Interactive Machine Learning: From Theory to Scale
Published 30 Dec 2025 in cs.LG, cs.AI, and stat.ML | (2512.23924v1)
Abstract: Machine learning has achieved remarkable success across a wide range of applications, yet many of its most effective methods rely on access to large amounts of labeled data or extensive online interaction. In practice, acquiring high-quality labels and making decisions through trial-and-error can be expensive, time-consuming, or risky, particularly in large-scale or high-stakes settings. This dissertation studies interactive machine learning, in which the learner actively influences how information is collected or which actions are taken, using past observations to guide future interactions. We develop new algorithmic principles and establish fundamental limits for interactive learning along three dimensions: active learning with noisy data and rich model classes, sequential decision making with large action spaces, and model selection under partial feedback. Our results include the first computationally efficient active learning algorithms achieving exponential label savings without low-noise assumptions; the first efficient, general-purpose contextual bandit algorithms whose guarantees are independent of the size of the action space; and the first tight characterizations of the fundamental cost of model selection in sequential decision making. Overall, this dissertation advances the theoretical foundations of interactive learning by developing algorithms that are statistically optimal and computationally efficient, while also providing principled guidance for deploying interactive learning methods in large-scale, real-world settings.
The paper introduces an abstention mechanism that achieves polylogarithmic label complexity, even under challenging high-noise conditions.
The paper leverages deep neural network approximations in Sobolev and Radon spaces to establish minimax-optimal performance in active learning.
The paper develops scalable contextual bandit algorithms independent of action set size and provides sharp bounds for online model selection.
Interactive Machine Learning: Theoretical Advances and Scalable Algorithms
Introduction
The dissertation "Interactive Machine Learning: From Theory to Scale" (2512.23924) develops new theoretical principles and algorithms for interactive learning, directly addressing the limitations of conventional machine learning methods that passively consume large labeled datasets or repeatedly interact with the environment in costly, time-consuming ways. The work positions interactive learning—comprising active learning and sequential decision making—as the key vehicle for improving sample efficiency and adaptivity in real-world problems. The contribution is organized across three major axes: (1) active learning beyond low-noise and restrictive model classes, (2) contextual bandits with large or continuous action spaces, and (3) model selection in online, feedback-constrained environments.
Efficient Active Learning with Abstention
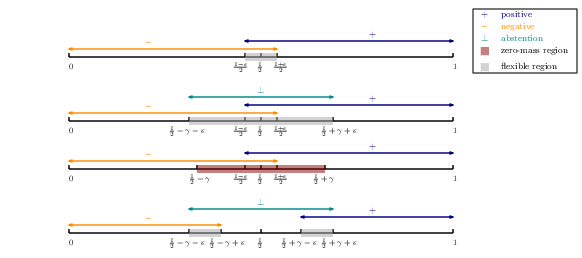
The first part of the research tackles foundational barriers in active learning by moving beyond settings that are either noise-free or governed by benign noise conditions (e.g., Massart or Tsybakov). Existing impossibility results highlight that, in agnostic (high-noise) regimes, active learners cannot outperform passive learners in terms of label complexity. The approach introduced here systematically incorporates abstention—a mechanism formalized by Chow’s error—to circumvent these limitations. By allowing the learner to abstain in uncertain regions, specifically where the conditional label probability η(x)≈1/2, exponential improvements in label complexity are achieved in broad settings.
The proposed algorithm is strongly grounded in practical feasibility by reducing the required operations to weighted square-loss regression oracles, widely available for large hypothesis spaces. The main theoretical result establishes a polylog(1/ε) label complexity without low-noise assumptions, a pronounced statistical gain over the Ω(1/ε2) lower bounds for both passive and non-abstaining active learning.
Figure 1: Decision regions under various error criteria including standard excess error and Chow’s error, showing the enlargement of flexible regions with abstention that enable exponential label savings.
Key properties are:
Proper Abstention: The algorithm abstains only when abstention is truly optimal. Under Massart/Tsybakov noise, it recovers minimax-optimal sample complexity for standard excess error.
Robustness to Noise-Seeking Conditions: Theoretical analysis introduces noise-seeking adversaries and shows that uncertainty sampling-type methods can suffer linear regret, whereas the proposed approach maintains statistical efficiency.
Constant Label Complexity: Under Massart noise and for classes with bounded eluder dimension, the method achieves constant (accuracy-independent) label complexity.
The practical implication is readily apparent for domains such as medical diagnostics, where misclassification of ambiguous examples is expensive or hazardous—a controlled rate of abstention can deliver accurate classifiers at dramatic reductions in expert annotation cost.
Deep Active Learning: Minimax-Optimality and Beyond
In the second part, the dissertation bridges the gap between empirical advances in deep active learning and theoretical label complexity guarantees. It leverages modern nonparametric function approximation insights, constructing neural network classes with provable global approximation properties in Sobolev and Radon BV2 spaces. Label complexity bounds previously only achieved for partition/nearest-neighbor-based learners are matched (up to disagreement coefficient factors) by networks with appropriate capacity scaling:
For distributions DXY in Sobolev spaces and satisfying Tsybakov noise with parameter β, excess error ε can be obtained using
O(θHdnn(εβ/(1+β))⋅ε−(d+2α)/(α+αβ))
label queries (where θ is the disagreement coefficient).
This approach extends to neural architectures that serve as universal approximators in the Radon BV2 space, reducing curse-of-dimensionality effects for certain smoothness regimes.
Importantly, when an abstention mechanism is incorporated, even this nonparametric setting admits exponential (polylogarithmic) label complexity improvements, with empirical routines (e.g., SGD-trained nets) well-aligned with the regression-oracle-based theory.
Sequential Decision Making at Scale
The next major thrust is scalable contextual bandit learning. In practical settings (e.g., recommendation or ad allocation) the number of possible actions can be enormous, rendering O(A) algorithms infeasible. This research develops computationally efficient contextual bandit algorithms whose regret and runtime are independent of the cardinality of the action set, both for structured (e.g., linear) and unstructured (general function class) settings:
In structured settings, leveraging linear optimization and regression oracles over the action space yields near-optimal regret even when actions are continuous or number in the millions.
For fully unstructured settings, a smoothed regret benchmark is proposed, bypassing hardness results for the classical benchmark. Efficient algorithms are obtained for admissible smoothness assumptions (e.g., Lipschitz/Hölder).
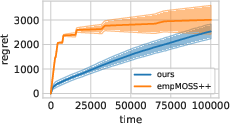
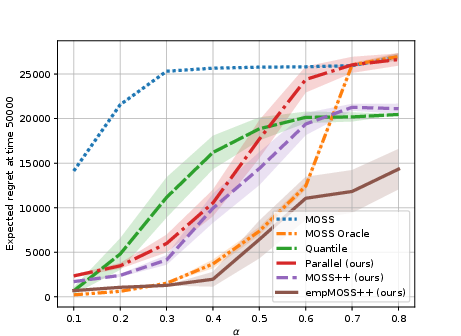
Empirical results on synthetic and large-scale real-world bandit datasets support these advances.
Figure 2: Regret on a bandit dataset with discrete action space, comparing algorithms under different scaling regimes.
Figure 3: Progressive regret with varying hardness parameter α on synthetic data, capturing instance-dependent adaptation.
Model Selection under Partial Feedback
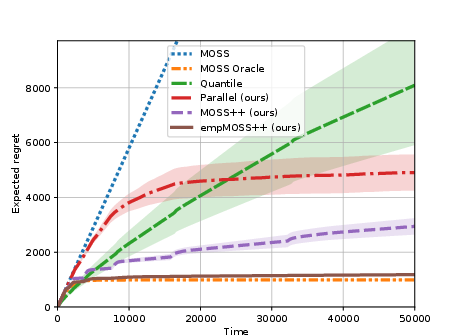
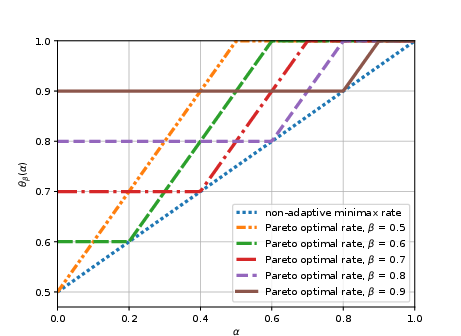
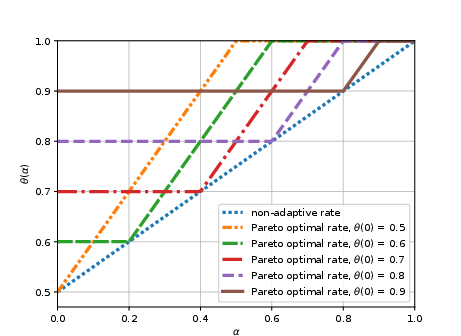
The final substantive focus is on model selection in adaptive, feedback-limited environments, an area theoretically less mature than its supervised counterpart. The work provides the first sharp lower and upper bounds, establishing that online model selection is strictly harder than batch: a polynomial cost must be paid (as opposed to logarithmic in supervised settings). Notably, Pareto-optimal algorithms are established for both regret minimization and best action identification, matching lower bounds up to logarithmic factors.
Figure 4: Pareto optimal rates for bandit learning with multiple best arms.
Figure 5: Pareto optimal model selection rates for linear bandits.
The methods adapt online to the complexity of the underlying problem instance, delivering performance guarantees that closely track oracle behaviors.
Implications and Future Directions
The theoretical contributions fundamentally expand the scope of efficient, statistically optimal interactive machine learning. Abstention and smoothed performance criteria are highlighted as essential technical levers for circumventing worst-case lower bounds, supporting large-scale and high-stakes applications. The ability to combine deep learning with adaptive data acquisition in a theoretically principled manner is particularly noteworthy.
Several directions are outlined for further investigation:
Sharper Characterization of Disagreement: For deep networks, bounding the disagreement coefficient and understanding its empirical scaling in practical regimes.
Adaptive Algorithms: Methods that self-tune to unknown smoothness/noise parameters, possibly leveraging data-dependent model selection.
Advanced Feedback Models: Extension to reinforcement learning and online settings with more complex partial feedback structures.
Conclusion
This work advances the theoretical and algorithmic foundations of interactive machine learning, demonstrating that statistically optimal and computationally practical learning is possible in challenging regimes previously thought intractable. Through abstention, robust nonparametric approximation, and scalable bandit algorithms, the research bridges theory and practice, with implications for both the design of efficient annotation protocols and the deployment of large-scale, adaptive decision systems.