Reaching Agreement Among Reasoning LLM Agents
Abstract: Multi-agent systems have extended the capability of agentic AI. Instead of single inference passes, multiple agents perform collective reasoning to derive high quality answers. However, existing multi-agent orchestration relies on static heuristic workflows such as fixed loop limits and barrier synchronization. These ad-hoc approaches waste computational resources, incur high latency due to stragglers, and risk finalizing transient agreements. We argue that reliable multi-agent reasoning requires a formal foundation analogous to classical distributed consensus problem. To that end, we propose a formal model of the multi-agent refinement problem. The model includes definitions of the correctness guarantees and formal semantics of agent reasoning. We then introduce Aegean, a consensus protocol designed for stochastic reasoning agents that solves multi-agent refinement. We implement the protocol in Aegean-Serve, a consensus-aware serving engine that performs incremental quorum detection across concurrent agent executions, enabling early termination when sufficient agents converge. Evaluation using four mathematical reasoning benchmarks shows that Aegean provides provable safety and liveness guarantees while reducing latency by 1.2--20$\times$ compared to state-of-the-art baselines, maintaining answer quality within 2.5%. Consistent gains across both local GPU deployments and commercial API providers validate that consensus-based orchestration eliminates straggler delays without sacrificing correctness.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about getting several AI “agents” (think of smart chatbots) to work together and agree on a good answer to a problem. Instead of trusting a single agent, the system lets multiple agents think in parallel, share their reasoning, and refine their answers over a few rounds. The challenge is deciding when the group has truly agreed on a reliable answer, and how to do that quickly without wasting computing time. The authors propose a formal way to define “agreement” for AI agents that can change their minds, and they build a new protocol and system—called Aegean—that reaches safe, fast agreement.
What questions did the paper ask?
- How can multiple AI agents, which are a bit random and may change their answers after discussion, reach a stable and correct agreement?
- When is it safe to stop and say, “This is the final answer,” without waiting forever or trusting a temporary majority that might flip next round?
- Can we design rules that ensure answers get better over time and the system always finishes?
- Can we implement these rules in a real system that runs faster and uses fewer resources than existing methods?
How did they approach it?
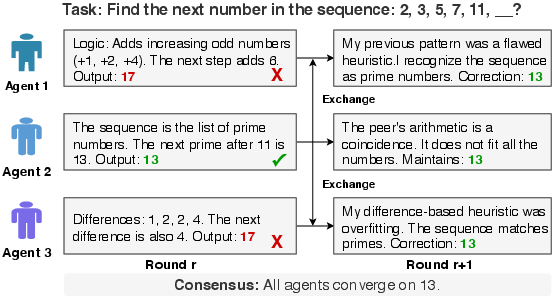
Why normal voting doesn’t work
Imagine three students solving a math problem:
- Round 1: Two say “17,” one says “13.”
- Round 2: After sharing their steps, one of the “17” students realizes a mistake and switches to “13,” so now two say “13.”
If you had stopped at Round 1 because a majority said “17,” you would have chosen the wrong answer. This shows that simple majority voting can be unstable: the top choice can flip after students see each other’s work.
New rules for agreement
The authors create a formal model with three simple guarantees:
- Safety: The committed answer must be at least as good as what most capable agents could produce on their own.
- Monotonicity: If the system outputs multiple answers over time, each later answer is at least as good as the earlier ones (answers never get worse).
- Liveness: The system will eventually finish and output an answer.
They explain this using a “Quality Oracle,” which you can imagine as an unbiased judge that scores how good an answer is. The system doesn’t know the judge’s score during the process, but it designs rules that make sure the final answer would score well.
A key assumption (backed by experiments) is “refinement”: when an agent sees others’ reasoning, it can improve or at least not get worse. In short, sharing good reasoning helps weaker agents, and stronger agents don’t adopt bad reasoning.
The Aegean protocol
Think of Aegean like a sports team with a captain:
- The captain (leader) runs the rounds.
- Each round, the captain sends all agents a set of the current best answers (plus reasoning).
- Agents read these, refine their own answers, and send them back.
- The captain looks for a “quorum” (enough agents agreeing) and keeps track across rounds.
Two tunable settings make agreement safer:
- Alpha (α): How many agents must agree on the same answer within a round (like “at least 2 out of 3”).
- Beta (β): How many consecutive rounds the same answer (or a very similar one) must appear before the system trusts it (like “the same answer should win two rounds in a row”).
This prevents committing to a temporary majority that flips next round. The leader can also change if needed (for reliability), and the protocol ensures that when a new leader takes over, it continues safely without losing progress.
The Aegean-Serve system
The authors built Aegean-Serve, a serving engine that:
- Watches agent answers as they stream in.
- Detects agreement early (without waiting for the slowest agent).
- Cancels slow or unnecessary agents once enough agreement is found, saving time and compute.
- Integrates with different AI backends using a simple interface (start an agent, get its result, cancel it if needed, and query ensemble status).
This avoids “barrier synchronization,” where you wait for everyone to finish each round, which wastes time because there’s always a straggler.
What did they find?
Across four reasoning benchmarks (GSM8K, MMLU, AIME, IMO), Aegean:
- Reduced average latency by 1.2× to 20× (it answers much faster).
- Cut worst-case tail latency (P99) by up to 11× (fewer very slow cases).
- Saved 1.1× to 4.4× tokens by stopping early when agreement stabilizes (cheaper).
- Kept accuracy within 2.5% of state-of-the-art baselines (so speed doesn’t sacrifice correctness).
These results held across local GPUs and commercial model APIs, and they show that consensus-based orchestration avoids delays caused by slow agents without finalizing bad answers.
Why does this matter?
- Better teamwork for AI: It gives AI agents a structured way to discuss and refine answers safely, like a well-run classroom or team meeting.
- Faster and cheaper: By stopping as soon as enough agents stably agree, the system uses fewer resources and responds quickly—important for real-time applications.
- More reliable: It reduces the risk of locking in a wrong answer due to a temporary majority, making multi-agent systems more trustworthy.
- Broad impact: As more AI systems use multiple agents to tackle complex tasks, these rules and tools can help them reach high-quality results consistently and efficiently.
In short, the paper turns messy group reasoning into a dependable process: it defines what “agreement” should mean for AI agents that can change their minds, proves that answers will improve and the system will finish, and delivers a practical system that’s both fast and accurate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- Quality oracle realism: The protocol’s guarantees depend on a deterministic Quality Oracle
Q, but practical evaluation of open-ended answers typically requires probabilistic or subjective judgment (e.g., LLM-as-judge), which is non-deterministic. Design and evaluate realistic surrogates forQthat preserve safety/monotonicity with quantifiable error rates. - Applicability beyond tasks with ground truth: The model and proofs implicitly fit tasks with well-defined correct answers (math benchmarks). Generalize the framework to tasks without single verifiable solutions (e.g., code synthesis, open-ended QA), including how to define and operationalize
Qand “equivalence” in those domains. - Assumption validation breadth: The “Reasoning Refinement” assumption is empirically validated on limited model pairs and datasets. Systematically test this assumption across broader agent heterogeneity (model families, instruction-tuning styles, languages), task types (symbolic vs. commonsense), and model sizes to uncover failure modes.
- Negative transfer and herd effects: Investigate conditions where exposure to peer traces degrades strong agents, induces mode collapse, or amplifies shared errors. Develop gating/robust aggregation mechanisms (e.g., trust scores, provenance checks) that prevent harmful refinement.
- Stability horizon (
β) calibration and theory: Provide sensitivity analyses and theoretical bounds that linkβto the probability of committing an incorrect answer under a stochastic agent model. Derive principled guidance for choosingβper task domain. - Similarity threshold (
α) reliability: The engine relies on semantic equivalence via embeddings and/or LLM-as-judge. Quantify false positive/negative rates, create task-adaptive similarity functions, and analyze howαaffects error/latency trade-offs. - Practical access to
Qvs. protocol guarantees: The protocol’s safety proofs useQ, which agents and coordinator do not access in practice. Bridge this theory-practice gap with implementable surrogates (formal verifiers, unit tests, constraint checkers) and show that guarantees degrade gracefully. - Quorum size selection and intersection: Formalize the quorum size
Rused in Aegean relative toNand fail-stop boundf, and prove intersection under all leader changes. Provide guidance for weighted or adaptive quorum when agents differ in reliability. - Byzantine/adversarial agents: The failure model is fail-stop only. Extend to Byzantine settings (malicious, colluding, or prompt-injected agents), analyze safety risks, and design defenses (Byzantine quorum, anomaly detection, diversity-preserving aggregation).
- Non-termination and oscillations: With
β > 1, multi-round persistence is required but not proven to eventually occur. Characterize conditions under which answers can oscillate or drift indefinitely (especially with multiple equally-good answers) and propose termination strategies that retain safety. - Multiple correct answers and tie-breaking: Clarify how the protocol handles genuinely non-unique solutions of equal quality. Provide tie-breaking rules consistent with monotonicity that avoid unnecessary rounds or instability.
- Leader bottlenecks and scalability: Analyze leader-based coordination overhead as
Ngrows (CPU/network bottlenecks, centralization risks), and explore scalable alternatives (hierarchical consensus, sharded ensembles, leaderless quorum). - Streaming consensus from partial outputs: The system claims incremental quorum detection “as answers stream,” but does not specify token-level agreement detection, partial-output equivalence, or rollback policies if early partial agreement flips. Develop robust streaming consensus methods.
- Context window constraints: Combining reasoning traces from many agents may exceed context limits. Design summarization, selection, or compression strategies that preserve refinement benefits while fitting model windows, and quantify their effect on safety and accuracy.
- Resource and scheduling details: The ensemble-aware scheduling section is incomplete. Provide concrete algorithms for admission control, preemption, KV cache partitioning across heterogeneous agents, and fairness across concurrent ensembles; evaluate throughput/latency trade-offs at scale.
- Costs and cancellations under real billing: Early cancellation improves latency, but cloud APIs may bill for partial generations or penalize aborts. Quantify economic impacts, and design policies that balance latency, accuracy, and cost across providers.
- Dynamic membership and churn: Real deployments face agent availability changes (rate limits, queueing, failures). Extend the protocol to handle dynamic
N, late joiners/leavers, and temporary unavailability without violating safety. - Heterogeneous agent weighting: Majority and stability treat agents uniformly. Investigate reliability-aware weighting (calibrated accuracy, uncertainty estimates, past performance) and its effects on safety, convergence, and latency.
- External verifiers and tool use: Integrate programmatic or domain-specific validators (symbolic solvers, unit tests) into the decision engine to constrain commitments, and measure how verification affects
α/βsettings and termination. - Multimodal and multilingual extension: The model assumes string-only inputs/outputs. Generalize to multimodal tasks (vision, code, tables) and multilingual ensembles, including how to define
Qand equivalence across modalities/languages. - Comprehensive benchmarks and statistical rigor: Provide full experimental details (N, α/β settings, model mix, dataset sizes), statistical significance, and failure case analyses (instances where Aegean finalized incorrect answers) to substantiate the “within 2.5%” accuracy claim.
- Reproducibility and open tooling: Release code, protocol specs, and decision engine implementations with parameter defaults; document integration steps with serving backends (e.g., vLLM), and provide ablation studies for each protocol component.
Glossary
- Aegean: A consensus protocol/framework for coordinating stochastic reasoning agents to reach stable agreement on refined solutions. "We present Aegean, a consensus framework that bridges non-deterministic reasoning and deterministic system guarantees."
- Aegean-Serve: A serving engine that embeds consensus logic into inference infrastructure to detect agreement early and cancel redundant work. "We implement the protocol in Aegean-Serve, a consensus-aware serving engine that performs incremental quorum detection across concurrent agent executions, enabling early termination when sufficient agents converge."
- Agent ensemble: A first-class scheduling unit representing a coordinated set of agents whose outputs are jointly evaluated. "We introduce the agent ensemble as a first-class scheduling primitive"
- Agreement monitor: A runtime component that tracks agent outputs to determine when quorum or stability conditions are met. "Its embedded agreement monitor tracks agent responses incrementally and evaluates quorum predicates as answers arrive, enabling early termination without barrier synchronization."
- Agreement permanence: A property in classical consensus where once a value is accepted by a majority, it remains committed permanently. "Classical consensus protocols like Paxos guarantee agreement permanence: Once a value is accepted by a majority of replicas, the value is permanently committed."
- Autoregressive generation: Token-by-token text generation where each token is sampled from a distribution conditioned on prior context. "LLMs generate outputs through autoregressive generation, where each token is drawn from a probability distribution conditioned on prior context."
- Barrier synchronization: A coordination pattern that forces all agents or processes to reach a point before any can proceed, often causing straggler-induced delays. "existing multi-agent orchestration relies on static heuristic workflows such as fixed loop limits and barrier synchronization."
- Consensus coordinator: The component responsible for maintaining protocol state and assessing agreement during execution. "The consensus coordinator maintains protocol state and detects quorum."
- Consensus instability: The phenomenon where majority support can shift between rounds as agents refine their reasoning, making naive majority voting unsafe. "Consensus is unstable; reasoning exchange can flip a majority from to between rounds and , rendering termination strategies unreliable."
- Distributed consensus: The problem of getting multiple independent processes to agree on a value despite failures and asynchrony. "We argue that reliable multi-agent reasoning requires a formal foundation analogous to classical distributed consensus problem."
- Fail-stop model: A failure model where a faulty agent halts and stops responding but never behaves incorrectly. "We target a fail-stop model in which a failed agent stops responding indefinitely but always follows the protocol precisely."
- Global stabilization time: The time after which a partially synchronous network behaves synchronously with bounded message delays. "there exists a finite but unknown period (commonly known as the global stabilization time) after which all messages are delivered within bounded delay."
- KV cache: Cached key/value tensors used by Transformer models to accelerate incremental decoding across tokens. "a memory manager that handles KV cache allocation across the heterogeneous agent pool."
- Leader election: A mechanism for agents to select a single leader responsible for coordinating rounds and decisions. "We use standard leader election protocols to elect a leader agent."
- Liveness: A guarantee that the protocol eventually makes progress to produce an output (does not deadlock). "Aegean provides provable safety and liveness guarantees while reducing latency"
- LLM ensemble: A set of LLM-based agents working together under the protocol to refine and agree on answers. "An Aegean deployment consists of agent processes, denoted where ranges from $0$ to , forming an LLM ensemble."
- LLM-as-judge: Using an LLM to assess equivalence or correctness of answers across rounds. "Equivalence across rounds is determined using exact match, LLM-as-judge, or both based on tasks."
- Majority intersection: The property that any two simple majorities overlap in at least one member, used to argue quality bounds. "By majority intersection, any majority of agents will include at least one strong agent."
- Majority optimal solution: The best-quality solution among those proposed by a simple majority of agents. "Suppose that each agent can individually generate a solution, a majority optimal solution is the best solution (evaluated by ) among the individual solutions generated by a simple majority of agents."
- Majority voting: A decision rule that selects the answer supported by the most agents. "The decision-making stage usually employs consensus mechanisms like majority voting"
- P99 tail latency: The 99th-percentile latency, capturing worst-case performance experienced by the slowest requests. "reduces average latency by 1.2--20× and P99 tail latency by up to 11× compared to state-of-the-art baselines."
- Partially synchronous: A network model where communication is eventually synchronous, but delays can be unbounded before stabilization. "The network is assumed to be partially synchronous"
- Quality Oracle: A deterministic function that evaluates the quality of a solution for a given task. "A Quality Oracle is a function () that takes two strings as input"
- Quorum: A sufficient subset of agents (e.g., a simple majority) whose agreement is enough to make or advance decisions. "The leader collects a quorum of #1{Solution} from unique agents (including from itself)"
- Quorum-based finalization: Committing results only when a quorum-based and stability-aware condition is satisfied. "introducing stability horizons and quorum-based finalization with provable safety and liveness guarantees."
- Quorum detection: Monitoring incoming agent outputs to determine when a quorum has been reached, enabling early stopping. "performs incremental quorum detection across concurrent agent executions"
- Quorum intersection property: The guarantee that any two quorums overlap, preserving safety across failures and rounds. "These protocols leverage the quorum intersection property to provide such a guarantee despite node failures and network asynchrony."
- Reasoning refinement: The capability of agents to improve their solutions by incorporating others’ reasoning traces without degrading quality. "We assume that all agents are capable of reasoning refinement"
- Refinement decision engine: The module that applies agreement criteria (e.g., similarity and stability thresholds) to decide when and what to output. "the protocol incorporates a modular refinement decision engine"
- Refinement Monotonicity: A property ensuring that later outputs are never lower quality than earlier ones. "Refinement Monotonicity: If a solution is outputted after solution (in real time), the quality of is at least as good (evaluated by ) as that of ."
- Refinement set: The set of solutions collected in a round that form the basis for the next round’s refinements. "The leader distributes the quorum refinement set from the previous round to all agents"
- Refinement Termination: The guarantee that some correct agent eventually outputs a solution. "Refinement Termination: Eventually, some correct agent outputs a solution ."
- Round-based stability: A commitment condition requiring that agreement persists across consecutive rounds before finalizing. "We formalize the first consensus model for stochastic multi-agent LLMs, establishing round-based stability as the necessary condition for safe commitment."
- Self-consistency: A technique that samples multiple reasoning paths from one model and selects the most frequent answer to improve reliability. "The self-consistency approach first explored this by sampling multiple reasoning paths from the same model and selecting the most frequent answer"
- Semantic equivalence: A criterion for treating answers as the same based on meaning rather than exact string match. "Semantic equivalence is evaluated using standard vector embedding similarity or exact match."
- Stability counter: A tally of consecutive rounds in which the candidate remains stable, used to trigger finalization at a preset threshold. "Finalization occurs when the stability counter reaches ."
- Stability horizon: The number of consecutive rounds a candidate must remain consistent before being safely committed. "introducing stability horizons and quorum-based finalization"
- Stragglers: Slow agents whose extended runtimes inflate overall latency when barrier synchronization is used. "incur high latency due to stragglers"
- Vector embedding similarity: A method that uses vector representations to measure semantic similarity between answers. "Semantic equivalence is evaluated using standard vector embedding similarity or exact match."
- View change protocols: Mechanisms for safely switching leaders/views while preserving system correctness. "The design resembles existing leader and view change protocols"
Practical Applications
Immediate Applications
The following applications can be deployed today by integrating Aegean and/or its serving engine (Aegean-Serve) into existing LLM stacks, multi-agent frameworks, or API-based services.
- Consensus-aware LLM orchestration for production chat and Q&A (Software, Customer Support, Enterprise IT)
- What: Replace majority-vote or fixed-loop multi-agent workflows with Aegean’s stability-aware consensus (α agreement threshold, β stability horizon) to reduce latency and token spend while maintaining answer quality.
- Tools/workflows: Aegean-Serve integrated with vLLM or commercial APIs; LangChain/AutoGen operators that stream agent outputs to a “quorum detector” and cancel stragglers.
- Assumptions/dependencies:
- Ability to normalize and compare answers (exact match, embedding similarity, or LLM-as-judge).
- Access to diverse agents/models to avoid mode collapse.
- Support for streaming and cancellation from serving layer or provider.
- Cost/latency optimization for multi-model ensembles (Cloud/AI Platforms, FinOps)
- What: Early quorum detection cancels slow agents once agreement stabilizes; reduces P99 latency and token costs by 1.1–4.4× (per paper).
- Tools/workflows: “EarlyQuorum” middleware between API clients and providers; per-round telemetry (quorum time, stability counters); dynamic α/β tuning by SLA tier.
- Assumptions/dependencies:
- Providers expose cancellation endpoints or short timeouts.
- Partial synchrony in networking (common in datacenter/API settings).
- Consensus-based content moderation and safety gating (Trust & Safety)
- What: Run multiple classifiers/reasoners and finalize only when a stable quorum agrees on allow/deny/rationale; reduces flip-flops and single-model bias.
- Tools/workflows: Aegean decision engine with task-specific equivalence rules; logs of stability horizons for audit.
- Assumptions/dependencies:
- Defined equivalence metrics for categorical decisions.
- Stability thresholds calibrated to desired false-positive/false-negative trade-offs.
- Multi-agent code generation and refactoring with stability guarantees (Software Engineering)
- What: Parallel agents propose patches/tests; finalize only when functionally equivalent solutions persist across rounds; prune stragglers.
- Tools/workflows: CI/CD step using Aegean to orchestrate agents; test-suite-as-quality proxy Q; early termination when tests pass across α agents for β rounds.
- Assumptions/dependencies:
- Availability of runnable tests as a proxy Quality Oracle Q.
- Sandboxed execution and normalized diffs to assess equivalence.
- Search/RAG answer consolidation with stable commitment (Enterprise Search, Knowledge Management)
- What: Multiple retrievers/LLMs propose answers; finalize when semantically equivalent answers persist; cancel remaining retrieval/generation.
- Tools/workflows: Aegean-Serve embedded in RAG pipeline; use embedding similarity thresholds; per-query dynamic α/β policy.
- Assumptions/dependencies:
- Reliable semantic equivalence metrics.
- De-duplication and normalization of citations/evidence.
- Clinical question answering prototypes with “stable agreement” guardrails (Healthcare; non-diagnostic support)
- What: For non-critical knowledge queries (e.g., guidelines lookup), combine multiple specialized models and commit only on stabilized consensus.
- Tools/workflows: α/β tuned for high precision; evidence-checking subagents; audit trail of refinement rounds.
- Assumptions/dependencies:
- Strict scoping to informational tasks (no autonomous diagnosis).
- Human-in-the-loop review; medically validated knowledge sources.
- Analyst copilot for finance/ops with conservative finalization (Finance, Business Intelligence)
- What: Multiple agents generate analyses and sanity checks; finalize only when majority persists; reduce exposure to single-run hallucinations.
- Tools/workflows: Aegean orchestration in BI tools; scenario subagents; stability horizon tied to risk tier.
- Assumptions/dependencies:
- Clear equivalence rules (e.g., numeric tolerance, KPI definitions).
- Human oversight for high-stakes decisions.
- Education/tutoring systems with step-by-step stable reasoning (Education)
- What: Agents deliberate over math/logic problems; commit explanations only when stability horizon is met; improves predictability for learners.
- Tools/workflows: Aegean decision engine with exact-match or unit-tested solutions; per-problem dynamic β (higher for harder tasks).
- Assumptions/dependencies:
- Testable answers or strong rubric for equivalence.
- Guardrails against leaking peer rationales to learners unless vetted.
- Evaluation racks for model selection and A/B tests (ML Ops, Research)
- What: Use α/β-based agreement stability to compare models/ensembles more fairly; avoids transient majority artifacts.
- Tools/workflows: Leader logs of rounds and quorum intersections; stability-adjusted win rates.
- Assumptions/dependencies:
- Consistent task normalization; fixed seeds not required due to protocol design.
- Incident response and investigation assistants (Security/IT Ops)
- What: Agents propose hypotheses and checks; finalize only on stable convergence; early exit when sufficient agreement detected.
- Tools/workflows: Playbooks as tasks; log-based equivalence; cancellation of long-running hypotheses after quorum.
- Assumptions/dependencies:
- Reliable normalization of hypotheses and evidence links.
- Human validation for remediation steps.
- API productization of “Consensus-as-a-Service” (AI Infrastructure)
- What: Expose a managed endpoint that orchestrates multi-agent consensus with configurable α/β; returns final answer + stability metadata.
- Tools/workflows: Thin client SDKs for Python/JS; usage-based billing by saved tokens/latency.
- Assumptions/dependencies:
- Backend support for streaming, cancellation, and aggregation.
Long-Term Applications
These applications require additional research, broader validation, regulatory alignment, or substantial engineering before widespread deployment.
- Clinical decision support with formal stability and provenance (Healthcare)
- What: Consensus-driven multi-agent reasoning with domain-calibrated α/β and provenance tracking for diagnostic support.
- Sector tools/workflows: EHR-integrated agents; stability-aware CDSS dashboards; audit trails meeting clinical governance requirements.
- Assumptions/dependencies:
- Domain-validated Quality Oracles (e.g., outcome-based metrics).
- Regulatory approvals; robust bias/variance assessments; adversarial testing.
- Autonomous trading/risk controls with monotonic commitment (Finance)
- What: Trading agents that only execute when projections stabilize; risk systems enforce β-round persistence for automated orders.
- Tools/workflows: Policy engines enforcing stability horizons; real-time cancelation of computation to meet market latencies.
- Assumptions/dependencies:
- Real-time equivalence for numeric forecasts; robust backtesting.
- Compliance approvals; circuit breakers around model drift.
- Safety-critical robotics and multi-robot planning (Robotics)
- What: Planners propose trajectories; finalize only upon stable consensus with formal monotonicity; cancel stragglers to meet control deadlines.
- Tools/workflows: Aegean-like consensus wrapped around stochastic planners (MPC/LLM-based); runtime monitors for β-persistent feasibility.
- Assumptions/dependencies:
- Real-time guarantees and deterministic safety layers.
- Extensions for byzantine robustness (adversarial agents).
- Scientific discovery pipelines with consensus-driven hypothesis refinement (Science/Pharma)
- What: Multi-agent hypothesis generation/refutation with stability-aware commitment to candidate models or experiments.
- Tools/workflows: LLM+symbolic agents; lab automation triggers only when β stability achieved; provenance and reproducibility logs.
- Assumptions/dependencies:
- Domain-specific Quality Oracles (e.g., simulation/test-based).
- Data access and validation at scale; human oversight.
- Regulatory and procurement standards: “stability horizon” requirements (Policy, GovTech)
- What: Define minimum α/β thresholds and logging requirements for AI systems in public procurement or critical services.
- Tools/workflows: Conformance tests; audit schemas for round histories; certification regimes.
- Assumptions/dependencies:
- Sector-specific calibration of thresholds and equivalence metrics.
- Legal frameworks for logging, privacy, and explainability.
- Cross-organization/federated agent consensus (Enterprise ecosystems)
- What: Multiple organizations’ agents reach stable agreement without sharing raw data; finalize decisions under partially synchronous, networked settings.
- Tools/workflows: Privacy-preserving consensus over reasoned summaries; secure leader election; federated logging.
- Assumptions/dependencies:
- Secure communication; privacy-preserving equivalence checks.
- Governance around failure models, accountability, and SLAs.
- Decentralized AI markets with consensus-based outcome quality SLAs (Web3/Marketplaces)
- What: Orchestrators purchase diverse agent outputs and only pay upon stable consensus; reputation scoring tied to stability contributions.
- Tools/workflows: On-chain proofs of α/β stability; incentive mechanisms for non-straggling behavior.
- Assumptions/dependencies:
- Verifiable logging; sybil resistance; robust-by-design against collusion.
- Standards for semantic equivalence in smart contracts.
- Standards for multi-agent evaluation and benchmarks (Academia, Standards Bodies)
- What: New benchmarks measuring stability horizons, refinement monotonicity, and straggler sensitivity across tasks and models.
- Tools/workflows: Public leader/round logs; datasets with known equivalence classes; evaluation harnesses implementing Aegean.
- Assumptions/dependencies:
- Community consensus on equivalence metrics and Q proxies.
- Diverse model access for ensemble realism.
- Byzantine-resilient consensus for adversarial agents (Security, High-stakes AI)
- What: Extend Aegean beyond fail-stop to handle malicious or colluding agents; quorum rules with intersection and trust-weighting.
- Tools/workflows: Reputation-weighted α; robust aggregation; anomaly detection in refinement rounds.
- Assumptions/dependencies:
- New theory/practice for non-deterministic byzantine participants.
- Richer telemetry to detect coordinated misbehavior.
- Multi-modal and tool-augmented consensus (Vision, Speech, Tools)
- What: Combine agents using different modalities/tools; require stability across heterogeneous outputs (images, tables, code runs).
- Tools/workflows: Modality-specific equivalence checkers; tool-executed Quality Oracles (e.g., unit tests, simulations).
- Assumptions/dependencies:
- Reliable cross-modal normalization.
- Execution sandboxes and dataset governance.
- Personal assistants aggregating multiple providers with stability thresholds (Consumer/Daily Life)
- What: Phones/browsers route queries to several providers; present an answer only after stable agreement; reduce flip-flops in recommendations or planning.
- Tools/workflows: Lightweight Aegean client; configurable α/β per user risk tolerance; on-device cancellation of network requests.
- Assumptions/dependencies:
- API access to multiple providers; latency acceptable for β horizons.
- Clear equivalence heuristics for everyday tasks (e.g., itinerary steps).
- Operational governance with monotonic update policies (Enterprise IT, Data)
- What: Policy changes or configuration updates applied only when multi-agent proposals stabilize; reduces oscillations in complex deployments.
- Tools/workflows: Change-management pipelines using Aegean; audit trail of refinement and finalization decisions.
- Assumptions/dependencies:
- Mapping from natural language proposals to normalized policy diffs.
- Human approval gates for high-impact changes.
Notes on Feasibility, Assumptions, and Dependencies
- Consensus stability relies on setting α (quorum size) and β (stability horizon) appropriate to task risk and cost/latency budgets.
- Practical proxies for the Quality Oracle Q are required (e.g., exact match, unit tests, numerical tolerance, rubric-based LLM-as-judge); quality of these proxies directly impacts outcomes.
- Reasoning Refinement Assumption: Agents improve or maintain quality when exposed to better peer rationales; empirically supported in the paper but may degrade with highly homogeneous ensembles or adversarial traces.
- Infrastructure needs:
- Streaming outputs and cancellation support in serving stack (e.g., vLLM, provider APIs).
- Normalization and semantic-equivalence tooling (tokenization, embeddings, judge LLMs).
- Logging for terms/rounds/quorums to enable monotonicity guarantees and audits.
- Network and failure model: Partially synchronous network and fail-stop failures align with most cloud deployments; byzantine robustness is a future extension for adversarial settings.
- Diversity matters: Heterogeneous models/temperatures/decoding strategies improve convergence and reduce shared blind spots; single-family ensembles may yield unstable or biased consensus.
Collections
Sign up for free to add this paper to one or more collections.