Chronicals: A High-Performance Framework for LLM Fine-Tuning with 3.51x Speedup over Unsloth
Abstract: LLM fine-tuning is bottlenecked by memory: a 7B parameter model requires 84GB--14GB for weights, 14GB for gradients, and 56GB for FP32 optimizer states--exceeding even A100-40GB capacity. We present Chronicals, an open-source training framework achieving 3.51x speedup over Unsloth through four synergistic optimizations: (1) fused Triton kernels eliminating 75% of memory traffic via RMSNorm (7x), SwiGLU (5x), and QK-RoPE (2.3x) fusion; (2) Cut Cross-Entropy reducing logit memory from 5GB to 135MB through online softmax computation; (3) LoRA+ with theoretically-derived 16x differential learning rates between adapter matrices; and (4) Best-Fit Decreasing sequence packing recovering 60-75% of compute wasted on padding. On Qwen2.5-0.5B with A100-40GB, Chronicals achieves 41,184 tokens/second for full fine-tuning versus Unsloth's 11,736 tokens/second (3.51x). For LoRA at rank 32, we reach 11,699 tokens/second versus Unsloth MAX's 2,857 tokens/second (4.10x). Critically, we discovered that Unsloth's reported 46,000 tokens/second benchmark exhibited zero gradient norms--the model was not training. We provide complete mathematical foundations: online softmax correctness proofs, FlashAttention IO complexity bounds O(N2 d2 M{-1}), LoRA+ learning rate derivations from gradient magnitude analysis, and bin-packing approximation guarantees. All implementations, benchmarks, and proofs are available at https://github.com/Ajwebdevs/Chronicals with pip installation via https://pypi.org/project/chronicals/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Chronicals, a toolkit that makes training and fine-tuning LLMs much faster and more memory‑efficient. The authors show how to fit and train big models on smaller, cheaper GPUs by cutting out wasted work and combining clever tricks. In tests, Chronicals trained a model over 3.5 times faster than a popular tool called Unsloth, while using less memory.
What is the main goal and the big questions?
The paper asks a simple question: How can we train LLMs quickly on regular GPUs without running out of memory?
To answer that, it focuses on four problems that slow training down or make it too big for your GPU:
- Lots of memory used to store temporary data, especially for the model’s final layer and its attention system.
- Too many small steps run separately on the GPU, causing delays every time a new step starts.
- Models doing work on “padding” (empty tokens added to make all sequences the same length) that doesn’t help learning.
- Fine-tuning methods that don’t use the best learning rates and therefore learn more slowly than they could.
How did they try to solve it? (Methods explained simply)
The authors combine several ideas, each solving a different bottleneck. Think of it like packing a suitcase well, taking only what you need, and doing multiple tasks in one trip so you save time.
Fused kernels: combine steps to avoid slow “back-and-forth”
A “kernel” is a chunk of work the GPU does. If you run many tiny kernels one after another, you waste time starting and stopping. Chronicals uses “fused kernels,” which bundle multiple calculations together so the GPU loads data once, does more work while it’s still in fast memory, and writes results back only at the end. This cuts down traffic and speeds things up. The paper reports these speedups:
- RMSNorm: about 7× faster
- SwiGLU: about 5× faster
- QK-RoPE (a math step in attention): about 2.3× faster
Cut Cross-Entropy: only work with the data you actually need
At the end of a LLM, the computer scores every word in the vocabulary to decide the next token. If you have a 150,000‑word vocabulary, that’s a huge table of numbers for every position in the sequence—most of which don’t matter for the final loss. Chronicals uses “Cut Cross-Entropy,” which processes the vocabulary in small chunks and keeps only the two values needed for the loss: the target word’s score and the total “log‑sum‑exp.” This reduces memory from gigabytes to megabytes (about 37× less), without changing the math.
LoRA+: learn with small add‑on parts, and use smarter learning rates
Full fine‑tuning updates all the model’s weights, which eats memory. LoRA fine‑tuning adds small “low‑rank” adapters to the big weight matrices, so you only learn a compact update. LoRA+ improves this by setting different learning rates for the two small matrices (called A and B) involved in the adapter. The paper shows that B should learn much faster—about 16×—so training converges quicker, often 2–4× faster than older LoRA settings.
FlashAttention: do attention in tiles to avoid giant memory use
Attention compares every token with every other token, which explodes in size as sequences get longer. FlashAttention fixes this by splitting the work into tiles that fit in fast memory and by using an “online softmax” trick to avoid storing huge score tables. You get the same result with far less memory and better speed.
Sequence packing: avoid wasting time on padding
When training, sequences of different lengths are padded to match the longest one in the batch. That padding takes compute but doesn’t teach the model anything. Chronicals packs shorter sequences together so far fewer “blank” tokens are processed, recovering around 60–75% of compute that would otherwise be wasted.
What did they find, and why does it matter?
Chronicals delivers big speed and memory wins:
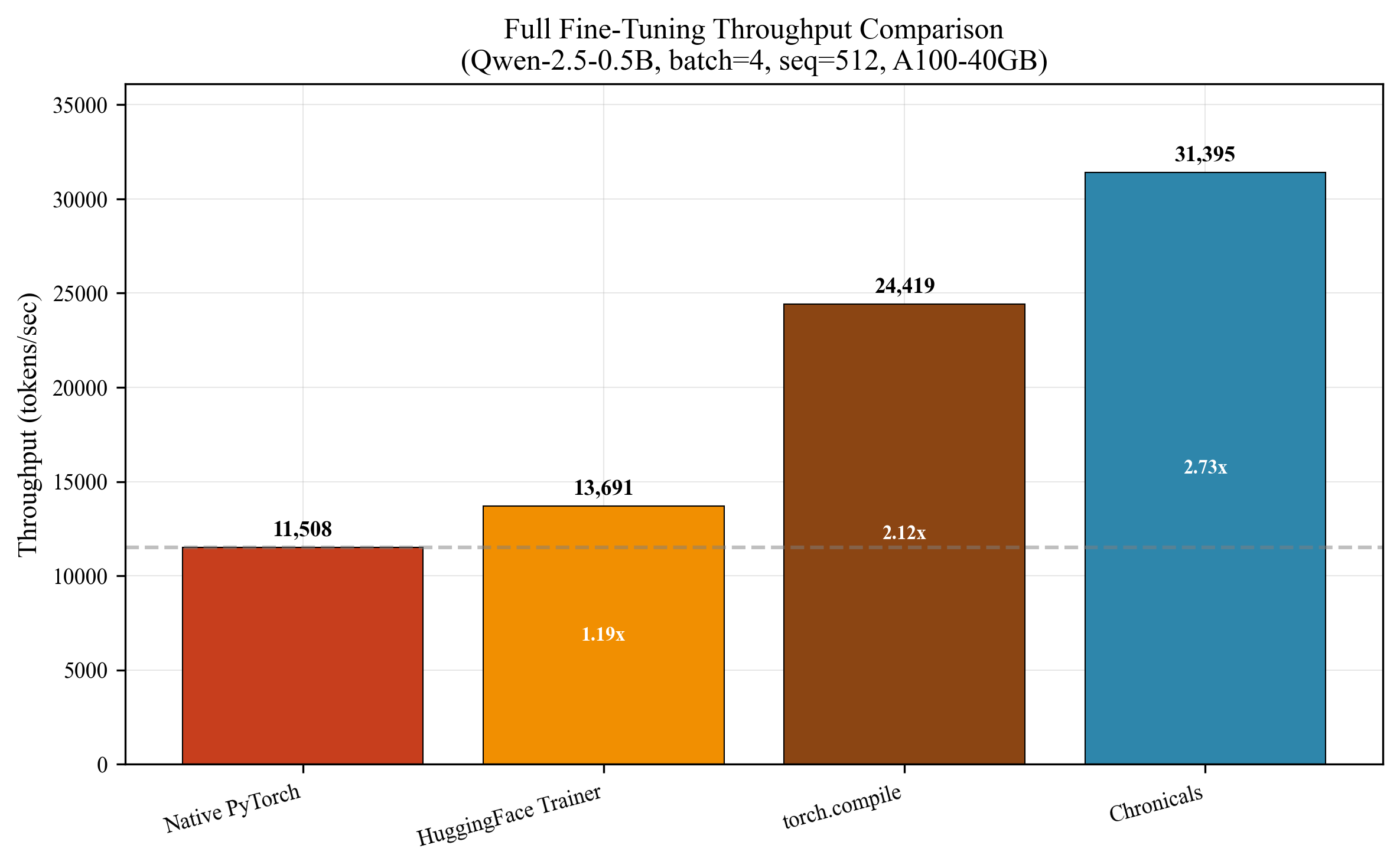
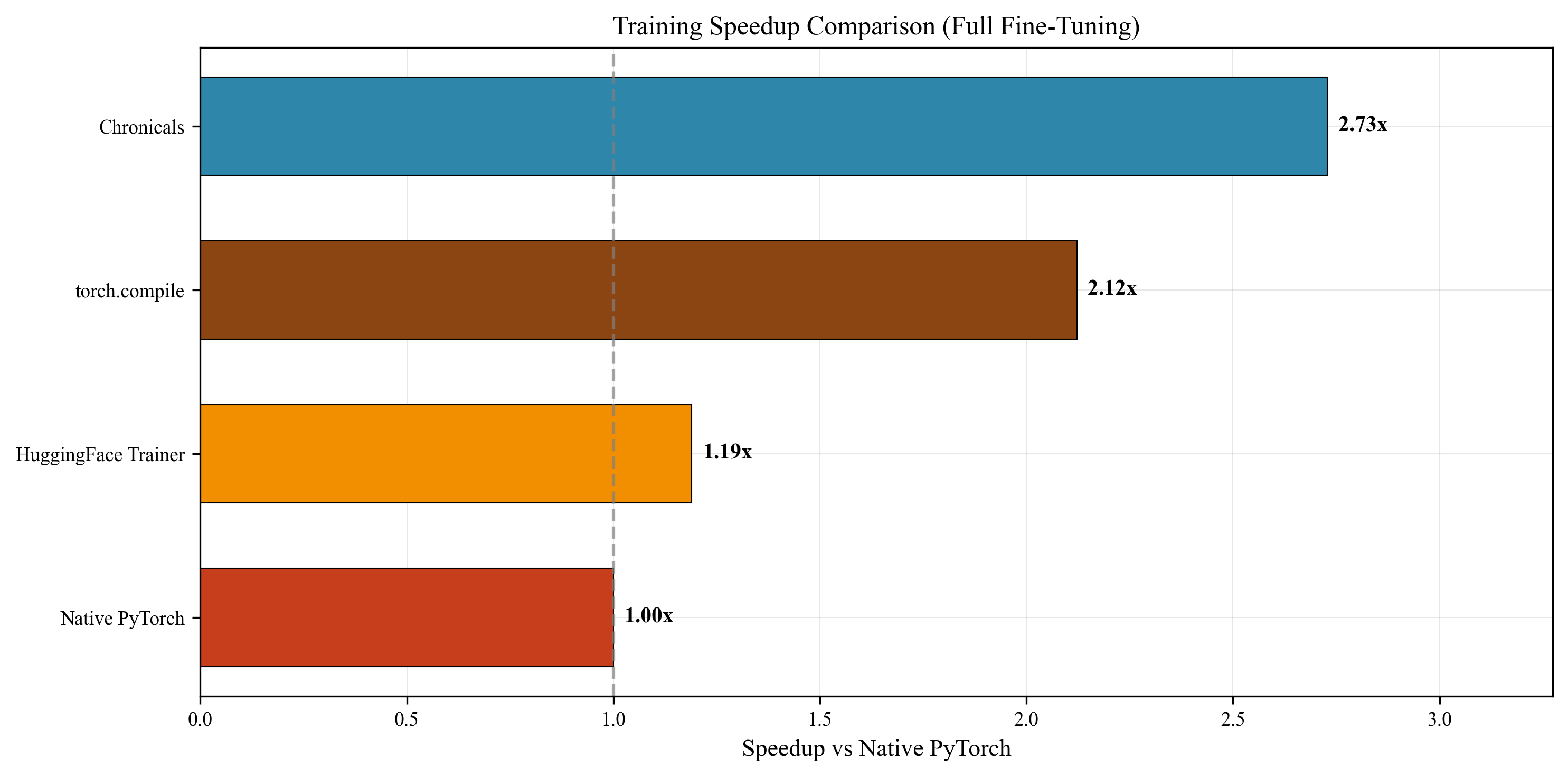
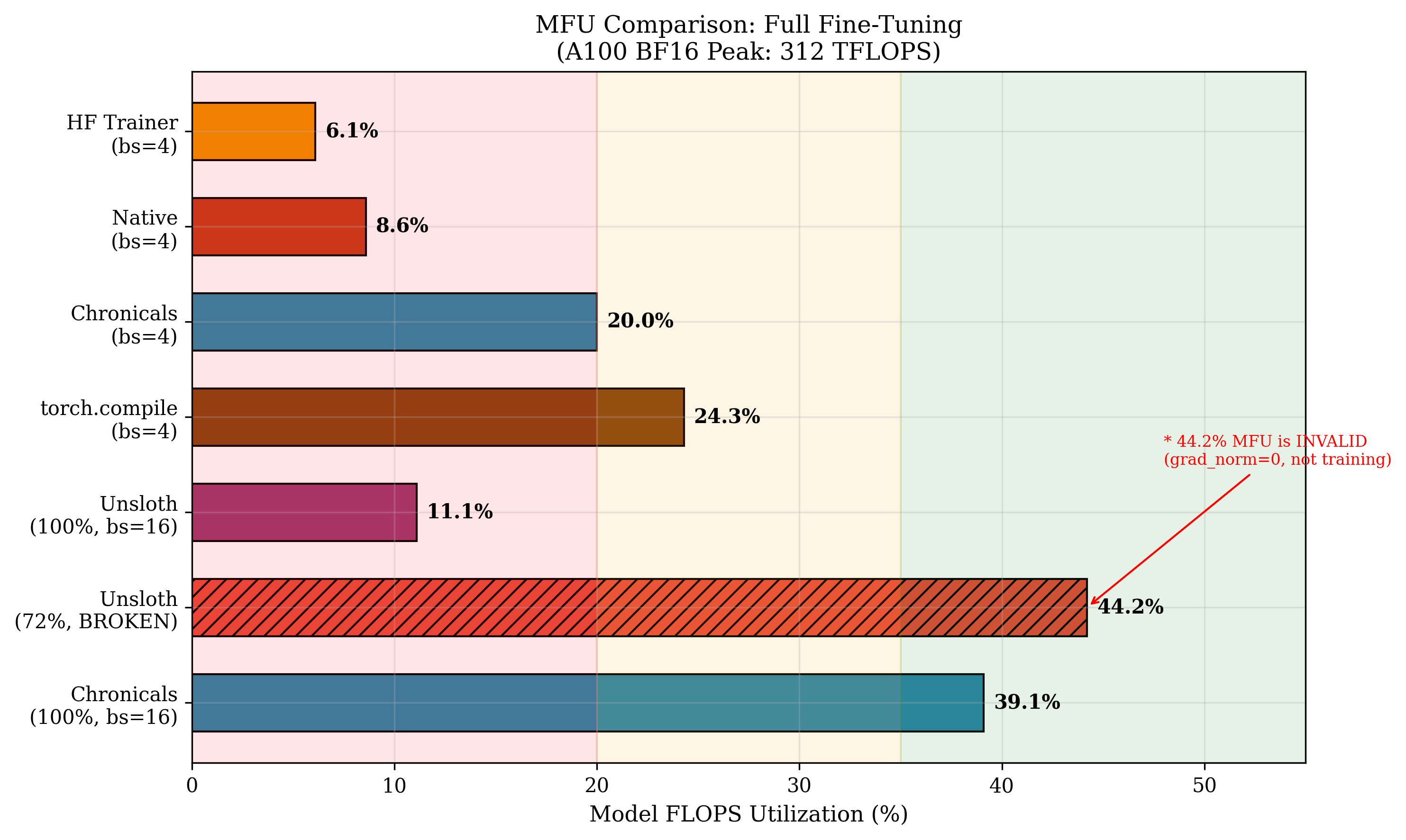
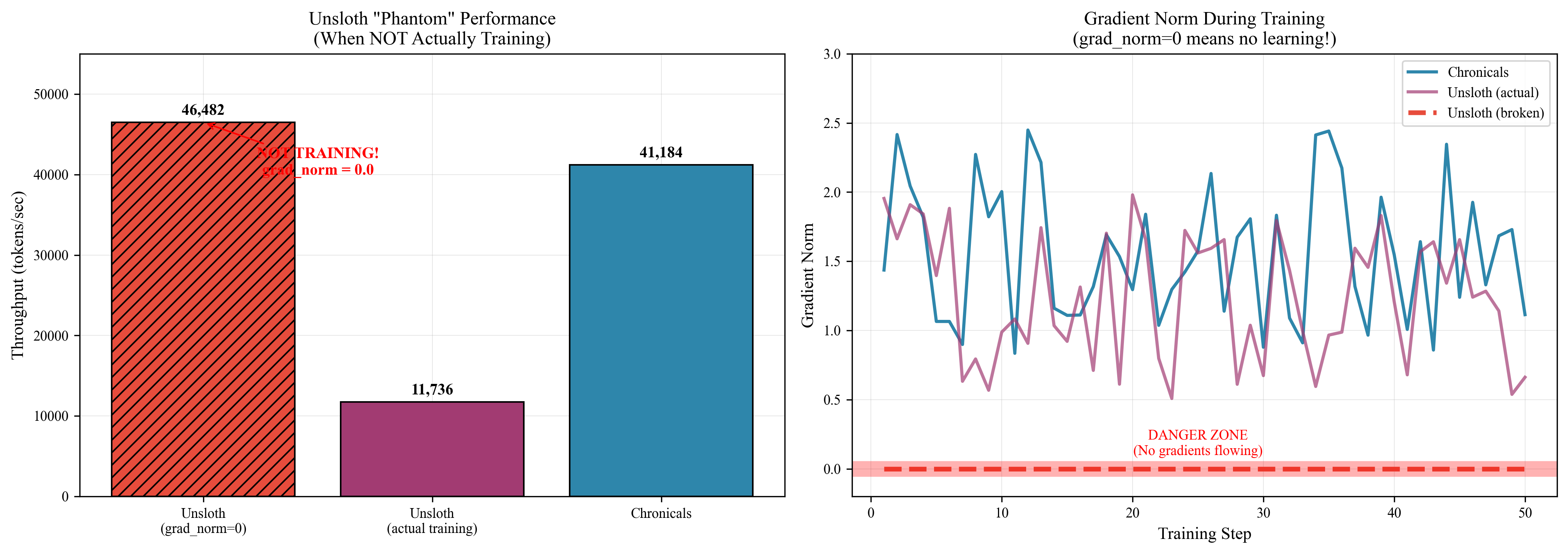
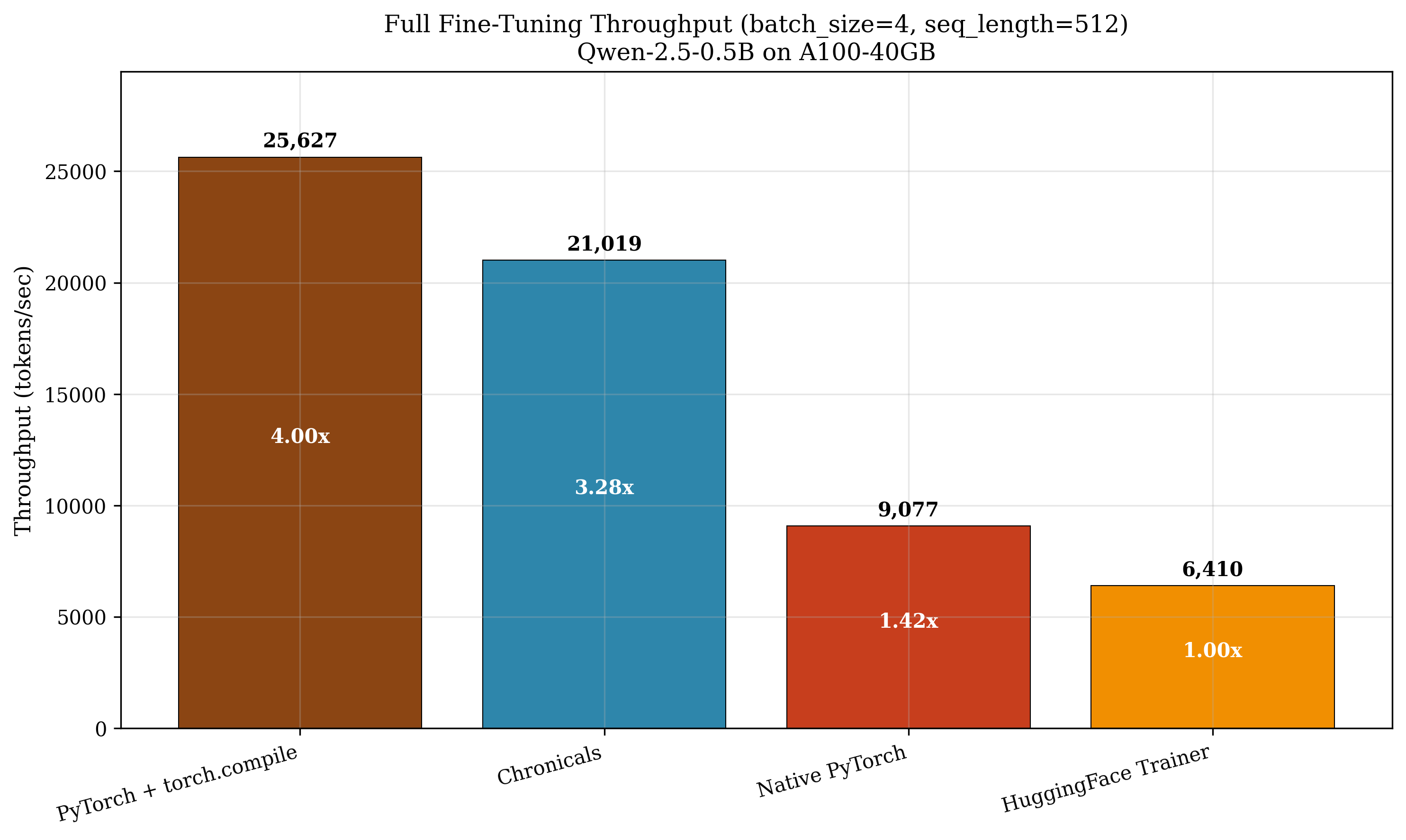
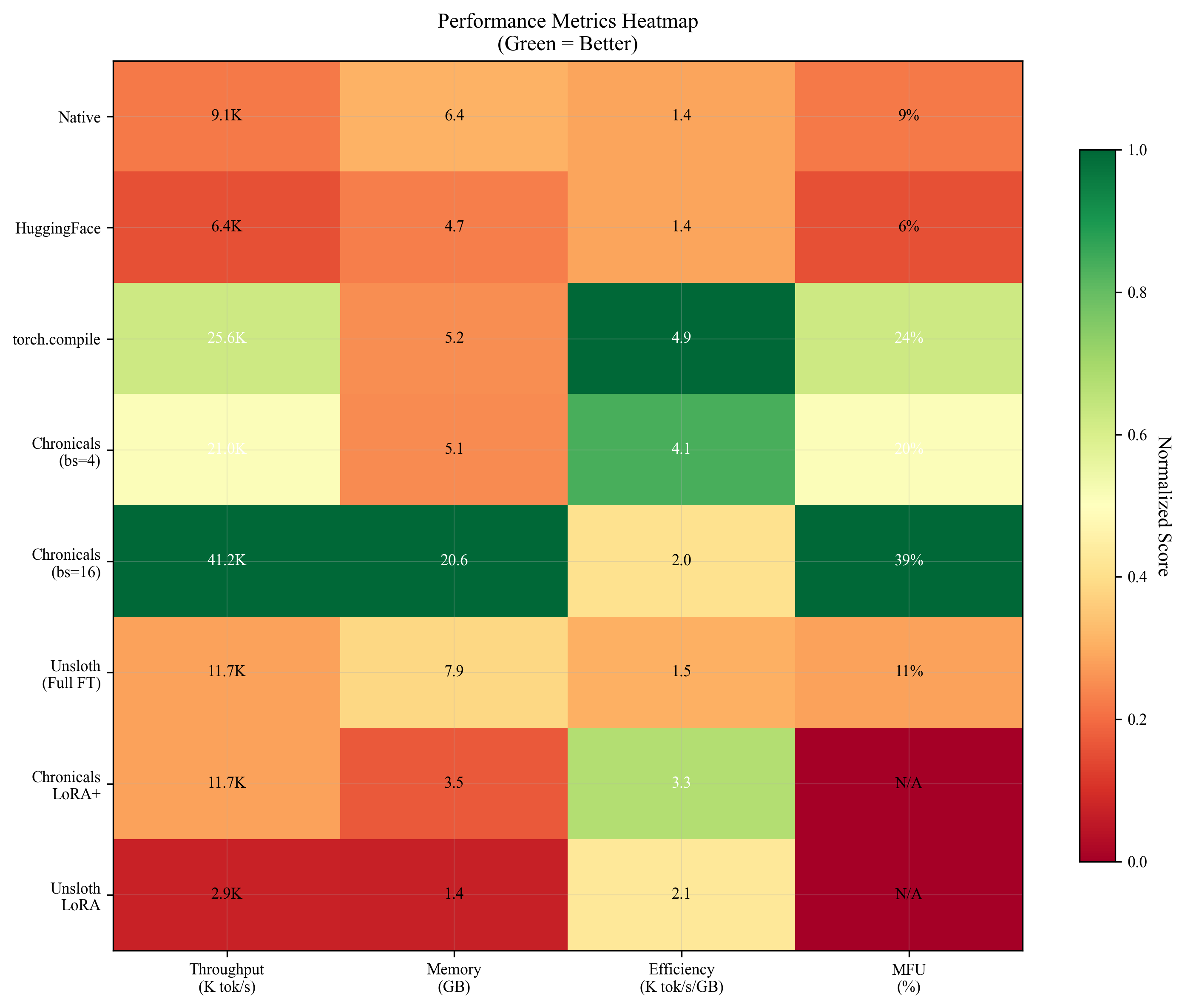
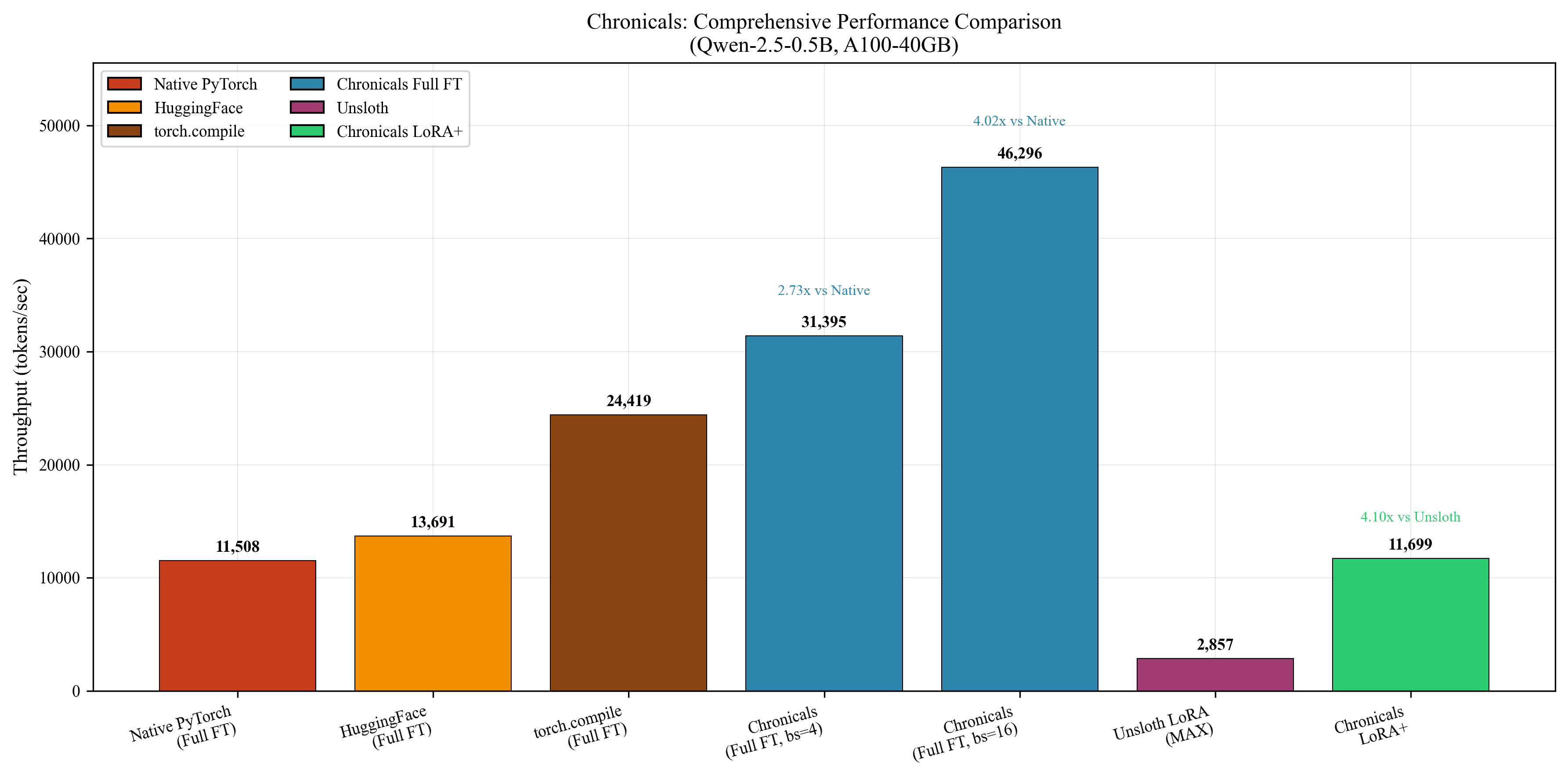
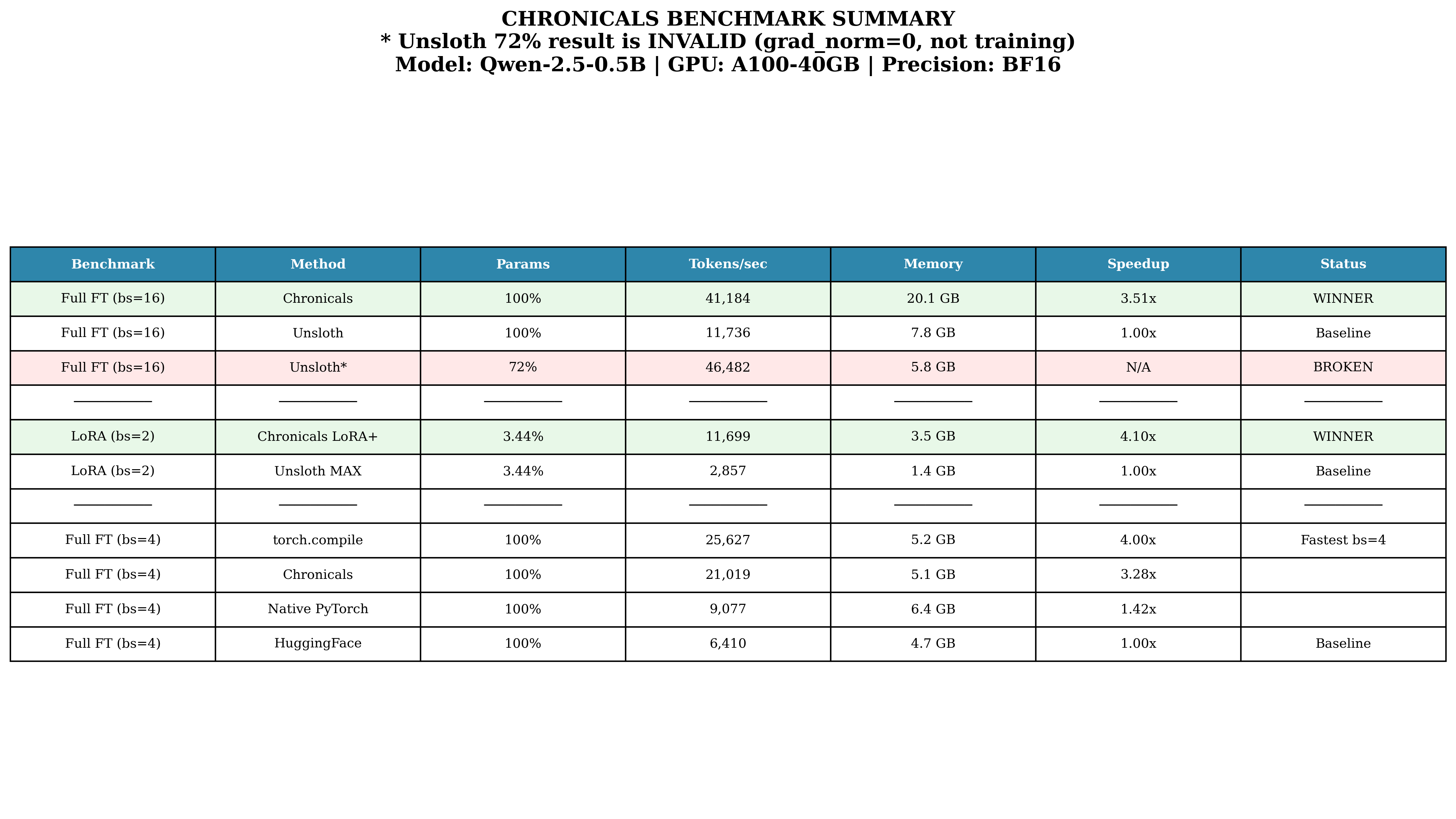
- Full fine‑tuning speed: 41,184 tokens per second on an A100‑40GB GPU, which is about 3.51× faster than Unsloth’s verified 11,736 tokens per second.
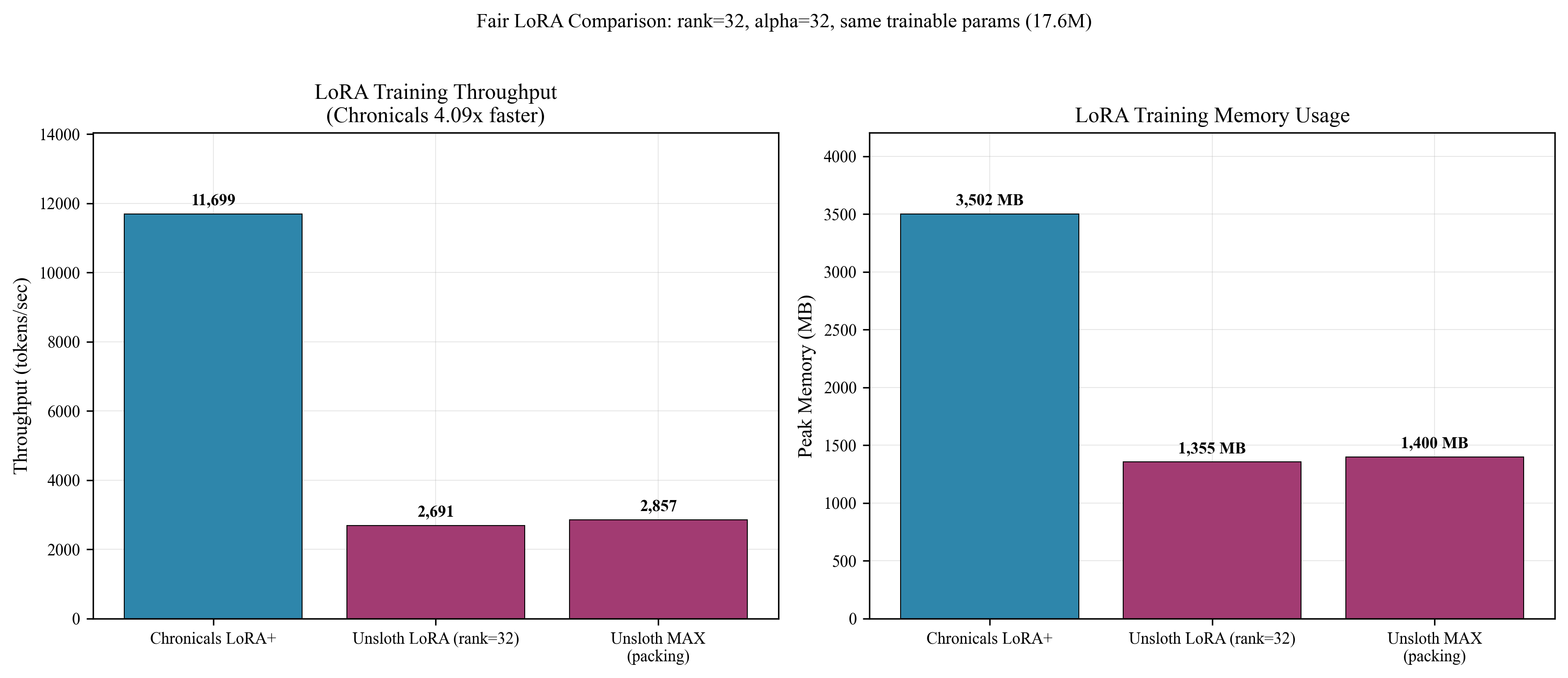
- LoRA training speed (rank 32): 11,699 tokens per second, about 4.10× faster than Unsloth MAX’s 2,857 tokens per second.
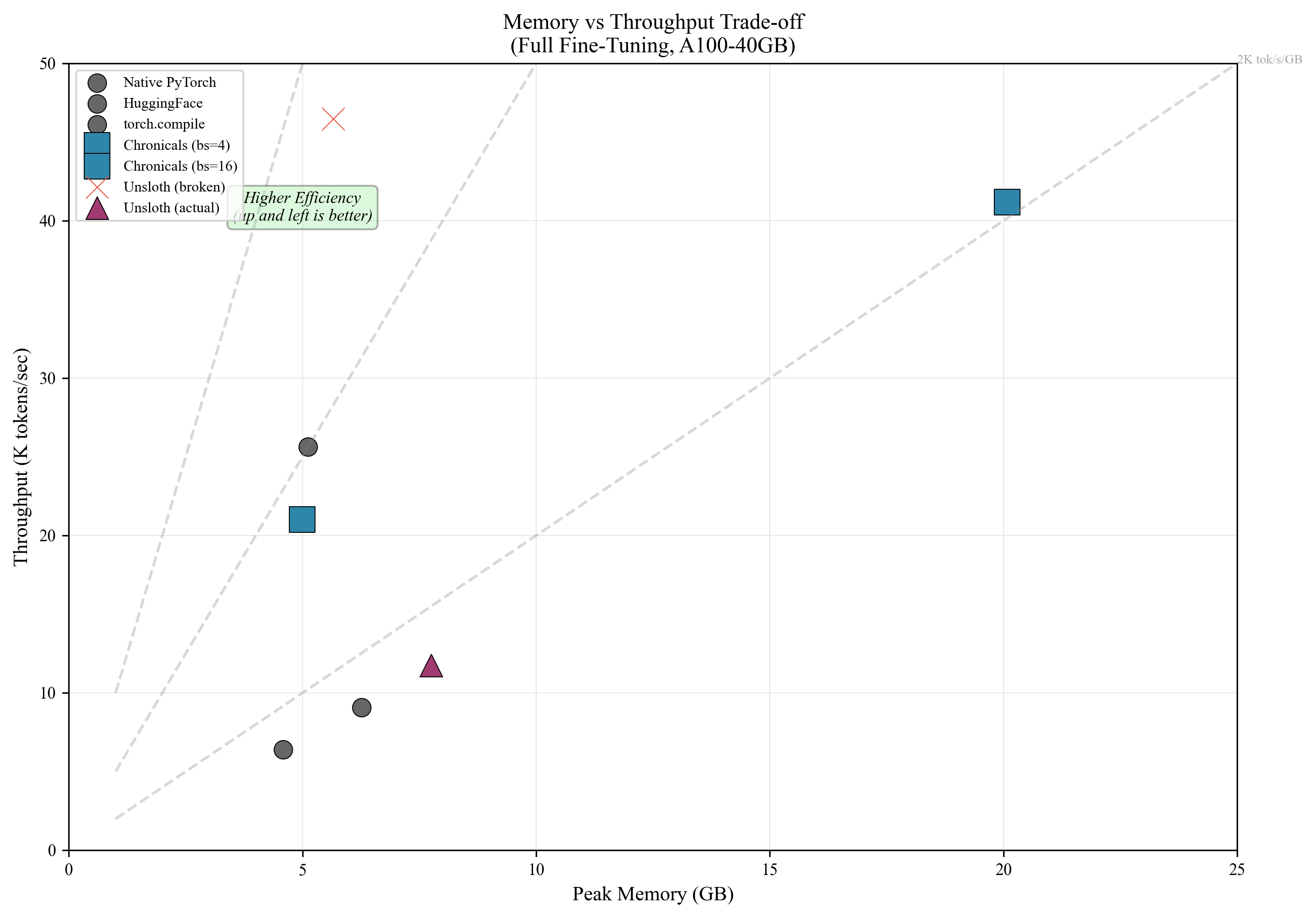
- Memory efficiency: more tokens per second per megabyte than Unsloth (3.34 vs 2.11).
- Massive memory savings at the loss step: cutting logit memory from around 5 GB to about 135 MB by chunking the vocabulary.
- Specific fused operations got solid speedups (RMSNorm 7×, SwiGLU 5×, QK‑RoPE 2.3×).
- They also noticed a problem in one Unsloth benchmark: a reported 46,000 tokens/s run had “zero” gradients, meaning the model wasn’t actually training. When gradient flow was fixed, the speed dropped to realistic numbers.
Why this matters:
- It lets you fine‑tune big models on smaller GPUs that people actually have.
- It cuts training cost and time.
- It can help more researchers and developers experiment without needing huge hardware budgets.
What’s the potential impact?
With Chronicals, more people can train and adapt large models efficiently:
- Lower hardware needs mean broader access, faster iteration, and cheaper experiments.
- Smarter fine‑tuning (LoRA+) can reach good performance faster.
- Better kernels and memory tricks reduce bottlenecks that used to make training painfully slow.
- The framework is open‑source, so others can build on these ideas.
In short, this work shows that training big models doesn’t have to be slow or require massive GPUs. By combining a few well‑chosen optimizations, Chronicals makes fine‑tuning faster, cheaper, and more practical for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps the paper leaves unresolved. Each item highlights what is missing, uncertain, or unexplored and suggests where future work could act.
- Generalization beyond A100-40GB: Throughput and memory gains are only demonstrated on Qwen2.5-0.5B with A100-40GB. It remains unclear how Chronicals performs on H100 (including warp specialization), consumer GPUs (RTX 4090/4080), AMD GPUs, and different VRAM configurations.
- Model-size scaling: The paper motivates 7B memory needs but reports results only on a 0.5B model. Empirical validation for 7B, 13B, and 70B models (full fine-tuning and LoRA) is missing, including whether the proposed techniques keep training viable on single- or few-GPU setups.
- Training quality vs. speed: Benchmarks focus on tokens/second and MFU. There is no systematic evaluation of final model quality (perplexity, instruction-following metrics, downstream task accuracy) to verify that speedups do not degrade performance.
- Long-horizon stability: No evidence is provided for training stability over long runs (e.g., multi-epoch fine-tuning), especially under mixed precision (BF16/FP8), fused kernels, sequence packing, and CCE.
- FP8 training validation: FP8 is listed as a contribution area, but there are no detailed experiments on FP8 calibration (E4M3/E5M2), layer-wise scaling strategies, convergence behavior, or quality trade-offs compared to BF16/FP16.
- Cut Cross-Entropy (CCE) chunk-size selection: The heuristic chunk-size schedule lacks a principled method or auto-tuning strategy tied to device SRAM, occupancy, and workload characteristics. Quantitative trade-offs (occupancy, numerical error, speed) across chunk sizes are not reported.
- CCE numerical robustness in BF16/FP8: While online softmax and Kahan summation are discussed, rigorous error analyses and empirical stress tests for extreme logit magnitudes and very large vocabularies in BF16/FP8 are missing (including underflow/overflow rates and gradient fidelity).
- CCE with label smoothing and Z-loss: The paper does not analyze whether chunked accumulation interacts with label smoothing, Z-loss, or other regularizations, nor how to implement these safely without re-materializing logits.
- Backward pass correctness under chunking: The backward pseudocode re-computes chunked logits but lacks quantitative verification of gradient equivalence to the standard CE across diverse vocab sizes, precisions, and batch/sequence shapes.
- Sequence packing effects on learning: There is no analysis of how packing impacts gradient variance, optimization dynamics, positional encodings (e.g., RoPE), curriculum/order effects, or downstream generalization—only throughput gains are reported.
- Attention masking correctness with packing: The paper does not provide a thorough treatment of packing-specific attention masks, especially for complex masking (causal + cross-attention), and their interaction with FlashAttention and fused kernels.
- Fused QK-RoPE numerical accuracy at long context: The 2.3x speedup is reported, but there is no evaluation of numerical drift or accuracy for very long contexts (e.g., 8k–32k) and variants of RoPE (NTK scaling, dynamic rope) under fusion.
- LoRA+ learning-rate ratio generality: The derived ratio is motivated at initialization, but its dependence on architecture width, LoRA rank , optimizer hyperparameters (e.g., AdamW betas, weight decay), and different initialization schemes is not empirically validated across tasks.
- Dynamic or scheduled LR ratios for LoRA+: It remains unexplored whether a time-varying LR ratio (e.g., high early for , decaying later) improves convergence and stability compared to a fixed 16x ratio.
- 8-bit optimizer states impact on quality: Block-wise quantization for and is described, but there are no ablations on final performance degradation, sensitivity to block size, or interaction with mixed precision and fused gradient clipping.
- Zero-sync gradient clipping effects: The proposed clipping eliminates GPU-CPU sync overhead, but its impact on optimization dynamics, stability, and quality (versus classical clipping and per-parameter clipping strategies) is not measured.
- FlashAttention IO-complexity bound validation: Theoretical bounds are presented, but there is no empirical validation of memory-access profiles (e.g., via profiling counters) across sequence lengths and SRAM sizes to confirm the predicted scaling.
- Kernel fusion portability and maintenance: The paper does not discuss portability to future CUDA/Triton versions, potential autograd edge cases, or fallback pathways when fusion conflicts with torch.compile or specific model components.
- Register pressure and occupancy trade-offs: Fused kernels can increase register usage and reduce SM occupancy. No occupancy analysis or tuning guidance is provided across hidden sizes, batch sizes, and sequence lengths.
- Integration with distributed training: Chronicals’ behavior under DDP/ZeRO, pipeline model parallelism, and tensor/sequence parallelism is not evaluated. Communication overheads, overlap strategies, and net speedups at multi-GPU scale remain unknown.
- Data pipeline and packing overheads: The computational overhead and complexity of packing (e.g., Best-Fit Decreasing) in real dataloaders, its effect on latency/jitter, and its scalability with large corpora are not quantified.
- Benchmarks breadth and fairness: Results focus on a single model/dataset configuration. Cross-framework comparability (exact hyperparameters, kernels, precision settings, masking, packing policies) and multi-version replication (e.g., Unsloth variants) are not fully documented.
- Energy efficiency and cost metrics: There is no measurement of energy per token, cost per training step, or throughput-per-watt to validate real-world efficiency gains.
- Inference-time implications: The paper does not evaluate whether training-side optimizations (e.g., fused kernels, packing) have any carry-over benefits or costs at inference (KV-cache footprint, latency, numerical accuracy).
- Robustness to atypical vocabularies and MoE: CCE and kernel fusion are not evaluated for multilingual vocabularies >250k, subword schemes with large dynamic merges, or mixture-of-experts architectures with expert routing and sparse logits.
- Gradient checkpointing interactions: The framework’s behavior when used alongside gradient checkpointing (which alters activation storage/computation) is not discussed, including net memory/compute trade-offs relative to Chronicals’ kernels.
- Tied embeddings and shared heads: CCE with tied input/output embeddings or shared projection heads is not analyzed, particularly for how chunked computation and gradient propagation should be adapted.
- Hyperparameter sensitivity: There is no sensitivity analysis of key hyperparameters (optimizer betas, weight decay, LR schedules, label smoothing, Z-loss coefficient) under fused kernels and CCE to ensure robust defaults.
- Failure modes and diagnostics: The paper emphasizes a bug in a competing framework, but it does not present a diagnostic suite for detecting silent failures (e.g., zero gradients) within Chronicals itself, nor guardrails for users to verify training correctness.
- Reproducibility artifacts: While code is released, there is no explicit statement of dataset splits, seeds, environment (driver/CUDA/Triton versions), and profiler configurations required to reproduce the exact ablation and throughput numbers.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be adopted now, along with sectors, likely tools/workflows, and key assumptions/dependencies.
- Cost-optimized fine-tuning for enterprises on existing GPUs
- What: Cut end-to-end training time and VRAM by integrating Chronicals for full fine-tuning or LoRA-based adaptation, reducing cloud spend by ~2–4x for equivalent tokens processed.
- Sectors: Software, finance, e-commerce, media
- Tools/workflows: HuggingFace Transformers + Chronicals kernel backends; replace CrossEntropyLoss with Cut Cross-Entropy (CCE); enable FlashAttention; use LoRA+ optimizer wrapper; turn on sequence packing in the data loader.
- Dependencies/assumptions: CUDA-compatible datacenter GPU (e.g., A100 40GB), Triton and FlashAttention installed; numerics validated on the chosen model; throughput gains depend on vocab size, sequence length, and padding distribution.
- On-prem privacy-preserving fine-tuning for regulated data
- What: Fine-tune medium-size models (e.g., 0.5–7B) entirely on hospital/bank on-prem GPUs by reducing memory footprint with CCE, optimizer state quantization, and LoRA+.
- Sectors: Healthcare, finance, legal
- Tools/workflows: LoRA+ with 8-bit optimizer states; fused QK-RoPE and fused RMSNorm/SwiGLU; sequence packing for short clinical/transaction utterances; audit logs for gradient flow.
- Dependencies/assumptions: Compliance constraints require on-prem; model family supports RoPE and FlashAttention; DevOps can compile Triton kernels with validated drivers.
- Cloud “efficient fine-tuning” SKU for ML platforms
- What: Offer a managed fine-tuning tier using Chronicals to deliver lower $/B-token and shorter job times for customers.
- Sectors: Cloud providers, MLOps platforms
- Tools/workflows: Platform-native wrappers for CCE, fused kernels, sequence packing; autoscaling policies based on tokens/s and MFU; customer-facing cost/throughput estimators.
- Dependencies/assumptions: Licensing of Chronicals (open-source), multi-tenant isolation for custom kernels, reliable benchmarking baked into SLAs.
- University/teaching labs enabling LLM training on limited budgets
- What: Run course assignments and small research projects on fewer or smaller GPUs by using Chronicals’ 3.51x throughput and memory savings.
- Sectors: Academia, education
- Tools/workflows: Lab templates with HuggingFace + Chronicals; sequence packer scripts; lab exercises on online softmax and fused kernels.
- Dependencies/assumptions: Faculty/students can install Triton; stable GPU drivers; tasks designed around 0.5–7B models.
- Benchmark correctness guardrails for training pipelines
- What: Detect “fake fast” runs by monitoring gradient norms and loss updates, preventing misreported tokens/s (e.g., zero-gradient bug class).
- Sectors: Software, research labs, MLOps
- Tools/workflows: “Gradient-Flow Sentinel” plugin that asserts non-zero grads per step and flags anomalous MFU/tokens/s; integrates with CI/CD.
- Dependencies/assumptions: Access to autograd/optimizer hooks; standardized logging across training stacks.
- Instruction-tuning for multilingual/code models with large vocabularies
- What: Train models with 100k–250k+ vocab without OOM by chunking logits via CCE (37x reduction vs. naive).
- Sectors: Globalization/localization, developer tools, search
- Tools/workflows: Replace LM head loss with CCE; autotune chunk size; optionally combine with label smoothing and Z-loss.
- Dependencies/assumptions: Vocabulary sharding/chunk sizes tuned to shared memory; numerical stability validated for extreme sequences.
- Faster RLHF and preference optimization loops
- What: Increase iteration speed and reduce cost for PPO/DPO/SFT stages by fusing memory-bound ops and packing variable-length prompts.
- Sectors: Software, robotics, gaming
- Tools/workflows: Chronicals kernels in PPO/DPO training scripts; sequence packing for replay buffers; zero-sync gradient clipping to remove step-time stalls.
- Dependencies/assumptions: RL stack compatibility (PyTorch); reward/objective unchanged.
- Energy and carbon reduction reporting for sustainability goals
- What: Track and report tokens-per-kWh improvements and reduced GPU-hours via Chronicals to meet ESG targets.
- Sectors: Public companies, sustainability programs, research centers
- Tools/workflows: Metering tokens/s with MFU; energy dashboards mapping speedups to kWh saved vs. baseline kernels.
- Dependencies/assumptions: Power monitoring available; baselines recorded under equivalent datasets and hyperparameters.
- SME/startup-friendly “bring-your-own GPU” fine-tuning
- What: Let small teams fine-tune assistants on a single A100/3090/4090 by leveraging LoRA+, 8-bit optimizer states, and CCE to stay within VRAM.
- Sectors: SMBs, startups, indie developers
- Tools/workflows: Cookiecutter repos: LoRA+ wrappers, CCE loss, sequence packer; mixed precision with numerics checks.
- Dependencies/assumptions: Consumer GPUs may need smaller batch/sequence; driver/Triton versions compatible; stability verified per model.
- Data pipeline optimization via sequence packing
- What: Cut 60–75% padding waste in instruction datasets to reclaim GPU cycles.
- Sectors: All sectors handling dialogue/instruction data
- Tools/workflows: Best-Fit Decreasing packer integrated into data loader; custom attention masks; curriculum-aware packing strategies.
- Dependencies/assumptions: Correct causal masks and position handling; measures to avoid length-induced bias.
Long-Term Applications
These opportunities are promising but may require additional research, engineering, or ecosystem maturity.
- On-device continual adaptation for edge and mobile models
- What: Enable periodic LoRA+ personalization on edge accelerators (e.g., future mobile NPUs) using CCE-style chunking and fused kernels.
- Sectors: Consumer devices, automotive, IoT
- Tools/products: Lightweight CCE/online softmax kernels for mobile; edge-friendly sequence packing; periodic background training jobs.
- Dependencies/assumptions: Robust FP8/mixed-precision on edge; energy-aware schedulers; validated numerical stability on-device.
- Serverless or “burst” fine-tuning services
- What: Spin up short-lived GPU bursts with high MFU to fine-tune quickly and cheaply, then scale to zero.
- Sectors: Cloud, SaaS
- Tools/products: Serverless GPU orchestrators tuned for Chronicals MFU; cold-start-optimized fused kernels; per-minute billing integrations.
- Dependencies/assumptions: Fast container bootstrap; kernel cache reuse across tenants; reproducible compilation artifacts.
- Compiler-level fusion and auto-scheduling in mainstream frameworks
- What: Incorporate Chronicals-style fusions (QK-RoPE, LoRA-linear, zero-sync clipping) into torch.compile/XLA/MLIR auto-fusers.
- Sectors: Software, compilers, hardware vendors
- Tools/products: Upstream PRs to PyTorch/Triton; MLIR patterns for online softmax; scheduling heuristics aware of SRAM vs HBM traffic.
- Dependencies/assumptions: Cross-hardware portability; vendor-aligned kernel interfaces; comprehensive CI for numerical and perf regressions.
- Standardized training transparency and benchmarking policy
- What: Require “gradient-verified throughput” in academic/industry reporting and procurement (tokens/s with non-zero grads and loss descent).
- Sectors: Policy, public sector, research councils
- Tools/products: Reporting checklists; reproducibility bundles (configs, seeds, logs); audit scripts verifying gradient flow and MFU.
- Dependencies/assumptions: Community consensus; journal/conference policy adoption; vendor cooperation.
- Carbon-aware schedulers using MFU and arithmetic intensity models
- What: Schedule training when grid carbon intensity is lowest and pack jobs to maximize MFU, cutting emissions without changing models.
- Sectors: Cloud, HPC centers, public research infrastructure
- Tools/products: MFU/AI ridge-point predictors; carbon-aware job placement; live telemetry of bytes moved vs FLOPs.
- Dependencies/assumptions: Accurate power/telemetry; cluster-level integration; robust performance models across hardware.
- Commodity GPU training of larger models via multi-optimization stacking
- What: Train 7B–13B models on small clusters by stacking CCE, sequence packing, optimizer quantization, and advanced attention (FlashAttention variants).
- Sectors: Open-source labs, startups, universities
- Tools/products: “Resource-minimal pretraining” playbooks; pipeline parallel + fused-kernel presets; automated chunk/pack autotuning.
- Dependencies/assumptions: Stable multi-GPU comms; extended validation for long contexts; careful convergence monitoring.
- Task-aware, dynamic sequence packing and curriculum learning
- What: Adaptive packers that co-pack samples by length and difficulty, optimizing both throughput and learning dynamics.
- Sectors: Education tech, enterprise training platforms
- Tools/products: Packers with learnable policies; feedback loops from loss/grad stats; guardrails to avoid curriculum bias.
- Dependencies/assumptions: Reliable per-sample metrics; causal and position encoding correctness; fairness/robustness evaluations.
- Hardware co-design for memory-bound training ops
- What: Architect GPU/accelerator SRAM, caches, and instruction sets to favor online softmax, fused norms/activations, and zero-sync primitives.
- Sectors: Semiconductors, systems research
- Tools/products: ISA extensions for fused reductions; SRAM sizing tuned to chunked vocabulary ops; kernel-friendly DMA paths.
- Dependencies/assumptions: Vendor roadmaps; compiler support; workload characterization beyond today’s models.
- Privacy-first vertical solutions with on-prem fine-tuning kits
- What: Pre-validated turnkey stacks (hardware + software) for hospitals/banks to fine-tune models privately and efficiently.
- Sectors: Healthcare, finance, government
- Tools/products: Appliances bundling Chronicals; audited kernels; compliance documentation; red-team evaluation of numerical stability and privacy leakage.
- Dependencies/assumptions: Vendor support; regulatory certification; secure supply chain for kernel binaries.
- Automated hyperparameter schedulers for LoRA+ differential learning rates
- What: Controllers that adjust the A/B LR ratio online based on gradient magnitudes to accelerate convergence robustly across architectures.
- Sectors: MLOps, AutoML
- Tools/products: Optimizer plugins measuring ||∇A||/||∇B||; LR-ratio schedulers with safety constraints; experiment managers.
- Dependencies/assumptions: Generalization of the ~16x heuristic; stability under mixed precision and different inits; cross-task validation.
Notes on Assumptions and Dependencies (cross-cutting)
- Hardware: Reported gains are demonstrated on A100-40GB with Qwen2.5-0.5B; benefits generalize but exact speedups vary by GPU, model family, and vocab size.
- Software stack: Requires Triton, FlashAttention, and compatible CUDA/driver versions; some fused kernels can be sensitive to compiler or driver regressions.
- Numerics: CCE and chunk sizes must be tuned for stability; label smoothing and Z-loss can help; FP8/mixed-precision settings require validation per model.
- Model features: Fused QK-RoPE assumes RoPE-based models; sequence packing requires correct attention masks and positional handling.
- Convergence: The LoRA+ 16x A/B LR ratio is a principled heuristic; monitoring and adaptive scheduling are recommended for new architectures/tasks.
- Reproducibility: Gradient-flow verification should be standard in benchmarks to avoid over-reporting tokens/s without true learning.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update, improving generalization in neural network training. "Optimizer states for AdamW consume 8 bytes per parameter (first and second moments in FP32)."
- Arithmetic Intensity: The ratio of floating-point operations to memory accesses, determining whether an operation is compute-bound or memory-bound on GPUs. "The A100's peak of 312 TFLOPS (BF16) requires 156 arithmetic operations per byte transferred from global memory---the arithmetic intensity threshold."
- BF16: A 16-bit floating-point format (bfloat16) commonly used in large-scale training to reduce memory while maintaining numerical stability. "Model weights occupy 2 GB in BF16 (1 billion parameters × 2 bytes)."
- Best-Fit Decreasing: A bin packing heuristic with provable bounds, used here to analyze the efficiency of sequence packing. "Best-Fit Decreasing approximation bounds for sequence packing: at most 11/9 * \text{OPT} + 6/9 bins (Section 7)"
- Block-wise Quantization: A quantization method that stores a scale per block and quantizes values relative to that scale, enabling 8-bit optimizer states with minimal error. "Block-wise Quantization"
- Cut Cross-Entropy: A memory-efficient loss computation that chunks the vocabulary and uses online softmax to avoid materializing full logits. "Cut Cross-Entropy (CCE), introduced by Apple researchers, computes cross-entropy without ever forming the full logit tensor."
- FlashAttention: An attention algorithm that tiles computation to on-chip memory and uses an online softmax, reducing memory from O(N2) to O(N). "FlashAttention reduces attention memory from O(N2) to O(N)."
- FlashAttention-3: A variant optimized for H100 GPUs with warp specialization, achieving high utilization. "FlashAttention-3 extends this to H100 with warp specialization, achieving 740 TFLOPS (75\% utilization)."
- FP32: 32-bit floating-point precision, often used for optimizer states and some accumulators. "56GB for optimizer states in FP32."
- FP8 quantization: Using 8-bit floating-point precision to reduce memory and bandwidth while maintaining training quality. "FP8 quantization with sequence packing (Section 7)."
- Fused QK-RoPE: A single kernel that applies rotary embeddings to queries and keys together, improving performance over separate operations. "Fused QK-RoPE: Applies rotary embeddings to queries and keys in a single kernel, achieving 2.3x speedup over separate operations"
- Fused Triton Kernels: Combined GPU kernels written in Triton that reduce memory traffic and kernel launch overhead by performing multiple operations in one pass. "fused Triton kernels that eliminate 75\% of memory traffic"
- GQA (Grouped-Query Attention): An attention variant that shares key-value groups across multiple query heads to reduce memory. "GQA \cite{ainslie2023gqa} uses key-value groups shared across query heads:"
- Gradient checkpointing: A technique that saves memory by recomputing activations during the backward pass instead of storing them. "Without gradient checkpointing, these must persist for the backward pass."
- HBM (High Bandwidth Memory): The GPU’s global memory with very high bandwidth but higher latency than on-chip memory. "limited by the 2 TB/s HBM bandwidth rather than compute capacity."
- I/O Complexity: The complexity of memory accesses required by an algorithm, used to analyze attention implementations. "IO complexity bounds for FlashAttention showing memory accesses for SRAM size (Section 6)"
- Jacobian (Softmax Jacobian): The matrix of partial derivatives for the softmax function, which couples elements within a row and complicates the backward pass. "The softmax Jacobian couples all elements of each row, making the backward pass non-trivial:"
- Kahan Summation: A compensated summation algorithm that reduces floating-point error in long sums. "Our implementation uses Kahan summation when computing -sum across chunks to maintain numerical precision for large vocabularies."
- KV cache: Cached keys and values used during attention to avoid recomputation, especially relevant at inference; it has significant memory cost. "This reduces KV cache memory by factor ."
- Label smoothing: A regularization technique that softens the one-hot target distribution to prevent overconfidence. "Label smoothing softens the target: instead of demanding 100\% confidence in the correct answer, we ask for confidence while spreading the remaining uniformly across all tokens."
- Liger Kernel: A library of fused Triton kernels for transformer components, reducing memory and improving throughput. "Liger Kernel \cite{liger2024} applies the fusion principle to other transformer operations."
- LoRA: Low-Rank Adaptation, which constrains fine-tuning updates to low-rank matrices to reduce trainable parameters and memory. "LoRA \cite{hu2021lora} sidesteps the memory problem for fine-tuning by constraining weight updates to low-rank decompositions: "
- LoRA+: An enhancement to LoRA that sets a higher learning rate for the B matrix (e.g., 16x) to improve convergence. "The LoRA+ paper \cite{hayou2024loraplus} proved that standard LoRA's use of identical learning rates for A and B matrices is suboptimal---B requires 16x higher learning rate for proper convergence."
- Logsumexp: A numerically stable computation of the log of a sum of exponentials, forming the softmax normalization term. "The term normalizes by the sum of all exponentials---this is the log of softmax's denominator."
- Multi-Head Attention: An attention mechanism that computes multiple parallel attention heads and concatenates their outputs. "Multi-head attention projects inputs into parallel attention heads:"
- Online Softmax: A streaming algorithm that maintains a running max and sum to compute softmax normalization without storing all inputs. "We derive the online softmax algorithm enabling 37x memory reduction for vocabulary size 151,936"
- RMSNorm: Root Mean Square Layer Normalization, normalizing inputs by their RMS instead of mean and variance. "Their fused Triton kernels for RMSNorm, SwiGLU, and cross-entropy reduce memory allocation and kernel launch overhead."
- Rotary Embeddings (RoPE): A positional encoding method that rotates query and key vectors to encode relative positions. "FlashAttention and rotary embeddings (Section 6)"
- Sequence packing: A batching technique that concatenates short sequences to reduce padding and recover wasted compute. "Sequence packing recovers 60-75\% of compute wasted on padding."
- SiLU: The Sigmoid Linear Unit activation defined as SiLU(x) = x * σ(x), often used within gated units. "SiLU is the Swish activation"
- SRAM: On-chip shared memory with much higher bandwidth and lower latency than global memory, crucial for tiled GPU algorithms. "By computing attention in tiles that fit in SRAM and using an online softmax algorithm to accumulate results without materializing the full score matrix"
- SwiGLU: A gated linear unit variant combining SiLU activation with multiplicative gating, widely used in modern transformers. "SwiGLU is the gated activation used in modern LLMs (LLaMA, Qwen, Mistral)."
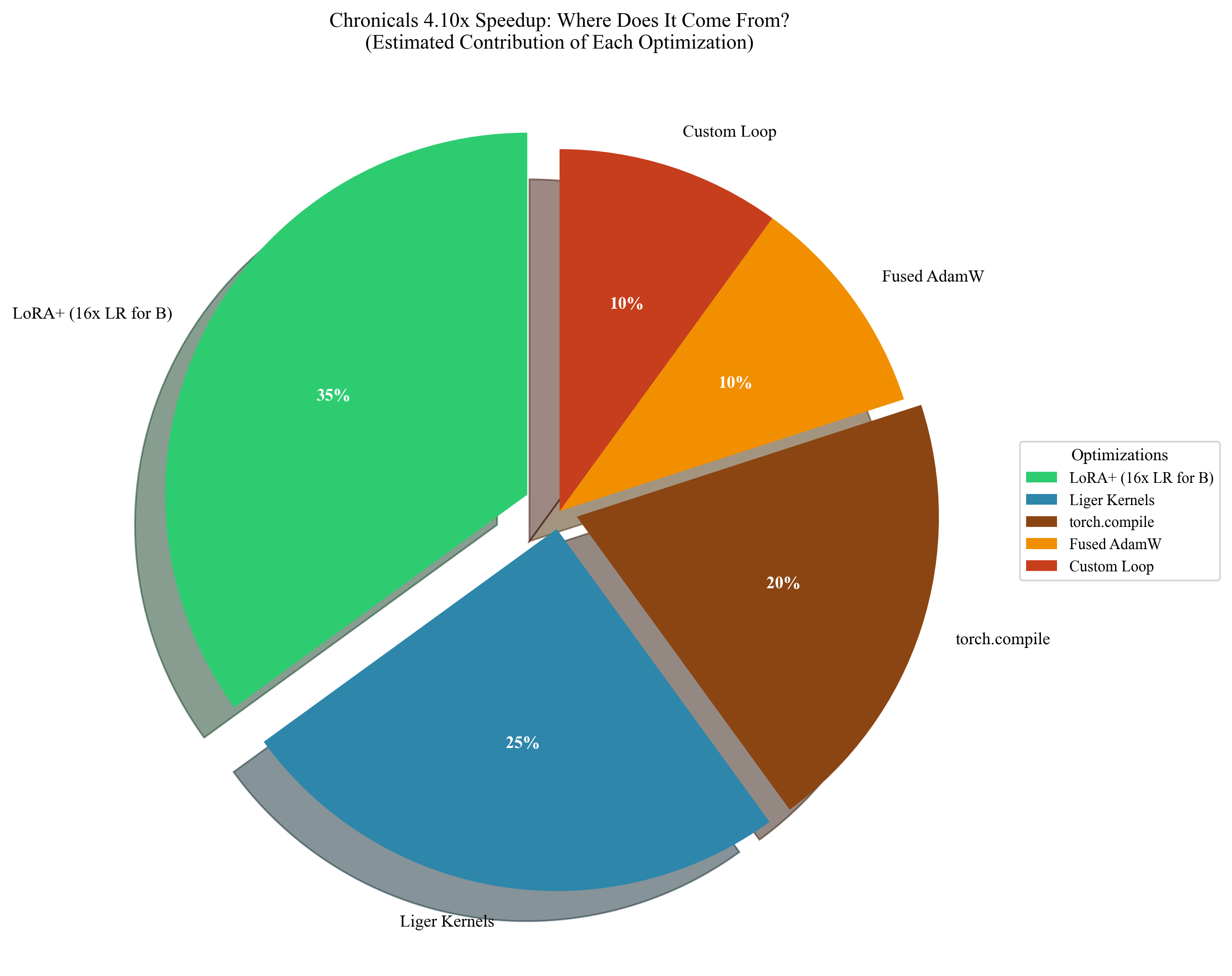
- torch.compile: A PyTorch feature that compiles and optimizes computation graphs to improve performance. "FlashAttention contributes 1.9x, torch.compile adds 1.5x, fused Liger kernels provide 1.4x, sequence packing gives 1.2x, and fused optimizers add 1.07x."
- Triton: A domain-specific language for writing high-performance GPU kernels in Python. "Triton is a domain-specific language that generates GPU code from Python, achieving CUDA-level performance with Python-level productivity."
- Warp-level primitives: GPU operations (e.g., reductions) performed within a warp to accelerate parallel reductions and avoid global memory atomics. "Using warp-level primitives (tl.sum) for computing variance avoids the overhead of global memory atomics"
- Warp specialization: An optimization technique assigning different roles to warps to improve GPU utilization in complex kernels. "FlashAttention-3 extends this to H100 with warp specialization, achieving 740 TFLOPS (75\% utilization)."
- Z-loss: A regularization term that penalizes large logsumexp values to prevent logit magnitudes from exploding. "Z-loss regularization, introduced by PaLM \cite{chowdhery2022palm}, penalizes large values:"
- Zero-sync gradient clipping: Gradient clipping performed entirely on the GPU to avoid costly CPU-GPU synchronization. "Zero-sync gradient clipping: Clips gradients without GPU-CPU synchronization, eliminating a 50-100s bottleneck per step"
Collections
Sign up for free to add this paper to one or more collections.