- The paper presents a comprehensive taxonomy of KD methods, highlighting that feature- and similarity-based approaches can compress models with only a 0.5–2% accuracy drop compared to teachers.
- It categorizes KD techniques by source, scheme, algorithm, modality, and application, thus offering a unified framework to compare diverse methods.
- Empirical analyses across benchmarks like CIFAR-100 and ImageNet illustrate robust student performance, achieving near-teacher accuracy with compression rates exceeding 4–7×.
A Comprehensive Survey on Knowledge Distillation (2503.12067)
Introduction and Motivation
This work addresses the landscape of Knowledge Distillation (KD), a paradigm that aims to compress large deep neural networks (DNNs)—now dominating vision and language benchmarks—into smaller, efficient student models without significant loss in task performance. With the increasing scale of foundation models, LLMs, and vision-LLMs, efficient deployment mandates model compression strategies that preserve accuracy and generalization. KD, as a teacher-student transfer framework, has emerged as an advantageous alternative or complement to pruning, quantization, or architecture search due to its flexibility in extracting latent knowledge from cumbersome models. The paper surveys recent KD developments and organizes methodologies according to the source of knowledge, training scheme, distillation algorithm, data modality, and application domain, integrating newer advances largely unaccounted for in previous reviews.
Taxonomy and Organization
The authors propose an organizational schema unifying prior disparate perspectives into a multidimensional taxonomy (see (Figure 1)). This structure enables cross-comparison of techniques and highlights relationships among recent developments:
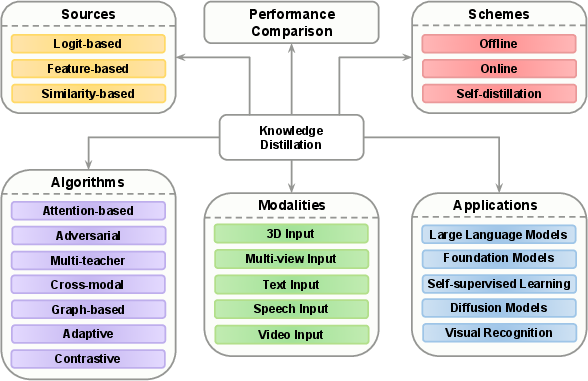
Figure 1: Diagram of the contents of this paper. Knowledge distillation is reviewed from different aspects, including sources, schemes, algorithms, modalities, and applications.
Distillation Sources
KD sources are categorized into logit-based (output distribution or soft targets), feature-based (intermediate representations), and similarity-based (pairwise or higher-order relations) methodologies ((Figure 2)). This tripartite breakdown clarifies distinctions among methods and their utility for different network architectures and tasks.
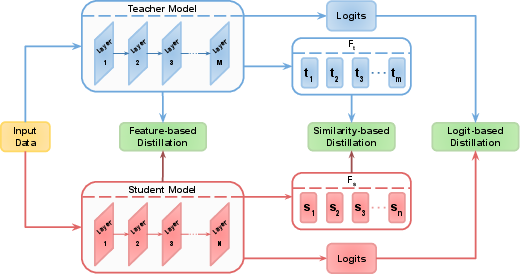
Figure 2: Illustration of the sources for distillation, including logits, features, and similarities. Logits are the model's last layer output, features are intermediate outputs of the model, and similarities are relationships between features, channels, samples, etc.
The survey demonstrates that feature and similarity-based distillation can transfer structural or contextual information overlooked by logits, a necessity for tasks with free-form outputs, non-classification endpoints, or cross-modal transfer. The review comprehensively analyzes advances in layer mapping, feature transformation, cross-layer/cross-modal alignment, and adaptive selection strategies for feature-based KD, as well as modern trends in instance-, channel-, and class-level similarity distillation.
Distillation Schemes
The comparison of offline, online, and self-distillation schemes ((Figure 3)) allows for a nuanced understanding of when and how teacher supervision is administered. Offline KD, with a pretrained and fixed teacher, is classified as the most widely used due to ease of implementation but is constrained by teacher capacity and biases. Online KD leverages simultaneous student-teacher co-optimization (including mutual and ensemble-based approaches), improving model flexibility in settings with no accessible large teacher. Self-distillation methods, where a model learns from its own earlier checkpoints, layers, or subcomponents, are critical to self-supervised and semi-supervised scenarios.
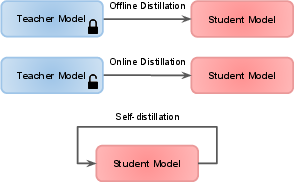
Figure 3: Illustration of distillation schemes. The teacher model in offline distillation is pre-trained and frozen, while in online distillation, the teacher and student are trained simultaneously. In self-distillation, the teacher and student are the same network.
Distillation Algorithms
The authors distinguish among attention-based, adversarial, multi-teacher, cross-modal, graph-based, adaptive, and contrastive distillation algorithms, each targeting specific transfer challenges. Attention-based methods transfer focus maps to encourage students to mimic salient regions or structures; adversarial distillation uses discriminator objectives for either privacy (e.g., data-free settings) or robust transfer; cross-modal distillation aligns information from rich-to-sparse modalities ((Figure 4)), and contrastive methods use representation-level discrimination to improve student discrimination ((Figure 5)). Notably, adaptive methods (e.g., curriculum distillation, dynamic weighting, teacher pruning) and multi-teacher strategies target architectural mismatches and distribution shift.
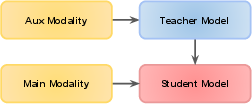
Figure 4: General overview of a cross-modal distillation method.
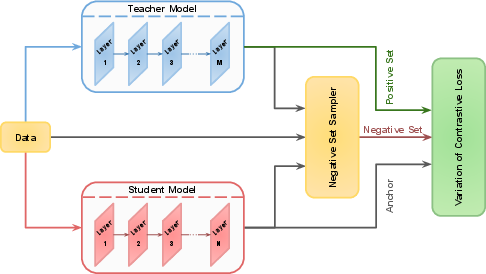
Figure 5: General overview of a contrastive distillation method. Embeddings of the teacher and student are considered as the positive set and anchor, respectively. The negative set can consist of embeddings from the teacher, student, or input data.
Modalities and Application Domains
KD's flexibility across data types is emphasized: the survey unifies treatments for 2D images, text, speech, video, 3D, and multi-view data. It extensively documents the evolution and adaptation of KD for emerging tasks, including 3D recognition and domain transfer ((Figure 6)), vision-LLMs, self-supervised learning, and diffusion-based generative modeling. The attention to KD in foundation models and LLMs is significant; the review catalogues white-box KD (with access to both logits and features) and black-box KD (only teacher outputs, relevant for closed/proprietary models), and outlines unique challenges and innovations in eg. chain-of-thought and instruction-following distillation strategies.
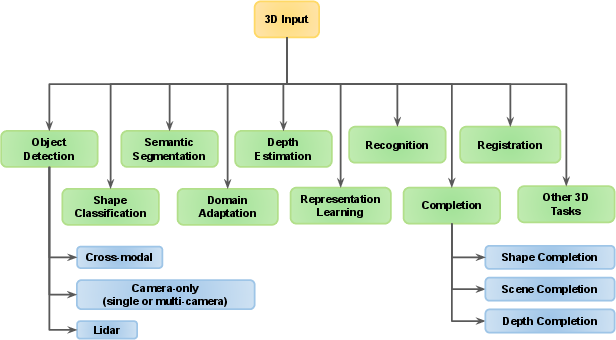
Figure 6: Overview of 3D domains and tasks.
Comparative Analysis
The meta-analysis collates and highlights strong empirical results in major benchmarks (e.g., CIFAR-100, ImageNet, Pascal VOC, and Cityscapes for vision; GLUE and downstream tasks for LLMs), demonstrating:
- With optimized feature-based or similarity-based KD, student networks can achieve within 0.5–2% of teacher accuracy while offering compression rates often exceeding 4–7×.
- Black-box KD of LLMs using chain-of-thought (CoT) reasoning delivers large language comprehension and reasoning capabilities to SLMs, attaining substantial gains (in some tasks, over 90% teacher performance; in others, SLMs even outperform teachers on select reasoning metrics via better fine-tuning).
- Robust KD (adversarial, privacy-preserving, multi-domain) is feasible through modified losses and teacher selection/pruning, supporting real-world deployment under security and fairness constraints.
The survey provides an explicit mapping from task requirements to recommended KD strategy, based on real-time constraints, available supervision, interpretability needs, compute budgets, and adversarial robustness.
Theoretical and Practical Implications
The paper underscores several unresolved research axes. Key challenges include capacity gap between teacher and student, architectural non-alignment, teacher bias transfer, and the limitations imposed by proprietary model APIs on black-box KD. The authors stress the importance of adaptive or curriculum-based loss weighting, teacher data augmentation, and hybrid sources (layer-wise remixing, feature aggregation, multi-stage meta-transfer) to mitigate these issues.
On the theoretical side, the review distinguishes between shallow transfer (logit-matching) and deeper functional transfer (hidden state/representation space alignment), warning that naive logit distillation is often insufficient for unsupervised, open-world, or non-classification problems. The expanding use of KD in privacy and fairness enhancement, as well as its combination with quantization, pruning, and architecture search, signals ongoing integration into holistic model compression and transfer frameworks.
Foundation Models, LLMs, and Broader Impacts
With the proliferation of foundation models and diffusion models, KD has become essential for model democratization and edge deployment. The authors catalogue the application and adaptation of KD to multi-modal fusion, prompt- and instruction-tuning, CoT transfer, and hierarchical teacher-student pipelines for both vision and language domains. Figures 9 and 10 provide illustrative overviews of the increasing diversity of foundation models and the salient points for knowledge extraction and transfer.
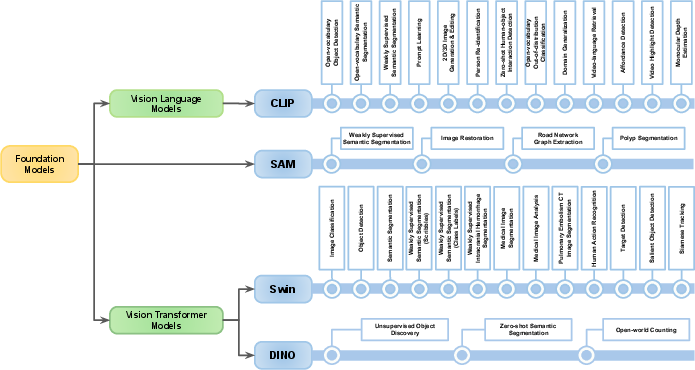
Figure 7: Categorization of foundation models based on their type, and the tasks for which their knowledge is distilled.
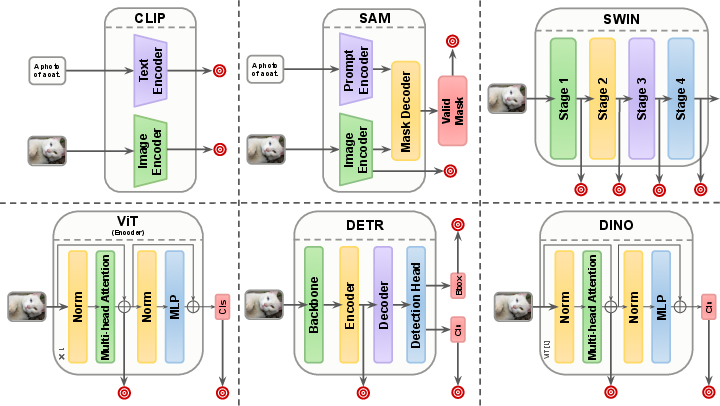
Figure 8: Architectural overview of prominent foundation models, indicating key points for data extraction and distillation to downstream tasks.
In LLMs, the review highlights the efficacy of distillation for attaining interpretability, cost/energy savings, and improved generalization in smaller models. The survey identifies two-phase strategies combining black-box (API) and white-box (open-source) KD to transfer closed model capabilities to open community models. This modular approach is likely to grow in significance as composite multi-modal models and retrieval-augmented generation continue to expand.
Conclusion
This comprehensive survey synthesizes and organizes the modern KD literature, offering a functional, multidimensional taxonomy. It emphasizes the role of feature and similarity-based KD for advanced tasks, the necessity for task- and resource-aware scheme and algorithm selection, and the necessity to adapt KD approaches for modern foundation models, 3D perception, and LLM deployment. The discussion section articulates open challenges, including privacy/security, fairness, teacher bias, architectural gap, and the evolving role of adaptive and contrastive techniques. Future directions will likely integrate KD more deeply with multi-stage model compression pipelines, personalized/continual learning, privacy-preserving training, and multi-modal learning, as well as methods for efficient knowledge transfer in the context of rapid model innovation and scaling.