- The paper demonstrates that using K1 in reward yields an unbiased gradient estimator that ensures stable training and improved generalization.
- It shows that common placements like K1 in loss and K3 in reward introduce bias, leading to instability and inferior performance.
- Comprehensive evaluations on Qwen2.5-7B and Llama-3.1-8B-Instruct confirm significant performance benefits from unbiased estimator configurations.
Analysis of KL Regularization Estimators in RL Training of LLMs
Introduction
This paper presents a rigorous empirical and theoretical investigation into the practical implementation of Kullback-Leibler (KL) regularization in reinforcement learning (RL) fine-tuning of LLMs (2512.21852). The authors identify and dissect several algorithmic and implementation choices that are common in public RL pipelines for LLM post-training—especially those choices that lead to biased gradient estimators in the context of reverse KL regularization. The analysis demonstrates how these design decisions influence training stability, in- and out-of-domain performance, and generalization.
Gradient Estimator Configurations for KL Regularization
A core motivation comes from the widespread but poorly documented variety of KL estimation methods used in applied LLM RL, including their estimator type (e.g., naive or Schulman-style), placement (loss vs. reward), and implications for gradient bias.
The paper formalizes the RL fine-tuning objective as maximizing the expected reward with a reverse-KL divergence penalty to the base policy, controlled by coefficient β. Due to the intractability of computing the sequence-level reverse KL exactly, practical implementations choose from several token-level, sample-based estimators. The two primary estimators considered are:
- Naive log-ratio estimator ("K1"): token-level log-probability ratio summed over the sequence.
- Schulman (low-variance, "K3") estimator: like K1, but incorporating a variance reduction term from the likelihood ratio.
Each estimator can be incorporated in the RL optimization as either a reward-shaping (stop-gradient) or loss-term (backpropagated) regularization. The bias of the resulting gradient estimates varies sharply depending on this placement.
Theoretical and Synthetic Analysis of Gradient Bias
The authors provide a comprehensive theoretical derivation showing:
- Using the naive K1 estimator as a reward penalty yields an unbiased estimator of the gradient of the reverse KL-regularized RL objective under on-policy sampling.
- Using K1 in the loss yields a gradient estimate that is zero in expectation, i.e., fully biased.
- Using the Schulman K3 estimator (either in reward or in loss) yields gradient estimators that are biased with respect to the true reverse KL gradient—even though the estimator itself is unbiased for the scalar KL value.
This fundamental discrepancy is illustrated using a minimal autoregressive model over binary sequences, with explicit calculations of gradient bias and variance.
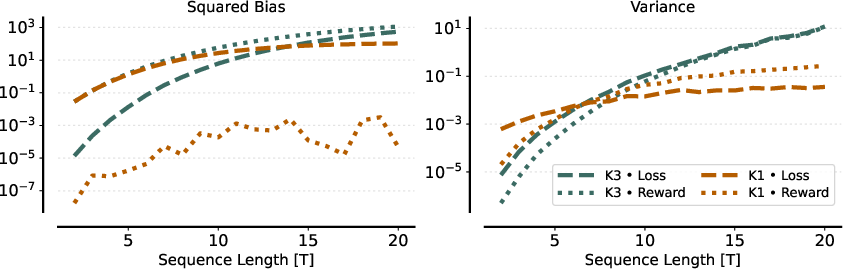
Figure 1: The bias and variance of expected gradients for different estimator and placement configurations, highlighting that only K1 in reward remains unbiased.
Empirical Evaluation on LLM RL Fine-Tuning
Effects in On-Policy Settings
The authors conduct extensive experiments fine-tuning Qwen2.5-7B and Llama-3.1-8B-Instruct on MATH and related reasoning tasks. Several significant empirical observations are established:
- Training Instabilities from Biased Gradients: Using K1 in loss or K3 in reward frequently causes unstable training behavior or catastrophic collapse, especially at higher KL penalty coefficients or when increasing the degree of off-policy updates.
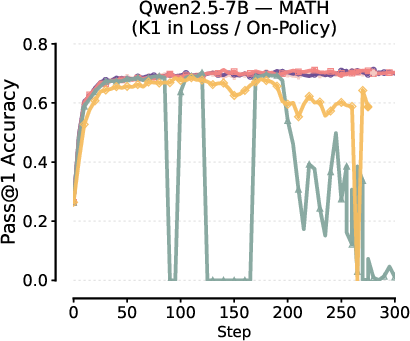
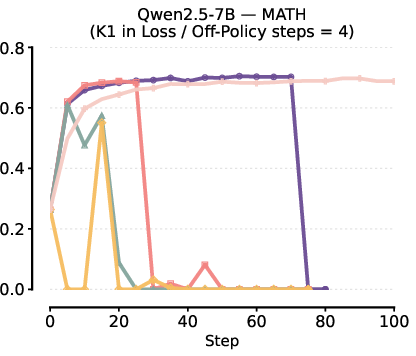
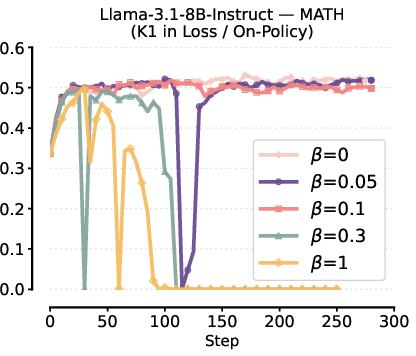
Figure 2: Instability and collapse in RL fine-tuning with K1 in the loss under various β and batch update schedules.
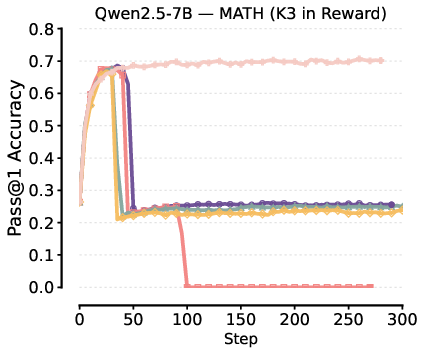
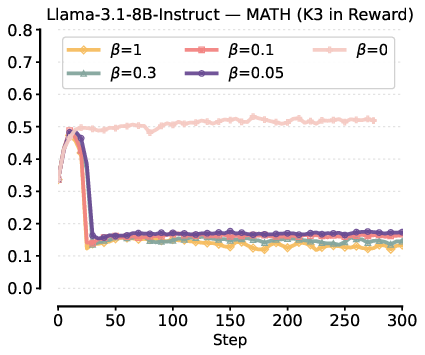
Figure 3: Collapse in Pass@1 performance when K3 is added to reward, attributed to the high gradient bias and variance.
- Stable Learning With Correct Estimator-Placement: K1 in reward, the only unbiased configuration, guarantees stable optimization and the most favorable downstream performance. K3 in loss, despite being biased, appears more robust but still underperforms K1 in reward across various tasks and seeds.
- Performance Trends: Lower KL penalty coefficients (β) generally improve both in-domain and out-of-domain results, but unbiased gradient configurations remain dominant.
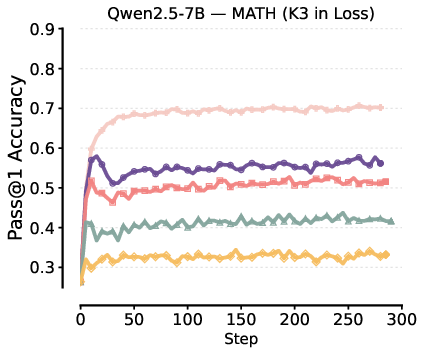
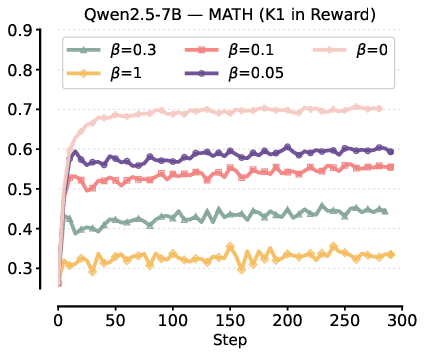
Figure 4: Comparison of Pass@1 test performance for K3-in-loss versus K1-in-reward, showing higher and more stable results for the latter.
Out-of-Distribution Generalization
Evaluation across MATH variants and MMLU subsets demonstrates that unbiased KL gradient configurations (K1 in reward) consistently deliver the best generalization, with relative accuracy gains of up to 19% in out-of-domain tasks. This trend holds for multiple model scales and architectures.
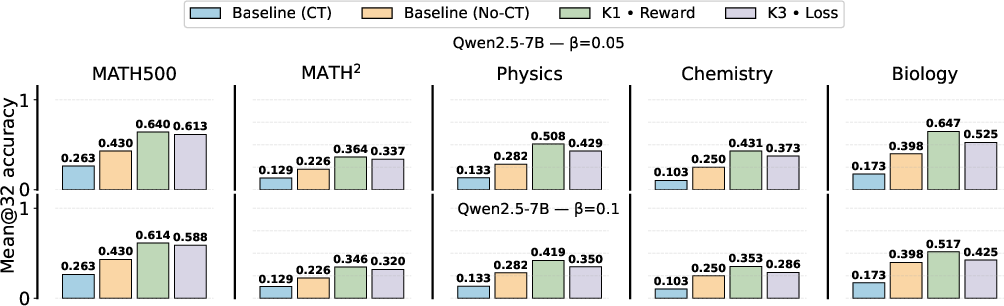
Figure 5: Performance comparison for Qwen2.5-7B highlighting gains in both in- and out-of-domain evaluations for K1-in-reward.
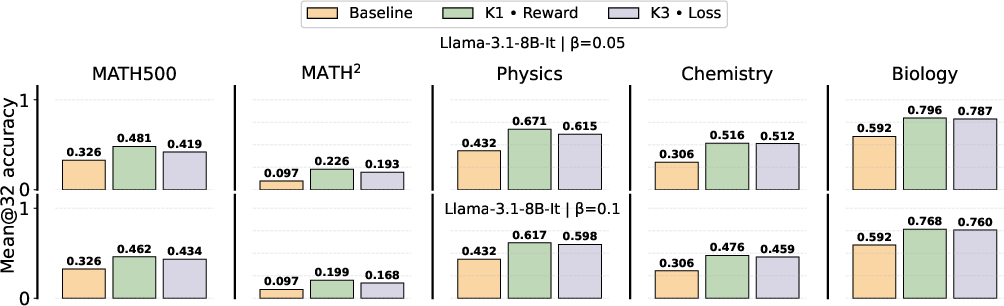
Figure 6: Analogous comparison for Llama-3.1-8B-Instruct, confirming the same estimator trends.
Robustness in Off-Policy and Asynchronous RL
Though all practical KL estimator placements induce bias under off-policy (asynchronous) RL, the paper empirically verifies that K1 in reward and K3 in loss still stabilize training relative to no KL or misconfigured regularization.
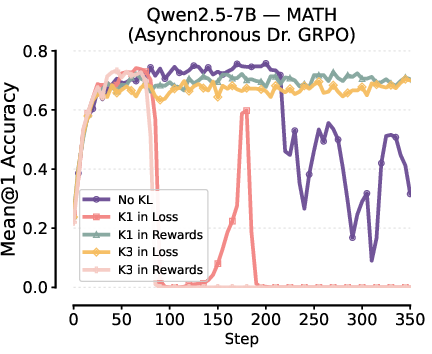
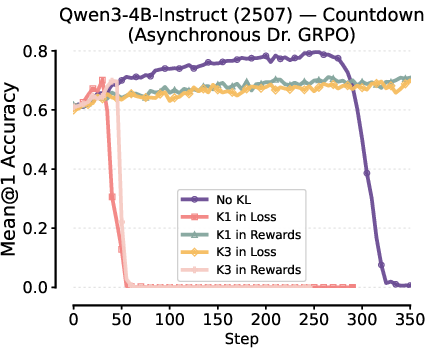
Figure 7: Effect of KL estimator configurations in asynchronous RL (async level = 10): only K1 in reward and K3 in loss achieve stable learning.
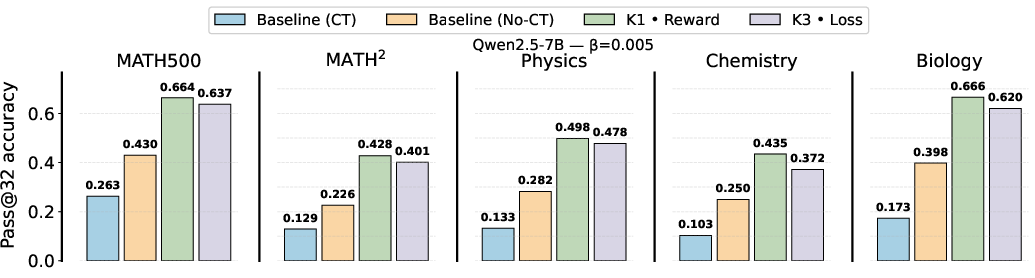
Figure 8: Evaluation of Qwen2.5-7B in asynchronous RL, again showing that K1-in-reward maintains superior performance.
Correction via Combined Placement
The study confirms that adding the KL estimator to both reward and loss (in the on-policy case) always recovers the unbiased estimator—regardless of K1 or K3—improving over standard implementations.
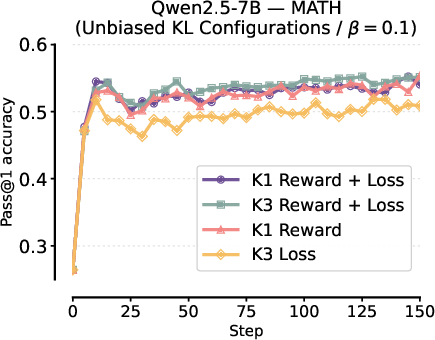
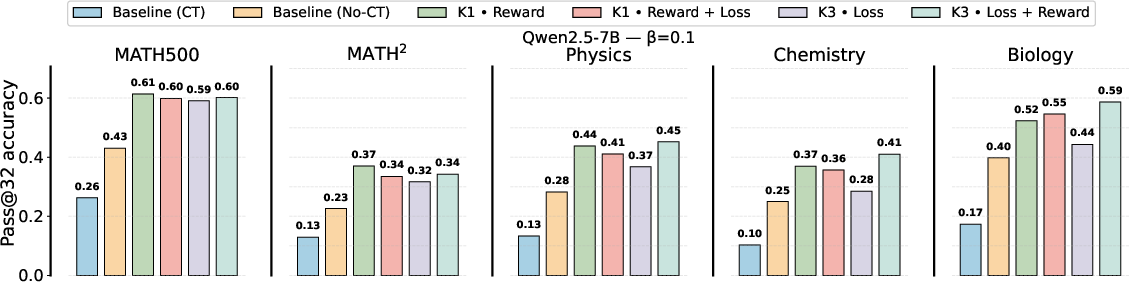
Figure 9: [Left] Stable and high performance for unbiased configurations. [Right] Unbiased settings consistently outperform K3-in-loss across all evaluation sets.
Discussion and Implications
These results decisively demonstrate that seemingly innocuous implementation choices for KL regularization induce strong and sometimes catastrophic biases in RL gradients, producing major differences in learning dynamics and generalization—despite widespread use in public libraries and recent high-profile RLHF systems.
Key claims supported by strong evidence include:
- Unbiased gradient configurations should be the default in RL-based LLM post-training, as they uniquely guarantee stability, task performance, and generalization.
- Practically popular configurations (e.g., K3 in loss, as in GRPO and similar PPO-based variants) are robust but consistently outperformed by unbiased alternatives.
- There is a critical need for explicit documentation and scrutiny of estimator placement in RL open-source tools and research code, as inherited bugs and ambiguities propagate instability and suboptimal results.
- This analysis motivates future work into unbiased sequence-level KL regularization under off-policy/asynchronous sampling, as well as refinement of RL reward shaping for compositional and multi-task transfer.
Conclusion
This comprehensive study establishes that in RL training of LLMs, KL regularization estimator choice and especially its placement (reward vs. loss) directly determines the bias of gradient estimators, with substantial consequences for practical training stability and generalization. Only certain reward-shaping approaches (notably K1-in-reward under on-policy sampling or combined loss plus reward) are unbiased for sequence-level reverse KL gradients. The observations are robust over model scales, datasets, and RL variants. These findings provide actionable recommendations for future RLHF and RLVR research and software, while highlighting the surprising fragility and inadequately documented pitfalls in current RL fine-tuning pipelines.