Assessing the Software Security Comprehension of Large Language Models
Abstract: LLMs are increasingly used in software development, but their level of software security expertise remains unclear. This work systematically evaluates the security comprehension of five leading LLMs: GPT-4o-Mini, GPT-5-Mini, Gemini-2.5-Flash, Llama-3.1, and Qwen-2.5, using Blooms Taxonomy as a framework. We assess six cognitive dimensions: remembering, understanding, applying, analyzing, evaluating, and creating. Our methodology integrates diverse datasets, including curated multiple-choice questions, vulnerable code snippets (SALLM), course assessments from an Introduction to Software Security course, real-world case studies (XBOW), and project-based creation tasks from a Secure Software Engineering course. Results show that while LLMs perform well on lower-level cognitive tasks such as recalling facts and identifying known vulnerabilities, their performance degrades significantly on higher-order tasks that require reasoning, architectural evaluation, and secure system creation. Beyond reporting aggregate accuracy, we introduce a software security knowledge boundary that identifies the highest cognitive level at which a model consistently maintains reliable performance. In addition, we identify 51 recurring misconception patterns exhibited by LLMs across Blooms levels.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About (Overview)
This paper asks a simple but important question: How well do today’s AI chatbots (the kind that can write and explain code) actually understand software security—the art of keeping software safe from hackers?
The authors built a test system, called Basket, to check what these AIs really know, from basic facts to designing secure systems. They tested several popular models using problems that feel like real school and real-world tasks.
What The Researchers Wanted To Find Out (Goals)
The study focused on two big ideas:
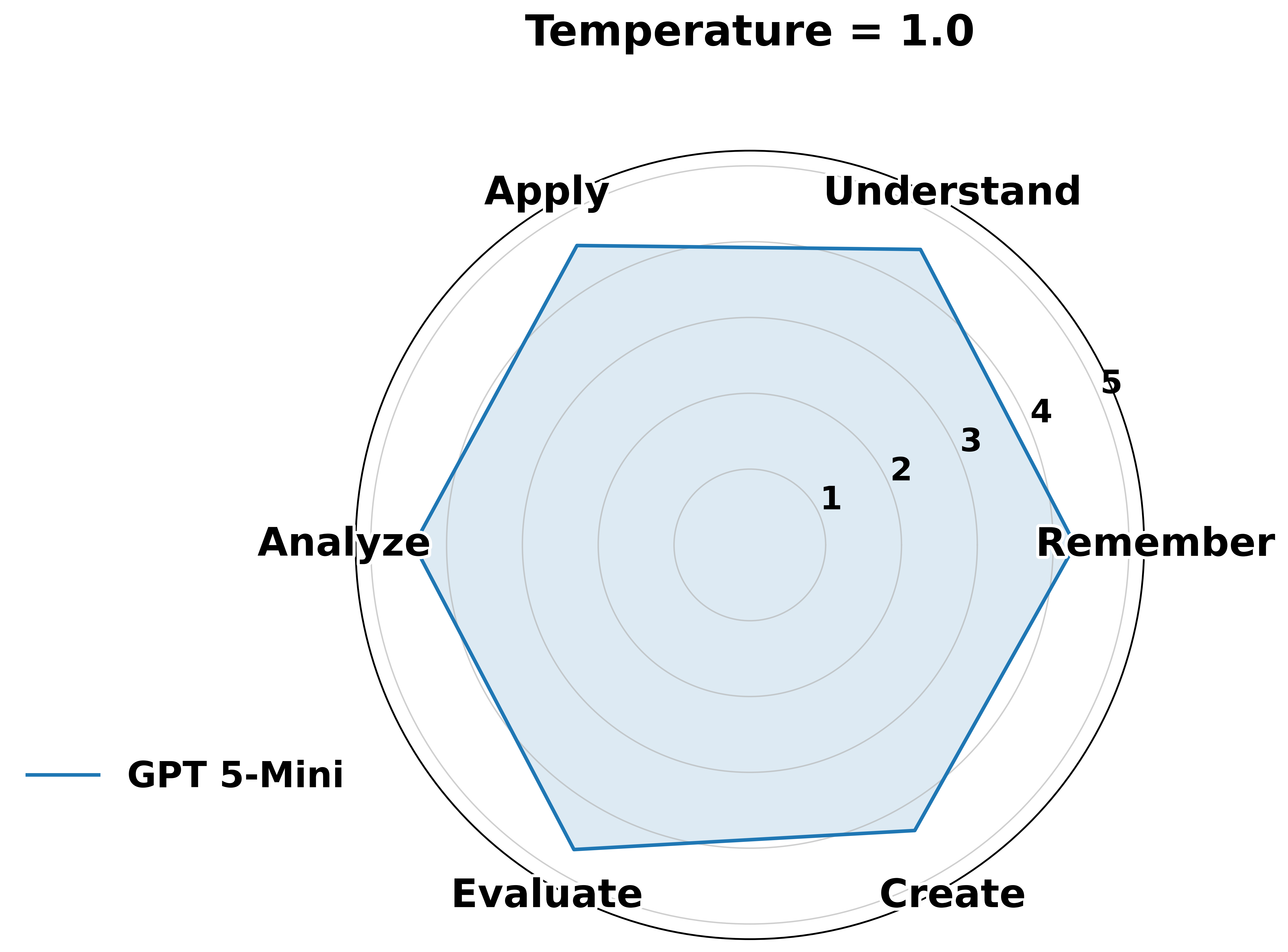
- How good are AI models at software security across different thinking levels—from remembering facts to creating secure designs?
- Where is each model’s “knowledge boundary”—the highest level it can handle reliably before it starts making confident but wrong answers?
To guide this, they used Bloom’s Taxonomy, which is like a ladder of thinking skills:
- Remember: recall facts
- Understand: explain ideas
- Apply: use knowledge to solve a problem
- Analyze: break things down and find causes
- Evaluate: judge options and make trade-offs
- Create: design something new and secure
How They Tested the AIs (Methods, in Simple Terms)
Think of it like testing students in a class, but the “students” are AI models. The team built a mix of tasks that matched each step of the thinking ladder:
- For Remembering: multiple-choice questions about common security terms and ideas (like “What is SQL injection?”).
- For Understanding and Applying: short, buggy code snippets where the AI had to find the security problem and explain or fix it.
- For Analyzing: “why” questions about the root cause of a vulnerability and how it spreads in code.
- For Evaluating: real-world mini case studies of web apps with multiple weaknesses—AI had to judge risks and defenses.
- For Creating: open-ended projects, like proposing a secure design or a full mitigation plan.
They pulled these tasks from:
- Curated multiple-choice sets (from online courses and websites)
- A dataset of real vulnerable code examples (SALLM)
- Course quizzes from an “Introduction to Software Security” class
- Realistic web app case studies with known bugs (XBOW)
- Project-style tasks from a “Secure Software Engineering” course
They scored not just right/wrong, but also looked at the kinds of mistakes AIs make, building a list of 51 common misunderstandings.
What They Found (Main Results)
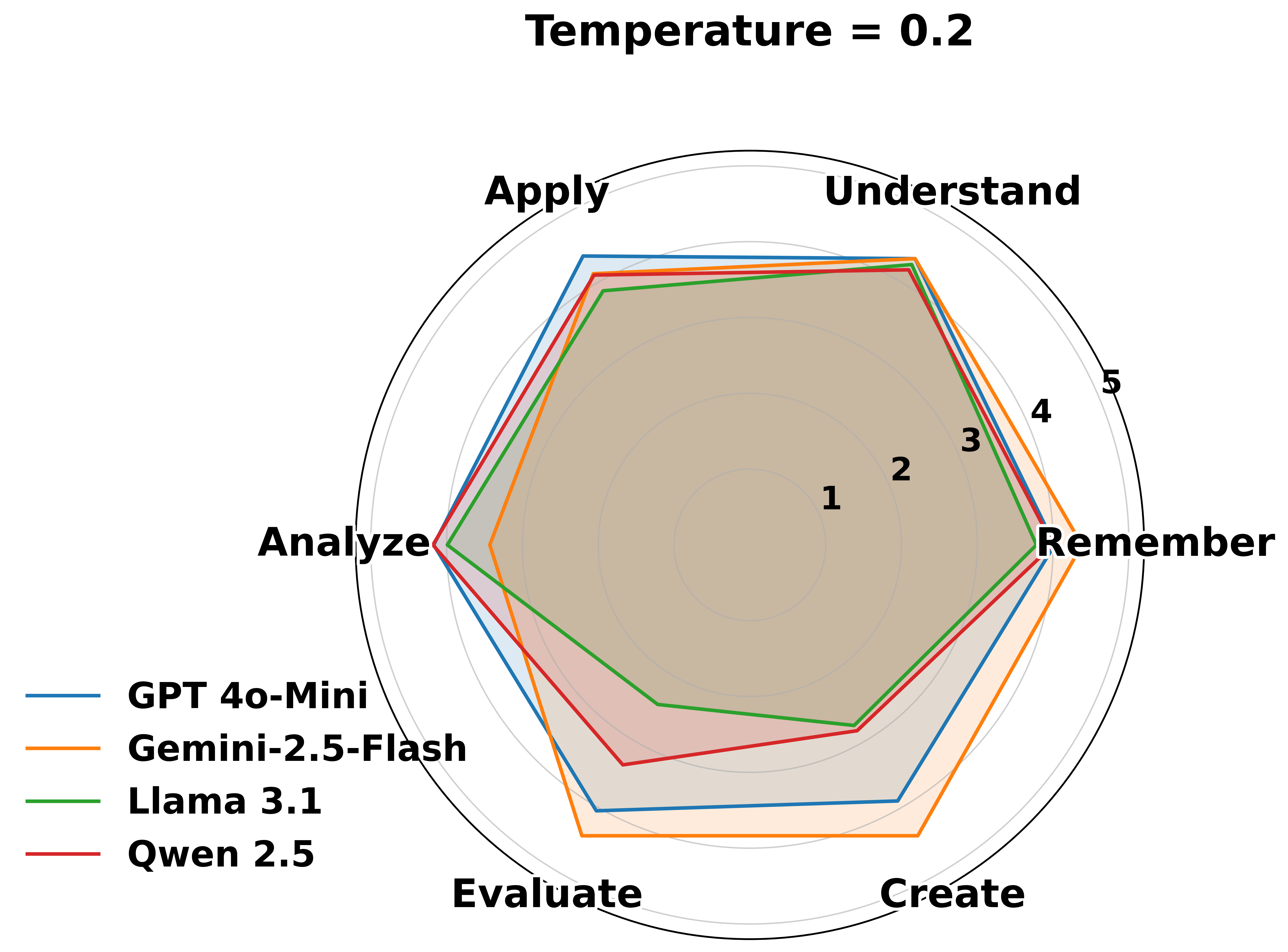
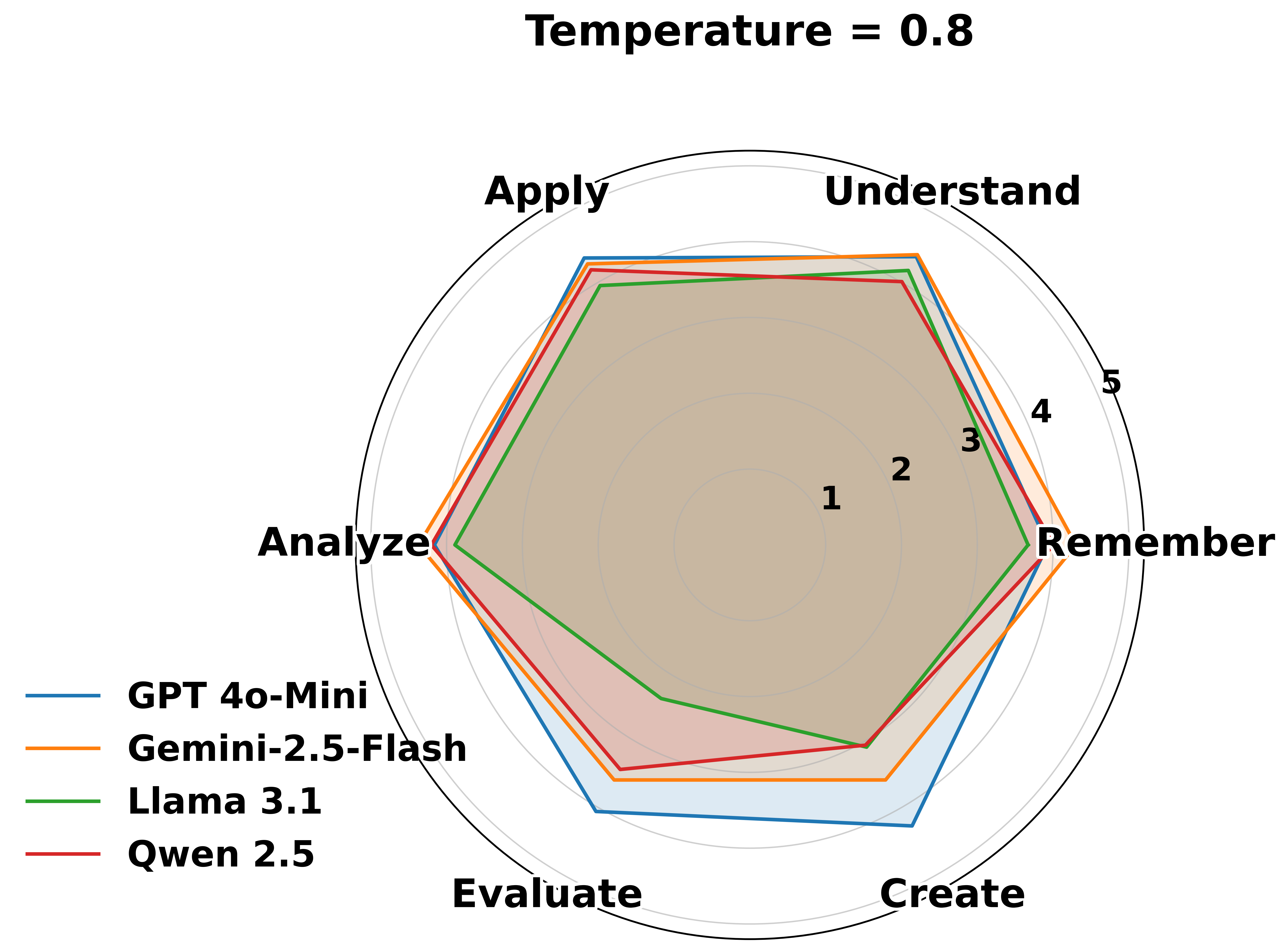
- Strong at basics, weak at deep thinking:
- The AIs did well at lower levels—remembering facts, explaining known concepts, and fixing simple, well-known bugs.
- Performance dropped a lot at higher levels—analyzing systems, comparing defenses, and especially designing secure solutions from scratch.
- “Knowledge boundary” matters:
- Each model had a clear ceiling—the highest level where it stayed consistently reliable. Above that, it started to sound confident but made mistakes or missed key security details.
- Recurring misunderstandings:
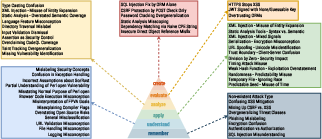
- The researchers found 51 repeated “misconception patterns”—for example:
- Mixing up similar vulnerabilities (like different types of injection)
- Assuming a single fix (like input validation) stops all attack paths
- Overtrusting tools or libraries without checking limits
- Ignoring system-wide issues (like authentication flow or threat models)
- Offering fixes that help functionality but don’t truly fix the security flaw
Why this is important: In security, a “plausible but wrong” explanation can be dangerous. If students or developers trust these answers, they might build systems that look safe but aren’t.
Why This Matters (Implications)
- For students and self-learners: AI can be a helpful study buddy for definitions, quick explanations, and simple bug fixes. But for deeper design and system-level security, you still need human guidance and verified materials.
- For developers: Treat AI outputs like junior assistant suggestions—review carefully, test thoroughly, and don’t rely on them to architect security.
- For teachers and researchers: The Basket framework shows a better way to measure “real understanding,” not just task scores. The 51-item misconception list can help design better lessons, warnings, and tools.
- For AI builders: Improving models isn’t just about more data—it’s about teaching them to reason about systems, know when they don’t know, and avoid sounding confident when they’re unsure.
In short: Today’s AIs are good at remembering and explaining common security topics and fixing simple issues, but they struggle with big-picture security thinking. Knowing their limits helps everyone use them safely and wisely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper. Each item is framed to be concrete and actionable for future research.
- Methodological transparency in prompting: The paper does not specify prompt design, sampling temperature, decoding strategies, or use of few-shot/contextual examples across Bloom levels, making reproducibility and fairness across models unclear. Define a standardized prompting protocol and report hyperparameters for all tasks.
- Validation of Bloom-level mappings: Item-to-level assignments (L2–L4 in Course A; L6 in Course B; others) were done by authors but lack inter-rater reliability statistics and psychometric validation. Establish expert panels, compute agreement metrics (e.g., Cohen’s/Fleiss’ kappa), and use item response theory to validate construct alignment.
- Scoring rubrics for higher-order tasks (L5–L6): The evaluation criteria for case studies and open-ended projects are not detailed (e.g., threat coverage, trade-off reasoning, feasibility, justification quality). Develop transparent, multi-criteria rubrics and measure inter-rater reliability.
- Operational definition of “knowledge boundary”: The threshold for “consistent, reliable performance” per Bloom level is not specified (e.g., accuracy cutoffs, stability under re-prompting, calibration). Formalize boundary metrics that include accuracy, stability under paraphrase, abstention behavior, and uncertainty calibration.
- Prompt-sensitivity and stability checks: The study does not explore how small changes in task wording affect performance or boundary placement. Conduct paraphrase, adversarial prompt, and context-variation experiments to quantify boundary robustness.
- Data contamination audits: Although MCQs were paraphrased, other datasets (SALLM, XBOW, course materials) may be present in training corpora. Perform contamination detection (e.g., fuzzy matching, n-gram overlap, source provenance checks) and report contamination-adjusted scores.
- Coverage limitations of software security KA: The evaluation focuses on Python and web vulnerabilities; key areas like memory safety in C/C/C++, concurrency, mobile/IoT, cloud-native architectures, secure protocols, and hardware-related software security are underrepresented. Expand to broader CyBOK Software Security subdomains and diverse languages/platforms.
- Tool use and dynamic analysis: Models appear to be evaluated in text-only mode without integration with SAST/DAST, interpreters, or execution environments. Study tool-augmented LLMs and quantify gains in L3–L6 tasks when coupled with analyzers/runtimes.
- Uncertainty calibration and overconfidence: The paper raises overconfidence concerns but does not measure calibration (e.g., Brier score, ECE) or abstention rates. Assess confidence estimates, willingness to say “I don’t know,” and alignment between confidence and correctness across Bloom levels.
- Educational impact via user studies: The paper argues LLMs may instill misconceptions but does not test this with learners. Run controlled studies to measure learning outcomes, misconception persistence, and remediation strategies when LLMs are used as tutors.
- Mitigation strategies for misconceptions: While a 51-item misconception taxonomy is presented, there is no evaluation of interventions (e.g., misconception-aware prompts, targeted feedback, retrieval augmentation, fine-tuning). Design and test remediation pipelines and measure improvements per misconception category.
- Risk-based evaluation: All errors appear to be treated equally; security severity (e.g., critical exploit vs. minor issue) is not weighted. Introduce risk-weighted scoring to prioritize high-impact vulnerabilities in evaluation and boundary estimation.
- MCQ quality and representativeness: Internet- and MOOC-sourced MCQs may be biased or poorly constructed; multiple-response items require careful scoring. Build expert-authored, validated MCQs aligned to CyBOK and apply psychometric analyses (difficulty, discrimination).
- XBOW selection bias and difficulty calibration: The greedy set cover selection of 26 projects may skew difficulty and vulnerability distribution. Validate difficulty tiers, ensure balanced coverage, and analyze performance stratified by complexity.
- Long-context and multi-step reasoning constraints: L6 tasks are multi-part projects; the paper does not detail context lengths, chunking strategies, or effects of long-context handling on performance. Evaluate models’ long-context limits and multi-step planning under realistic project conditions.
- Comparison against domain-tuned models: Only general-purpose instruction-following LLMs are reported; security-specialized or code-specialized models (e.g., CodeLlama variants, domain-fine-tuned security LLMs) are not benchmarked. Include domain-specific baselines to test the benefit of specialization.
- Multimodal security inputs: Threat models, architecture diagrams, logs, and traces are common in security practice; the evaluation appears text/code-only. Incorporate multimodal inputs and assess system-level reasoning in L5–L6 tasks.
- Ethical and safety considerations: The study does not address risks of generating exploit instructions or insecure code in the evaluation pipeline. Define safety constraints and measure the tendency to produce harmful outputs, along with guardrail effectiveness.
- Metrics beyond accuracy: Explanation faithfulness, step-wise reasoning consistency, and architectural evaluation quality are not measured. Add metrics for reasoning soundness (e.g., rationale correctness, plan feasibility) to diagnose higher-order failures.
- Cross-language generalization: Python-centric evaluation may not capture memory safety/concurrency issues prevalent in C/C++/Rust. Create language-diverse benchmarks and analyze transferability.
- Task-level transferability analysis: It’s unclear whether performance on MCQs predicts outcomes on SALLM/XBOW or L6 projects. Quantify cross-task correlations to understand whether lower-level success translates to higher-order competence.
- Misconception taxonomy validation and utility: The 51-pattern taxonomy lacks validation details (e.g., sampling, coder agreement, prevalence across models) and practical integration pathways. Validate the taxonomy, publish detailed exemplars, and test its use in training, RAG, and targeted evaluations.
- Dataset scale inconsistencies: SALLM is described as 100 prompts, but Table reports 800 tasks; this inconsistency needs clarification. Reconcile task counts and provide a detailed breakdown per Bloom level and dataset.
- Dialogue-based tutoring evaluation: The study evaluates single-shot/task responses; tutoring occurs over multi-turn dialogues. Assess interactive, step-wise tutoring scenarios and measure misconception propagation dynamics.
- Real-world system-scale assessment: XBOW offers small projects; the study does not evaluate large open-source systems or enterprise microservices/cloud deployments. Extend to repo-scale, multi-service systems to test L5–L6 at realistic complexity.
- Standards and policy comprehension: OWASP ASVS, NIST, and compliance frameworks are central to secure development; their comprehension and application are not evaluated. Add standards-driven tasks to L4–L6 assessments.
- Adversarial robustness: Robustness against jailbreaks, prompt attacks, or misleading contexts is not measured. Evaluate adversarial resilience specific to security tasks and its impact on the knowledge boundary.
Practical Applications
Overview
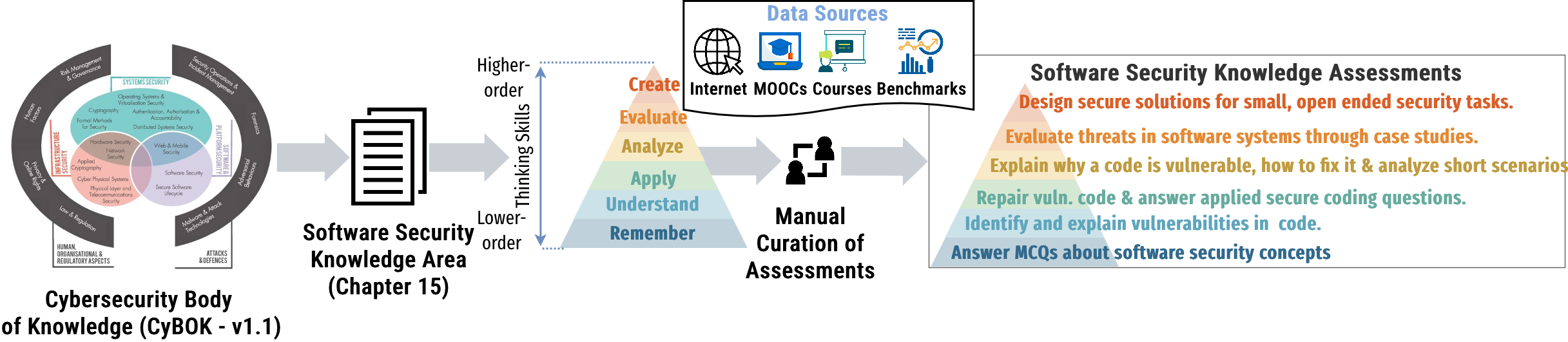
This paper introduces Basket, a Bloom’s Taxonomy–guided framework for evaluating LLMs’ (LLMs) software security knowledge across six cognitive levels (remember, understand, apply, analyze, evaluate, create). It aggregates multiple datasets (paraphrased MCQs, SALLM vulnerable code, course quizzes, real-world XBOW case studies, and open-ended secure engineering projects), defines an operational “software security knowledge boundary” per model, and catalogs 51 recurring misconception patterns. Findings show that current LLMs are reliable on lower-order tasks (recall, identification, basic fixes) but degrade significantly on higher-order reasoning (architecture evaluation, trade-off analysis, secure system design).
Below are actionable, real-world applications derived from these findings and artifacts.
Immediate Applications
Software and Cybersecurity (Industry)
- LLM capability gating in the SDLC
- Use Basket to profile an LLM’s software security knowledge boundary and gate tasks accordingly (e.g., allow L2–L3 “identify and fix simple code issues,” but require human review for L4–L6 analysis/design).
- Tools/workflows: CI/CD gate that tags PRs with Bloom level; “boundary badge” in IDE assistants; routing of high-order security items to security engineers.
- Assumptions/dependencies: Access to Basket test harness and datasets; alignment of Bloom levels to your org’s SDLC task taxonomy; ongoing re-evaluation as models update.
- “Security output linter” for LLM assistance
- Build a post-processor that detects the paper’s 51 misconception patterns in LLM-produced advice/code and flags risky guidance before it reaches developers.
- Tools/products: IDE plugin or chat wrapper highlighting likely misconceptions (e.g., misuse of cryptography, authentication oversimplifications).
- Assumptions/dependencies: Availability and maintenance of the misconception taxonomy; false positives kept manageable.
- Procurement and vendor due diligence for AI coding tools
- Require vendors to disclose their models’ software security knowledge boundary (by Bloom level) as part of RFPs and SLAs.
- Tools/workflows: Intake checklist; reproducible Basket-based evaluation scripts; red-team reports tied to Bloom levels.
- Assumptions/dependencies: Vendor cooperation; standardized reporting format.
- Prompting and abstention policies for secure use
- Deploy prompt templates and guardrails that trigger abstention or human handoff when user requests are likely L4–L6 (e.g., “design a secure architecture,” “evaluate threat model”).
- Tools/workflows: Prompt router; risk-aware system message policy with boundary-aware escalation.
- Assumptions/dependencies: Reliable boundary detection for your model and domain; clear escalation paths.
- Risk-aware code review augmentation
- Pair static/dynamic analyzers (SAST/DAST) with LLMs only for L2–L3 tasks; enforce human sign-off for L4–L6 findings and fixes.
- Tools/workflows: SAST/DAST orchestrator invoking LLMs for explanatory summaries or simple remediations; PR labels by Bloom level.
- Assumptions/dependencies: Good CWE coverage; mapping between analyzer findings and Bloom levels.
- Targeted developer upskilling
- Use misconception taxonomy to create micro-trainings that inoculate engineers against common LLM-driven security errors (e.g., unsafe parameterization, misapplied hashing).
- Tools/products: Just-in-time training snippets surfaced when a misconception is detected in code reviews or chat.
- Assumptions/dependencies: Training content aligned to org stack; buy-in from teams.
Academia and Education
- Curriculum-aligned AI tutoring policies
- Align LLM tutor usage with Bloom levels: permit use for L1–L2 explanations/exercises; enforce scaffolds and reflection for L3; restrict or proctor L4–L6.
- Tools/workflows: Course policy statements; LMS-integrated boundary checks; rubric mapping to Bloom levels.
- Assumptions/dependencies: Instructor training; student compliance.
- Assessment design and validation
- Use Basket to create and validate quiz banks and projects by Bloom level; paraphrase to reduce contamination; compare student vs. LLM misconceptions.
- Tools/products: Question banks tagged by Bloom level; automated parity checks of LLM vs. student errors.
- Assumptions/dependencies: Access to the replication package; psychometric checks for your cohort.
- Safer AI-based code help in courses
- Wrap LLMs with the “security output linter” to prevent propagation of misconceptions in labs and assignments.
- Tools/workflows: LMS plugin or coding sandbox integration that flags risky advice in real time.
- Assumptions/dependencies: Integration effort; acceptable latency overhead.
Policy, Governance, and Compliance
- Internal AI-use standards for secure development
- Establish policies stating which Bloom levels are permissible for LLMs in security-critical workflows and when human review is mandatory.
- Tools/workflows: AI risk register entries; control mappings to ISO/IEC 27001, NIST SSDF, and SOC-2.
- Assumptions/dependencies: Policy adoption; auditability of boundary evidence.
- Disclosure and labeling
- Label AI developer tools with their validated software security knowledge boundary (e.g., “reliable up to L3-Apply”) to set user expectations.
- Tools/products: Product safety labels; documentation templates.
- Assumptions/dependencies: Agreement on a standard label; periodic re-validation.
Daily Practice for Developers and Learners
- “Know when not to use the model”
- Provide a simple checklist that maps task type to Bloom level and indicates whether to trust the model or escalate (e.g., “threat modeling → escalate”).
- Tools/products: Dev wiki page; IDE cheat-sheet pane.
- Assumptions/dependencies: Team adoption; accurate task-to-level mapping.
- Safer study and exam prep
- Use paraphrased MCQs and L2/L3 exercises for practice; avoid relying on LLMs for open-ended design justifications without instructor feedback.
- Tools/workflows: Personal spaced-repetition cards (L1/L2); peer review for L4–L6 artifacts.
- Assumptions/dependencies: Access to curated questions; instructor guidance for higher levels.
Long-Term Applications
Software and Cybersecurity (Industry)
- Certification of AI coding assistants for secure development
- Create third-party certification programs that test AI tools against Basket-like suites and certify maximum Bloom level reliability per security domain (web, cloud, mobile).
- Tools/products: Independent labs; periodic re-cert processes; public registries.
- Assumptions/dependencies: Industry consortium support; standardized benchmarks across languages and stacks.
- Boundary-aware autonomous remediation
- Develop systems that automatically fix L2–L3 vulnerabilities while explicitly abstaining at L4–L6, generating tickets with rationale and risk context for humans.
- Tools/workflows: DevSecOps orchestration; “abstain-with-context” patterns; integration with ticketing systems.
- Assumptions/dependencies: High precision on fix eligibility; robust rollbacks; governance.
- Misconception-resistant model training
- Fine-tune or align models to correct the 51 misconception patterns and to calibrate uncertainty/abstention when nearing their boundary.
- Tools/products: RLHF datasets derived from the taxonomy; self-consistency and selective prediction training.
- Assumptions/dependencies: Access to training pipelines; risk of overfitting; generalization to new CWE families.
- Cross-language and cross-domain expansion
- Extend Basket to C/C++, Rust, Java, mobile, IoT, embedded, and cloud-native security to support broader enterprise stacks.
- Tools/workflows: New vulnerable corpora; multi-language test harnesses; domain adapters.
- Assumptions/dependencies: Availability of high-quality, diverse datasets; expert labeling.
Academia and Education
- Adaptive AI tutors with boundary awareness
- Build tutors that detect when a student’s prompt requires L4–L6 reasoning and shift to Socratic scaffolding, exemplars, and human-in-the-loop review.
- Tools/products: Boundary-aware tutoring platforms; learning analytics tied to Bloom levels.
- Assumptions/dependencies: Reliable boundary detection at the dialogue level; institutional deployment.
- Concept-inventory–driven curriculum evolution
- Use longitudinal analytics of LLM vs. student misconceptions to redesign instruction, labs, and assessments for durable security understanding.
- Tools/workflows: Department-wide dashboards; A/B testing of curricular interventions.
- Assumptions/dependencies: Data governance and privacy; faculty resources.
Policy, Governance, and Compliance
- Regulatory guidance for AI use in high-stakes sectors
- Develop sector-specific guidelines (healthcare, finance, energy, gov) that mandate boundary-aware use of LLMs in secure development and require abstention/oversight at higher Bloom levels.
- Tools/products: NIST-style special publications; ENISA/ISO technical reports; procurement clauses.
- Assumptions/dependencies: Multistakeholder alignment; harmonization with existing secure-by-design guidance.
- Incident accountability and audit trails
- Require audit logs that record the Bloom level of AI-involved security tasks, boundary status, and human review, supporting post-incident analysis.
- Tools/workflows: AI activity logging standards; evidence collection for audits.
- Assumptions/dependencies: Tooling support; privacy and legal considerations.
Daily Practice for Developers and Learners
- Personal AI “coach” with safe defaults
- Boundary-aware assistants that automatically avoid giving high-order security prescriptions, instead offering references, checklists, and “questions to ask a human reviewer.”
- Tools/products: Browser/IDE extensions; mobile study apps.
- Assumptions/dependencies: High-quality reference content; user trust and adherence.
- Community-maintained misconception playbooks
- Living repositories of common LLM security pitfalls and “correct patterns,” linked to examples in various languages and frameworks.
- Tools/workflows: Open-source playbooks; curated PR reviews with before/after fixes.
- Assumptions/dependencies: Active maintainer community; continuous updates.
Notes on Feasibility and Dependencies
- Scope limitations: Current evaluation centers on the Software Security KA (CyBOK) and is strongest for Python/web contexts; broader domains require new datasets and expert validation.
- Model drift: Knowledge boundaries can change with model updates; periodic re-validation is essential.
- Data quality and contamination: Paraphrasing mitigates leakage, but new datasets must maintain similar rigor; psychometric validation improves reliability.
- Human-in-the-loop: Higher-order security decisions should remain human-led for the foreseeable future, especially in regulated or safety-critical sectors.
- Standardization: Widespread uptake benefits from shared reporting formats, benchmarks, and labels for “maximum reliable Bloom level” by domain.
Glossary
- Abstention mechanisms: Methods that enable a model to refrain from answering when uncertain to reduce errors in high-stakes contexts. "abstention mechanisms as a practical mitigation for boundary failures"
- Ambiguous answer sets: Collections of multiple plausible answers used to study model behavior on semi-open-ended questions. "ambiguous answer sets (via auxiliary models)"
- Automated Program Repair (APR): Techniques that automatically detect and fix bugs or vulnerabilities in source code. "automated program repair (APR)"
- Bloom’s Taxonomy: A hierarchical framework for categorizing cognitive skills from remembering to creating, used to structure learning objectives and assessments. "Bloomâs Taxonomy"
- Common Weakness Enumeration (CWE): A standardized catalog of software vulnerability types used for classification and benchmarking. "Common Weakness Enumeration Taxonomy (CWE)"
- Concept inventory: A validated assessment instrument designed to identify persistent, domain-specific misconceptions. "Concept inventories provides a methodological foundation for systematically identifying recurring patterns of incorrect reasoning"
- Cyber Security Body of Knowledge (CyBOK): An organized compendium of cybersecurity knowledge areas that defines core concepts and practices in the field. "Cyber Security Body of Knowledge (CyBOK) v1.1"
- Data contamination: When evaluation items appear in a model’s training data, potentially inflating reported performance. "training data contamination"
- Dynamic Application Security Testing (DAST): Security testing performed against a running application to detect vulnerabilities through dynamic analysis. "Dynamic Application Security Testing (DAST)"
- Greedy set cover algorithm: A heuristic that iteratively selects the set covering the largest number of remaining elements to achieve coverage with minimal sets. "greedy set cover algorithm (i.e. iteratively picking the project that covers the largest number of uncovered vulnerabilities)"
- Insecure Direct Object Reference (IDOR): A vulnerability where user-supplied input directly references internal objects, enabling unauthorized access. "Insecure Direct Object Reference (IDOR)"
- Inter-procedural vulnerabilities: Security issues that arise from interactions across multiple functions, modules, or components rather than within a single procedure. "inter-procedural vulnerabilities"
- Knowledge boundary: The frontier separating inputs where a model provides stable, correct answers from those where it guesses or hallucinates. "software security knowledge boundary"
- LLMs: General-purpose neural models trained on vast corpora to understand and generate human language across tasks. "LLMs"
- Multiple Choice Questions (MCQs): An assessment format with predefined answer options used to evaluate recall and understanding. "Multiple Choice Questions (MCQs)"
- Prompt-agnostic knowledge: Facts that a model can consistently retrieve correctly regardless of prompt wording or format. "{prompt-agnostic} and {prompt-sensitive} knowledge"
- Prompt-sensitive knowledge: Facts for which retrieval correctness depends heavily on the exact phrasing or structure of the prompt. "{prompt-agnostic} and {prompt-sensitive} knowledge"
- Psychometric validation: Statistical evaluation of an assessment’s reliability and validity to ensure it measures intended constructs. "psychometric validation"
- SALLM dataset: A benchmark of vulnerable Python prompts and code with tests and metadata for evaluating LLM security capabilities. "The SALLM dataset aims to benchmark the security of Python code generated by LLMs"
- Server-Side Template Injection: An attack that exploits server-side template engines to execute arbitrary code or access sensitive data. "Server-Side Template Injection"
- Static Analyzer-based ranking: A mitigation strategy that ranks generated code by static analysis findings to prioritize more secure outputs. "static-analyzer-based ranking"
- Static Application Security Testing (SAST): Security analysis of source code or binaries without execution to detect vulnerabilities statically. "Static Application Security Testing (SAST)"
- Threat modeling: A structured process to identify potential threats, analyze vulnerabilities, and propose mitigations in a system. "Threat modeling and Python web application security."
- XBOW Validation Benchmark: A collection of real-world web projects with tagged vulnerabilities used to validate security-focused LLM systems. "XBOW Validation Benchmark"
- Zero-shot capabilities: A model’s ability to perform tasks without task-specific training examples, relying on generalized knowledge. "zero-shot capabilities for automated program repair (APR)"
Collections
Sign up for free to add this paper to one or more collections.