- The paper introduces Universal Conditional Logic (UCL), a domain-specific language that transforms prompt engineering into a precise, optimization-driven science.
- It employs formal grammar, indicator-driven conditionals, and structural overhead metrics to achieve up to a 30% reduction in prompt length without sacrificing correctness.
- Empirical validation across 11 LLM architectures demonstrates improved token efficiency and output integrity through model-specific calibration and early binding techniques.
Overview
"Universal Conditional Logic: A Formal Language for Prompt Engineering" (2601.00880) proposes and rigorously evaluates Universal Conditional Logic (UCL), a formal domain-specific language for prompt engineering in LLMs. UCL transforms prompt engineering from an artisanal, heuristic discipline into a calibratable, optimization-driven science anchored in precise grammar, syntax, semantics, and pragmatics. The framework models prompt quality and efficiency as explicit functions of specification, structural overhead, and selective activation, resulting in significant and reproducible reductions in prompt length (up to 30%) without sacrificing task correctness across diverse state-of-the-art LLM architectures.
Motivation and Theoretical Foundation
Despite the maturation of programming paradigms, prompt engineering remains ad hoc, typically relying on natural language with limited formal control over logic flow, structural modularity, or selective content activation. UCL is introduced as a domain-specific language—functionally analogous to C or Python for software, but targeting prompt specification for LLMs. Its expressivity relies on a formal grammar (validated with production rules), composable operators, and deterministic semantics based on indicator functions and conditional logic.
Crucially, UCL identifies and formalizes the "Over-Specification Paradox": prompt quality exhibits a non-monotonic relationship with the level of specification. Empirical analysis reveals that prompt quality Q(S) increases with detail up to an optimal specification threshold S∗≈0.509, beyond which further elaboration rapidly degrades output, reflected mathematically as a quadratic penalty for over-specification. This results from compounded role confusion, cognitive complexity, and perceived sophistication by the model—a precise analog to regularization and overfitting in classical machine learning.
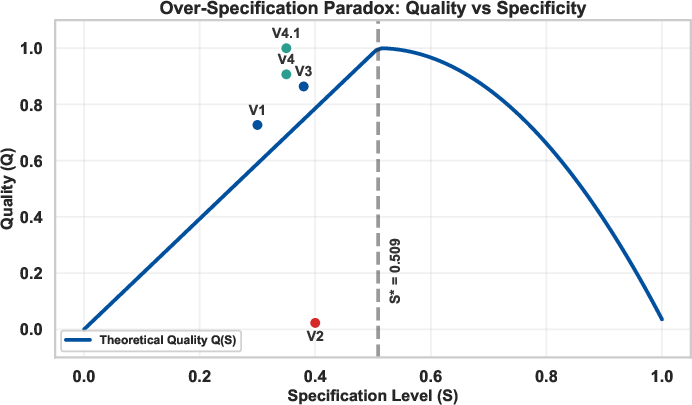
Figure 1: Illustration of quality function Q(S) exhibiting the Over-Specification Paradox; quality peaks at S∗ and falls quadratically for S>S∗.
UCL Language Design and Mechanisms
Core Primitives
UCL's validated language constructs include:
- Indicator-driven Conditionals: Each domain or content block is guarded by an indicator function Ii(x)∈{0,1}, evaluated as a Boolean of keyword-token intersection. Only blocks with Ii=1 are activated, achieving up to n-fold content reduction compared to standard prompts.
- Structural Overhead Quantification: UCL introduces a structural overhead metric Os(A)=γk∑ln(Ck)+δ∣Lproc∣, capturing both branching complexity and procedural code length. Overhead operates as a quantifiable penalty analogous to dead code or unoptimized branching in software compilers.
- Early Binding (CRITICAL Directive): Version-specific directives, such as [[CRITICAL:]], enforce model-family-specific output requirements with empirically validated quality gains via early binding.
- Concept References: Domain-based semantic labels replace verbose natural-language explanation, reducing ambiguity and centralizing maintainability.
The formal grammar is evidenced with static production trees and token-level validators, supporting both static analysis and extensibility.
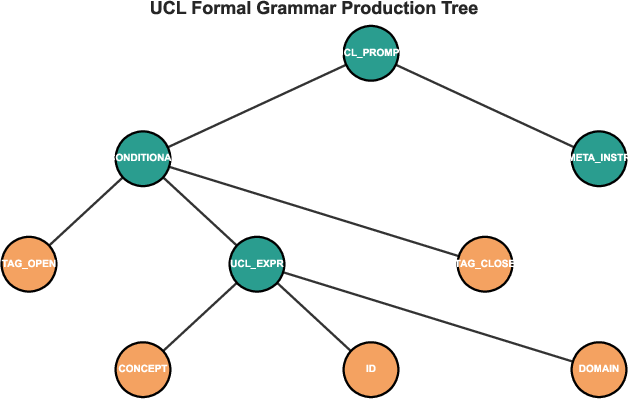
Figure 2: UCL grammar production tree, separating non-terminal structural elements from concrete operational tokens.
Comparison to Standard Prompt Patterns
Unlike baseline prompt strategies (including switch/case or procedural blocks), UCL's conditional branching achieves true selective activation. The architecture ensures that only relevant instructions are processed and executed, akin to lazy evaluation paradigms in functional programming.
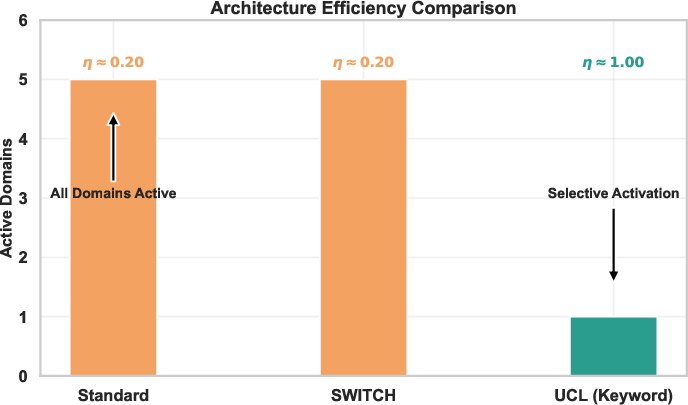
Figure 3: Comparison of indicator-based selective activation across standard and UCL prompt architectures.
Control flow analysis reveals that while standard (and even switch-based) prompts exhibit unconditional linear or multi-case processing, UCL employs parse-time conditionals to entirely skip irrelevant branches, eliminating superfluous token consumption.
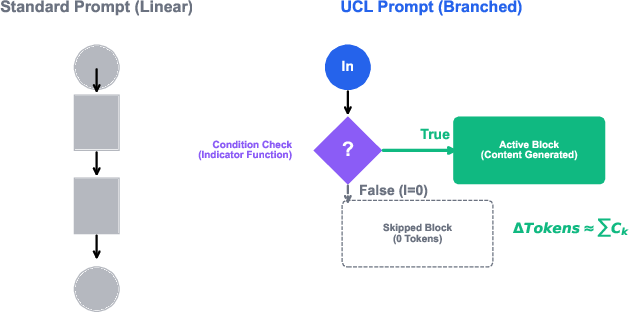
Figure 4: Visual comparison of control flow in standard versus UCL logic, establishing branching token efficiency.
Empirical Validation
The UCL framework is exhaustively validated on mathematical text-to-speech (TTS) conversion tasks, using 305 annotated trials across 11 LLM architectures, including Qwen-3-VL-235B, Llama 4 Scout, Gemini, Mistral, GPT-5-Mini, and others.
Quality and Efficiency Outcomes
Progressive UCL evolution (V1 baseline to V4.1 optimal) demonstrates:
- Token Reduction: Mean reduction of 29.8% (Cohen's d=2.01, p<0.001) across all tested architectures.
- Output Integrity: JSON validity rates ascend steadily to 100% in UCL V4.1, matching or exceeding baseline.
- Over-Specification Failure: Excessive specification in V2 (2.3% correctness) empirically confirms the quadratic penalty model.
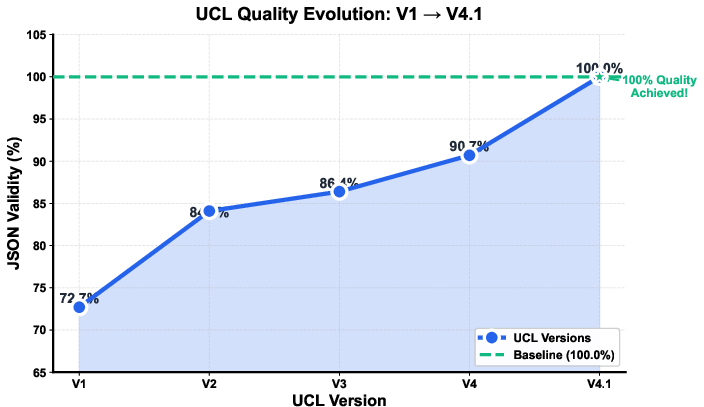
Figure 5: Quality improvement trajectory through UCL versions, with V4.1 achieving perfect output validity.
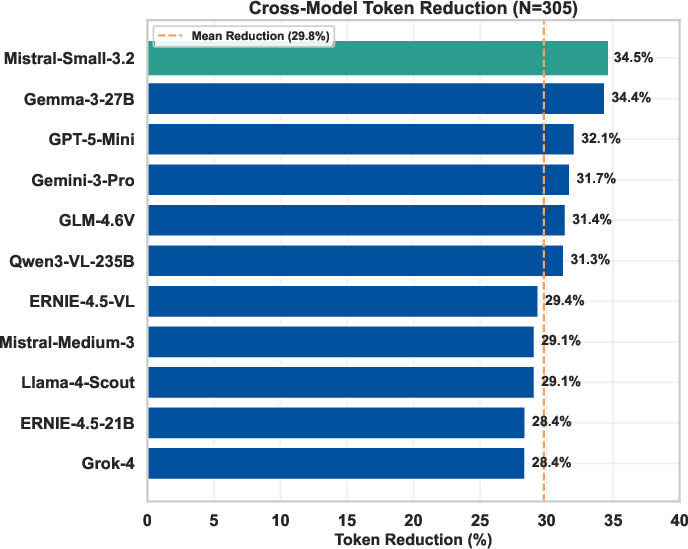
Figure 6: Per-model token count reduction, consistently demonstrating UCL's efficiency.
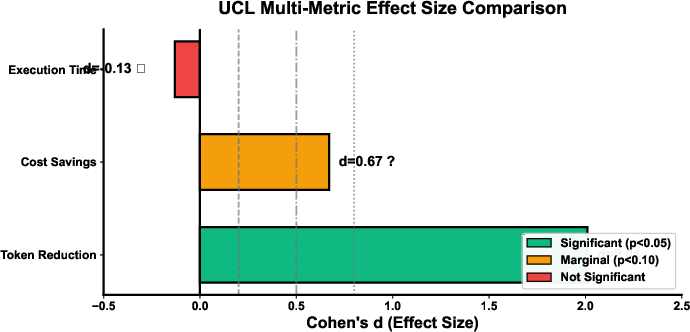
Figure 7: Multi-metric effect size analysis, highlighting token reduction as a robust and significant outcome.
Furthermore, statistical analysis (paired t-test, df=10) is executed using a repeated-measures model, with each architecture supplying a paired baseline/UCL measurement.
Performance is tightly predicted by the measured structural overhead Os; high overhead architectures (V2, V3) exhibit low quality and inflated token counts, while minimized overhead (V4, V4.1) correlates with optimal performance.
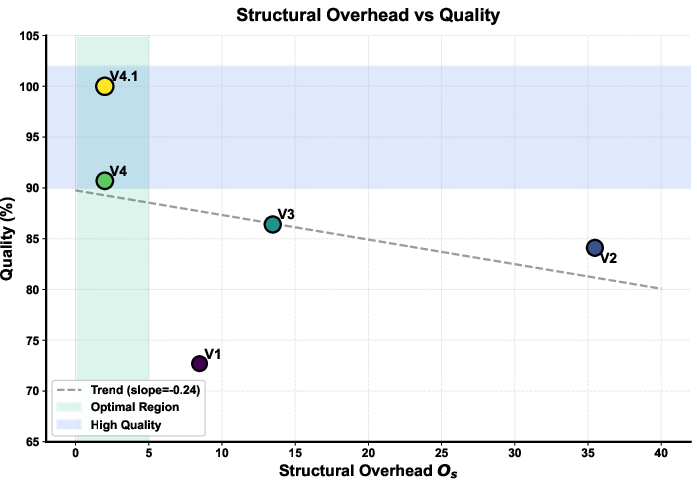
Figure 8: Scatter plot contrasting UCL version overhead with JSON validity, identifying optimal design regions.
Model-Specific Optimization and Compatibility
Despite universal content reduction benefits, empirical findings highlight the necessity of architecture-aware calibration. For example, the Llama 4 Scout model is uniquely incompatible with standard UCL up to V4, achieving baseline performance only after the CRITICAL directive of V4.1 is included to enforce strict output formatting.
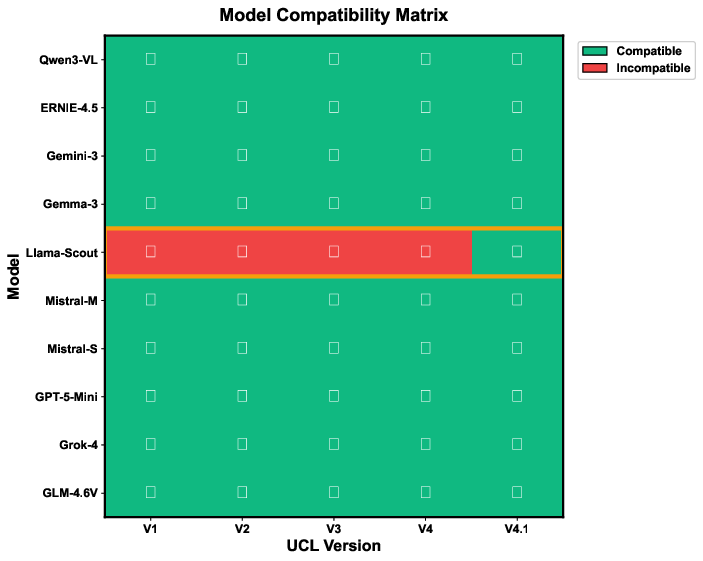
Figure 9: Model compatibility matrix, revealing the Llama 4 Scout's requirement for the CRITICAL directive.
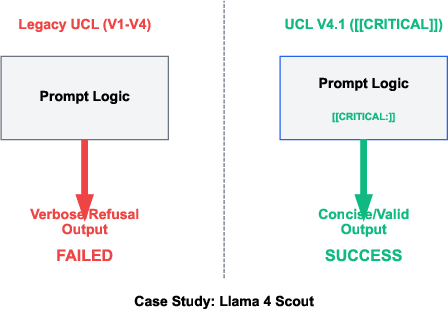
Figure 10: Case study of successful resolution of model-specific output failure using the CRITICAL directive.
This implies that while UCL provides foundational mechanisms, optimal configurations demand per-architecture tuning, echoing the need for target-specific compilation profiles in software systems.
Practical and Theoretical Implications
UCL stands as the first formalized, grammar-based prompt engineering language validated in cross-model contexts. Its contributions and implications are multifold:
- Token and Cost Efficiency: Deterministic reduction in generated content translates to direct computational and financial savings.
- Structural Regularization: By operationalizing specification penalty, prompt authors are equipped to calibrate for maximum clarity without triggering model confusion or verbosity.
- Extensibility: The language accommodates 30+ proposed operators (most pending empirical validation), providing a roadmap for expanding its logic to recursion, meta-cognitive control, and static analysis via dedicated toolchains.
- Standardization Potential: UCL introduces a path towards reproducible, systematic, and toolchain-supported prompt programming.
Theoretically, UCL bridges prompt engineering to information theory (noise minimization versus channel capacity), compiler optimization (dead code elimination, if-guard logic), and foundational notions in language design (DSL validation and evolution).
Future Directions
Research is already oriented towards community-driven standardization, static analysis (linting, over-specification detection), and automated optimization—mirroring the maturation of classical programming toolchains. The protocol for future operator validation is defined rigorously, requiring static pre-validation, empirical inference, and cross-architecture robustness checks. UCL is further positioned as a substrate for automated prompt compilation, dynamic runtime adaptation (selecting UCL variants per detected model), and integration into broader AI-agent programming systems.
Conclusion
Universal Conditional Logic substantially advances the state of prompt engineering by introducing a mathematically founded, grammar-driven, and empirically validated language for instructing LLMs. UCL achieves strong, model-independent reductions in token generation while safeguarding or improving output quality, and exposes new, actionable levers for prompt designers targeting robust, efficient AI pipelines. Its architecture-aware calibration requirement underscores the complexity of model interaction but also opens a productive research avenue for community development and standardization. The framework lays robust groundwork for future work in AI prompt optimization, 'prompt compilation,' and the eventual emergence of a programmable prompt engineering paradigm.