- The paper presents a novel framework that preserves clipped-token gradients to balance exploration and exploitation in reinforcement learning.
- The methodology employs a stop-gradient mechanism to dynamically adjust gradient magnitudes, preventing entropy collapse and explosion.
- Empirical results on mathematical reasoning benchmarks show CE-GPPO achieves superior performance and stable training compared to conventional PPO variants.
CE-GPPO: Coordinating Entropy in Reinforcement Learning
The paper "CE-GPPO: Coordinating Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning" introduces an innovative approach to address the complexities of managing policy entropy in reinforcement learning (RL) environments, particularly when fine-tuning LLMs. This piece of research explores the shortcomings of existing methods like PPO and its variants, providing a new framework that reintroduces gradients from clipped tokens to optimize exploration-exploitation trade-offs.
Policy Entropy in RL
Policy entropy in RL is a critical factor in balancing exploration and exploitation during the training process. Models with high policy entropy have diverse action outputs which promote exploration, whereas models with low policy entropy are more structured towards exploiting current knowledge. The paper identifies two critical types of tokens influencing this entropy: Positive-advantage low-probability (PA{content}LP) tokens, encouraging exploration, and negative-advantage high-probability (NA{content}HP) tokens, aiding exploitation.
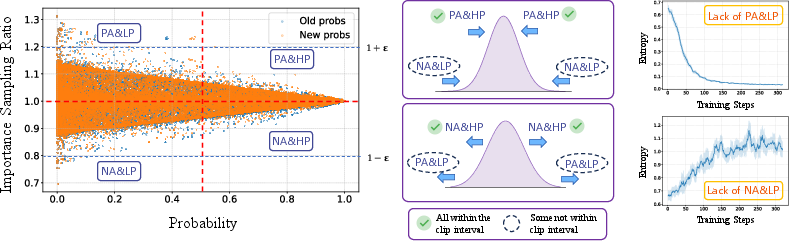
Figure 1: Visualizes token distribution types and their effect on entropy dynamics.
Methodology: Gradient-Preserving Clipping Policy Optimization
Impact of Clipped-Token Gradients
The paper reveals that clipped tokens play an essential role in the stability of policy entropy, which affects overall model performance. Ignoring them leads to issues such as entropy collapse and explosion. The innovation here lies in incorporating gradients from tokens that lie outside the clipping interval, hence supporting a stable entropy trajectory during training.
Algorithm Implementation
The CE-GPPO algorithm fundamentally modifies the typical clipping approach in PPO by preserving gradients of tokens outside the clipping interval using a stop-gradient mechanism. By adjusting the gradient magnitudes dynamically, CE-GPPO maintains an effective balance between exploration and exploitation.
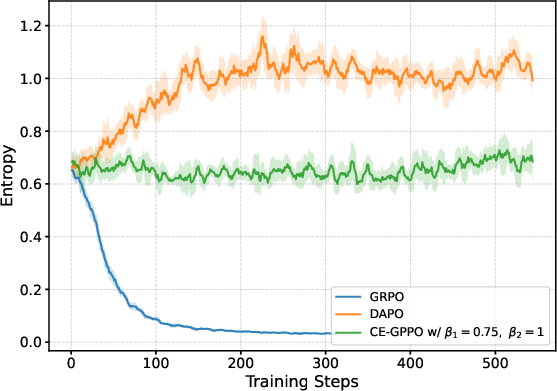
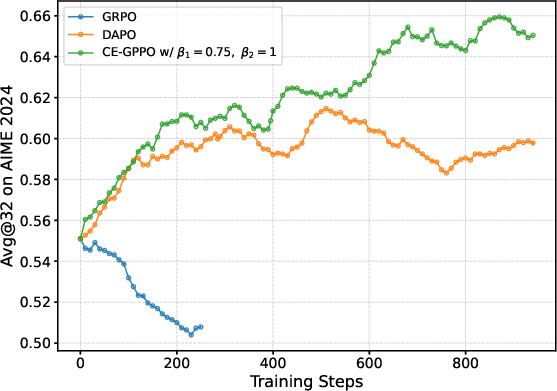
Figure 2: Entropy dynamics display the stability achieved by implementing CE-GPPO.
Ensuring Training Stability
CE-GPPO retains stability akin to traditional PPO through a structured gradient formulation. The stop-gradient mechanism limits excessive policy deviations, ensuring that the optimization process remains controlled and stable.
Empirical Evaluation
Experiments on mathematical reasoning benchmarks highlight CE-GPPO's superior performance in comparison to other RL methods like GRPO and DAPO. The algorithm not only achieves higher scores on complex tasks but also demonstrates better scaling capabilities with larger models.
Analysis
Hyperparameter Influence
The research shows that specific hyperparameter configurations, such as β1 and β2, critically affect the entropy dynamics and overall performance. Empirical results indicate that adjusting these parameters significantly influences the exploration capabilities of models, thereby guiding entropy evolution beneficially.
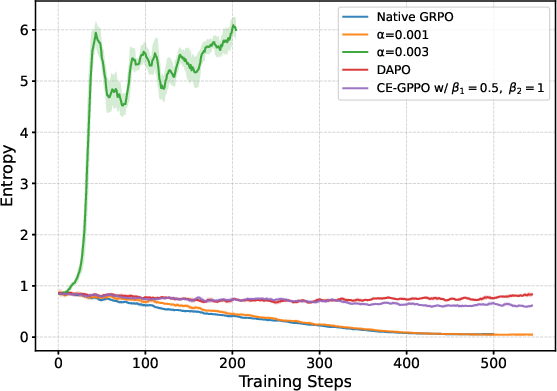
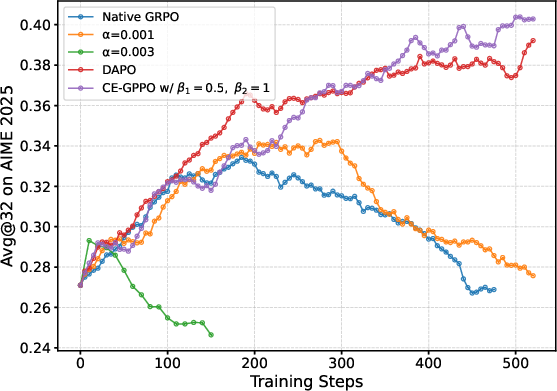
Figure 3: Effects of various hyperparameter settings on entropy stability.
Comparative Evaluation
In comparison to CISPO and GSPO, CE-GPPO consistently produces superior results across multiple benchmarks, suggesting its broad applicability and effectiveness. Additionally, its unique gradient propagation strategy safeguards against model collapse often seen in other RL algorithms.
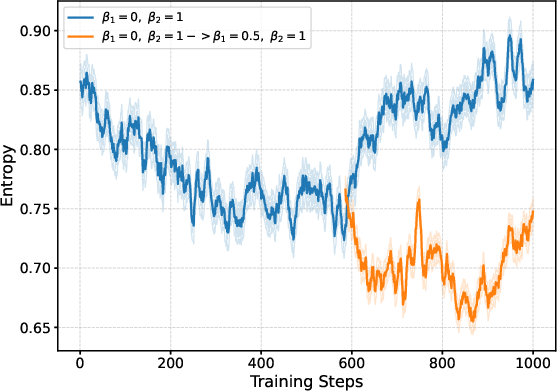
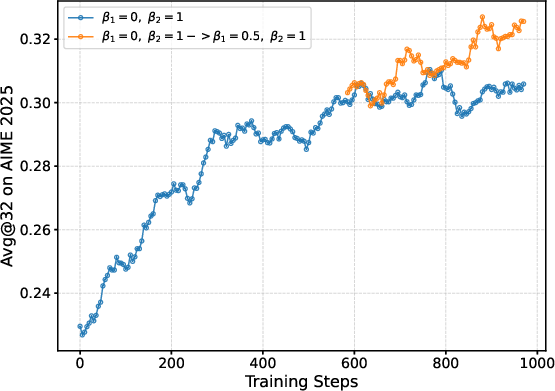
Figure 4: CE-GPPO maintains stable KL divergence and gradient norms, verifying stable training.
Practical Implications and Future Work
The research carries substantial implications for real-world cognitive tasks where balancing exploration and exploitation is crucial. CE-GPPO’s ability to maintain entropy stability and achieve high model performance could lead to more efficient RL applications in complex reasoning and decision-making systems.
Further exploration is necessary to fully understand the potential of CE-GPPO in diverse settings and its adaptability across various model architectures. This might involve fine-tuning hyperparameters further to optimize for distinct operational environments.
Conclusion
The study successfully highlights the importance of entropy coordination in RL and offers a compelling solution through the CE-GPPO framework. By managing token gradients effectively, CE-GPPO stabilizes the exploration-exploitation balance, paving the way for enhanced RL application in LLM fine-tuning. This research opens avenues for exploring gradient-preserving strategies in other learning paradigms.