture-of-Experts (MoE) architecture naturally enables early-fusion grounding VLMs via modality-specific experts."
- Entropy-weighted head ensembling: A fusion method that weights teacher-head outputs by confidence (entropy) per input. "we introduce a new entropy-weighted head-ensembling evaluation designed for agglomerative models."
- FlexAttention: An attention mechanism that supports masking to prevent inter-image attention within packed sequences. "avoid inter-image self-attention via FlexAttention."
- Frobenius norm: A matrix norm used to measure cross-covariance magnitude in CKA. "Linear CKA measures the similarity between these two sets of representations based on the Frobenius norm of their cross-covariance matrix."
- Gram-Anchoring: A regularization that preserves dense feature quality during adaptation. "Gram-Anchoring preserves dense feature quality during adaptation, preventing the degradation typically observed when learning VLMs."
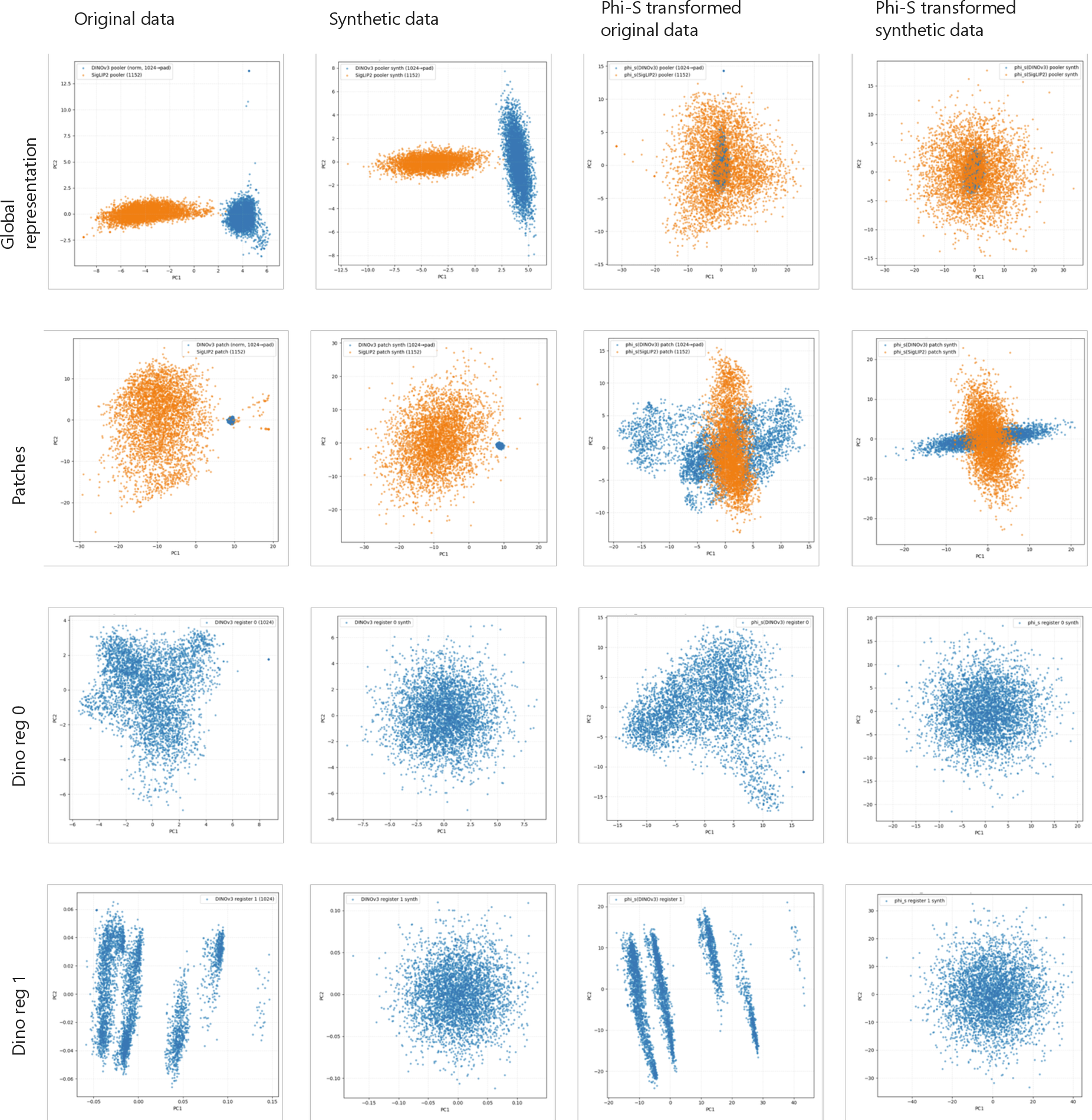
- Hadamard Matrices: Structured orthogonal matrices used in PHI-S for feature normalization. "built from Hadamard Matrices and second-order moments estimation."
- Hierarchical clustering: Multi-level clustering used to curate balanced datasets and flatten long-tail distributions. "We utilize the hierarchical clustering and sampling technique, introduced by~\cite{vo2024automatic}, to mitigate long-tail biases in web-scraped datasets."
- LiT (Language-Image Pretraining): A post-hoc alignment procedure for image-text embedding spaces. "aligned with text only a posteriori through the LiT procedure~\cite{zhai2022lit}"
- Linear probing: Evaluating representations by training simple linear classifiers/segmenters on frozen features. "For segmentation, we report mIoU for 10 epochs of linear probing with 32-batch sizes with learning rate at on the patch representations"
- Mixture-of-Experts (MoE): An architecture that routes tokens to specialized expert networks to improve capacity and specialization. "We employ a MoE architecture and two teacher-specific, single-layer MLP projection heads."
- Multi-teacher distillation (MT): Training a student to match multiple teachers’ signals simultaneously. "We revisit Multi-Teacher (MT) Distillation and identify three critical factors"
- OpenLVD200M: A curated 200M-image dataset constructed via hierarchical clustering and balanced sampling. "We introduce OpenLVD200M, constructed from a 2.3B-image blend of DFN and LAION."
- Patch tokens: Spatial tokens representing image patches in transformer-based vision models. "the student backbone outputs a global summary token along with patch tokens."
- PCA map: A visualization of embeddings using Principal Component Analysis to show representation structure. "The PCA map of the student embeddings (at the top) illustrates the high-quality, dense representations obtained after distillation."
- PHI-S (PCA–Hadamard Isotropic Standardization): A label-free normalization that equalizes teacher feature scales during distillation. "PHI-S~\cite{ranzinger2024phi} (PCA–Hadamard Isotropic Standardization) is a normalization technique for label-free multi-teacher distillation that equalizes the statistical scales of diverse teacher feature distributions"
- Register tokens: Special tokens added to improve dense feature quality and stability in ViTs. "Additional register tokens are employed in the student model, similar to DINOv3."
- Relational Knowledge Distillation (RKD): A distillation approach that matches pairwise relations/geometry between samples. "inspired by relational knowledge distillation~\cite{park2019relational} (RKD), is beneficial."
- Router (MoE router): The component that assigns tokens to experts in a Mixture-of-Experts layer. "the token embeddings that the router assigns to that expert."
- Self-distillation: Training a model to predict targets generated by itself (or an older version) to improve representations. "DINOv3 is trained with self-distillation and Gram-anchoring"
- Sequence packing: Combining multiple images into a single sequence up to a token budget for efficient training. "where multiple images are packed into sequences up to a maximum context length "
- SigLIP2: A multilingual vision-language encoder trained with sigmoid contrastive and captioning objectives. "SigLIP2 is a vision–language encoder contrastively trained with a sigmoid image–text objective and a decoder-style captioning loss."
- Smooth-L1 function: A loss function combining L1 and L2 behaviors for robust regression. "With the smooth-L1 function , the loss is:"
- Token-balanced batching: Packing images to equalize token budgets across ranks and normalizing losses per image to stabilize training. "We address this through token-balanced batching"
- Vision foundation models: Large pretrained vision encoders intended to provide general-purpose visual representations. "Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations"
- Vision-LLMs (VLMs): Models that jointly process images and text for multimodal tasks. "While VLMs are effective for instruction-following, they aren't natively multi-modal and often underperform on dense prediction tasks."
- Vision Transformers (ViT): Transformer architectures applied to images using patch tokenization. "Knowledge Distillation (KD) has been employed to make large and expensive Vision Transformers (ViT), usually trained on ImageNet"
- Zero-shot: Evaluation without task-specific training, using pretrained representations or prompts. "reflected in zero‑shot and kNN accuracy."
Collections
Sign up for free to add this paper to one or more collections.