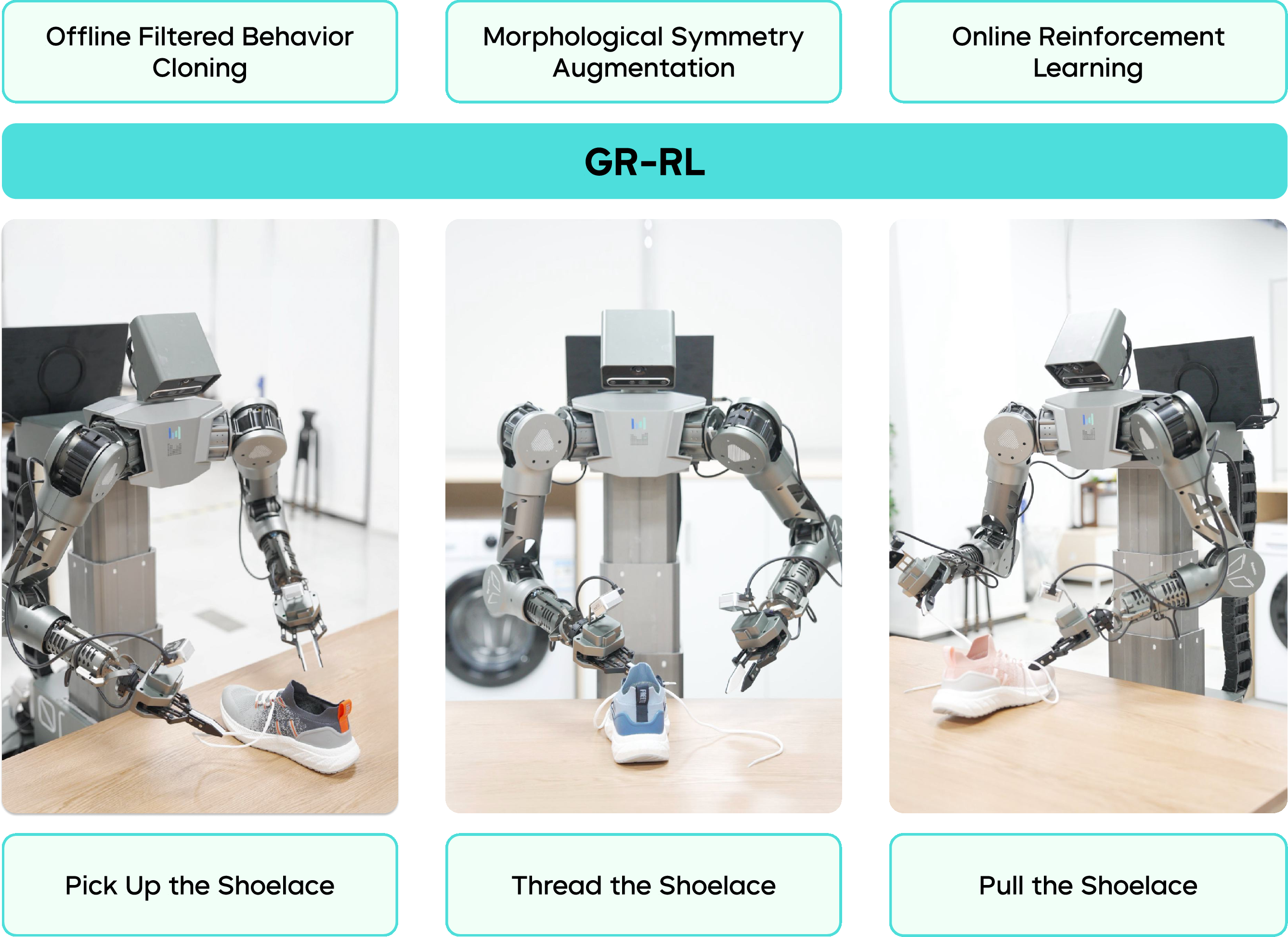
GR-RL: Going Dexterous and Precise for Long-Horizon Robotic Manipulation
Abstract: We present GR-RL, a robotic learning framework that turns a generalist vision-language-action (VLA) policy into a highly capable specialist for long-horizon dexterous manipulation. Assuming the optimality of human demonstrations is core to existing VLA policies. However, we claim that in highly dexterous and precise manipulation tasks, human demonstrations are noisy and suboptimal. GR-RL proposes a multi-stage training pipeline that filters, augments, and reinforces the demonstrations by reinforcement learning. First, GR-RL learns a vision-language-conditioned task progress, filters the demonstration trajectories, and only keeps the transitions that contribute positively to the progress. Specifically, we show that by directly applying offline RL with sparse reward, the resulting $Q$-values can be treated as a robust progress function. Next, we introduce morphological symmetry augmentation that greatly improves the generalization and performance of GR-RL. Lastly, to better align the VLA policy with its deployment behaviors for high-precision control, we perform online RL by learning a latent space noise predictor. With this pipeline, GR-RL is, to our knowledge, the first learning-based policy that can autonomously lace up a shoe by threading shoelaces through multiple eyelets with an 83.3% success rate, a task requiring long-horizon reasoning, millimeter-level precision, and compliant soft-body interaction. We hope GR-RL provides a step toward enabling generalist robot foundations models to specialize into reliable real-world experts.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces GR-RL, a way to train a robot to do very delicate, many-step tasks—like lacing up a shoe—reliably. It starts with a “generalist” robot brain that understands images, language, and actions (a Vision-Language-Action, or VLA, model) and turns it into a “specialist” that can handle tiny, precise movements over a long time without giving up when things go wrong.
Key Questions
The paper focuses on three simple questions:
- How can we clean up and improve noisy human demonstrations so the robot doesn’t learn bad habits?
- How can we help a general-purpose robot practice and become accurate at very precise, multi-step tasks?
- How can we make the robot’s training match what actually happens when it runs in the real world?
Methods and Approach
To make this easy to imagine, think of training a robot like coaching a team:
- First, the robot studies recordings of humans doing the task. But humans sometimes hesitate or make mistakes, especially in very precise tasks. So the robot needs help telling “good moves” from “bad moves.”
- Second, the robot practices both left-handed and right-handed versions of the moves to get more balanced and flexible skills.
- Third, the robot practices for real, gets feedback on how it’s doing, and tweaks its decision-making to match how it actually moves.
Here’s how GR-RL does that in three stages:
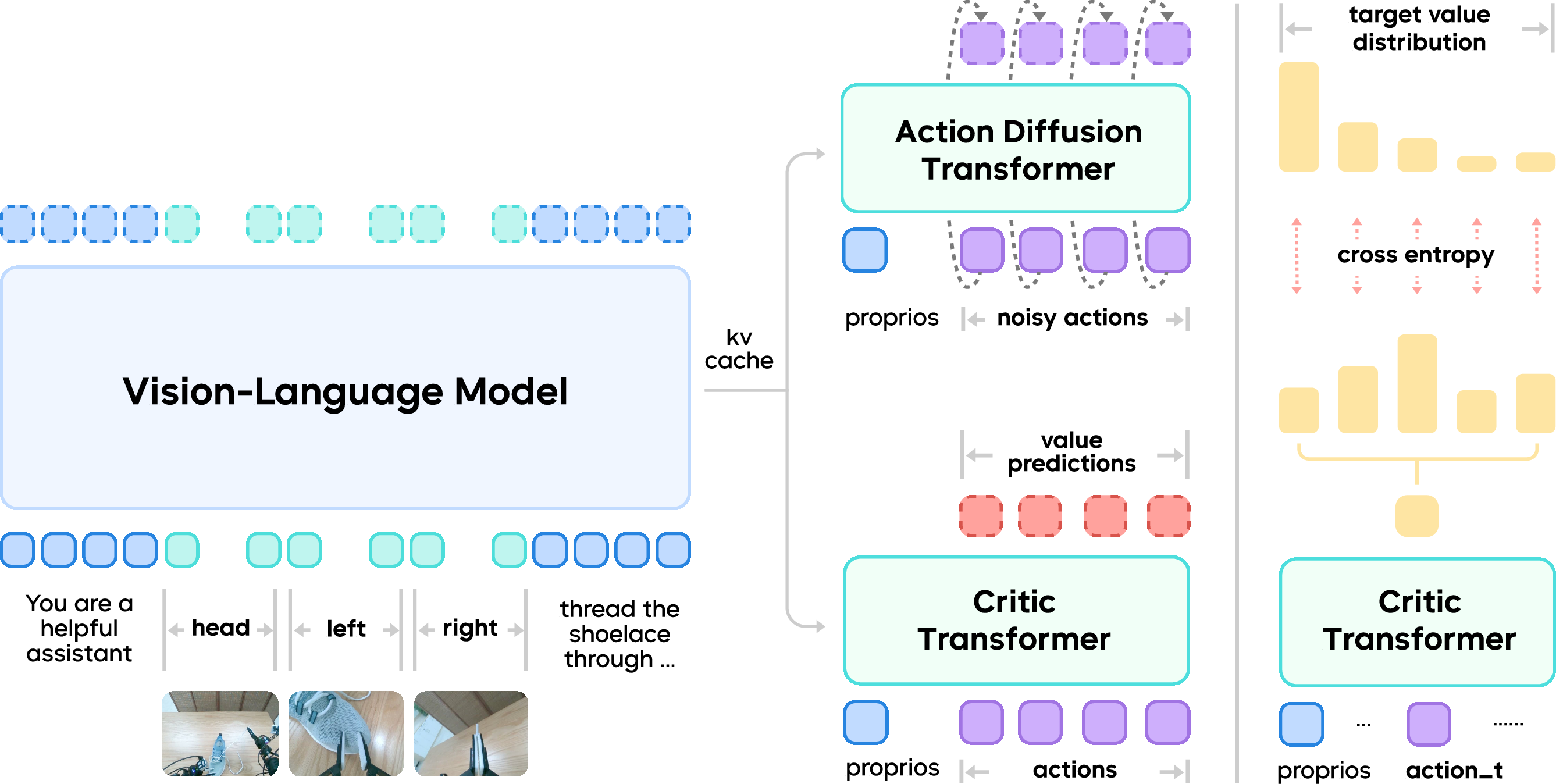
- Stage 1: Learn a “progress bar” and filter the data.
- The robot trains a “critic,” which is like a judge that scores how much a move helps finish the task. Even though the actual reward only comes at the very end (that’s called a “sparse reward”), the critic learns to estimate progress at each step. This progress score acts like a progress bar for the task.
- Using this progress score, the robot filters out parts of the human demonstrations that make the progress drop (like hesitations or mistakes), and keeps the parts that truly help.
- Stage 2: Mirror the actions to double useful practice.
- Many bimanual tasks (using two hands) have left-right symmetry. GR-RL flips camera views and swaps left/right hand actions, and it also flips words in the instruction (like “left hole” becomes “right hole”). It’s like practicing the same trick both ways to get stronger and more adaptable.
- Stage 3: Practice online and “steer” the robot’s decisions.
- When the robot runs for real, the control system smooths its motion to avoid sudden jerks. That means the actions it executes are slightly different from the raw actions it learned to predict—this mismatch can hurt performance.
- GR-RL fixes this by adding a small “noise predictor” that nudges the robot’s internal action generator toward high-scoring choices, based on what the critic says. You can think of this as steering the robot’s creativity: it doesn’t randomly try anything, it gently shifts its suggestions toward moves that lead to success.
- The robot keeps a memory of recent practice episodes (a replay buffer), learns from both fresh and past attempts, and steadily improves.
Technical ideas translated into everyday language:
- VLA model: a robot brain that looks at pictures, reads instructions, and outputs actions.
- Critic: a judge that scores each action by how much it helps finish the task.
- Sparse reward: the robot only gets a point when it finishes correctly; mid-task steps don’t give points directly.
- Distributional critic: instead of one score, the judge predicts a range of possible scores. This makes it more careful, which helps in messy, real-world situations.
- Action chunking: the robot plans short segments of actions at a time, like moving in small, smooth steps.
The robot used is ByteMini-v2, a compact mobile robot with two 7-joint arms. It’s stronger, smaller, and more polished than the previous version, which helps it work in tight spaces and handle the shoe and laces well.
Main Findings
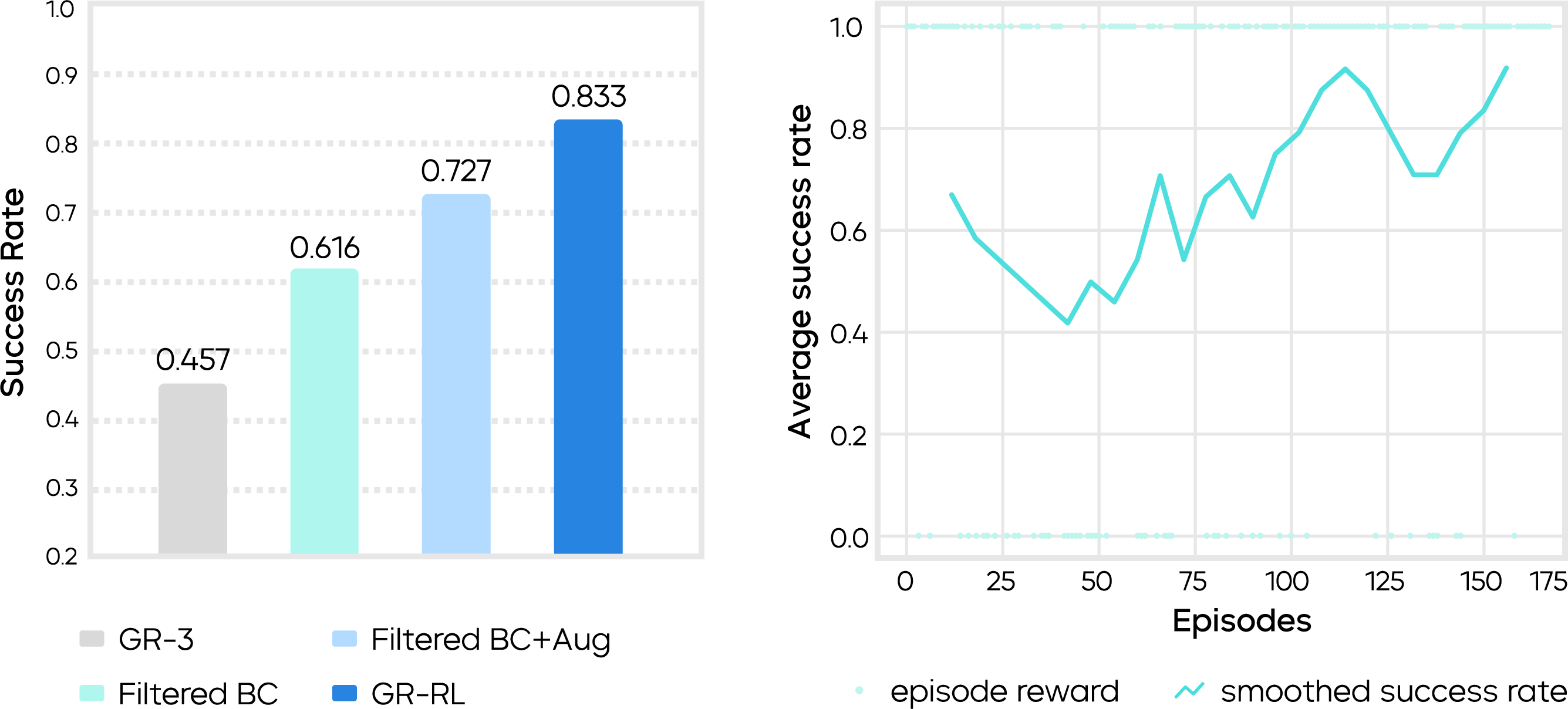
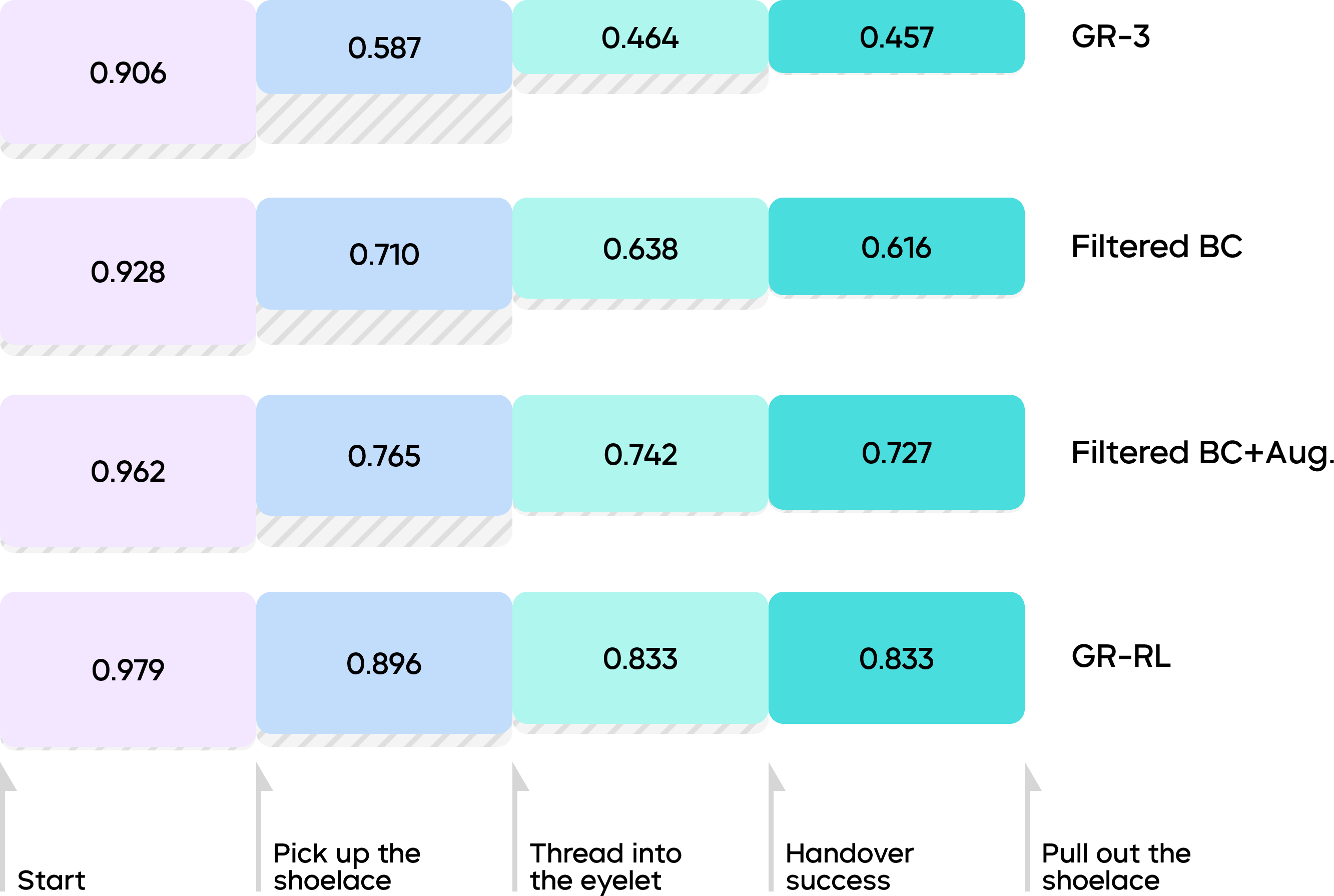
- Starting baseline (generalist model): 45.7% success.
- After filtering out bad parts of demonstrations: 61.6% success.
- After adding mirrored (left-right) data: 72.7% success.
- After online practice with the steering method: 83.3% success lacing shoes through multiple eyelets.
Why this is impressive:
- Lacing a shoe requires long-horizon planning (many steps).
- It demands millimeter-level precision (threading through tiny holes).
- It involves soft, bendy objects (shoelaces and shoes), which are hard for robots.
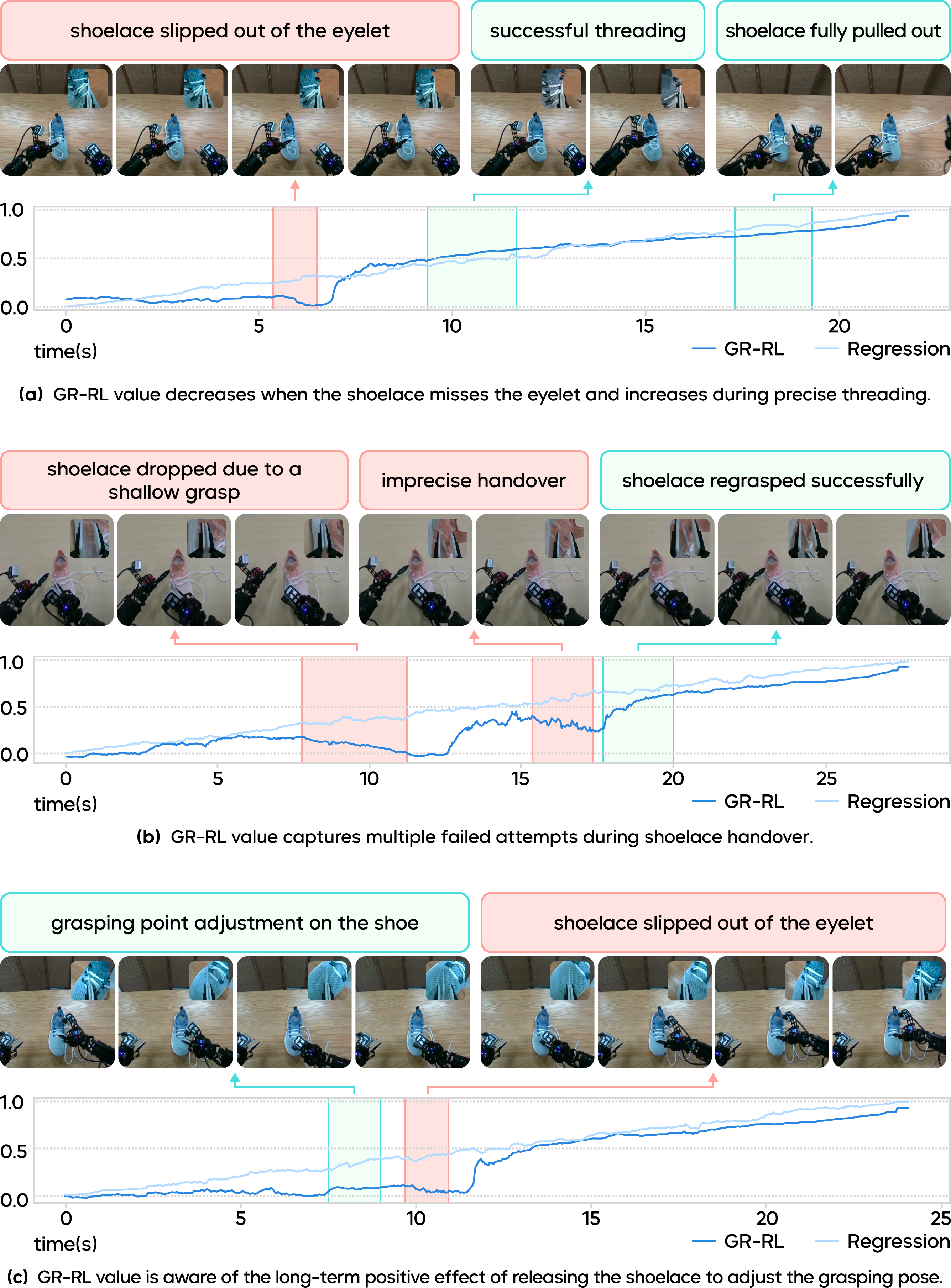
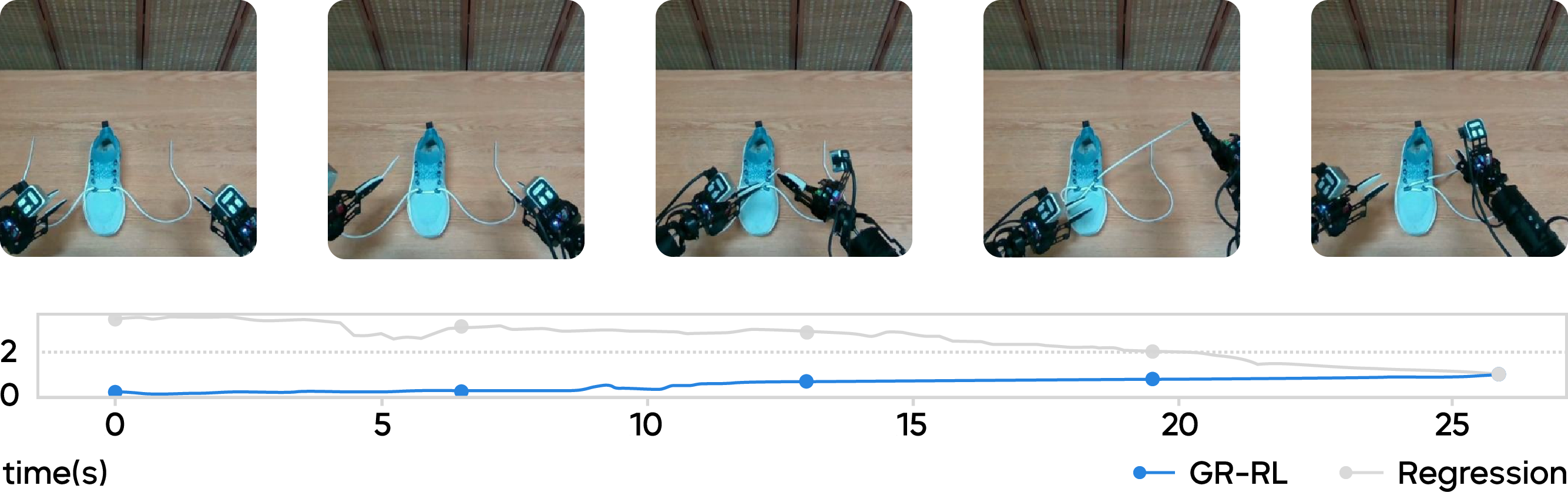
The robot didn’t just follow a fixed script. It showed smart behaviors, like:
- Regrasping the lace if it slipped.
- Retrying if it missed the hole.
- Adjusting the shoe’s position to make threading easier.
- Picking the correct lace even if the ends were crossed.
The paper also tested different ways to estimate progress. The “distributional critic” (the careful judge that predicts a range) worked better than standard methods, especially when rewards were sparse and tasks were long.
Implications and Impact
GR-RL shows how to turn big, general robot models into reliable specialists for tough, real-world tasks. The key idea is to:
- Clean the training data using an RL-based progress judge,
- Augment the data with symmetry (left-right practice),
- Align training with real execution using online RL that steers the robot’s internal action generator.
This approach could help robots master other delicate, multi-step jobs, like threading cables, tying knots, plugging in connectors, or assembling small parts. In short, GR-RL is a step toward robots that are not just “smart,” but also careful, precise, and dependable in the messy, real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions the paper leaves unresolved that future researchers could act on:
- Data requirements and coverage: the paper does not report the size, diversity, and state distribution of the demonstration dataset (e.g., number of trajectories, success/failure ratios), making it unclear how much and what kind of data are needed to reproduce or scale the approach.
- Progress threshold sensitivity: the choice of the value-drop threshold δ for filtering suboptimal transitions is not analyzed; it is unknown how filtering aggressiveness affects performance, data retention rate, and removal of rare-but-useful recovery behaviors.
- Risk of over-filtering recoveries: filtering based on short-horizon value drops may discard transitions that temporarily reduce progress but enable recovery; there is no mechanism to protect such patterns or quantify their loss.
- Manual failure mining: creating failed trajectories relies on manually annotated “retry keyframes”; the paper does not explore automated detection of retries/errors or alternative hindsight relabeling schemes that reduce annotation cost and subjectivity.
- Generality of “value-as-progress”: the paper shows offline distributional Q under sparse rewards works as a progress estimator for shoelacing; there is no theoretical or empirical analysis of when this surrogate is calibrated and monotonic for other tasks, horizons, or reward structures.
- Distributional critic calibration: no calibration metrics (e.g., ECE, AUROC for failure detection, rank correlation with true progress) are reported; it is unclear how well predicted distributions reflect uncertainty and progress across different states and tasks.
- Chunked-Q consistency: the implications of Q-chunking on temporal credit assignment and Markov consistency are not analyzed; it is unknown how chunk length k trades off stability, responsiveness, and value estimation accuracy.
- Morphological symmetry limits: augmentation hinges on left-right symmetry; applicability to asymmetric morphologies, tools, or tasks without clear symmetries is untested.
- Language augmentation robustness: flipping “left/right” in instructions is simple for spatial tokens, but the method’s robustness to richer spatial language, synonyms, and ambiguous phrasing remains unexplored.
- Perception-only precision: the method uses RGB without tactile/force sensing; it is unknown how tactile feedback or force control would impact millimeter-level insertion reliability and contact-rich manipulation safety.
- Inference-time control mismatch: while online RL aims to align with deployment behaviors, the paper does not quantify residual mismatch between training actions and trajectory-optimized actions (e.g., jerk-constrained smoothing) or study training with those optimized actions directly.
- Online RL stability and drift: the paper notes behavior drifting under sparse/noisy rewards; it remains unclear which components (critic bounds, penalty schedules, target networks, conservative objectives) most effectively mitigate drift.
- Latent-space steering capacity: the noise predictor is lightweight (≈51.5M params) and only steers initial noise; the trade-off between its capacity, coverage of the latent manifold, and policy improvement is not studied.
- On-manifold exploration guarantees: penalizing noise norm constrains exploration, but there is no measure of how well actions remain on the offline data manifold; OOD detection or safety shields are absent.
- Frozen backbone constraints: the VLM backbone is frozen during certain stages; the effect of fine-tuning the VLM or action DiT on adaptation, stability, and catastrophic forgetting is not investigated.
- Sample efficiency and ops costs: the paper does not report wall-clock time, resets, human interventions, wear-and-tear, or energy usage for online training; practical costs and scalability of real-world RL remain opaque.
- Safety during exploration: there is no safety layer or constraint handling for exploration (e.g., force limits, collision avoidance around soft objects); methods for safe RL in deformable-object manipulation are left open.
- Generalization beyond shoelacing: evaluation is focused on one long-horizon deformable task; transfer to other precise, contact-rich tasks (e.g., cable routing, knot tying, dressing assistance) is untested.
- Cross-robot transfer: the approach is demonstrated on ByteMini-v2; portability to different robot kinematics, grippers, calibration quality, and sensor suites is not assessed.
- Robustness to environment shifts: quantitative tests under varied lighting, occlusions, eyelet shapes/materials, lace stiffness, shoe poses, and dynamic disturbances are not reported; robustness remains uncertain.
- Instruction generalization: the policy’s sensitivity to varied natural-language instructions (length, ambiguity, compositionality) is not characterized; instruction conditioning fidelity is unclear.
- Horizon scaling: the method’s behavior as horizon increases (more eyelets, multi-stage lacing patterns) is not systematically evaluated; failure accumulation and recovery at larger scales remain open.
- Benchmarking and baselines: comparisons to strong non-learning planners or recent RL/VLA baselines (beyond internal ablations) are limited; standardized benchmarks for long-horizon deformable manipulation would strengthen claims.
- Theoretical guarantees: there are no convergence or performance guarantees for distributional critics as progress surrogates under sparse rewards, nor analysis of bounded-support choices and their implications.
- Model efficiency and deployment: with a 5B-parameter MoT and a 3B VLM, the paper does not quantify real-time inference latency, compute/memory footprint, or the benefits of distillation/quantization for edge deployment.
- Integration of control objectives: jerk/continuity constraints are enforced only at inference; learning to internalize such constraints (e.g., via differentiable control or imitation of optimized trajectories) is not addressed.
- Multi-objective rewards: only binary sparse success is used; incorporating auxiliary shaped rewards (precision, smoothness, contact quality, time) or learned reward models could improve credit assignment but is unexplored.
- Replay composition and freshness: the impact of on-/off-policy buffer ratios, data staleness, and buffer curation on performance and stability is not ablated.
- Open-loop vs closed-loop perception: the approach relies on visual feedback but does not analyze closed-loop correction latency, failure detection timing, or recovery policies when occlusions persist.
- Distillation into generalist policy: the paper notes as future work distilling the improved specialist back into the generalist VLA; methods to preserve generality while retaining precision and dexterity are open.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, drawing directly from GR-RL’s training pipeline, control strategy, and demonstrated performance.
- RL-based demonstration filtering for higher-quality robot learning datasets — Sector: robotics software, research labs, industrial automation — Tools/Workflows: distributional critic that serves as a task-progress scorer; automated filtering of teleoperation logs to keep only progress-increasing transitions; reduced manual labeling effort — Assumptions/Dependencies: availability of both successful and failed trajectories (or “retry keyframe” annotations to synthesize failures); a clear sparse success indicator; integration with existing BC/RL training stacks
- Symmetry (mirror) augmentation for bimanual and morphologically symmetric tasks — Sector: manufacturing (assembly), logistics, household/service robotics, education/research — Tools/Workflows: image flip + wrist-swap + proprioception/action mirroring + instruction text “left/right” flipping; plug-in augmentation module for VLA/BC training — Assumptions/Dependencies: robot morphology exhibits usable left-right symmetry; correct world-to-local frame transforms; instruction text contains spatial cues that can be consistently rewritten
- Latent-space steering for flow/diffusion policies to align training and deployment — Sector: industrial robotics, warehousing, service robotics, academic labs — Tools/Workflows: lightweight noise-predictor head; dual critics (action-space and noise-space); warm-start RL with mixed on/off-policy buffers; deployment-time temporal ensembling and jerk-constrained trajectory optimization — Assumptions/Dependencies: safe online interaction environment; reliable sparse success detection; guardrails for exploration (noise penalty threshold β, physical safety interlocks); sufficient compute and logging for on-robot RL
- Shoe-lacing as a controlled assistive function (demo/pilot) — Sector: retail automation, assistive devices, rehabilitation labs, education/demos — Tools/Workflows: GR-RL policy for threading laces in standardized fixtures (single shoe on a table); scripted recovery behaviors; human override — Assumptions/Dependencies: controlled environment, consistent shoe/lace types, clear success signal (eyelet threading + lace placement), acceptable 83.3% success in pilot contexts; human-in-the-loop supervision for safety
- Flexible-material handling micro-tasks in logistics — Sector: e-commerce fulfillment, packaging — Tools/Workflows: adapting GR-RL pipeline for threading straps through buckles, closing drawstring bags, feeding polybags onto rails; filtered BC + symmetry augmentation + brief online tuning on-site — Assumptions/Dependencies: instrumented success checks (binary outcomes), symmetric task setups, mm-level calibration; throughput requirements that tolerate occasional retries
- Precision insertion and wire routing subroutines in light assembly — Sector: electronics assembly, appliance manufacturing — Tools/Workflows: progress-filtered BC to learn precise cable threading and connector insertion; online RL steering to recover from micro-mistakes; jerk-limited action smoothing for repeatability — Assumptions/Dependencies: reliable visual perception in tight clearances; mechanical fixtures that constrain variance; cycle-time targets compatible with long-horizon control
- Drop-in training recipe for labs and startups — Sector: academia, startups, integrators — Tools/Workflows: “Filtered BC + Symmetry Aug + Online Steering RL” scaffold; off-policy buffer warm-start with rollout data; periodic online updates aligned with deployment actions — Assumptions/Dependencies: minimal engineering to wrap existing VLA backbones; logging, replay, and safety infrastructure; sparse reward definition for the task(s) of interest
- Mobile manipulation in confined spaces with ByteMini-v2-like platforms — Sector: facilities, hospitality, light maintenance — Tools/Workflows: compact mobile base footprint, increased elbow torque for heavier tools, improved wrist spherical joint dexterity; combine with GR-RL for precise long-horizon tasks (e.g., plugging cables, tidying) — Assumptions/Dependencies: access to comparable hardware or retrofits; perception coverage with multiple RGB views; careful motion constraints in cluttered spaces
Long-Term Applications
These use cases require additional research, scale-up, safety engineering, and/or regulatory work before broad deployment.
- Specialist “deformable-object” experts for manufacturing — Sector: automotive, aerospace, consumer electronics — Tools/Workflows: GR-RL-based specialization that threads wires in harnesses, routes cables, inserts gaskets, and manages soft parts on complex assemblies; factory-grade success detection and recovery — Assumptions/Dependencies: robust mm-level vision and calibration; high reliability (>99.9% at line speeds); integration with MES/QA systems; long-tail generalization to varied parts
- Assistive dressing and home-care robots — Sector: healthcare, eldercare, rehabilitation — Tools/Workflows: extended GR-RL policies for dressing tasks (laces, zippers, buttons, straps), with compliant control and safe human-robot interaction; failure-aware retries and language-guided personalization — Assumptions/Dependencies: clinical-grade safety, regulatory approvals, multi-modal sensing (vision + force/tactile), robust success detectors, coverage over diverse body types and clothing
- Surgical dexterity: suture threading and knot tying — Sector: surgery, interventional robotics — Tools/Workflows: GR-RL-style filtering and online steering for long-horizon, mm-level suturing and ligature tying; distributional critics for progress under sparse/rare success signals — Assumptions/Dependencies: high-fidelity perception in operative fields; advanced haptics; stringent validation and certification; extremely low tolerance for errors
- Household generalist robots capable of complex, multi-step tasks — Sector: consumer robotics — Tools/Workflows: pipeline to specialize generalist VLAs into reliable experts for folding clothes, making beds, cable management, bag closure, plant care; on-device online RL with strict safety bounds — Assumptions/Dependencies: affordable hardware, robust home perception, standardized success detectors for domestic tasks, graceful failure recovery, user trust and UX
- Standardized dataset curation policies and tooling for robot learning — Sector: policy/standards, software tooling — Tools/Workflows: progress-based filtering as a “quality gate” for demonstration datasets; shared schemas for retry keyframes and sparse rewards; audit trails for dataset provenance — Assumptions/Dependencies: community agreement on success criteria; benchmarking against shared tasks; alignment with data governance and privacy regulations
- Productization of a GR-RL Toolkit — Sector: robotics platforms, software vendors — Tools/Workflows: packaged modules for distributional critics, Q-chunking, symmetry augmentation, latent-space steering, jerk-constrained controllers; APIs compatible with ROS, SERL, and popular VLA backbones — Assumptions/Dependencies: sustained maintenance and support; broad hardware compatibility; clear metrics and diagnostics for progress and safety
- Safety and regulatory frameworks for online RL on physical robots — Sector: policy/regulation, compliance, risk management — Tools/Workflows: standards for exploration limits, fail-safes, event logging, post-hoc analysis of policy updates; certification pathways for adaptive systems — Assumptions/Dependencies: involvement of regulators and insurers; incident reporting infrastructure; harmonization across jurisdictions
- Cross-robot symmetry augmentation beyond bimanual systems — Sector: robotics R&D — Tools/Workflows: generalized morphological augmentation that maps between heterogeneous kinematics (e.g., single-arm to dual-arm, different gripper geometries); language-grounded spatial rewriting — Assumptions/Dependencies: reliable cross-robot calibration; learned equivalence mappings; prevention of harmful distribution shifts when symmetry assumptions partially fail
Notes on feasibility across applications:
- Success detection and sparse rewards are central; tasks must provide reliable binary success signals or proxies.
- Safety interlocks and motion constraints (e.g., jerk limits) are needed for any online RL on hardware.
- Symmetry augmentation assumes accurate transforms and consistent spatial language; incorrect rewrites can degrade performance.
- Scaling to safety-critical domains (healthcare, surgery) requires orders-of-magnitude improvements in reliability, comprehensive sensing (including force/tactile), and formal validation.
Glossary
- Action chunk: A fixed-length sequence of low-level actions produced together by the policy. "generating a -length action chunk "
- Action Diffusion Transformer (DiT): A transformer-based diffusion model that generates actions. "an action diffusion transformer (DiT) trained by flow matching objectives"
- Action modality: The action channel added to multimodal models so they can output robot actions. "adapting the vision-LLMs (VLMs) pretrained with web-scale data to robotic actions by adding the action modality"
- Asynchronous receding horizon control: A control strategy that plans and executes over a shifting time window asynchronously. "asynchronous receding horizon control"
- Behavior cloning: Supervised imitation learning that trains a policy to mimic demonstration actions. "offline filtered behavior cloning with learned task progress"
- Bimanual: Relating to the use of two robotic arms or hands for manipulation. "our bimanual task settings"
- Categorical distribution: A discrete probability distribution used here to represent value distributions for robustness. "compute its mean value of the categorical distribution as progress"
- Causal transformer: An autoregressive transformer that processes inputs with causal (time-forward) masking. "is a causal transformer that evaluates each action"
- Discount factor: The parameter in RL that exponentially down-weights future rewards. "and means the discount factor."
- Distribution shift: A change in data distribution between training and deployment causing performance degradation. "due to the distribution shift from offline to online RL."
- Distributional critic: A value estimator that predicts a distribution over returns instead of a single scalar. "We adopt distributional critics and observe that they give much more robust performance under offline sparse reward scenarios."
- Distributional reinforcement learning: RL that models the full distribution of returns rather than only their expectation. "and adopt distributional reinforcement learning"
- DoF (Degrees of Freedom): Independent controllable axes of motion in a robot mechanism. "7-DoF dual robotic arms"
- Flow matching objectives: Training objectives for continuous-time flow models that align vector fields with data. "trained by flow matching objectives"
- Flow policy: A policy represented as a continuous-time flow model that can be steered via latent variables. "steer the trained flow policy"
- Indicator function: A function that returns 1 if a condition holds and 0 otherwise, used to mark success. "where is an indicator function to evaluate whether a trajectory is successful or not"
- Jerk: The rate of change of acceleration; constraints on jerk help ensure smooth motion. "imposes constraints on jerk and temporal continuity"
- KV cache: Cached key-value activations from transformer layers to accelerate inference. "use only the KV cache from the latter half of the VLM layers for fast inference"
- Latent space noise predictor: A model that predicts initial diffusion noise in latent space to steer action generation. "we perform online RL by learning a latent space noise predictor."
- Mixture-of-Transformer (MoT) architecture: An architecture that combines multiple transformer components in a mixture. "adopts a Mixture-of-Transformer (MoT) architecture."
- Morphological symmetry augmentation: Data augmentation leveraging the robot’s mirrored morphology to improve generalization. "we introduce morphological symmetry augmentation that greatly improves the generalization and performance of GR-RL."
- Noise transformer: A transformer module that predicts noise used to initialize diffusion-based action generation. "The online training objectives for the noise transformer"
- Off-policy buffer: A memory store of trajectories collected by past policies used for off-policy learning. "we maintain an off-policy buffer and an on-policy buffer"
- Offline reinforcement learning (RL): RL performed on a fixed dataset without further environment interaction. "train a critic model on both successful and failed trajectories with offline reinforcement learning (RL)"
- On-policy buffer: A buffer that stores trajectories generated by the current (or most recent) policy. "we maintain an off-policy buffer and an on-policy buffer"
- Online reinforcement learning: RL that improves a policy through active, ongoing interaction with the environment. "we perform online reinforcement learning to further explore and fix the failure modes of the base policy."
- Proprioception states: Internal sensing signals of the robot (e.g., joint positions/velocities). "proprioception states"
- Q-chunking: Predicting a chunk of Q-values aligned with an action chunk for coarse-to-fine evaluation. "we follow -chunking"
- Q-values: Expected return estimates for state-action pairs in RL. "the resulting -values can be treated as a robust progress function."
- Receding horizon control: Model predictive control that optimizes over a moving finite horizon. "whole-body receding horizon control"
- Replay buffer: A memory of past transitions used to train off-policy RL algorithms. "off-policy replay buffer"
- Sparse reward: A reward signal provided only at rare events such as successful completion. "Given a sparse reward at the end of the episode"
- Temporal ensembling: Smoothing actions or predictions over time via aggregation to ensure continuity. "temporal ensembling"
- Temporal difference learning: A method that learns value functions by bootstrapping from future estimates. "With temporal difference learning over both successful and failed data"
- Temporal-Difference (TD) errors: The residuals between predicted and bootstrapped values used to update value estimates. "Temporal-Difference (TD) errors via distributional reinforcement learning."
- Trajectory optimization: Refining action sequences to satisfy smoothness or dynamic constraints. "we incorporate a trajectory optimization module"
- Vision-Language-Action (VLA) model: A multimodal model that consumes vision and language to output actions. "vision-language-action (VLA) model"
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs. "Vision-Language-Model (VLM) backbone"
- Wrist spherical joint: A multi-DoF joint at the wrist allowing rotation about multiple axes. "featuring a unique wrist spherical joint design"
Collections
Sign up for free to add this paper to one or more collections.