GR-Dexter Technical Report
Abstract: Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GR-Dexter, a complete robot system that combines new robot hands, a way to control and teach the robot, and an AI model so the robot can follow language instructions and use two human‑like hands to do long, multi‑step tasks in the real world. The goal is to make robots better at everyday jobs that need careful finger movements, like picking up delicate objects, pressing buttons, or using tools—things that are hard to do with simple two‑finger grippers.
What were the main goals?
Here are the main questions the researchers set out to answer:
- How can we build compact, human‑like robot hands with many joints that are still reliable and easy to maintain?
- How can we collect good training examples for such complicated hands without spending huge amounts of time and money?
- How can we train a single AI policy that reads instructions, looks at the scene, and controls two arms and two dexterous hands across many different tasks—even ones it hasn’t seen before?
How did the researchers do it?
To tackle the challenge, they built three parts that work together: new hardware, a teaching/teleoperation system, and a vision‑language‑action (VLA) model trained on diverse data.
A new pair of robot hands
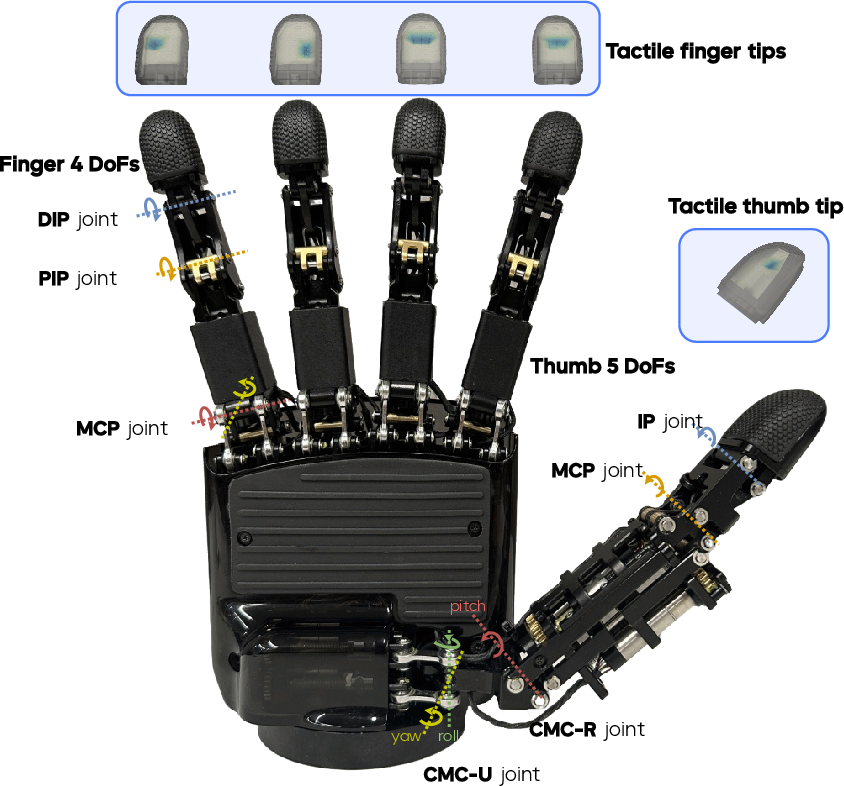
- The ByteDexter V2 hand has 21 “degrees of freedom” (DoF) per hand. A “DoF” is like a joint that can move—more DoFs mean more flexible, human‑like motion.
- The thumb has extra movement so it can oppose every finger, enabling strong, precise grips.
- The motors are tucked inside the palm to keep the hand compact.
- The fingertips have touch sensors, so the robot can “feel” contact and how hard it’s pressing.
A way to control and teach the robot
Teaching robots is hard, especially when each hand has many joints. The team built a bimanual (two‑handed) teleoperation setup using:
- A VR headset to track where the person is looking and moving,
- Special gloves to track finger positions,
- Software that “retargets” human hand motions to robot hand joint commands in real time.
Think of retargeting like translating a person’s hand pose into the closest matching robot hand pose, with a focus on where the fingertips should touch—because contact points are what matter most for grasping.
They also used multiple cameras around the robot to capture good views even when the robot’s hands hide the object (this hiding is called “occlusion”).
A brain for the robot: the GR-Dexter model
- GR-Dexter is a 4‑billion‑parameter AI model that takes three inputs: 1) a language instruction (like “pick up the red cup and put it in the box”), 2) camera images, and 3) the robot’s current state (joint angles, etc.).
- It outputs short “action chunks,” which are small sequences of movements for the arms and hands. This helps make motions smooth and coordinated over time.
- The model is a Vision‑Language‑Action (VLA) policy, meaning it reads words, sees images, and decides actions—all in one system.
Lots of training data from different places
Collecting tons of real robot data with dexterous hands is expensive, so they mixed several sources:
- Vision‑language web data: captions, questions about images, and grounding tasks help the model “see” and “understand” scenes and language.
- Cross‑embodiment robot data: demonstrations from other robot platforms with different hands. They “retarget” these to ByteDexter by aligning fingertip contacts so the key grasping intent transfers even if joints differ.
- Human hand trajectories: large collections of first‑person videos and tracked hand poses from VR devices. These show everyday hand‑object skills at scale. The team cleans, filters, and standardizes these before training, and maps them into the robot’s format.
By standardizing camera views and focusing on fingertip alignment, the model learns what matters for contact and manipulation, not just exact joint angles.
What did they find?
The team tested GR-Dexter on real robots in two main categories: long, multi‑step tasks and general pick‑and‑place with new objects and instructions.
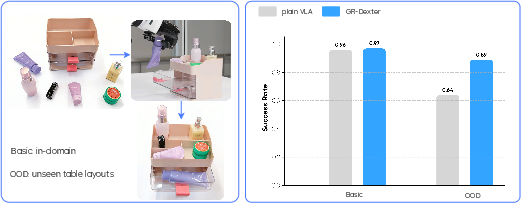
- Long‑horizon tasks (like decluttering a makeup desk with drawers and many items):
- In basic, familiar setups, GR-Dexter performed as well as a strong baseline trained only on robot data.
- In new, shuffled layouts it hadn’t seen, the baseline’s success dropped to about 64%, while GR-Dexter stayed high at about 89%. The extra vision‑language and cross‑embodiment training clearly helped it generalize.
- It also handled tool use, such as:
- Vacuuming confetti by holding a mini vacuum, pressing the power button with the thumb, and sweeping,
- Serving bread with tongs while holding a plate in the other hand.
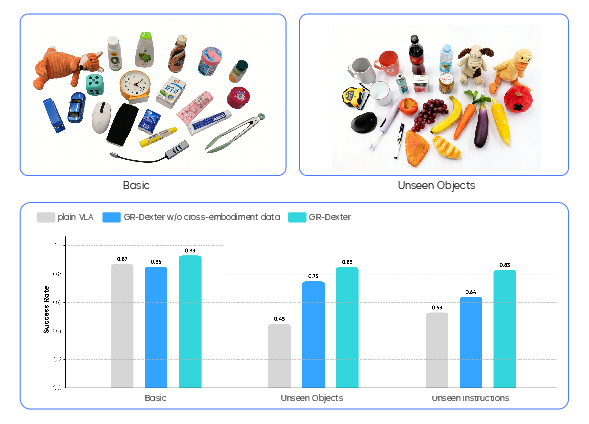
- Generalizable pick‑and‑place:
- On known objects, GR-Dexter reached about 93% success (better than the 87% baseline).
- On new, unseen objects, it achieved about 85% success.
- With unseen instructions (phrasing it hadn’t read before), it reached about 83% success.
- Training with carefully cleaned cross‑embodiment robot data made the biggest difference in overall robustness.
Why this matters: the robot didn’t just memorize; it learned patterns it could reuse for new objects, new layouts, and new instructions.
Why is this important?
- It’s a step toward robots that can help with real‑world tasks in homes, labs, and workplaces—where objects vary and instructions change.
- Using human data and other robots’ data means you don’t need to collect every example from scratch on the final robot. That makes training faster, cheaper, and more scalable.
- The combination of better hands, smarter training, and a strong VLA model shows a workable path to human‑like manipulation.
Limitations and what’s next
- There’s still a lot more human demonstration data out there that could be used; training on even larger, more diverse datasets would likely help.
- The hands and arms are currently controlled in a partly separate way; tighter coordination could improve very delicate, contact‑heavy moves.
In the future, the team aims to scale up cross‑embodiment and human data even more and design control methods that transfer across different robots more easily. Overall, GR-Dexter demonstrates that pairing practical, human‑like hardware with a smart, data‑rich training recipe can unlock reliable two‑handed dexterous manipulation in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, structured to guide actionable future research.
- Tactile sensing is not integrated into the policy: the fingertips have dense tactile arrays, but no experiments quantify the benefit of adding tactile signals to the VLA inputs (e.g., slip detection, contact force control, compliant grasping, in-hand manipulation).
- Separate hand–arm control: the policy and controller treat hands and arms independently; there is no evaluation of unified whole-body control or learned coupled action spaces, nor metrics on how this separation limits contact-rich dexterity.
- Limited ablations on data sources: beyond a “without cross-embodiment data” variant, the paper does not isolate contributions of vision–language, human trajectories, and cross-embodiment data individually (per-source removal, weighting, curricula).
- Retargeting fidelity unvalidated: fingertip-centric alignment is proposed, but there is no quantitative validation (e.g., contact map similarity, grasp stability, joint-limit compliance, force distribution) showing that retargeted motions preserve task-relevant geometry and physics.
- Camera and view modality gaps: multi-view RGB-D cameras are used, yet the model input modality (RGB vs RGB-D vs multi-view fusion) and its contribution to performance are unspecified; no ablations quantify robustness to occlusions, single-view constraints, or onboard-only sensing.
- Manual visual standardization: “resize and crop once” per dataset is a manual, potentially biased process; the sensitivity of performance to scaling/cropping choices and the need for automated, embodiment-agnostic visual normalization are not studied.
- Action representation redundancy and consistency: the model outputs joint actions, end-effector poses, and fingertip positions simultaneously (potentially redundant/overconstrained); there is no study on which channels are necessary, how conflicts are resolved, or their impact on physical consistency and training stability.
- Temporal chunking and optimizer hyperparameters: chunk length k, smoothing parameters, and their effect on latency, closed-loop stability, and failure recovery are not specified or ablated.
- Autonomous safety and failure handling: safety mechanisms are described for teleoperation but not for autonomous rollouts; there is no failure taxonomy, safety monitor/fallback design, or quantitative analysis of unsafe behaviors and recovery.
- Generalization scope is narrow: quantitative results focus on tabletop decluttering and pick-and-place; there is no systematic evaluation on fine in-hand reorientation, deformable/soft objects, liquids, varied articulated mechanisms, or tool-use breadth with metrics.
- Statistical rigor in reporting: success rates are given without trial counts, confidence intervals, or significance testing; evaluation scale and variance across runs remain unclear.
- Baseline coverage is limited: the paper compares to a “plain VLA” trained on robot data only; there is no benchmarking against state-of-the-art dexterous-manipulation policies (e.g., DexGraspVLA, hierarchical VLA+RL controllers, diffusion policies, Octo/π models) under matched budgets.
- Domain mismatch risks in cross-embodiment mixing: potential negative transfer from heterogeneous embodiments is not analyzed; no strategies are explored for dataset weighting, curriculum scheduling, or representation alignment to mitigate distribution shifts.
- Language grounding and task decomposition: long-horizon experiments rely on manual subtask prompting; autonomous instruction parsing, subgoal discovery, and planner integration are not evaluated, nor is robustness to ambiguous or underspecified language.
- Occlusion robustness is asserted but unquantified: performance under controlled occlusion stress tests (e.g., covering fingers, clutter density changes) is not reported.
- Reactive tactile control is absent: there is no exploration of tactile-triggered micro-adjustments (grasp tightening, slip prevention, regrasping) or closed-loop force control at fingers.
- Hardware characterization lacks quantitative benchmarks: no force output, joint speed, backdrivability, tactile resolution (e.g., N/mm²), durability (cycle counts), or comparative metrics against other hands are provided.
- Underactuation impacts unmeasured: DIP and thumb IP underactuation are described but not analyzed for effects on precision grasps, in-hand manipulation, or contact stability; mitigation strategies (e.g., variable stiffness, compliance) are unexplored.
- Real-time performance and compute footprint: inference latency, end-to-end control loop timing, and compute requirements (onboard vs offboard) are not reported; their impact on delicate manipulation is unknown.
- Teleoperation pipeline usability: there is no user study on operator workload, learning curve, throughput (demos/hour), or error rates; data quality control criteria and inter-operator variability are not documented.
- Cross-dataset calibration and bias: differences in camera intrinsics/extrinsics and scene scale across datasets may induce biases; automated calibration and sensitivity analyses are missing.
- Portability to other platforms: the policy and retargeting pipeline are not validated on different bimanual robots/hands; generality across embodiments and the effort required for adaptation remain open.
- Absence of arm/wrist force–torque sensing in control: F/T integration for contact-rich tasks is not discussed; benefits of combining tactile and F/T signals are untested.
- Pretraining design choices: the choice of a 4B Mixture-of-Transformer and flow-matching objective is not justified via scaling laws; trade-offs against smaller models or alternative objectives (diffusion, policy gradients) are unstudied.
- Data scaling and sample efficiency: only ~20 hours of robot teleop per task and “few hundred hours” of human trajectories are used; there is no analysis of sample efficiency, diminishing returns, or optimal mixing ratios across data sources.
- Distribution shift robustness beyond layouts: evaluations on lighting, background, distractors, clutter density, and camera motion (ego-motion) are absent; systematic stress testing is needed.
- Few-shot/online adaptation: the policy’s ability to adapt to new objects/tools/tasks with minimal additional data (fine-tuning or test-time adaptation) is not assessed.
- Human trajectory noise handling: temporal jitter filtering is mentioned but not quantified; error rates, smoothing efficacy, and residual noise impacts on learning remain unclear.
- 3D spatial grounding: despite RGB-D availability, there is no explicit 3D scene representation or grounding assessment (e.g., PointVLA-like methods) to improve spatial reasoning under occlusion/clutter.
- Collision-avoidance constraints in retargeting: constraint formulations are described, but collision rates, mapping accuracy (wrist-to-fingertip and thumb-to-fingertip alignment error), and their effect on downstream learning are not measured.
- Autonomous in-hand manipulation: complex behaviors like controlled rolling, fingertip walking, and dynamic regrasping are only shown via teleoperation; autonomous execution with metrics is not demonstrated.
- Reproducibility and data access: curated datasets and proprietary teleoperation data/pipelines are not fully detailed or released; replicability of preprocessing, retargeting, and training recipes is uncertain.
Practical Applications
Immediate Applications
Below are concrete deployments that can be run today or within short pilot timelines using the paper’s hardware (ByteDexter V2), teleoperation pipeline (VR + gloves + retargeting), data pipeline (cross-embodiment/human trajectory curation), and VLA policy (GR-Dexter).
- Bimanual dexterous R&D platform for labs [Academia, Robotics]
- What: Use ByteDexter V2 + dual-arm setup and the GR-Dexter training recipe to reproduce long-horizon tasks (decluttering, tool use), study policy generalization, and prototype new dexterous skills.
- Tools/workflows: ByteDexter V2 Hand Kit (hardware + tactile fingertips + ROS drivers), Bimanual Teleop Suite (Meta Quest + Manus gloves + retargeting solver), GR-Dexter Training Pipeline (VLM co-training + flow-matching DiT + action chunking + smoothing).
- Dependencies/assumptions: Availability of dual 7-DoF arms, multi-camera RGB-D capture, GPU inference for a ~4B-parameter policy, and basic operator training.
- Teleoperated precision handling in hazardous/clean environments [Energy, Pharma, Semiconductor, Nuclear, Lab Ops]
- What: Remote manipulation of delicate or hazardous items (e.g., vial handling, opening containers, cable routing) with teleop fallback and partial autonomy.
- Tools/workflows: Safety-aware teleop controller with collision constraints, fingertip tactile readouts for grasp quality monitoring, “human-in-the-loop” supervision.
- Dependencies/assumptions: Reliable network and tracking, process-specific safety protocols, shielding/clean-room compatibility, operator training.
- High-mix, low-volume rework, kitting, and sorting cells [Manufacturing, Logistics]
- What: Flexible stations for handling varied SKUs, ad hoc rework, and small-batch assemblies without task-specific tooling, leveraging GR-Dexter’s OOD generalization.
- Tools/workflows: Generalizable pick-and-place policy, task prompts via language, teleop-assisted exception handling.
- Dependencies/assumptions: Object set within the policy’s visual/language priors, stable camera perspectives, throughput compatible with line cadence.
- Service robotics pilots for light household and facilities tasks [Hospitality, Corporate Facilities, Light Cleaning]
- What: Supervised pilots for tasks like decluttering, placing items, operating simple tools (tongs, small vacuum) demonstrated in the paper.
- Tools/workflows: Task scripting via natural-language prompts, routine policy rollouts with chunked action smoothing to ensure safe motions.
- Dependencies/assumptions: Controlled environments, supervision, safety barriers, manageable task variability.
- Dexterous lab automation for non-standard tasks [Biotech, Research Labs]
- What: One-off or infrequent procedures (e.g., opening/closing drawers, transferring non-standard containers, manipulating tools) that defeat classic grippers.
- Tools/workflows: Rapid teleop demonstrations to create short “on-robot” fine-tune sets; retargeted human demos to bootstrap behaviors.
- Dependencies/assumptions: SOP-compliant operation, traceability of actions, consistent lighting and camera placement.
- Cross-embodiment data augmentation for existing robot fleets [Software/ML, Robotics]
- What: Use the paper’s retargeting pipeline to import diverse bimanual datasets and egocentric human videos to boost generalization of in-house policies.
- Tools/workflows: Cross-Embodiment Retargeting Toolkit (fingertip-centric alignment, action masking for missing joints), Data Pyramid Trainer (dynamic mixing of robot/VL/human data).
- Dependencies/assumptions: Access and licensing for datasets, kinematic calibration per platform, careful data QA to avoid negative transfer.
- OEM productization of ByteDexter V2 as a modular end-effector [Robotics OEMs, Integrators]
- What: Retrofit existing arms with a compact 21-DoF hand for dexterity-critical cells; leverage tactile sensing to improve grasp reliability and monitoring.
- Tools/workflows: Hand SDK, driver packages (ROS), fingertip tactile APIs for grasp events, maintenance guides for linkage-driven actuation.
- Dependencies/assumptions: Mechanical/electrical compatibility, spare parts supply chain, integrator expertise.
- Operator training and coursework in dexterous teleoperation and VLA [Education, Workforce Development]
- What: Teach teleop skills, safe bimanual control, dataset collection, and VLA fine-tuning using the paper’s pipeline as a hands-on curriculum.
- Tools/workflows: Teleop practice tasks, benchmark task suites (long-horizon and pick-and-place), evaluation rubrics for OOD generalization.
- Dependencies/assumptions: Access to VR gear and dual-arm platform, GPU time for training/fine-tuning.
- Quality inspection and rework stations with ad hoc manipulation [Manufacturing]
- What: Handling defectives, removing/reattaching parts, repackaging, where OOD objects/instructions arise frequently.
- Tools/workflows: Language-in-the-loop task instructions, tactile-assisted grasp adjustment, fallback teleop for edge cases.
- Dependencies/assumptions: Throughput constraints, robust perception under occlusion and clutter.
- Benchmarking and reproducible evaluation of bimanual dexterity [Academia, Industry Consortia]
- What: Establish shared evaluation suites for long-horizon dexterous tasks with unseen objects/instructions to compare policies fairly.
- Tools/workflows: Public task protocols, standardized camera/layout configs, reference data splits for Basic vs OOD.
- Dependencies/assumptions: Community buy-in, consistent hardware or equivalently retargeted embodiments.
Long-Term Applications
These require additional research, scaling, safety certification, or productization beyond pilot environments.
- General-purpose home assistant robots with true in-hand dexterity [Consumer Robotics]
- What: Multi-step household tasks (tidying, loading/unloading appliances, tool operation) robust to unseen objects and instructions.
- Enablers: Larger-scale cross-embodiment + human video pretraining, better occlusion handling, low-cost hands, reliable on-device inference.
- Dependencies: Cost, reliability, safety certification for in-home operation, user-friendly supervision interfaces.
- Assistive care and rehabilitation support [Healthcare]
- What: Feeding assistance, dressing, object retrieval, and bimanual ADLs requiring fine manipulation and compliance.
- Enablers: Stronger safety guarantees, tactile/force control, ergonomics and HRI studies, clinical validation.
- Dependencies: Regulatory approval, medical-grade hardware, robust fail-safes, liability frameworks.
- Fixtureless, flexible assembly lines [Manufacturing]
- What: High-mix assembly without dedicated jigs, rapid reconfiguration via language prompts and few-shot on-robot demos.
- Enablers: Tighter arm–hand coordination controllers, richer tactile coverage, reliable in-hand manipulation and tool use.
- Dependencies: Cycle-time competitiveness, uptime, predictive maintenance for hands, integration with MES/QA systems.
- Autonomous fulfillment cells for novel SKU handling [Logistics, E‑commerce]
- What: Robust picking/packing of constantly changing catalog items and packaging materials, minimal reprogramming.
- Enablers: Massive multi-domain pretraining, fast continual learning from operations data, scalable perception under clutter.
- Dependencies: Safety around humans, cost/throughput parity with specialized systems, reliable failure recovery.
- Surgical tele-assist and perioperative dexterous support [Healthcare]
- What: Non-critical perioperative tasks (instrument handling, suture assistance) progressing towards more delicate operations.
- Enablers: High-fidelity haptics, latency-robust shared autonomy, sterile adaptations, verifiable precision.
- Dependencies: Stringent regulatory pathways, surgeon oversight workflows, extensive validation and risk management.
- Disaster response and field manipulation [Public Safety, Defense]
- What: Door opening, valve turning, debris removal, and tool operation in unstructured, hazardous scenes.
- Enablers: Ruggedized hands/arms, robust perception in dust/smoke/low light, teleop-autonomy handoff under poor comms.
- Dependencies: Power/weight constraints, communications resilience, safety and reliability in extreme conditions.
- On-orbit or planetary dexterous servicing [Aerospace]
- What: Maintenance, assembly, and sample handling with limited supervision and high delays.
- Enablers: Delay-tolerant autonomy, fault-tolerant control, radiation-hardened compute, advanced tactile sensing.
- Dependencies: Space-grade hardware, mission integration, rigorous verification/validation.
- Agricultural dexterity for delicate crops [Agritech]
- What: Harvesting, pruning, thinning, and sorting requiring gentle bimanual handling and tool use.
- Enablers: Domain-specific datasets (crop varieties, seasons), compliance control, outdoor perception robustness.
- Dependencies: Environmental robustness (weather, dust), ROI vs traditional methods, safety near workers.
- Cross-embodiment data and control standards [Policy, Standards, Consortia]
- What: Industry-wide schemas for action spaces, retargeting metadata, tactile formats, and safety annotations to unlock data sharing.
- Enablers: Open benchmarks, reference converters, privacy-preserving data pipelines.
- Dependencies: Stakeholder alignment, IP/licensing models, regulatory guidance on shared robot data.
- Embodiment-agnostic manipulation foundation services [Software/Cloud]
- What: Cloud or edge services offering pre-trained VLA dexterity models with adapters per robot/hand, “training-as-a-service” for continual learning.
- Enablers: Modular action abstractions, reliable retargeting across diverse hands, efficient 4B+ model inference on edge.
- Dependencies: Vendor-neutral APIs, security and uptime SLAs, cost-effective inference, data governance.
Notes on Feasibility and Assumptions Across Applications
- Hardware readiness: Many applications assume access to a dual-arm platform and ByteDexter-class hands; widespread deployment depends on cost, durability, and supply chain.
- Perception: Multi-camera RGB-D setups to mitigate occlusions are assumed; dynamic, cluttered scenes may require additional sensing or 3D perception modules.
- Compute: Real-time inference for a ~4B-parameter VLA policy typically needs a GPU; embedded deployment may need model compression or accelerators.
- Data coverage: Robust OOD performance depends on the breadth/quality of cross-embodiment and human trajectory data, plus careful retargeting and QA.
- Safety and compliance: Operation near people and in regulated domains requires certified safety behaviors, reliable fallback/teleop, and auditable logs.
- Operator workflow: Many near-term deployments rely on supervised autonomy with teleop for edge cases; training and ergonomic tools are critical for adoption.
Glossary
- Abduction–adduction: Paired motions moving a digit away from and toward the hand’s midline; common degrees of freedom in finger and thumb joints. "enabling abduction--adduction and flexion--extension."
- Action chunk: A contiguous sequence of actions predicted and executed as a block to ensure temporal consistency. "generating a -length action chunk "
- Anthropomorphic: Human-like in form or function; used to describe robot hands that mimic human anatomy and motion. "a 21-DoF linkage-driven anthropomorphic robotic hand"
- Bimanual: Involving two arms or hands working together. "for bimanual manipulation"
- Biomimetic: Imitating biological structures or behaviors for mechanical design. "ByteDexter V2 implements a biomimetic four-bar linkage mechanism"
- Carpometacarpal (CMC) joint: The base joint of the thumb enabling multi-axis motion critical for dexterity. "the saddle-shaped carpometacarpal (CMC) joint enables flexion--extension and abduction--adduction"
- Constrained optimization: An optimization formulation with explicit constraints on variables or states. "Hand-motion retargeting is formulated as a constrained optimization problem"
- Cross-embodiment: Spanning different robot or human body configurations to transfer skills and data. "cross-embodiment demonstrations"
- Degree-of-Freedom (DoF): An independent parameter of motion or control in a mechanical system. "a 21-DoF linkage-driven anthropomorphic robotic hand"
- Diffusion Transformer (DiT): A transformer-based diffusion model used to generate action sequences. "the action DiT using the flow-matching objective"
- Distal interphalangeal (DIP): The finger joint nearest the fingertip. "and DIP (distal interphalangeal)"
- Egocentric view: A first-person camera viewpoint aligned with the operator or robot perspective. "one primary egocentric view"
- End effector: The tool or hand attached to the end of a robot arm that interacts with objects. "gripper-based end effectors"
- Fingertip-centric alignment: Retargeting strategy that aligns fingertip positions to preserve contact geometry. "This fingertip-centric alignment preserves task-relevant contact geometry"
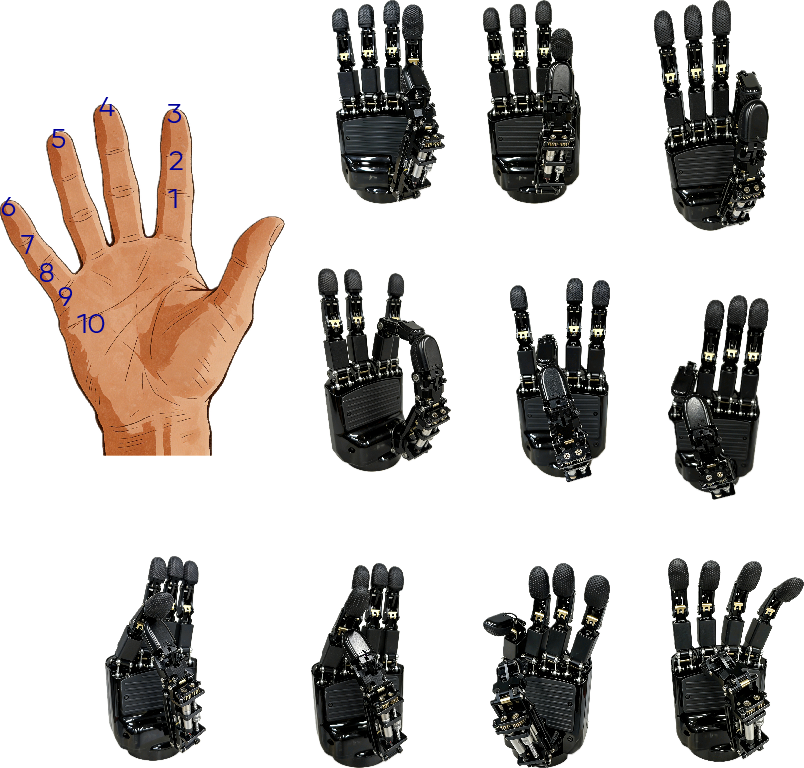
- Feix grasp types: A standardized taxonomy of human grasp patterns used to evaluate grasping capability. "executing all 33 Feix grasp types"
- Flow matching: A training objective that aligns model-generated trajectories with data distributions. "using the flow-matching objective"
- Four-bar linkage: A mechanical linkage of four rigid bars that produces coupled joint motion. "ByteDexter V2 implements a biomimetic four-bar linkage mechanism"
- Kapandji test: A clinical assessment of thumb opposition capability scored from 0–10. "ByteDexter V2 scores 10 in the Kapandji test"
- Kinematic coupling: Intrinsic dependence between joint motions within a mechanism. "reproducing the intrinsic kinematic coupling observed in the human DIP–PIP joint complex"
- Kinematically consistent mapping: A retargeting map that preserves feasible joint kinematics during control. "providing a kinematically consistent mapping"
- Linkage-driven transmission: Actuation via mechanical linkages offering durability and force transparency. "employ a linkage-driven transmission mechanism"
- Metacarpophalangeal (MCP) joint: The finger base joint allowing flexion/extension and abduction/adduction. "a universal joint at the MCP (metacarpophalangeal)"
- Mixture-of-Transformer: An architecture that combines multiple transformer experts for policy modeling. "adopts a Mixture-of-Transformer architecture"
- Next-token-prediction: A language modeling objective predicting the next symbol in a sequence. "via the next-token-prediction objective"
- Occlusion: Visual blockage where parts of the scene are hidden by hands or objects. "frequent hand-object occlusions"
- Out-of-distribution (OOD): Test conditions that differ from the training distribution. "out-of-distribution (OOD) cases"
- Parameterized trajectory optimizer: An optimizer with tunable parameters to smooth and adjust action sequences. "The parameterized trajectory optimizer smooths the generated actions"
- Piezoresistive tactile sensors: Force-sensitive resistive arrays measuring contact at the fingertips. "high-density piezoresistive tactile sensors at the fingertips"
- Policy rollout: Executing a learned policy to produce actions in the environment. "During policy rollout, our model generates future action chunks"
- Proximal interphalangeal (PIP): The middle finger joint between MCP and DIP. "at the PIP (proximal interphalangeal) and DIP (distal interphalangeal)"
- RGB-D cameras: Cameras that capture color (RGB) and depth (D) simultaneously. "a set of global RGB-D cameras"
- Revolute joint: A rotational joint allowing motion around a single axis. "two revolute joints at the PIP (proximal interphalangeal) and DIP (distal interphalangeal)"
- Sequential Quadratic Programming: A numerical method for solving constrained nonlinear optimization problems. "and is solved using Sequential Quadratic Programming"
- Teleoperation: Remote human control of a robot using interfaces like VR and data gloves. "We collect real-world robot data using a bimanual teleoperation interface"
- Thumb opposition: The thumb’s ability to oppose fingertips for grasping and manipulation. "the thumb's opposition capability"
- Underactuation: Having fewer actuators than the total degrees of freedom, leading to coupled motions. "The DIP joints of four fingers and the IP (interphalangeal) joint of the thumb are underactuated"
- Universal joint: A joint allowing rotation around two perpendicular axes. "Each finger comprises a universal joint at the MCP (metacarpophalangeal)"
- Vision-Language-Action (VLA): A model class that integrates visual input, language, and action generation. "Vision-language-action (VLA) models have enabled language-conditioned control"
- Vision-LLM (VLM): A model that processes and aligns visual content with language. "The policy is built on a pre-trained VLM"
- Workspace: The set of positions and orientations that the hand or end effector can reach. "The resulting enlarged reachable workspace enables robust oppositional contact"
- Whole-body controller: A controller coordinating all robot joints (arms and hands) for consistent motion. "via a whole-body controller, providing a kinematically consistent mapping"
Collections
Sign up for free to add this paper to one or more collections.