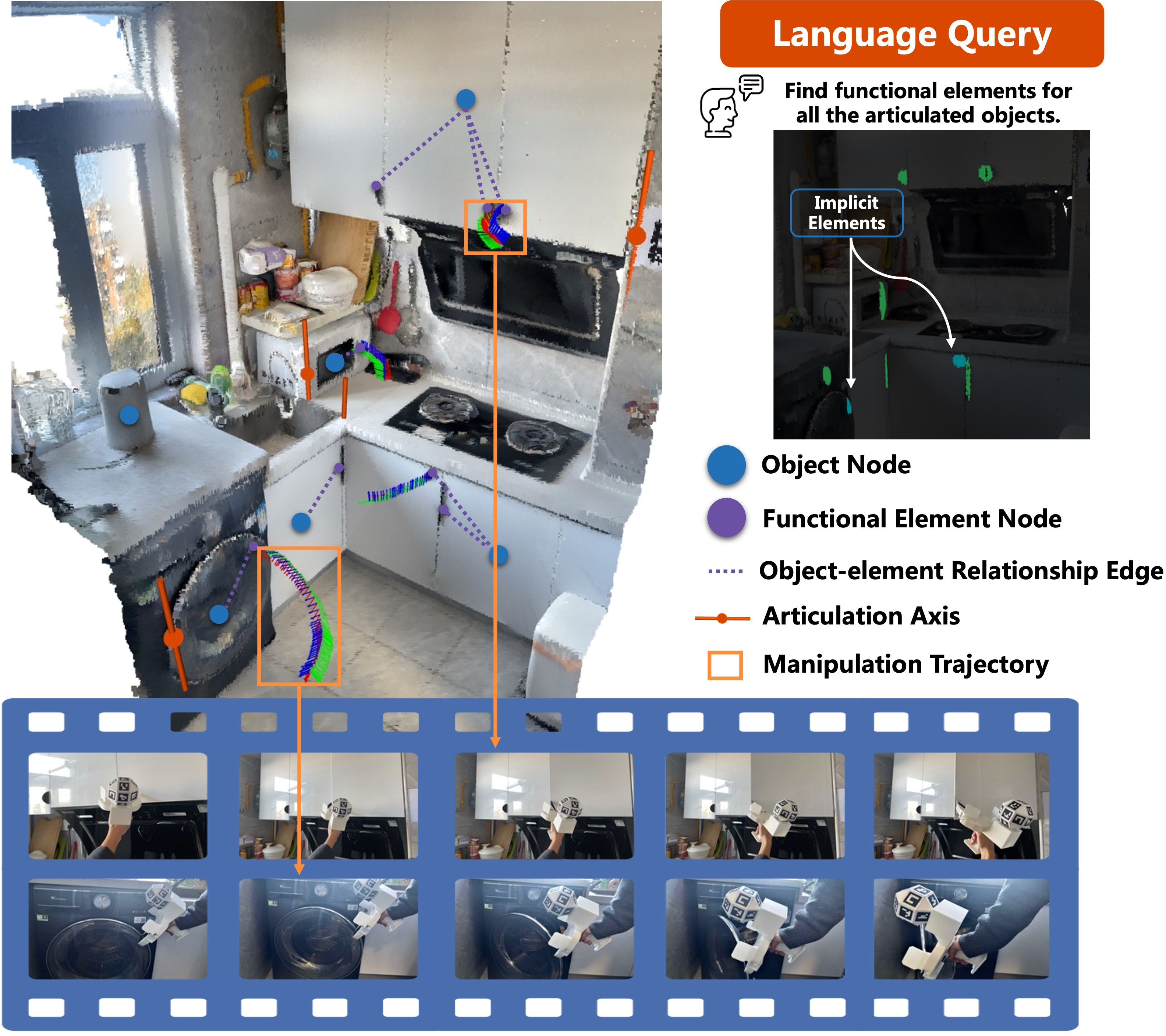
ArtiSG: Functional 3D Scene Graph Construction via Human-demonstrated Articulated Objects Manipulation
Abstract: 3D scene graphs have empowered robots with semantic understanding for navigation and planning, yet they often lack the functional information required for physical manipulation, particularly regarding articulated objects. Existing approaches for inferring articulation mechanisms from static observations are prone to visual ambiguity, while methods that estimate parameters from state changes typically rely on constrained settings such as fixed cameras and unobstructed views. Furthermore, fine-grained functional elements like small handles are frequently missed by general object detectors. To bridge this gap, we present ArtiSG, a framework that constructs functional 3D scene graphs by encoding human demonstrations into structured robotic memory. Our approach leverages a robust articulation data collection pipeline utilizing a portable setup to accurately estimate 6-DoF articulation trajectories and axes even under camera ego-motion. We integrate these kinematic priors into a hierarchical and open-vocabulary graph while utilizing interaction data to discover inconspicuous functional elements missed by visual perception. Extensive real-world experiments demonstrate that ArtiSG significantly outperforms baselines in functional element recall and articulation estimation precision. Moreover, we show that the constructed graph serves as a reliable functional memory that effectively guides robots to perform language-directed manipulation tasks in real-world environments containing diverse articulated objects.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
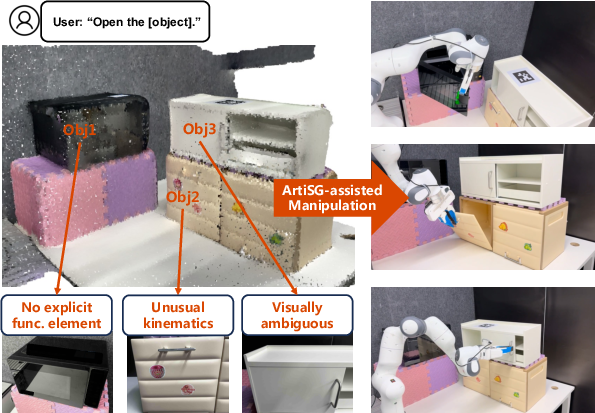
This paper introduces ArtiSG, a way to build a smart 3D “map” of a room that doesn’t just know what objects are where, but also understands how their parts work. Think of things like doors, drawers, buttons, and handles. ArtiSG watches a person demonstrate how to use these objects and turns that into a kind of memory the robot can use later to manipulate the same objects on its own.
What questions did the researchers ask?
They focused on three simple questions:
- How can a robot’s 3D map include not just object names and shapes, but also how their parts move (for example, sliding vs. rotating)?
- How can we collect good movement data even if the camera or person is moving around?
- How can we help the robot find small, hard-to-see parts (like tiny handles) that normal vision systems often miss?
How did they do it?
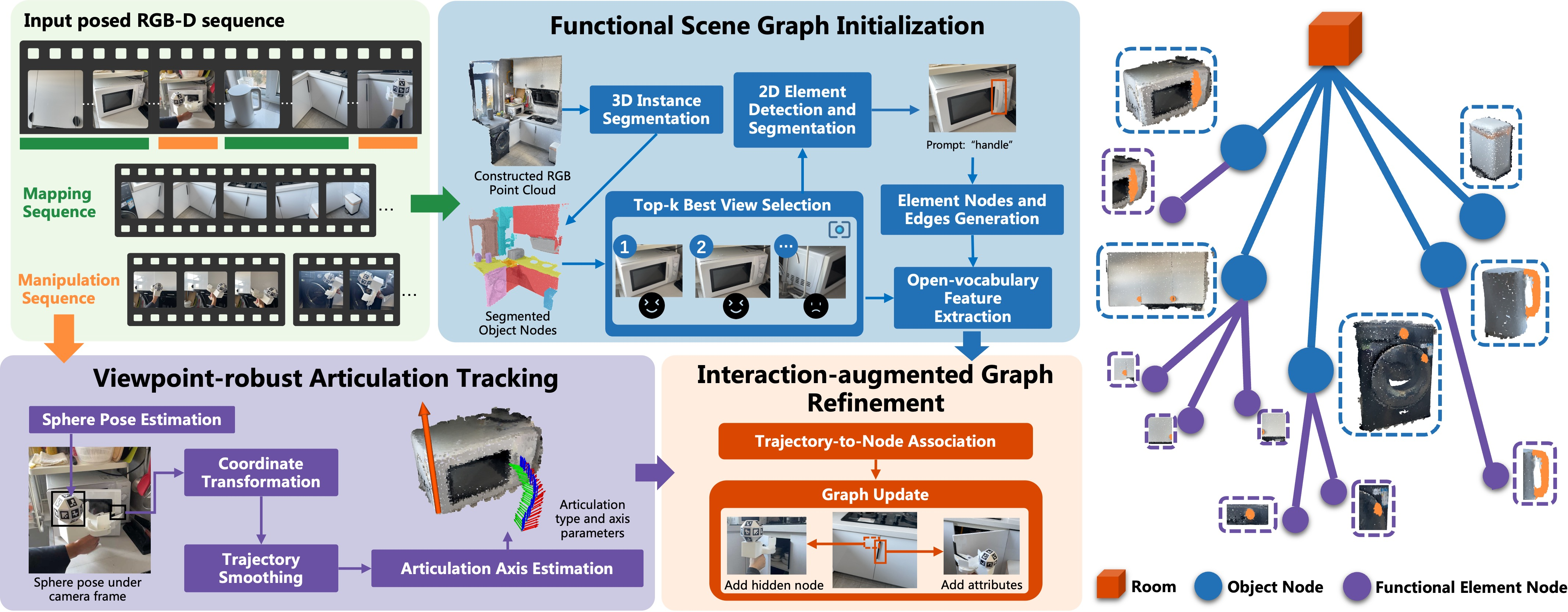
The approach has three main steps. You can imagine building a detailed guidebook for the robot: first you draw the map, then you add “how to use” tips, and finally you fill in any missing details.
Step 1: Build a smart 3D map
- The system scans a room with a camera to make a 3D point cloud (a detailed set of dots representing surfaces).
- It finds objects (like a cabinet or microwave) and also tries to spot their functional parts (like handles and knobs) using strong vision tools.
- It picks the best camera views (“top-k frames”) where the parts are most visible, so it can understand them better and avoid confusion from bad angles.
- It stores both geometry (shape and position) and open-vocabulary features (semantic clues from language, like “handle” or “knob”), so later you can search with natural words.
Step 2: Learn how parts move from human demos
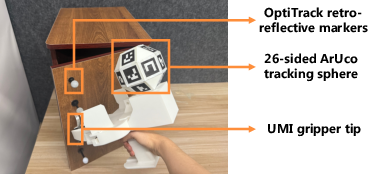
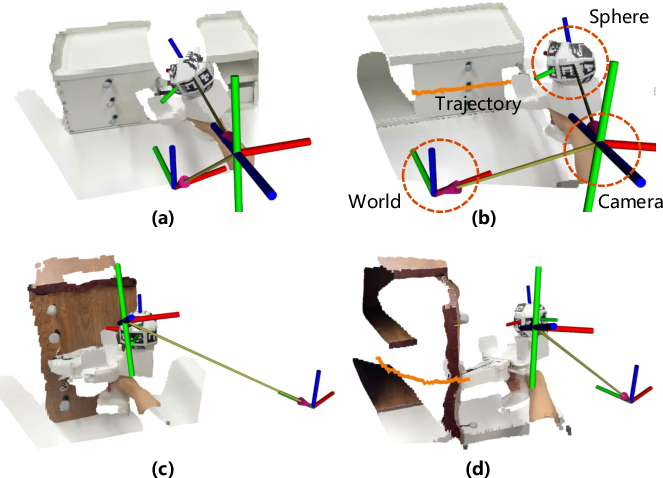
- A person uses a simple handheld gripper with a ball covered in special markers. A head-mounted camera watches this and tracks the gripper’s 3D position and orientation over time. This gives a clean “6-DoF” trajectory, which means the full pose in 3D (x, y, z position plus roll, pitch, yaw rotation).
- As the person opens or closes something, the system records the motion, smoothing it with a filter so it’s not jittery.
- It then figures out the type of movement:
- Prismatic joint: slides along a straight line (like a drawer).
- Revolute joint: rotates around an axis (like a door on hinges).
- Using math tools that fit lines or circles, it estimates the movement axis direction and the center point. In everyday terms, it discovers the “track” the part moves on and where it rotates or slides.
Step 3: Add missing details using interaction
- The system matches the recorded motion to the map. If it finds the element already in the map, it attaches the movement info to that element. If it doesn’t, it creates a new “functional element” node (for example, a hidden latch it didn’t see before).
- This turns the map into a functional memory: not just where parts are, but how to use them.
What did they find?
- ArtiSG is better at finding small functional parts than other methods, especially in real-world scenes. Watching human demonstrations helps uncover handles or buttons that were too small, hidden, or hard to detect with visual tools alone.
- It estimates how parts move more accurately than methods that only look at static images or rely on tracking texture in videos. The special gripper and camera setup stays reliable even if the person or camera moves around.
- The resulting 3D scene graph is useful: when a robot is told in natural language to “Open the cabinet” or “Open the microwave,” ArtiSG can look up the right part and its movement trajectory and guide the robot to perform the action successfully.
Why does this matter?
Robots need more than names and locations—they need to know how things work to interact safely and effectively. With ArtiSG:
- Robots can learn how to manipulate everyday objects by watching humans, much like how kids learn by observing.
- The robot’s internal “map” becomes a practical how-to guide, not just a picture. This makes home, office, and kitchen tasks more reliable.
- It handles tricky cases like unusual doors, flip-down panels, or tiny hidden elements that confuse vision-only methods.
Potential impact and future directions
This research could make robots better helpers in the real world—opening drawers, doors, and appliances, and following natural language instructions more reliably. In the future, the team plans to:
- Make the setup even more portable by removing printed markers (markerless tracking).
- Combine ArtiSG’s kinematic “know-how” with general robot skills, so robots can plan and execute tasks faster and with fewer mistakes.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide future research and engineering efforts.
- Reliance on instrumented demonstrations: The approach depends on a UMI gripper with an ArUco-marked tracking sphere and a head-mounted RGB-D device with SLAM, limiting portability and scalability; it remains unclear how to replace markers and specialized hardware with robust markerless tracking while maintaining accuracy under ego-motion and occlusions.
- Limited kinematic expressivity: Only prismatic and revolute joints are modeled; compound, coupled, or higher-DoF mechanisms (e.g., planar joints, screw joints, sliders with limits, linkages, compliant or elastic closures) are not supported or detected.
- Missing joint limits and dynamics: Estimated models lack joint bounds, directionality (e.g., open vs. close), friction, damping, and torque/force profiles—information often needed for safe and robust execution.
- Uncertainty quantification absent: Axis and trajectory estimation provide point estimates without uncertainty/confidence measures; there is no propagation of uncertainty into graph attributes or downstream planning.
- Sensitivity to short or noisy demonstrations: The axis-fitting procedure (SVD + least squares) can be ill-conditioned for small motion arcs, partial trajectories, or demonstrations with slip; no analysis of minimal motion length, SNR requirements, or robustness to outliers (e.g., no RANSAC-based fitting).
- Slippage and non-rigid contacts: The method assumes rigid coupling between gripper and functional element; no detection or correction for slippage, soft contacts, or deformable handles/panels.
- Sparse association logic: Trajectory-to-node association uses nearest-centroid with a threshold, which may fail in dense or cluttered settings with multiple nearby elements; no probabilistic data association, geometric constraint checking, or learned association models are explored.
- Incomplete element geometry for interaction-discovered nodes: When a functional element is missed by vision and later instantiated from demonstrations, its geometric representation may be poor or absent beyond a centroid; methods to reconstruct or refine geometry from limited views are not provided.
- Narrow prompt set for element detection: Element discovery uses fixed prompts (e.g., “handle”, “knob”), likely missing buttons, latches, hinges, touch panels, sliders, magnetic catches, or push-to-open panels; the paper does not investigate systematic expansion to a richer, task-driven, or learned open-vocabulary for element classes.
- Multi-view semantic consistency not enforced: While top-k frames are used, there is no explicit cross-view consistency checking or label fusion to resolve contradictory detections/segmentations from vision-LLMs.
- SLAM dependence and drift: Robustness to SLAM drift, relocalization failures, rolling-shutter effects, and device variability is not measured; there is no loop-closure-informed correction or global alignment verification for the recorded manipulation trajectories.
- Calibration assumptions untested: The method assumes fixed, pre-calibrated transforms (sphere-to-tip, camera intrinsics/extrinsics); procedures for on-the-fly calibration, drift detection, or auto-recalibration in the wild are not studied.
- Handling occlusion and visibility loss: The ArUco pose estimation relies on marker visibility; failure modes under prolonged occlusions, fast motion blur, and adverse lighting are not quantified, nor are recovery strategies described.
- Dataset scale and diversity: Real-world evaluation covers 79 articulated objects and 139 elements in a few scenes; there is no analysis across diverse object categories, materials (glossy/transparent), lighting, clutter levels, and cultural/industrial environments.
- Baseline coverage and fairness: Comparisons omit interaction-centric baselines (e.g., Ditto-style before/after methods with mobile cameras) under comparable conditions; joint-type misclassification rates and ablations on the model selection penalty are not reported.
- Limited downstream evaluation: Robot experiments are qualitative on a handful of objects without statistics on success rate, time-to-completion, safety incidents, or robustness to pose/placement variations, lighting shifts, or repeated trials.
- Transfer across embodiments: The paper does not analyze how stored human-demonstrated trajectories transfer to robots with different kinematics, end-effectors, reachability constraints, or compliance properties; re-targeting strategies and feasibility checks are missing.
- World-to-robot frame alignment: Application details for registering the scene graph/world frame to the robot base frame are not explained; calibration pipelines and their error impact remain unreported.
- Real-time performance and resource use: There is no profiling of computation time, latency, and memory for top-k selection, open-vocabulary feature extraction, multi-view fusion, and tracking; real-time viability on embedded platforms is unknown.
- Lifelong updates and change handling: The graph does not model or detect changes in articulation state, environment rearrangements, or element wear/failure over time; policies for updating, versioning, or forgetting stale functional information are not addressed.
- Sequential affordances and dependencies: Multi-step interactions (e.g., unlatch before opening), inter-element constraints, or dependency graphs (e.g., which element enables another) are not modeled.
- Symmetry and duplication: The system does not reason about symmetric or repeated elements (e.g., cabinet pairs), which could aid detection, association, and trajectory reuse.
- Safety and compliance: The paper does not consider safety constraints, force control, compliance, or sensing for delicate operations; replaying trajectories without force feedback may risk damage.
- Language grounding depth: Open-vocabulary retrieval is evaluated via R@k, but complex language referring to function, relational context, or instruction parsing (e.g., “press the release latch above the left hinge”) is not tested; multilingual robustness is unexplored.
- Multi-user and inter-demonstration variability: The effect of different users’ demonstrations (speed, path style, noise) and methods for aggregating multiple demos into a canonical, uncertainty-aware model are not studied.
- Active data collection strategies: No method is proposed to prioritize which elements to demonstrate, how to cover a space efficiently, or how to autonomously request demonstrations when uncertainty is high.
- Ethical/privacy considerations: Head-mounted recording in human environments raises privacy concerns; policies for anonymization, on-device processing, or consent management are not discussed.
- Reproducibility and release: There is no explicit commitment to release code, datasets, calibration files, or standardized evaluation protocols for the community to reproduce and extend results.
Practical Applications
Immediate Applications
The following applications can be deployed with the current ArtiSG framework and its portable hardware setup (head-mounted RGB-D camera with SLAM and UMI gripper + ArUco sphere), plus off-the-shelf VFM tools (Grounding DINO, SAM, SigLIP2) and standard robotics stacks (e.g., ROS/MoveIt).
- Commissioning mobile manipulators by “teach-and-repeat”
- Sector: robotics (service, household, hospitality), manufacturing (workcell setup), education/research labs
- Application: Rapidly onboard robots in a new environment by scanning, demonstrating openings (doors, drawers, appliances), auto-fitting articulation axes, and storing trajectories to the functional scene graph. Language commands (“Open the microwave”) retrieve the right element and 6-DoF path.
- Tools/Workflow:
ArtiSG Capture Kit(head-mounted RGB-D + UMI gripper),Functional Scene Graph Serverwith open-vocabulary query, ROS2 node that publishes kinematic priors to controllers, top-k view selection for semantic robustness. - Assumptions/Dependencies: Human demonstrations available; robot has sufficient reach and compliance; prismatic/revolute motions cover the object; marker visibility for tracking; environment SLAM quality.
- Facility functional twins for operations and maintenance
- Sector: facilities management, construction/BIM, real estate
- Application: Build a “functional memory” of buildings—doors, cabinets, panels—annotated with handle locations, articulation types/axes, and safe manipulation trajectories. Use for onboarding staff, maintenance scheduling, and asset documentation.
- Tools/Workflow:
Facility Functional Twindatabase, multi-room scanning + demonstration pass, open-vocabulary retrieval (“find flip-down panels”), integration with BIM viewers and CMMS. - Assumptions/Dependencies: Indoor geometry mapped with RGB-D; prompts cover typical functional elements (“handle”, “knob”); privacy/compliance for recording; compute for VFM inference.
- Assistive and domestic robots: learn-by-demonstration for daily tasks
- Sector: healthcare (assistive living), smart home
- Application: Caregivers or residents demonstrate opening appliances, cabinets, medication drawers; robots reuse stored trajectories to perform tasks reliably despite visual ambiguity.
- Tools/Workflow:
Teach-at-homeapp to record demonstrations; on-device functional graph query; safe motion executor with grasp/force limits. - Assumptions/Dependencies: Clear handle access during demo; robot dexterity/gripper compatibility; safe demonstration protocols; marker tracking continuity.
- AR guidance for technicians and users
- Sector: education, facilities, industrial training
- Application: Overlay element locations and articulation directions (e.g., “pull along axis,” “rotate around here”) to reduce training time and errors when operating unfamiliar devices.
- Tools/Workflow: AR headset/app reading the functional scene graph; open-vocabulary search to highlight elements (e.g., “show all flip-down compartments”).
- Assumptions/Dependencies: Accurate registration between AR view and mapped environment; dependable SLAM; multi-view feature aggregation to avoid occlusion-induced errors.
- Data curation and QA for vision foundation models on functional elements
- Sector: software/AI, academia
- Application: Use interaction-augmented detection to find elements missed by VFM (handles/buttons), improving recall and building labeled 3D datasets for training/evaluation.
- Tools/Workflow:
Interaction-Augmented Labelerthat fuses demonstrations with SAM/Grounding DINO detections; metrics for recall/precision and R@k retrieval; batch export to dataset formats. - Assumptions/Dependencies: Sufficient demo coverage; consistent world-frame registration; policy for data privacy and annotation quality.
- Robotic manipulation research: kinematic priors for planning and policy learning
- Sector: academia, robotics R&D
- Application: Plug ArtiSG kinematic priors into planners and imitation/RL policies to reduce search and failure in articulated object manipulation; benchmark experiments on prismatic/revolute joints under ego-motion.
- Tools/Workflow:
Kinematic Prior Pluginfor planners (MoveIt, TAMP), dataset and evaluation suite (trajectory RMSE, axis angle/position errors), integration with language-conditioned policies. - Assumptions/Dependencies: Access to the capture hardware; reproducible calibration; availability of challenging object sets (textureless/occluded).
- Rapid changeover in flexible manufacturing fixtures
- Sector: manufacturing
- Application: Demonstrate how to operate new fixtures, clamps, and access panels; store articulated motions for robots to perform repeatable setup/tear-down without bespoke programming.
- Tools/Workflow: Workcell scan + demonstration; scene graph-backed macro scripts for setup operations; safety checks with axis constraints.
- Assumptions/Dependencies: Fixtures’ motions fit prismatic/revolute models; industrial safety compliance; minimal occlusions during capture.
- Emergency and field robotics “just-in-time” operation mapping
- Sector: public safety, utilities, maintenance
- Application: Rapidly record critical operations (e.g., opening access cabinets, switching panels) via human demonstration; teleoperated/field robots replay trajectories reliably in visually degraded conditions.
- Tools/Workflow: Portable capture kit, lightweight graph server, offline replay with path verification; language prompts to query critical elements.
- Assumptions/Dependencies: Short capture windows; clear marker visibility; safe force application; compliance with site access/security.
Long-Term Applications
These applications require further research, scaling, standardization, or hardware advancements (e.g., markerless tracking, broader articulation types, large-scale deployments).
- Markerless manipulation tracking and ultra-portable capture
- Sector: robotics, software/AI
- Application: Replace the ArUco sphere with markerless hands/gripper tracking and robust 3D keypoint recovery under occlusion for in-the-wild collection.
- Tools/Workflow: Foundation models for 3D hand/gripper pose; temporal fusion with SLAM; uncertainty-aware filters;
Markerless ArtiSGpipeline. - Assumptions/Dependencies: Reliable markerless tracking on textureless surfaces; occlusion resilience; high-fidelity calibration; compute on edge devices.
- City- or campus-scale functional maps and interoperability standards
- Sector: policy, smart cities, building automation
- Application: Maintain standardized functional scene graphs across buildings for emergency response, accessibility audits, and automation; define APIs so robots/building systems can consume a common “functional twin.”
- Tools/Workflow:
Functional Graph Standard(schema, kinematic attributes, vocabularies), integration with BIM/IFC and automation standards (e.g., OPC UA), governance and privacy frameworks. - Assumptions/Dependencies: Stakeholder buy-in; data-sharing policies; versioning and change tracking; cybersecurity; multilingual open-vocabulary support.
- Manufacturer-provided “function cards” for appliances
- Sector: consumer electronics, industrial equipment
- Application: Ship appliances with machine-readable articulation graphs (element locations, axes, recommended trajectories), enabling plug-and-play robotic operation without on-site demos.
- Tools/Workflow:
Function Cardmetadata embedded in QR/NFC or cloud; robot reads and adapts trajectory to local geometry; alignment procedures. - Assumptions/Dependencies: Industry adoption and standardization; calibration pipelines for geometric alignment; legal/safety liability clarity.
- Autonomous discovery of functional elements via active exploration
- Sector: robotics
- Application: Robots plan exploratory interactions to discover handles/buttons and infer articulation axes without human demos, using ArtiSG priors to guide safe probing and learning.
- Tools/Workflow: Active perception policies with uncertainty-driven actions; closed-loop tracking and axis fitting; risk-aware contact strategies.
- Assumptions/Dependencies: Reliable contact sensing; safe exploration constraints; robust recovery from failed probes; more general articulation models.
- Integrated task-and-motion planning with functional priors
- Sector: robotics, software/AI
- Application: Use ArtiSG’s kinematic memory within TAMP/MBRL pipelines to plan multi-step tasks (e.g., open door, retrieve item, close) with reduced search complexity and failure rates.
- Tools/Workflow:
Functional-TAMPintegration layer; constraint solvers consuming axis/trajectory attributes; probabilistic reasoning over ambiguous elements. - Assumptions/Dependencies: Accurate priors under distribution shift; richer element semantics (stiffness, limits, required forces); multi-object coordination.
- Compliance auditing and accessibility certification
- Sector: policy, facilities, healthcare
- Application: Automate verification of egress routes, opening directions, reachability, and assistive access (e.g., door forces, handle heights) using functional maps and measured trajectories.
- Tools/Workflow:
Accessibility Auditorthat compares stored kinematics against local codes; standardized reporting; remediation guidance. - Assumptions/Dependencies: Codified thresholds for forces/angles; sensors for force/torque; regulatory acceptance; periodic re-validation workflows.
- Industrial process safety and energy infrastructure operation
- Sector: energy, utilities, process industries
- Application: Map valves, breaker panels, and access mechanisms with articulation info for robots to safely operate critical controls during routine maintenance or emergencies.
- Tools/Workflow: Hazard-aware capture protocols; high-precision kinematic fitting including more joint types; integration with SCADA/DCS systems for authorization and logging.
- Assumptions/Dependencies: Joint models beyond prismatic/revolute (compound/continuous); strict safety certification; robust operation under harsh conditions.
- Education and workforce development modules
- Sector: education, training
- Application: Curricula where students build functional scene graphs, study articulation estimation, and deploy robots that act from language queries and stored demonstrations.
- Tools/Workflow: Classroom kits (RGB-D headset, UMI gripper), open-source datasets and benchmarks, scaffolded labs on kinematics and VFM integration.
- Assumptions/Dependencies: Affordable hardware; institutional support; curated object sets; reproducible evaluation.
- Retail, logistics, and micro-fulfillment automation
- Sector: retail, logistics
- Application: Robots open storage units, micro-fulfillment cabinets, and packaging fixtures learned via demos; reduce manual intervention and accelerate restocking.
- Tools/Workflow:
Fulfillment Functional Graphper site; batch demonstrations for high-frequency elements; scheduling and collision avoidance with human workers. - Assumptions/Dependencies: Reliable access paths; high-throughput coordination; resilience to layout changes; worker safety protocols.
- Enhanced digital twin simulation for robot validation
- Sector: simulation/virtualization, software/AI
- Application: Simulators consume ArtiSG graphs to emulate realistic articulated interactions, enabling policy validation and what-if analyses before deployment.
- Tools/Workflow: Import/export adapters for Isaac/Unity; stochastic models over axes and tolerances; automated scenario generation from functional graphs.
- Assumptions/Dependencies: Fidelity of articulation models; alignment between sim and real kinematics; dataset breadth for generalization.
Glossary
- 3D scene graph: A graph-based representation of a 3D environment where nodes (objects/elements) and edges (relationships) encode geometry and semantics for reasoning and planning. Example: "3D scene graphs have empowered robots with semantic understanding for navigation and planning"
- 6-DoF: Six degrees of freedom describing a rigid body's pose in 3D (3 for position, 3 for orientation). Example: "estimate 6-DoF articulation trajectories and axes even under camera ego-motion."
- Adaptive Kalman filter: A recursive state estimator that adaptively tunes its noise parameters to smooth and denoise measurements (e.g., poses) over time. Example: "using an adaptive Kalman filter"
- ArUco marker: A square fiducial marker with a known ID used for robust camera-based pose estimation. Example: "we detect visible ArUco markers on the sphere."
- Articulated object: An object composed of linked parts that move relative to each other via joints (e.g., doors, drawers). Example: "particularly regarding articulated objects."
- Articulation axis: The line (position and direction) that defines how a part moves under a joint (e.g., hinge axis or slide direction). Example: "an articulation axis "
- Back-projection: The process of lifting 2D image pixels (e.g., masks) into 3D coordinates using camera geometry and depth. Example: "These 2D part masks are back-projected into 3D space"
- DBSCAN: Density-Based Spatial Clustering of Applications with Noise; a clustering algorithm that groups dense regions and filters outliers. Example: "utilize DBSCAN clustering to remove outliers"
- Ego-motion: Motion of the camera (observer) itself, which complicates tracking and estimation. Example: "even under camera ego-motion."
- Extrinsic parameters: Camera parameters that describe the pose (position and orientation) of the camera in the world or another frame. Example: "using the camera's extrinsic and intrinsic parameters."
- Intrinsic parameters: Camera parameters that describe the internal imaging geometry (e.g., focal length, principal point). Example: "using the camera's extrinsic and intrinsic parameters."
- Kinematic mechanism: The motion model of an articulated part, specifying how it can move under joint constraints. Example: "that defines its kinematic mechanism"
- Kinematic priors: Prior knowledge or constraints about allowable motions (e.g., joint types/axes) used to guide perception or planning. Example: "We integrate these kinematic priors into a hierarchical and open-vocabulary graph"
- Non-linear least squares: An optimization method that minimizes squared residuals in problems where the relation between parameters and observations is non-linear. Example: "via non-linear least squares optimization"
- Open-vocabulary: A modeling approach that can recognize or retrieve concepts beyond a fixed label set using learned semantic embeddings. Example: "compute open-vocabulary features"
- Perspective-n-Point (PnP): A pose estimation method that recovers camera-to-object transformation from 2D–3D point correspondences. Example: "via a Perspective-n-Point (PnP) solver"
- Point cloud: A set of 3D points representing scene geometry, often derived from RGB-D sensing or reconstruction. Example: "generating the RGB point cloud of the scene."
- Principal Component Analysis (PCA): A technique that finds orthogonal directions of maximum variance; used here to infer motion axes/planes. Example: "based on Principal Component Analysis (PCA) and non-linear optimization."
- Prismatic joint: A joint allowing linear sliding motion along a single axis. Example: "For the prismatic joint where motion follows a 3D line"
- R@k (Recall@k): A retrieval metric indicating whether the correct item appears within the top-k ranked results. Example: "We also utilize the query success rate R@ as defined in OpenFunGraph"
- Reprojection error: The pixel-space error between observed 2D points and reprojected 3D points given an estimated pose; used to assess PnP quality. Example: "based on the PnP reprojection error."
- Revolute joint: A joint allowing rotation around a fixed axis (e.g., a hinge). Example: "For the revolute joint where motion follows a circular arc"
- Root Mean Squared Error (RMSE): A measure of average magnitude of error, computed as the square root of mean squared differences. Example: "We calculate the trajectory RMSE "
- Simultaneous Localization and Mapping (SLAM): Algorithms that estimate a sensor’s pose while building a map of the environment. Example: "the camera utilizes built-in SLAM"
- Singular Value Decomposition (SVD): A matrix factorization used to find principal directions; here, to estimate motion axes and planes. Example: "we apply Singular Value Decomposition (SVD) to the centered points"
- Top-k frames: The subset of frames with the highest utility (e.g., visibility) chosen for processing or aggregation. Example: "we select the top- frames"
- Vision foundation models: Large, general-purpose vision models used for tasks like detection or segmentation without task-specific training. Example: "turn to vision foundation models for functional element segmentation"
Collections
Sign up for free to add this paper to one or more collections.

