- The paper introduces the Regularized Policy Gradient (RPG) framework, integrating KL divergences to stabilize LLM training.
- It details derivation of fully differentiable and REINFORCE-style loss functions to effectively manage off-policy learning.
- Extensive experiments demonstrate RPG's enhanced performance on mathematical reasoning benchmarks compared to existing methods.
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
The paper "On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning" explores the integration of Kullback-Leibler (KL) divergence into policy gradient algorithms to improve LLM reasoning. By investigating different KL divergence formulations, this research highlights optimization techniques that leverage forward and reverse KL divergences within the reinforcement learning context to enhance training stability and performance. This essay dissects the methodological contributions, implementation insights, and empirical evaluations presented in the paper.
Regularized Policy Gradient Framework
The paper introduces a framework called Regularized Policy Gradient (RPG), which systematically derives and analyzes policy gradient methods regularized by KL divergences. The framework accommodates both forward and reverse KL divergences, permitting the exploration of normalized and unnormalized policy distributions. This diversification allows RPG to adapt to various algorithmic needs, offering significance in online reinforcement learning environments.
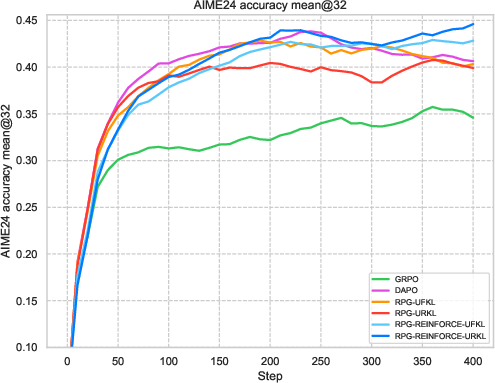
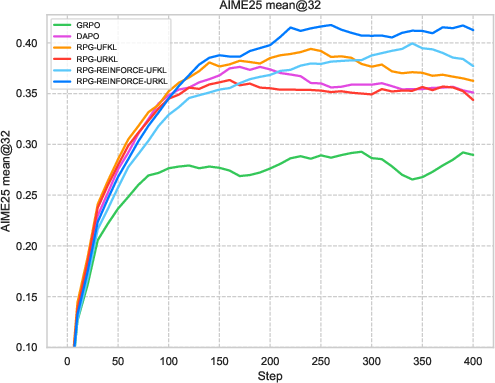
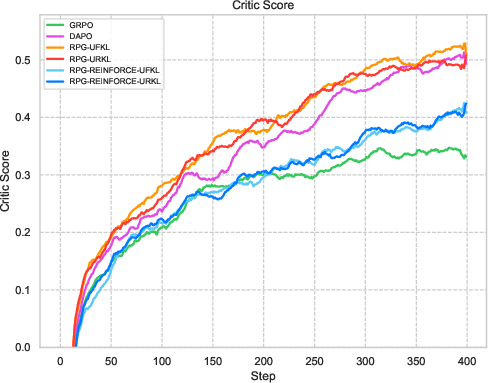
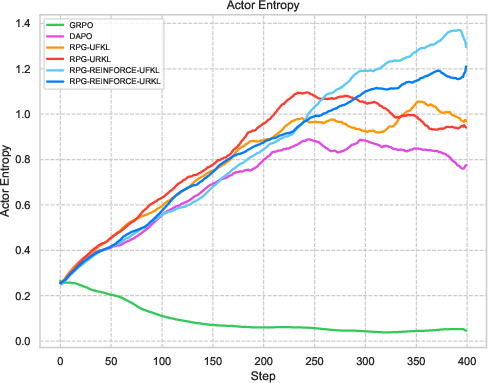
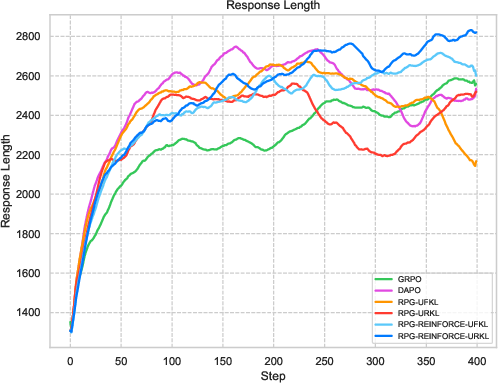
Figure 1: An overview of RPG's iterative training framework focusing on KL-regularized objectives for LLM reasoning tasks.
Derivation and Implementation Approaches
RPG constructs surrogate loss functions corresponding to KL-regularized objectives, specifically focusing on objectives regularized by normalized (KL) and unnormalized (UKL) formulations. The derivations encompass fully differentiable loss functions and REINFORCE-style gradient estimators:
- Fully Differentiable Losses: These are formulated to achieve direct alignment with original gradients for gradient-descent-based optimization. For instance, a surrogate loss for forward KL is derived to maximize expected rewards while controlling policy divergence.
- REINFORCE-Style Estimators: The framework adapts these estimators to manage off-policy learning scenarios through importance sampling techniques, including using stop-gradient operators to effectively implement policy updates.
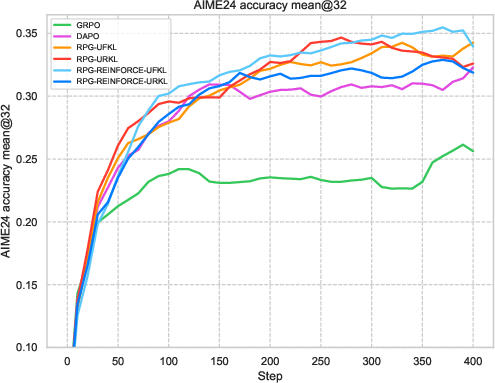
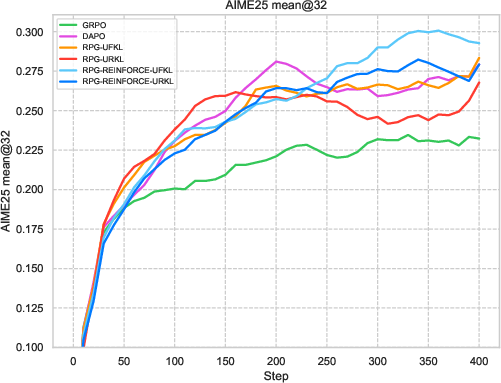
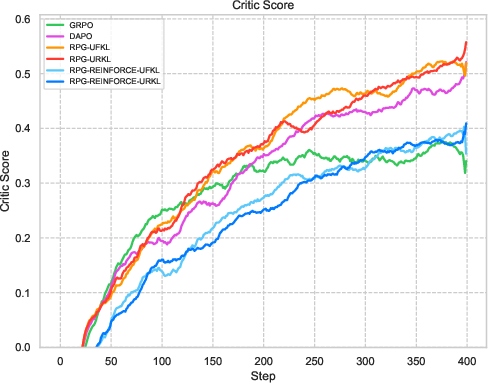
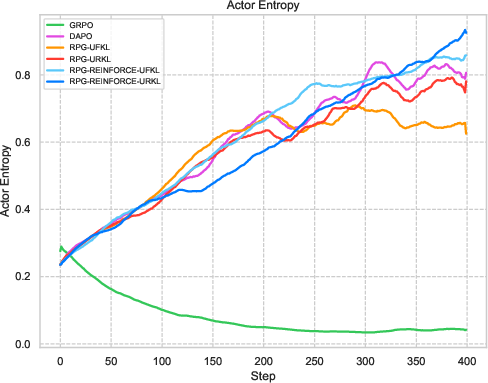
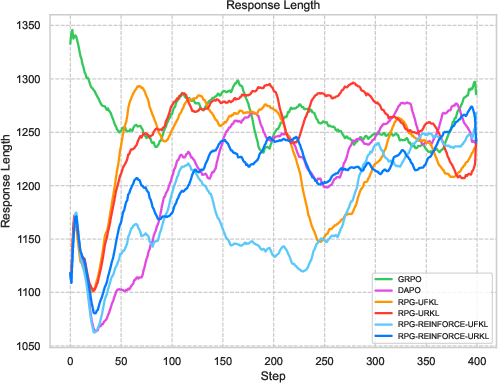
Figure 2: Comparative results highlighting RPG variants' performance in efficient learning against established baselines.
Theoretical Insights and Corrections
One significant theoretical contribution lies in identifying and correcting an inconsistency in the gradient estimation of the Group Relative Policy Optimization (GRPO) algorithm's KL objective. By proposing a corrected gradient estimator, the paper improves upon existing methodologies by incorporating importance weighting accurately within the objective function.
Computational Considerations
The computational efficiency of RPG is augmented by its design choice of not requiring dual models in memory simultaneously. By utilizing precomputed probabilities from a previous policy iteration, RPG enhances computational efficiency, reducing the typical memory burden associated with reference-based regularization methods.
Empirical Evaluation
Extensive experiments on reasoning tasks for LLMs confirm the effectiveness of the RPG framework. Compared against baselines like GRPO and REINFORCE++, the RPG methods exhibit improved training stability and competitive performance. Notably, results on mathematical reasoning benchmarks demonstrate RPG's ability to sustain high performance, effectively balancing exploration and exploitation through its KL regularization strategies.
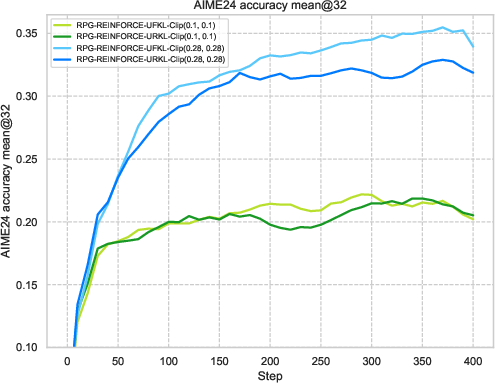
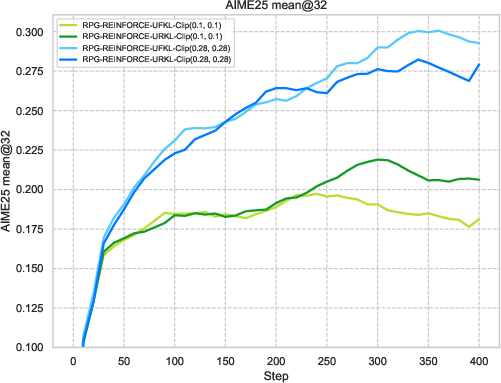
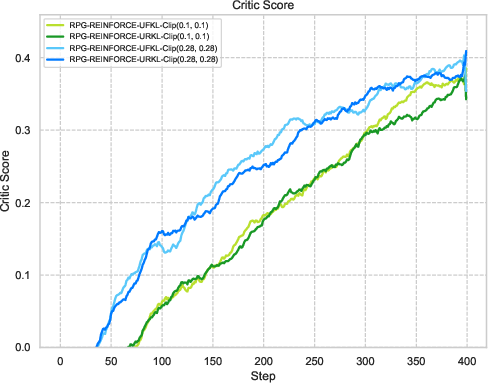
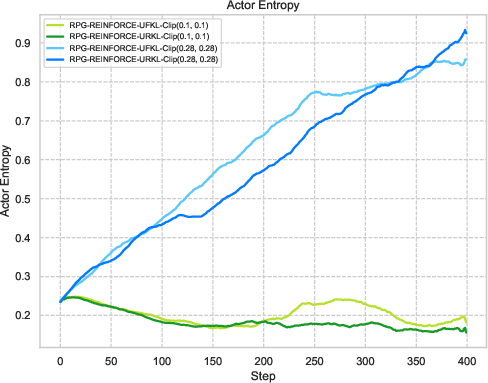
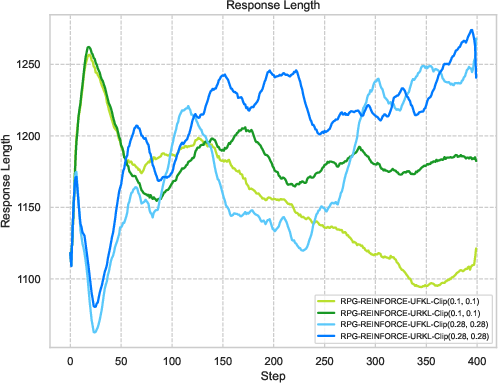
Figure 3: Visualization of reward metrics and training dynamics demonstrating RPG's stability on LLM reasoning tasks.
The experiments reveal strong performance of RPG methods across various tasks, particularly highlighting substantial improvements on tasks such as AMC23 and AIME24. These results underscore RPG's capability to maintain robust training dynamics, as shown by sustained reward metrics and control over policy entropy.
Conclusion
The introduction of KL-Regularized Policy Gradient algorithms presents a refined approach to optimizing LLMs for complex reasoning tasks by structurally integrating KL divergence into reinforcement learning frameworks. The RPG framework not only enhances empirical performance but also offers theoretical insights with practical implementation strategies that efficiently manage computational resources. Future explorations might extend these methodologies to broader applications involving sparse or complex reward structures typical in natural language processing and decision-making scenarios.