- The paper introduces a novel benchmark, MultiSessionCollab, to measure how well agents learn and apply user preferences in consecutive sessions.
- It presents a memory-augmented agent architecture that integrates session-level reflections and RL-based updates to enhance preference alignment.
- Empirical evaluations, including a human user study, demonstrate that agents with memory significantly improve task success, reduce user effort, and shorten conversations.
Learning User Preferences Through Interaction for Long-Term Collaboration
Motivation and Problem Setting
The paper "Learning User Preferences Through Interaction for Long-Term Collaboration" (2601.02702) addresses the problem of personalization in LLM-based conversational agents operating across multiple user sessions. Motivated by the empirical limitations of current personalized LLMs—primarily short-horizon evaluation and a lack of mechanisms for persistent adaptation—the work focuses on long-term collaborative interaction. It introduces a new benchmark, MultiSessionCollab, designed specifically to measure how well agents can learn user preferences during repeated interactions and leverage this knowledge to improve collaboration quality over time.
A core premise is that effective human-AI collaboration requires not only competence in domain reasoning but also adaptive alignment with user-specific interaction preferences. These preferences, modeled as non-trivial constraints on response style, content, and initiative, are expected to be learned incrementally without explicit re-statement by the user.
MultiSessionCollab Benchmark Design
MultiSessionCollab operationalizes the evaluation of longitudinal preference adaptation via a simulated environment where agents have to support users in solving problems drawn from five challenging datasets (MATH-500, MATH-Hard, LogiQA, MMLU, MedQA). Each session consists of turn-based collaborative problem-solving, with only the user having access to the problem statement. Agents must elicit sufficient contextual information, reason about optimal solutions, and crucially, align their communicative acts with the user's stated preferences, which are revealed and enforced incrementally.
User simulators are instantiated from the large-scale Persona Hub dataset and assigned three randomly selected interaction preferences, reflecting dimensions such as elaborateness, politeness, proactivity, and analytical style, grounded in cognitive science and HCI literature. User simulators enforce these preferences by interrupting the task-flow and refraining from updating their internal draft answer unless the agent's response aligns with all enforced preferences.
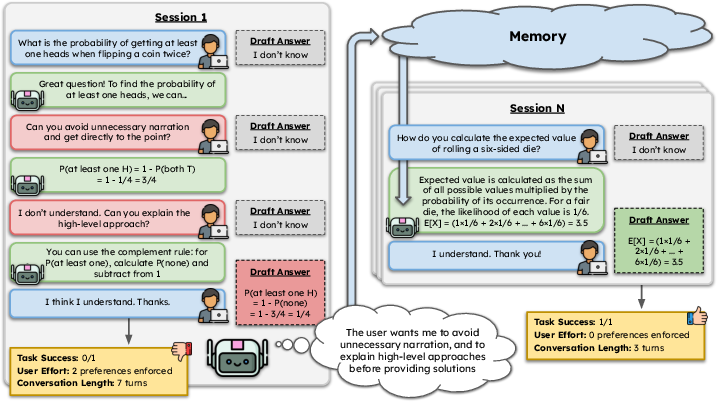
Figure 1: The MultiSessionCollab benchmark schematic, illustrating the session flow, preference enforcement, agent memory updates, and evaluation signals.
The evaluation framework consists of three orthogonal axes: task success (final problem-solving accuracy), user effort (number of preference enforcement actions required), and conversation length (number of turns).
Long-Term Collaborative Agent Architecture
To address the persistence of user preference information, the paper proposes a memory-augmented agent framework. Each agent maintains an external memory that is (a) refined after every session via structured agent-generated reflections and (b) provided as context during both the system prompt initialization and at crucial turn-level retrieval points. The memory is intended not to maximize verbatim recall but to encode actionable, user-specific strategies and preference policies recovered from dialogue.
A session-level reflection component analyzes each completed interaction to extract and update preference notes, integrating evidence from user enforcement utterances. The memory can be dynamically retrieved and conditionally injected into the agent’s context for maximal relevance, as determined by the ongoing conversational trajectory.
Reinforcement Learning for Memory Refinement
The memory update process is further optimized via reinforcement learning. The proposed RL framework leverages Group Relative Policy Optimization (GRPO), where the policy generates reflection rollouts post-session. An LLM-based judge evaluates these rollouts for completeness, actionability, and faithfulness against user-enforced preference signals, assigning dense rewards based on coverage and output format constraints. Policy improvement is thus driven by maximizing coverage of user-revealed preferences while minimizing hallucinations and redundancy.
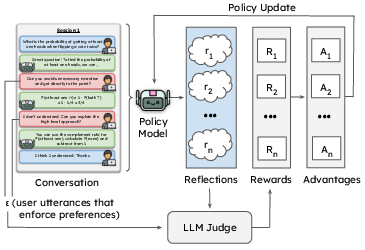
Figure 2: RL architecture for training reflection policies; n rollouts are scored by the judge wrt preference enforcement utterances, with GRPO updates.
Empirical Evaluation
Simulation Results
Agents are assessed under three conditions—no memory, memory without RL, and memory with RL (GRPO-trained)—across model scales and architectures (Llama-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, gpt-oss-20b, Llama-3.3-70B-Instruct). Extensive experiments over 10,000 sessions per agent demonstrate:
- Consistent, statistically significant improvements in task success, reduced user effort, and shorter conversations when memory is enabled, across all models.
- RL-trained agents (with GRPO) achieve even larger gains, especially for memory retrieval and preference adherence-sensitive metrics, transforming some negative or stagnant memory impacts into measurable positive outcomes. For instance, Qwen-2.5-7B-Instruct with memory and GRPO yields a +3.43% improvement in aggregate task success compared to the baseline.
- The effect of memory is dynamic: early sessions show steep deltas in performance, with gains stabilizing but persisting through at least 20 sessions.
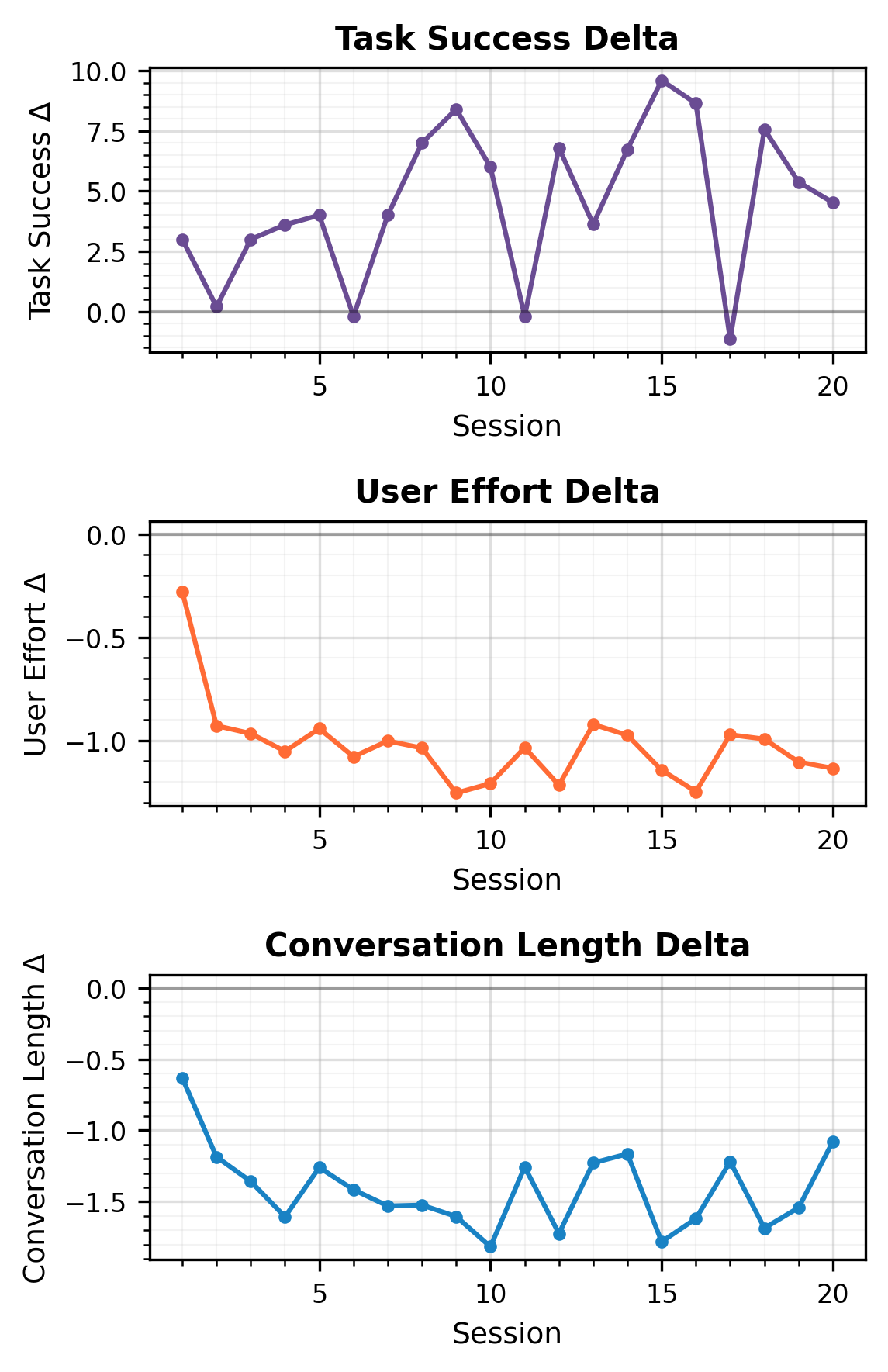
Figure 3: Longitudinal deltas in performance (task success, user effort, conversation length) for Llama-3.3-70B-Instruct, highlighting the cumulative benefit of persistent memory.
Additional analyses show that memory-augmented agents can rival or exceed the performance of "oracle" agents directly provided with user preferences. This indicates that contextualized, interaction-derived preference notes may encode richer actionable knowledge than static user-declared preferences.
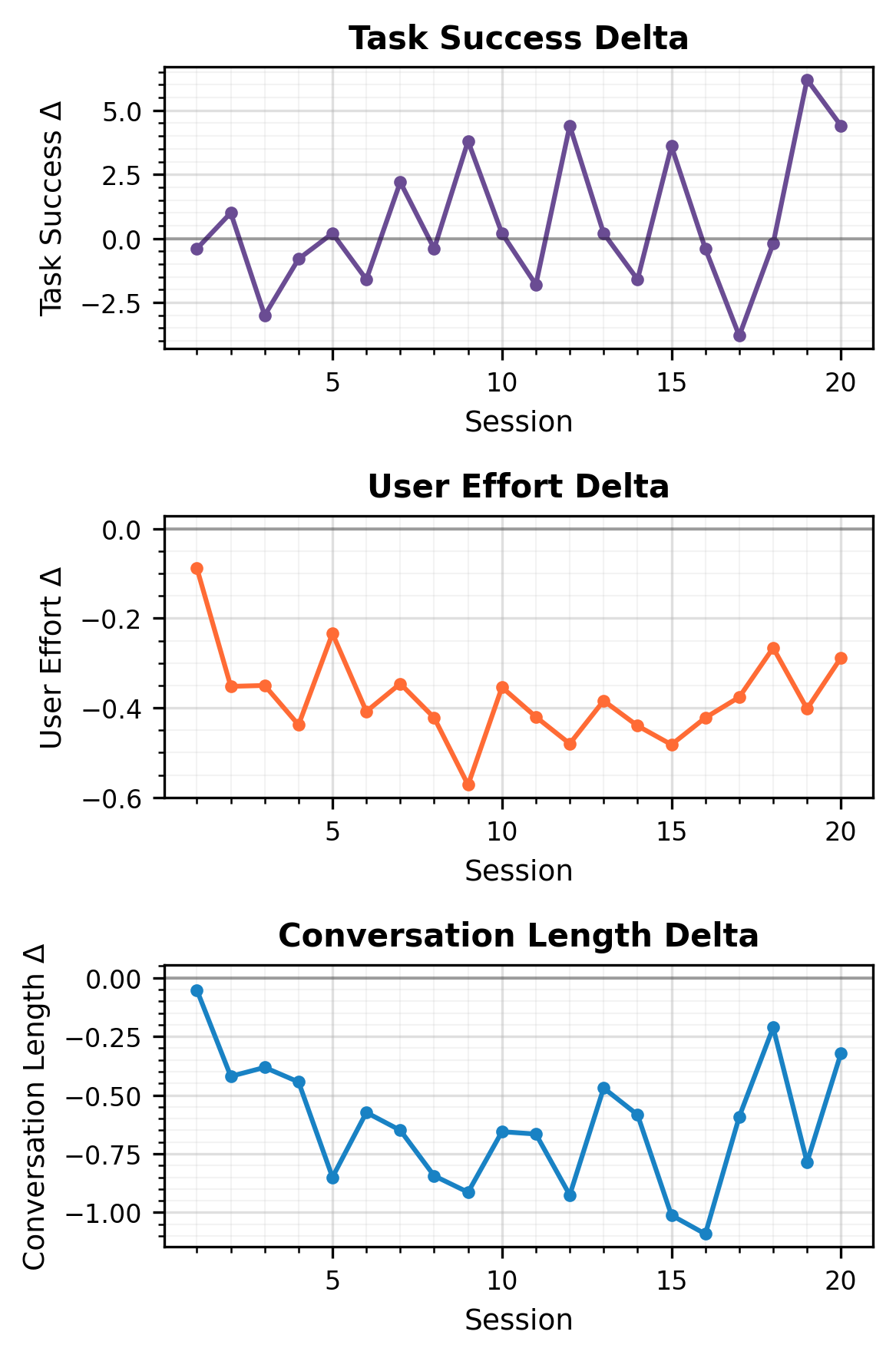
Figure 4: Performance deltas across sessions for Qwen-2.5-7B-Instruct post-GRPO, showing robust memory impacts on all target metrics.
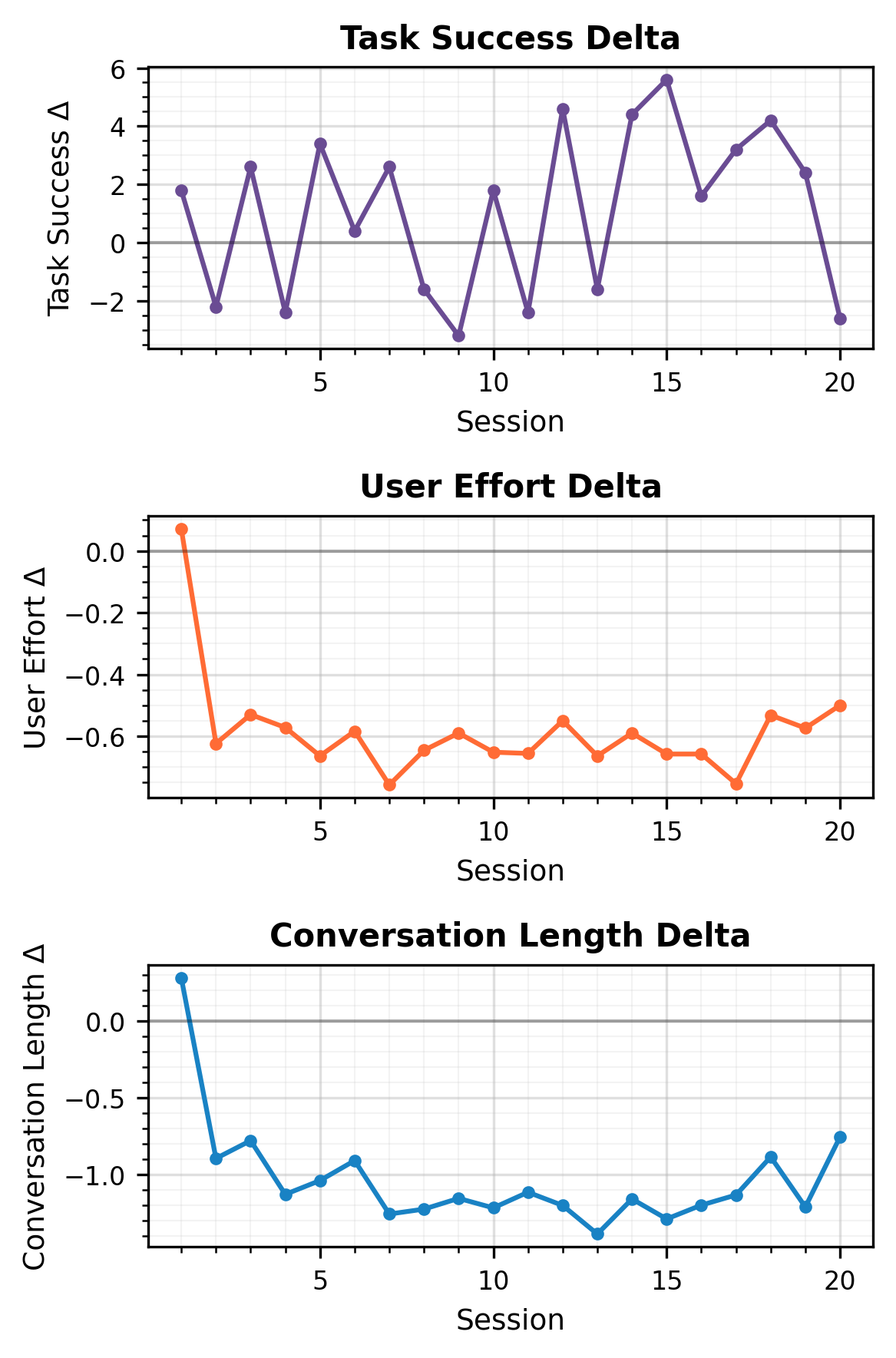
Figure 5: Llama-3.1-8B-Instruct's session-level deltas after GRPO, underscoring enhanced efficiency and preference alignment.
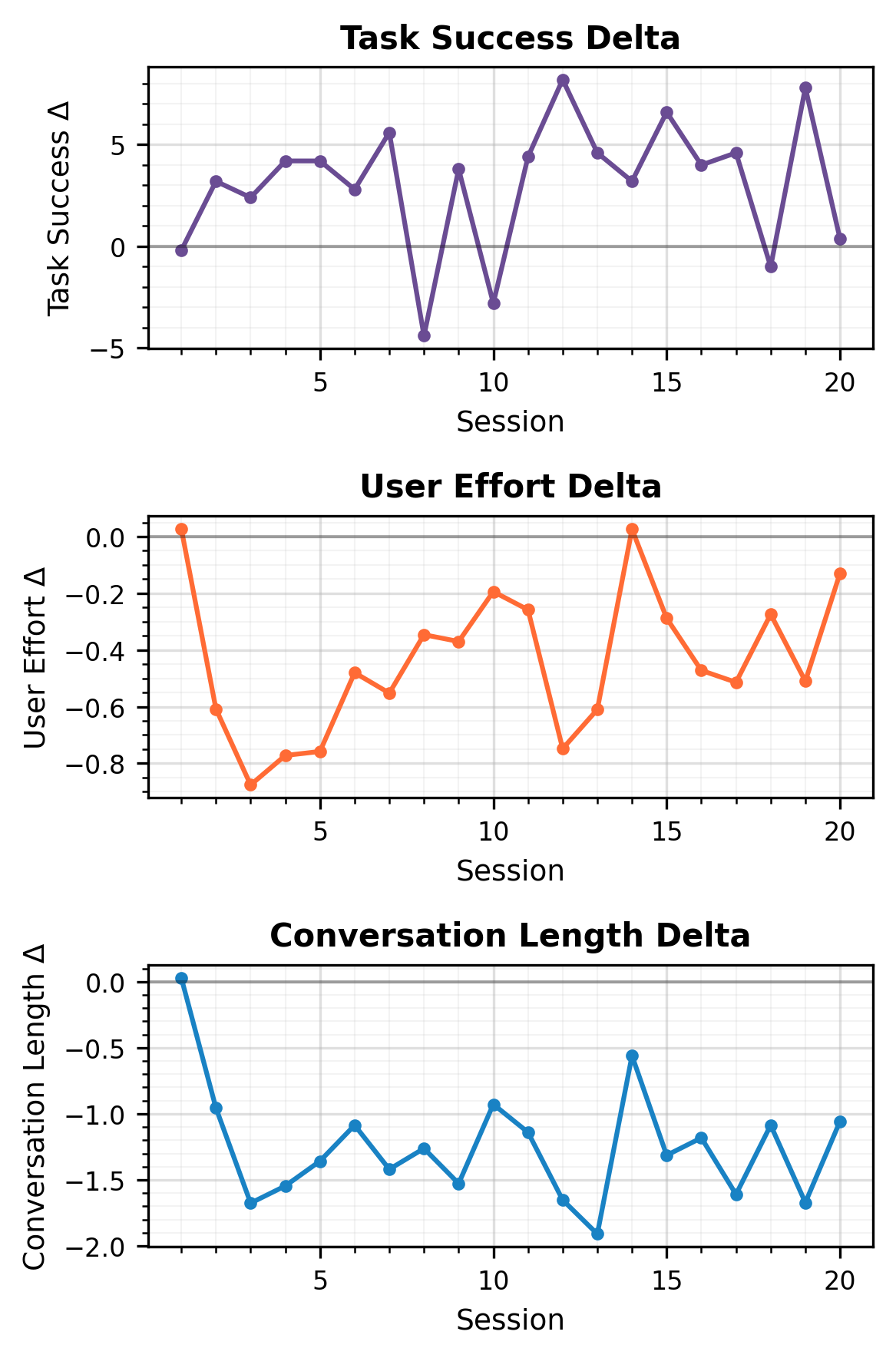
Figure 6: gpt-oss-20b delta curves, further confirming cross-model transferability of the memory effect.
Human User Study
A controlled user study with 19 participants validates the simulated findings. Users enforced both explicit and self-selected preferences across three sessions spanning code, writing, and math tasks. Agents with memory mechanisms were perceived as more personalized, led to reduced session length, better preference retention, and higher subjective satisfaction, though some limitations emerged in cross-domain preference generalization.

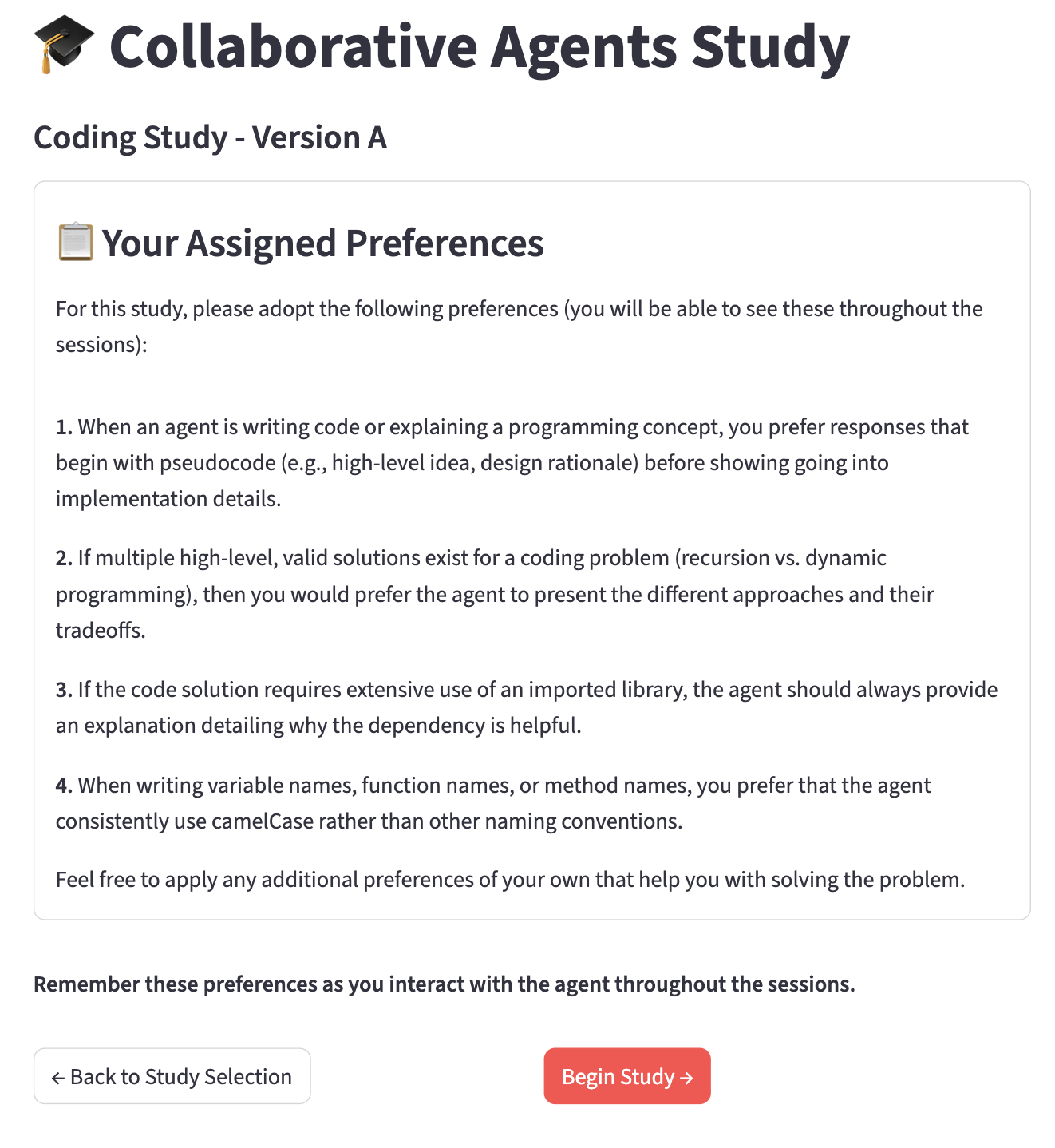
Figure 7: User study interface sample instructions screen.
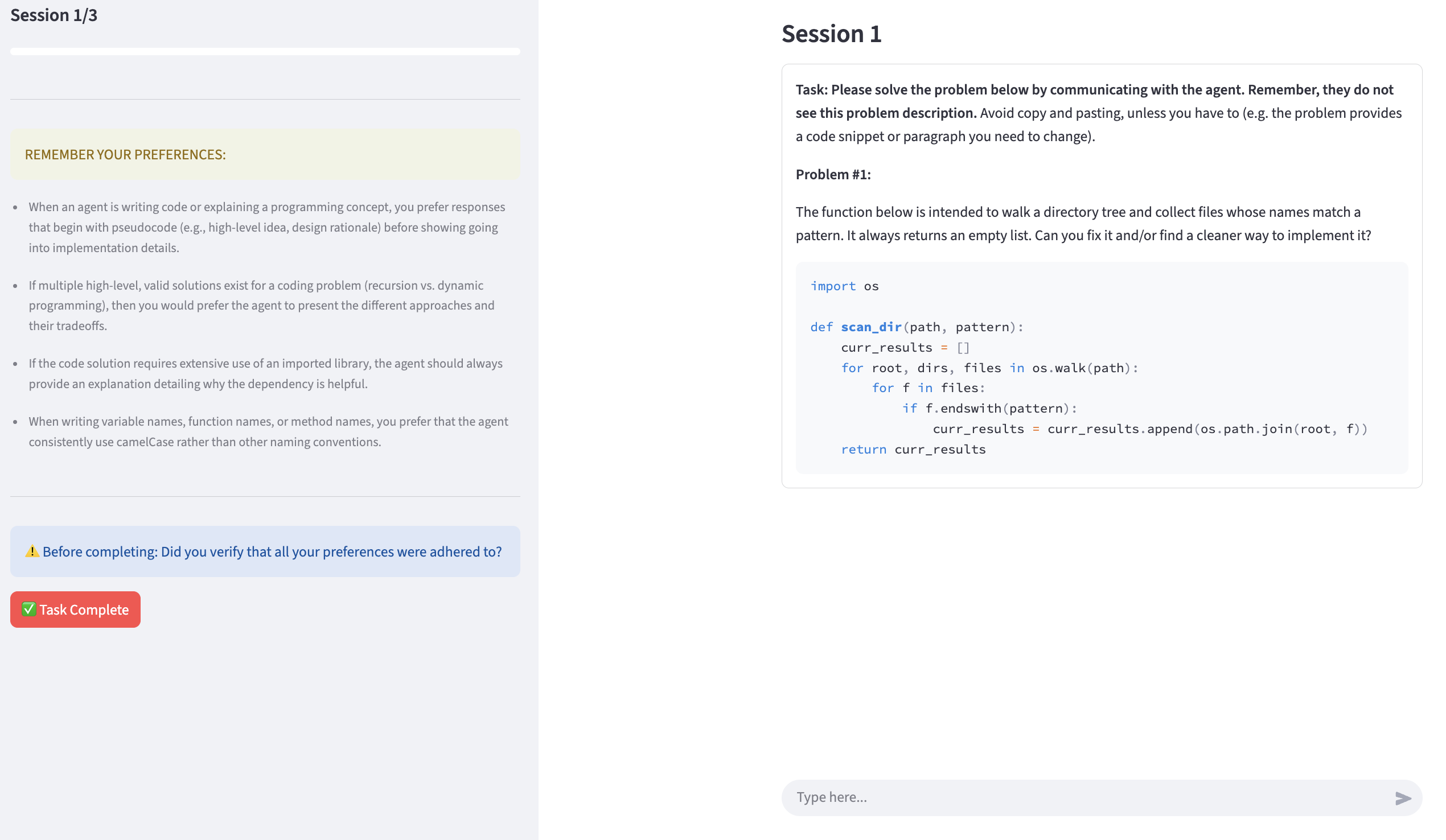
Figure 8: A real session from the user study, demonstrating agent-user preference negotiation and problem-solving dynamics.

Figure 9: Post-session user survey used for grounded measurement of subjective experience.

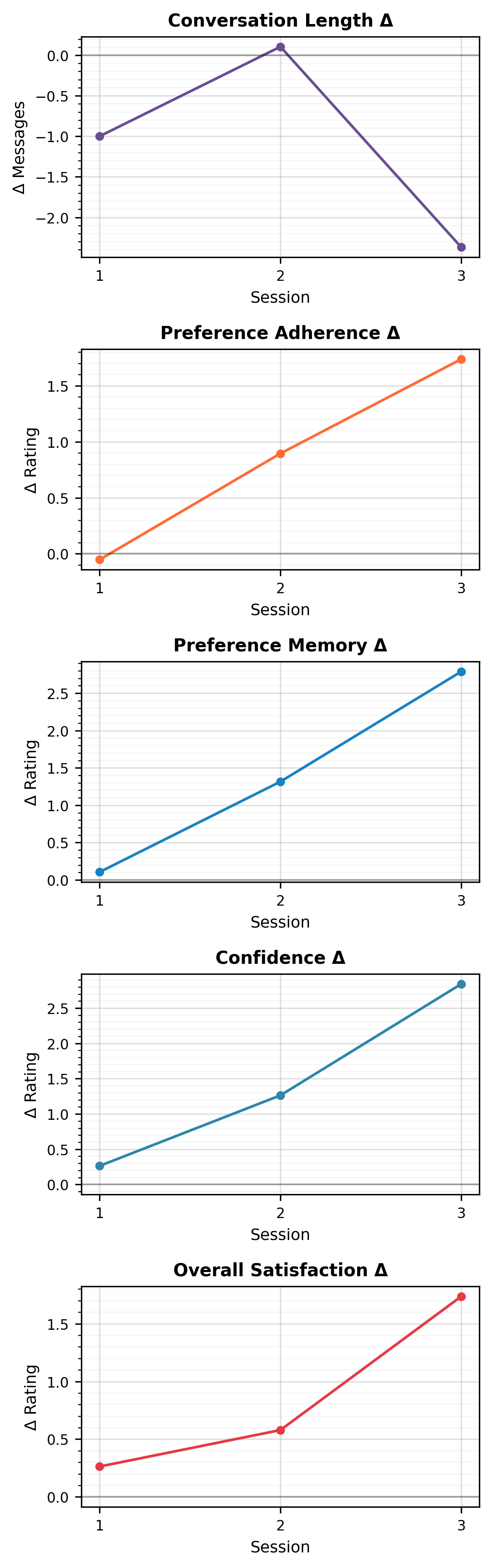
Figure 10: Coding domain example integrated in the study.
Discussion and Implications
Theoretical Implications
This work substantiates the hypothesis that LLM-based agents can incrementally and persistently acquire fine-grained user interaction policies through longitudinal interaction, provided a suitable memory architecture and alignment objective. The demonstrated superiority over "oracle" preference provision supports the perspective that preference acquisition is not purely a information retrieval task but a contextual, adaptive policy formation process.
The efficacy of RL-driven memory updates, leveraging reward signals directly from user act enforcement rather than synthetic supervision, signals a promising methodological direction for preference alignment in LLMs.
Practical Implications
Agents exhibiting robust long-term memory and preference learning are positioned to offer improved user experiences in domains such as tutoring, complex collaborative workflows, and personalized knowledge assistants. Critically, these agents minimize repetitive preference specification by users and lower cognitive frictions, which is crucial for deployment in settings where user engagement and longitudinal satisfaction are priorities.
However, the findings also highlight domain transfer challenges: cross-domain generalization of preferences remains imperfect, and memory-induced personalization can be outperformed—on occasion—by explicit user re-statement, pointing to unresolved problems in context and abstraction management.
Future Directions
The methodology lays a research trajectory toward:
- Extending preference models to handle temporally-evolving, context-sensitive, or implicitly expressed preferences
- Fusing richer behavioral cues (beyond direct enforcement utterances) into the preference learning signal
- Advancing cross-domain and meta-preference adaptation strategies in memory retrieval and abstraction
- Diagnosing and mitigating memory overwriting and preference forgetting dynamics in continual learning regimes
Conclusion
The study establishes the importance and feasibility of agents that acquire robust, actionable models of user preference through interaction, mediated by structured memory and reinforcement learning. The MultiSessionCollab benchmark provides a rigorous, extensible testbed for this learning paradigm. Experimental results across both simulation and human trials confirm that memory-equipped, reflectively trained agents achieve higher collaboration quality and user satisfaction, setting a new bar for personalized, long-term human-AI interaction (2601.02702).