- The paper introduces a domain-specialized pipeline that integrates CPT, SFT, and reinforcement learning to significantly improve MD code generation accuracy.
- It leverages a structured data pipeline combining MD-Knowledge, MD-InstructQA, and MD-CodeGen to train the LLM on simulation scripts and materials science workflows.
- Experimental results show enhanced code executability with ExecSucc@3 rising from 14.23% to 37.95% and improved QA performance through iterative feedback.
MDAgent2: End-to-End Domain-Specialized LLM Pipeline for Molecular Dynamics Code Generation and Knowledge Q&A
Motivation and Contributions
The complexity and domain specificity of molecular dynamics (MD) simulation scripts, particularly LAMMPS input files, present severe bottlenecks in materials science and related fields. General-purpose LLMs exhibit insufficient executability and limited reliability when tasked with text-to-code generation and scientific question answering in this environment. MDAgent2 addresses these limitations through a methodological pipeline covering domain data curation, adaptive model training, closed-loop reinforcement learning, automated multi-agent runtime, and standardized benchmarking. The framework demonstrates enhanced code generation accuracy, executability, and domain reasoning, establishing a new paradigm for integrating LLMs into industrial-scale simulation workflows.
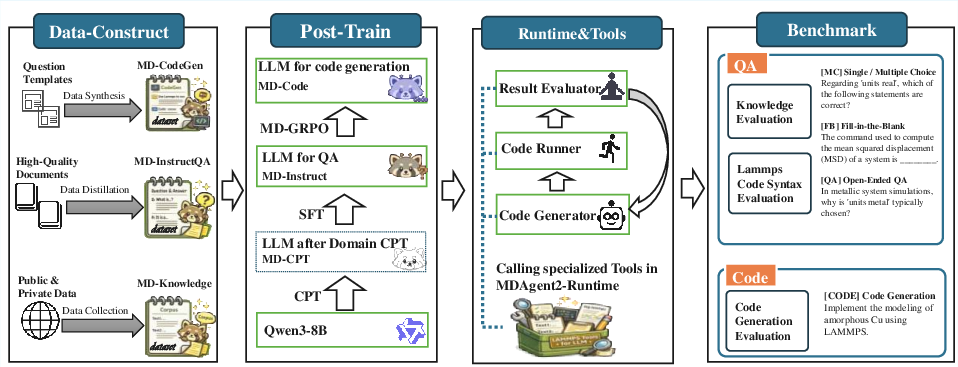
Figure 1: End-to-end workflow of MDAgent2, highlighting data construction, multi-stage model training, multi-agent runtime, and benchmarking modules.
Structured Data Pipeline for Domain-Specific Model Adaptation
A pivotal component of MDAgent2 is the high-fidelity data pipeline:
- MD-Knowledge: Curated from expert-written domain literature, textbooks, and LAMMPS documentation, the corpus is processed via regex filtering, multi-stage deduplication (LSH, MinHash, and embedding similarity) [lee2022deduplicating], and LLM-based sample screening. This corpus supplies robust semantic pretraining signals for molecular dynamics.
- MD-InstructQA: Semantic chunk extraction and structure-sensitive label tree construction enable automated question and answer generation, yielding both direct and chain-of-thought supervision samples.
- MD-CodeGen: Combines expert hand-authored code-task pairs and large-scale automated synthesis via template-driven task description to cover diverse material systems and simulation objectives.
This structured data foundation is crucial for the robust domain adaptation realized in subsequent training phases.
Post-Training: CPT, SFT, and RL via MD-GRPO
The training protocol comprises three sequential phases on Qwen3-8B:
Continual Pretraining (CPT): Hybridized domain and general corpora facilitate representation alignment to materials-specific terminology and workflows [xie2024efficient]. CPT serves to prime the LLM for semantic fidelity in the target domain.
Supervised Fine-Tuning (SFT): Mixing MD-InstructQA and selective MD-CodeGen samples, SFT calibrates the LLM for reasoning, QA, and basic code synthesis tasks. This stage is optimized for task alignment and factual accuracy [lu2025fine].
Reinforcement Learning (MD-GRPO): Building on GRPO [shao2024deepseekmath], MD-GRPO introduces closed-loop optimization using actual code execution as reward signals (format and correctness). Key innovations include multi-dimensional correctness scoring (syntax, logic, parameters, completeness, validity, physical soundness) and low-reward trajectory recycling for hard-case amelioration. Feedback from code execution is aggregated via KL-regularized policy optimization.
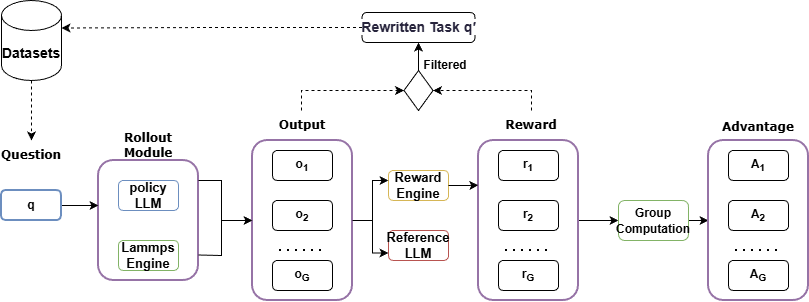
Figure 2: Schematic of the MD-GRPO reinforcement learning pipeline: code generation, rollout execution, reward aggregation, and trajectory rewriting.
MDAgent2-RUNTIME: Automated Multi-Agent System
MDAgent2-RUNTIME operationalizes the trained models in a fully automated multi-agent framework enabling natural language to executable code conversion, iterative self-correction, and human-in-the-loop feedback.
- Code Generator: Synthesizes initial code using MD-Code, invoking syntax and potential-file verification tools for rapid error screening and automated parameter supplementation.
- Code Runner: Executes the LAMMPS input in sandboxed environments, ensuring reproducibility and resource isolation.
- Result Evaluator: Applies the rubric-based multi-dimensional evaluation framework, generating reward signals and triggering automatic code revisions as necessary.
The integration of specialized MD tools (syntax validation, potential management, result visualization) increases system robustness and real-world usability.
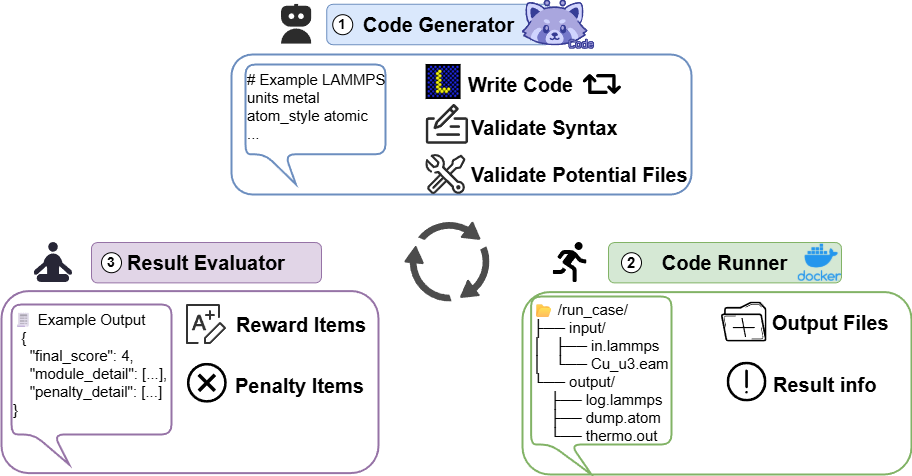
Figure 3: MDAgent2-RUNTIME multi-agent system architecture, automating code generation, verification, execution, and evaluation loops.
Benchmarking: MD-EvalBench and Quantitative Results
MD-EvalBench is the first comprehensive benchmark for MD-LAMMPS QA and code generation. It comprises three components:
- MD-KnowledgeEval: 336 expert-curated theoretical questions.
- LAMMPS-SyntaxEval: 333 command and script comprehension items.
- LAMMPS-CodeGenEval: 566 natural language to code tasks, assessed for execution success and human-rated code quality.
MD-Instruct-8B Demonstrates Strong QA Performance: Post-training, this lightweight model closes the gap with much larger general-purpose LLMs, outperforming Qwen-Flash and Qwen3-14B on aggregate QA score (74.67 vs. 73.47/72.91), indicating effective domain knowledge transfer under parameter-efficient constraints.
MDAgent2-RUNTIME Achieves Significant Gains in Code Executability: Enabling runtime correction boosts ExecSucc@3 from 14.23% to 37.95% for MD-Code-8B, with Code-Score-Human stabilized at 9.32. These results substantiate the impact of iterative execution-feedback loops and specialized tool integration.
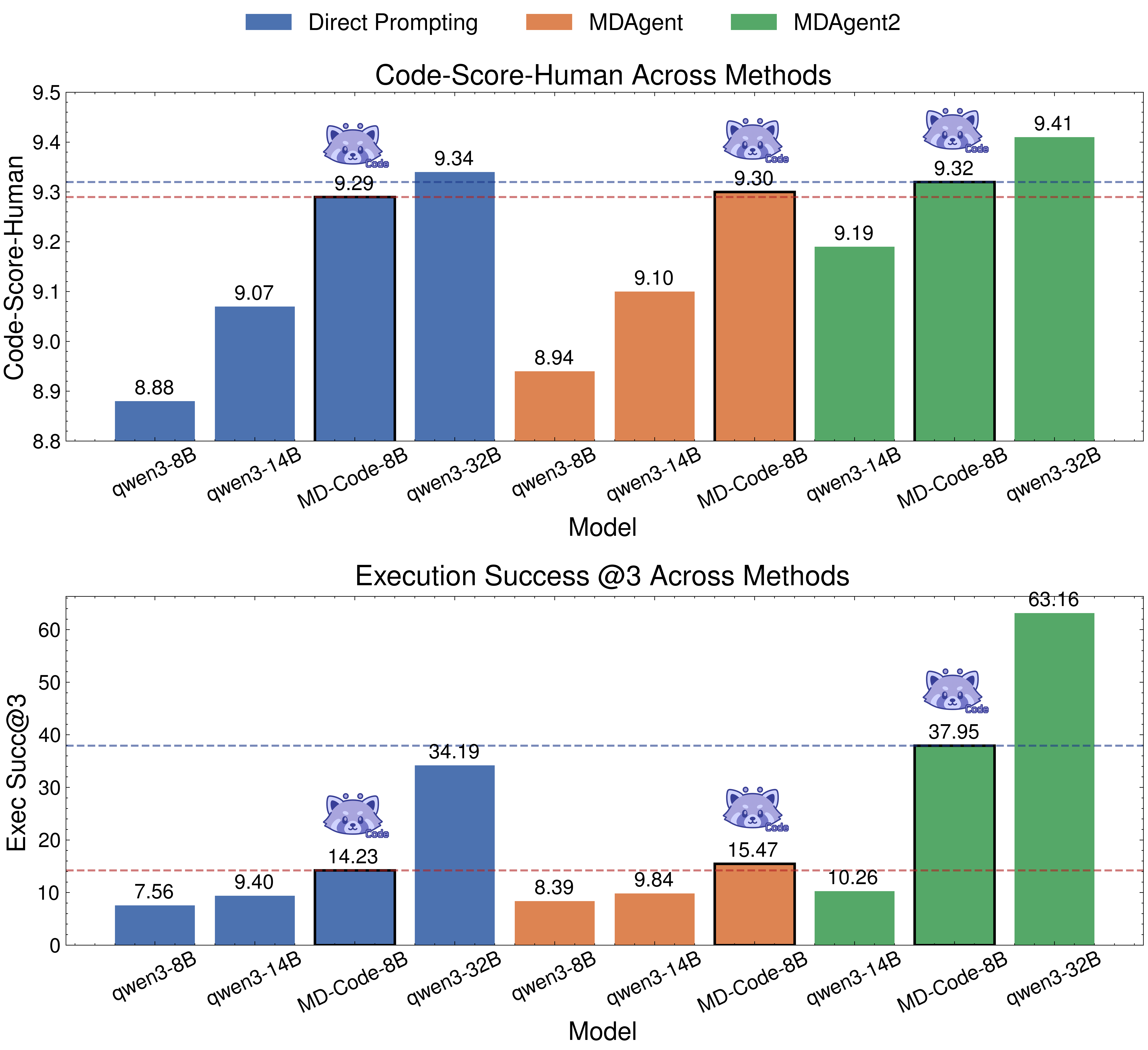
Figure 4: Comparative results for code generation quality (Code-Score-Human) and execution reliability (Success@3) across evaluated systems.
Theoretical and Practical Implications
MDAgent2 methodologically advances the integration of scientific knowledge, simulation logics, and code synthesis into a closed-loop LLM architecture for industrial science. Post-training on structured domain data avoids excessive reliance on large proprietary models, enabling local deployment and reducing inference cost. The demonstrated gains establish methodological principles for domain-specific LLM adaptation—structured data acquisition, hybrid CPT/SFT, RL with executable feedback—and provide a blueprint for extending such systems to other computational science domains. The multi-agent architecture supports fully autonomous, self-correcting workflows, facilitating the development of universal AI-driven scientific assistants.
Future Directions
Enhancing multimodal support, integrating visual simulation outputs into LLM evaluation, and expanding the domain coverage across simulation types (thermodynamics, mechanics, fluidics) are key targets. Scalability for other scientific areas is promising given the modular pipeline. Ongoing dataset expansion and refinement, alongside improved RL algorithms and more granular correction heuristics, can further elevate practical value.
Conclusion
MDAgent2 establishes a rigorous, scalable framework for code generation and QA in molecular dynamics via automated data curation, structured fine-tuning, reward-driven RL, and multi-agent runtime systems. Quantitative results validate model adaptability, executability, and self-correction in an industrial context. The approach sets methodological standards for AI4Science LLM pipelines, with direct implications for automated experimentation and universal scientific assistants (2601.02075).