- The paper shows that LLMs' concept circuits with higher node importance and robustness drive stronger learning but increase the risk of forgetting under continual pre-training.
- It employs controlled pre-training with the Fico dataset and graph metrics to quantify circuit dynamics and map acquisition with interference patterns.
- The study reveals asymmetric transfer among knowledge types, guiding curriculum design to mitigate interference and enhance retention.
Circuit-Level Dynamics of Concept Learning in LLMs during Continual Pre-Training
Introduction
This paper investigates the representation and acquisition of conceptual knowledge in LLMs during continual pre-training, with a focus on the internal circuit-level mechanisms. Unlike prior studies that emphasize fact-level knowledge or probe model outputs in isolation, this work introduces a framework for tracing concept learning, forgetting, interference, and synergy at the computational subgraph level. The analysis leverages concept circuits—DAG subgraphs associated with individual concepts—and their graph-theoretic properties, providing mechanistic insights with potential implications for curriculum design, data scheduling, and interference mitigation in continual learning paradigms.
The methodology centers on the construction of the Fico dataset, which maps real-world ConceptNet knowledge to synthetic concepts, avoiding contamination from prior LLM knowledge. Through controlled continual pre-training and systematic analysis of the learned circuits, the paper demonstrates non-trivial, statistically robust correlations between circuit topology and behavioral learning dynamics, as well as inter-concept interference dependent on semantic and graph-level proximity.
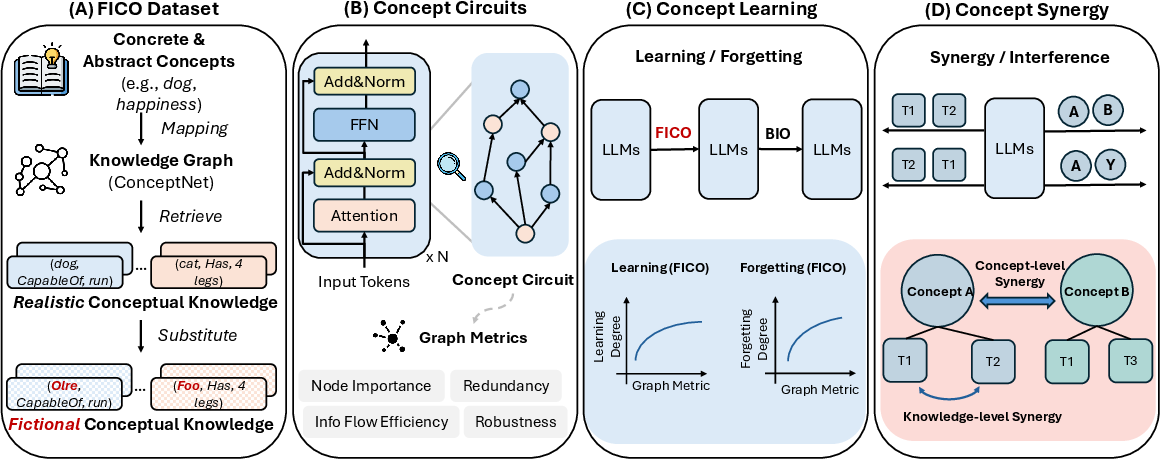
Figure 1: Overview of the experimental pipeline, including the construction of synthetic concepts, extraction and analysis of concept circuits, continual pre-training, and interference/synergy studies.
Methodology
Fico Dataset Construction
The Fico dataset is designed to provide controlled analysis of concept representation without contamination from prior knowledge. Concretely, it maps 1,000 real-world concepts (500 concrete, 500 abstract) and their associated relational knowledge (drawn from ConceptNet) to randomly generated fictional names. Relations are grouped into five major knowledge types (e.g., Hyponym–Hypernym, Property–Affordance), and templates for expressing knowledge triples are diversified via GPT-5. The resulting dataset supports evaluation of relational generalization independent of surface form memorization.
Concept Circuit Extraction and Graph Metrics
Concept circuits for each synthetic concept are identified via EAP-IG, selecting edges whose cumulative importance preserves ≥70% of model performance on relevant knowledge, at various checkpoints during continual pretraining. Circuit structure is then characterized using four families of graph metrics:
- Node Importance: Variance in eigenvector centrality, indicating hub concentration.
- Redundancy: Edge density.
- Information Flow Efficiency: Global efficiency (inverse shortest path).
- Robustness: Mean k-core number.
These metrics enable quantification of acquisition and retention correlates at the circuit level.
Continual Pre-Training and Behavioral Metrics
A two-stage training regime is employed: (1) pre-train an LLM (GPT-2-Large, LLaMA-3.2B) on the Fico train set, then (2) continue pre-training on unrelated BIO data to induce forgetting. Behavioral learning/forgetting degrees are defined as the aggregate change in output logits (and probabilities) for concept-related knowledge across stages.
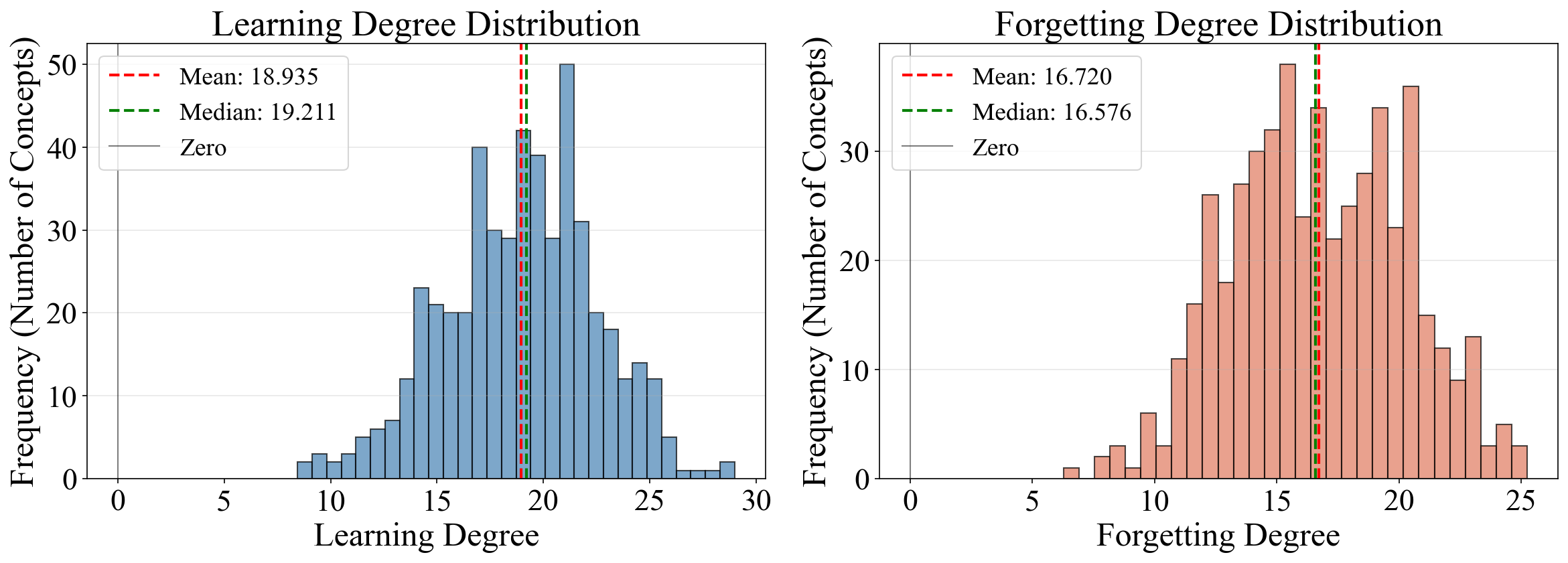
Figure 2: Distribution of learning and forgetting degrees across concepts, demonstrating substantial heterogeneity in concept acquisition and retention.
Circuit-Behavioral Correlation Analysis
Systematic analysis demonstrates unimodal but widely dispersed distributions of both concept learning and forgetting degrees. Importantly, pairwise Spearman correlations reveal that:
- Concepts whose circuits have higher node importance and robustness (centralized, integrated subgraphs) exhibit stronger acquisition but are also more susceptible to forgetting under continued training.
- Greater redundancy and flow efficiency correlate positively with both learning and forgetting, indicating a structural trade-off: features that facilitate strong, rapid learning also amplify subsequent vulnerability to interference and catastrophic forgetting.
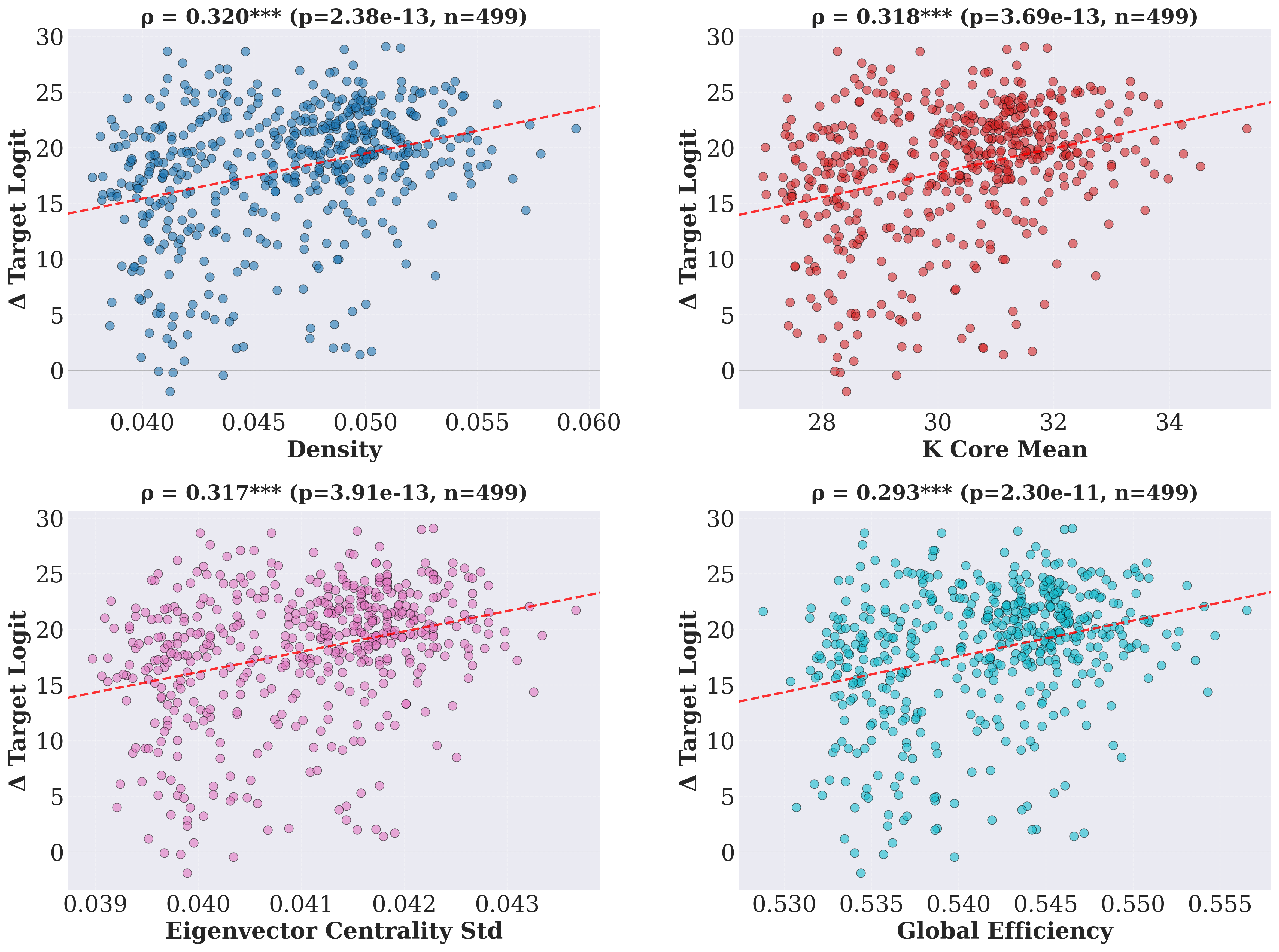
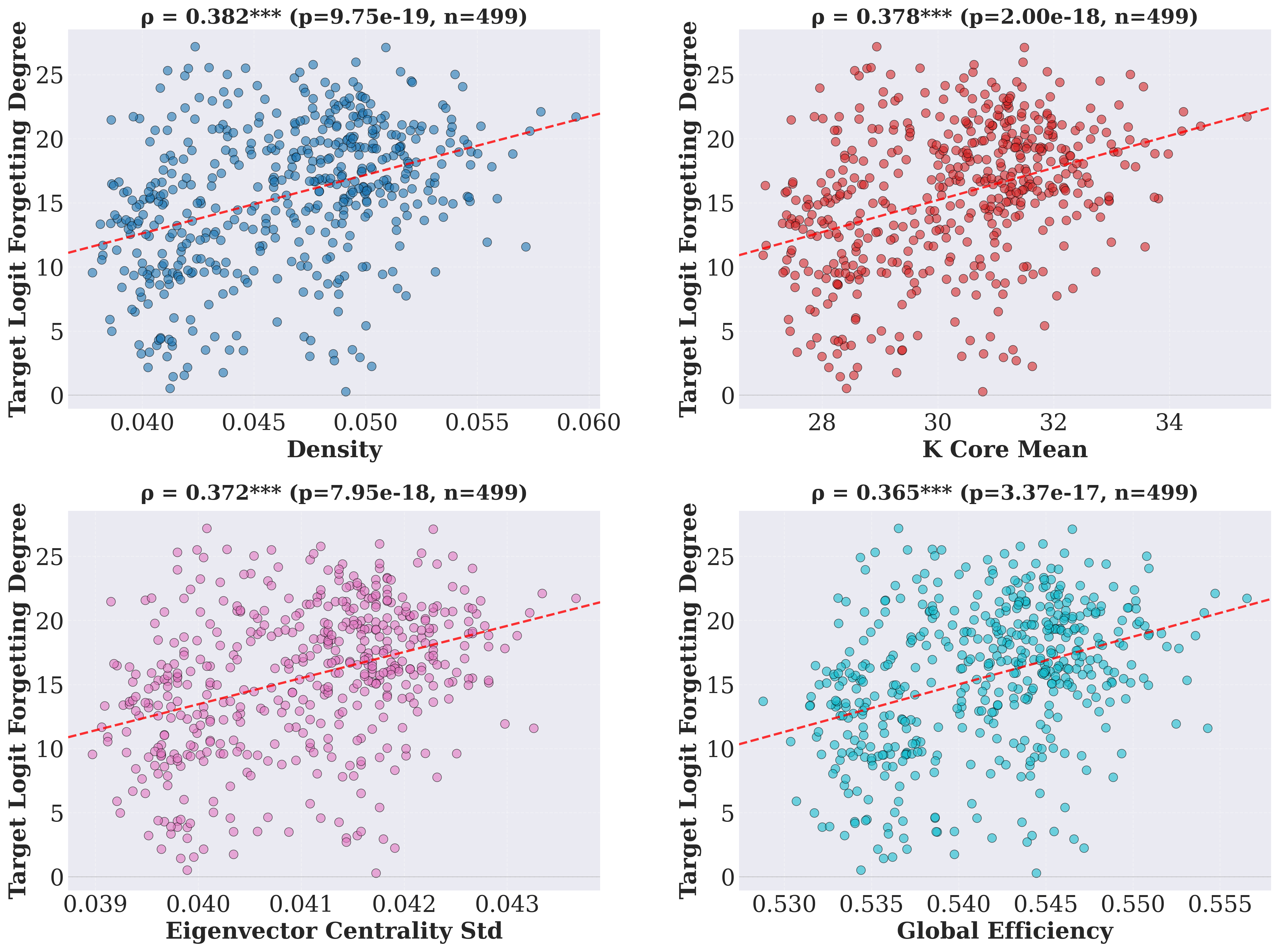
Figure 3: Correlation between learning degree and LLM circuit pattern, indicating structural correlates of acquisition effectiveness.
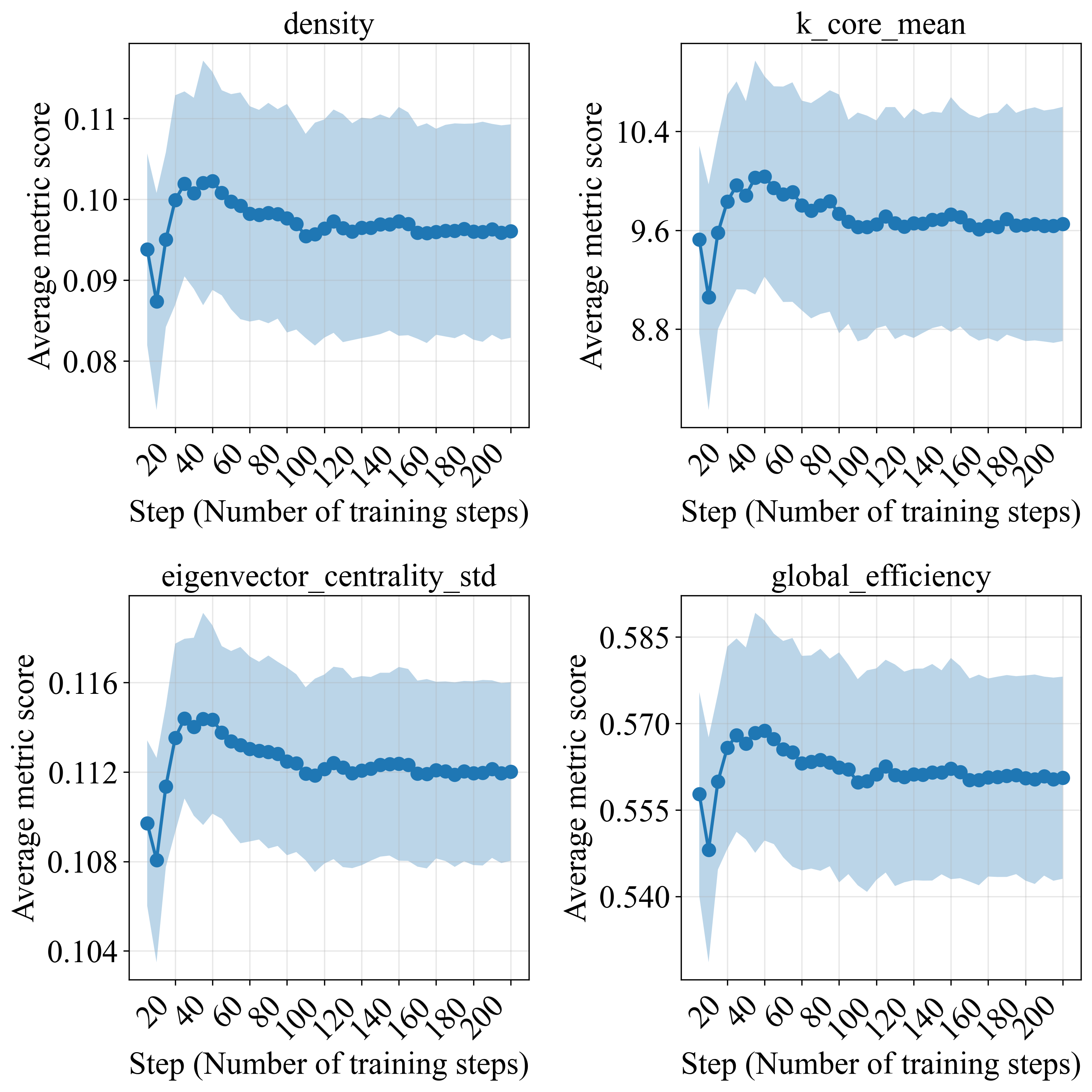
Figure 4: Temporal evolution of graph metrics during continued training, showing stage-wise reorganization with early-phase increases and subsequent stabilization.
Additionally, a direct positive correlation between learning and forgetting degrees is observed: concepts acquired more aggressively tend to be less stable upon further training. This suggests that even though denser, highly integrated circuits improve short-term learning, they induce interference-prone representations that are not robust in the presence of non-stationary data or continual updates.
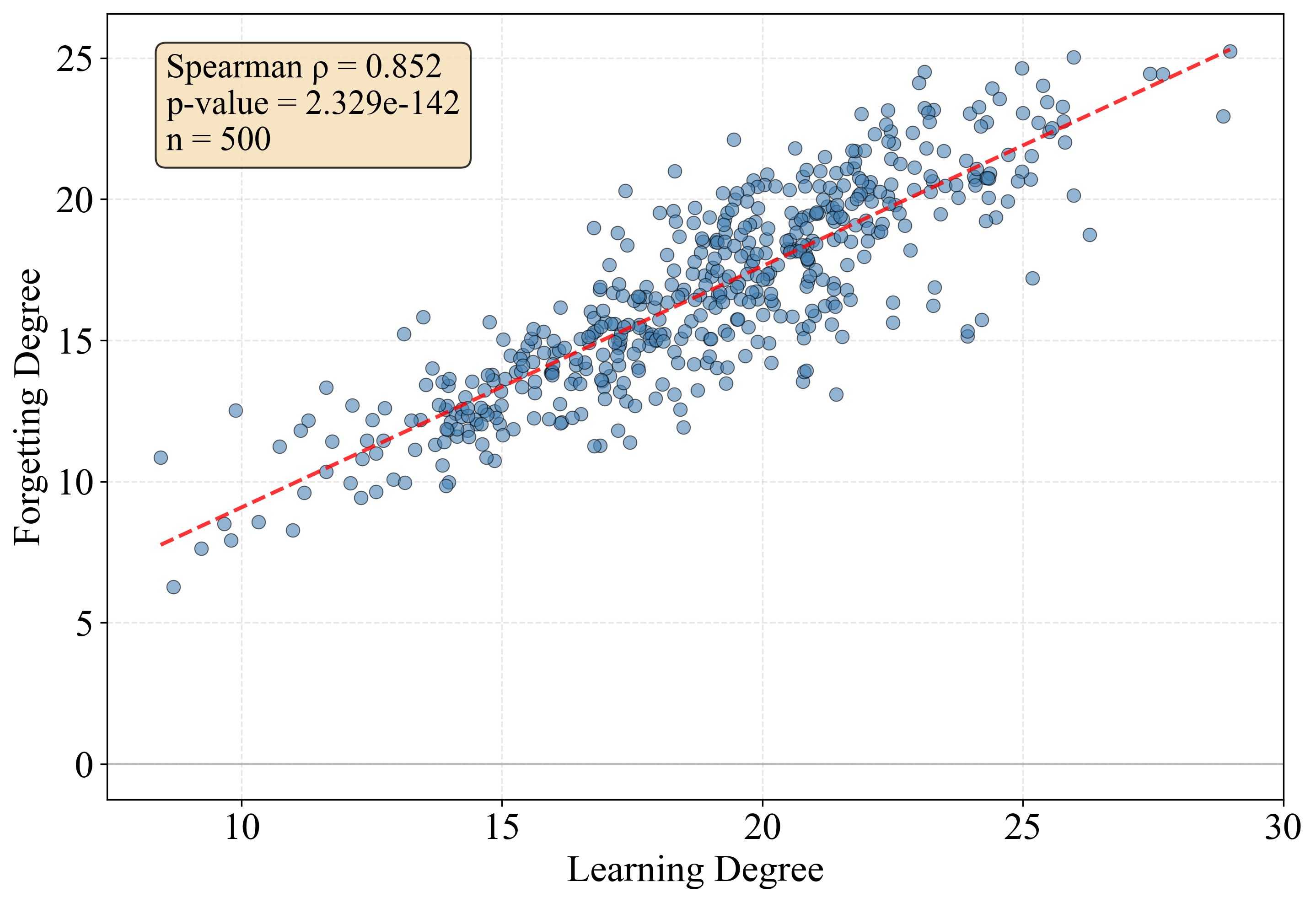
Figure 5: Spearman correlations between learning and forgetting of concepts, quantifying the trade-off between acquisition and retention.
Interference and Synergy in Multi-Concept Representation
Concept-Level Interference
Experiments varying the semantic relatedness of co-trained concepts show that LLMs experience strongest interference when semantically similar concepts are trained jointly, as evidenced by depressed post-training logit and probability performance on target concepts in the presence of highly related distractors. This effect is mechanistically explained by increased circuit overlap: similarity in the Jaccard index of concept circuit edge sets is higher for closely related concepts, amplifying representational competition and increasing vulnerability to forgetting or degraded acquisition.
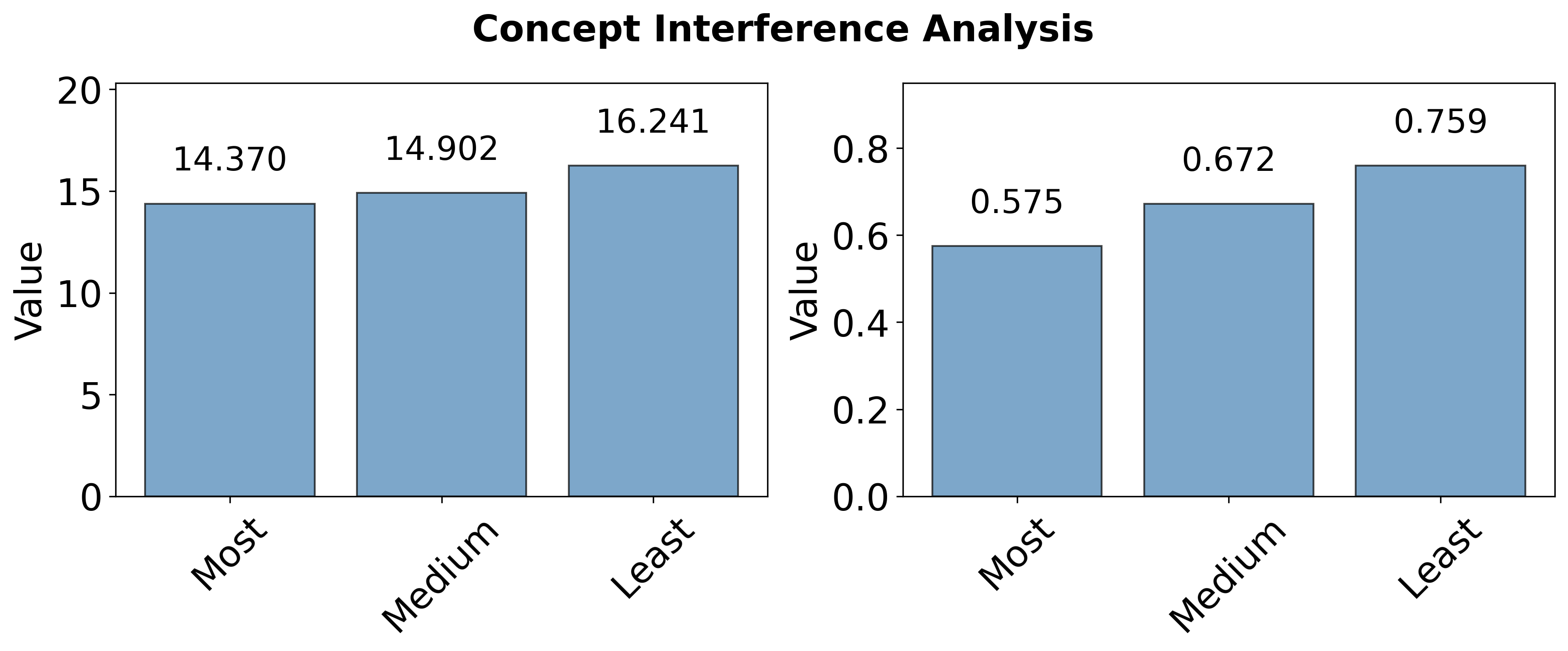
Figure 6: Target concept performance under joint training with semantically related versus unrelated concepts, demonstrating heightened interference among similar concepts.
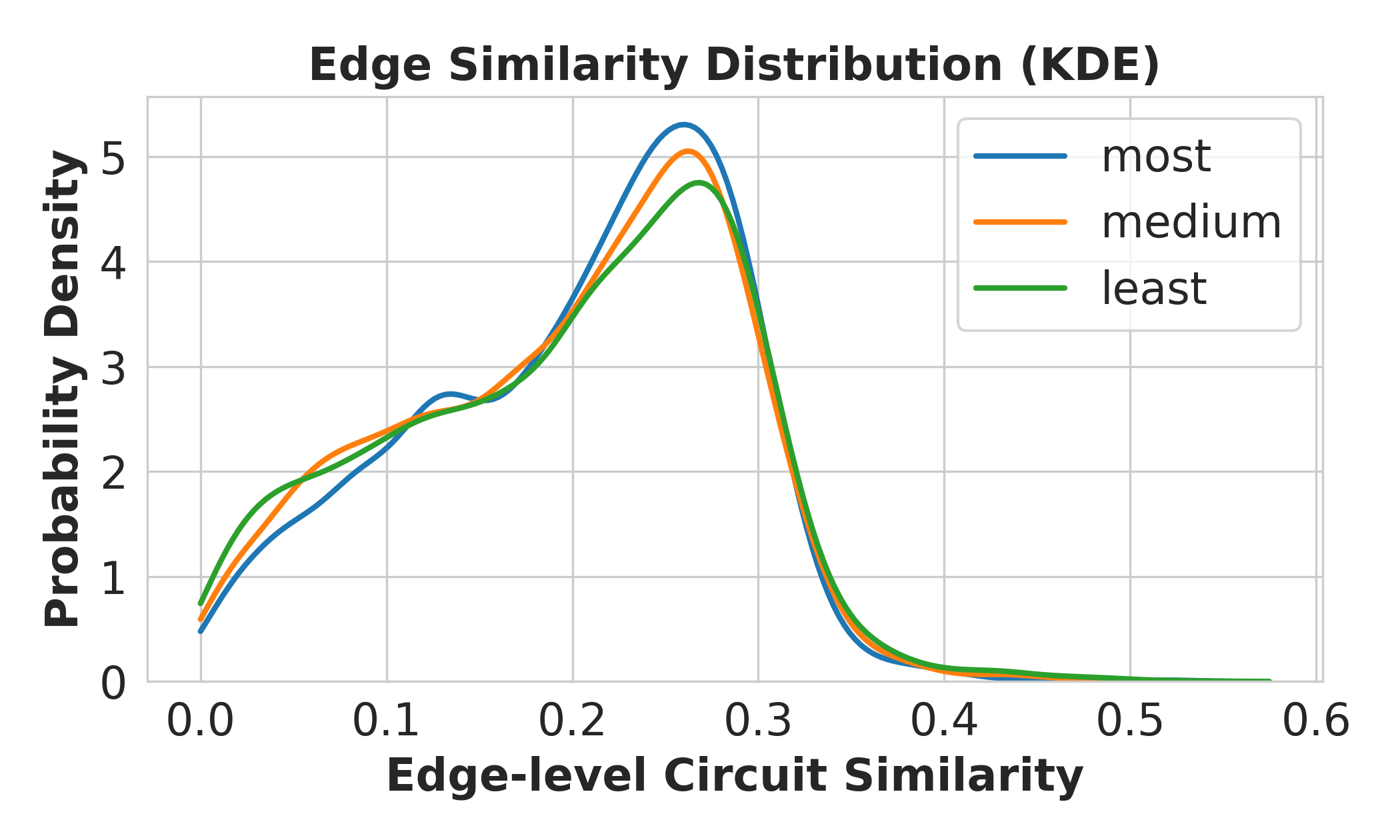
Figure 7: Jaccard similarity distribution across concept circuits, illustrating greater pathway overlap in semantically related concept pairs.
Knowledge-Type Transferability
Inter-knowledge transfer studies analyze the directionality and magnitude of transfer effects among five high-level relational groupings. Non-trivial, asymmetric synergy is detected; for instance, Property–Affordance pre-training facilitates subsequent Hyponym–Hypernym acquisition much more than the reverse. Such patterns suggest non-redundant, hierarchically dependent encodings among knowledge types. The complementarity of knowledge categories provides empirical guidance for scheduling and curriculum methods: ordering data to exploit positive transfer relations can accelerate and stabilize the acquisition of difficult or interference-prone concept knowledge.
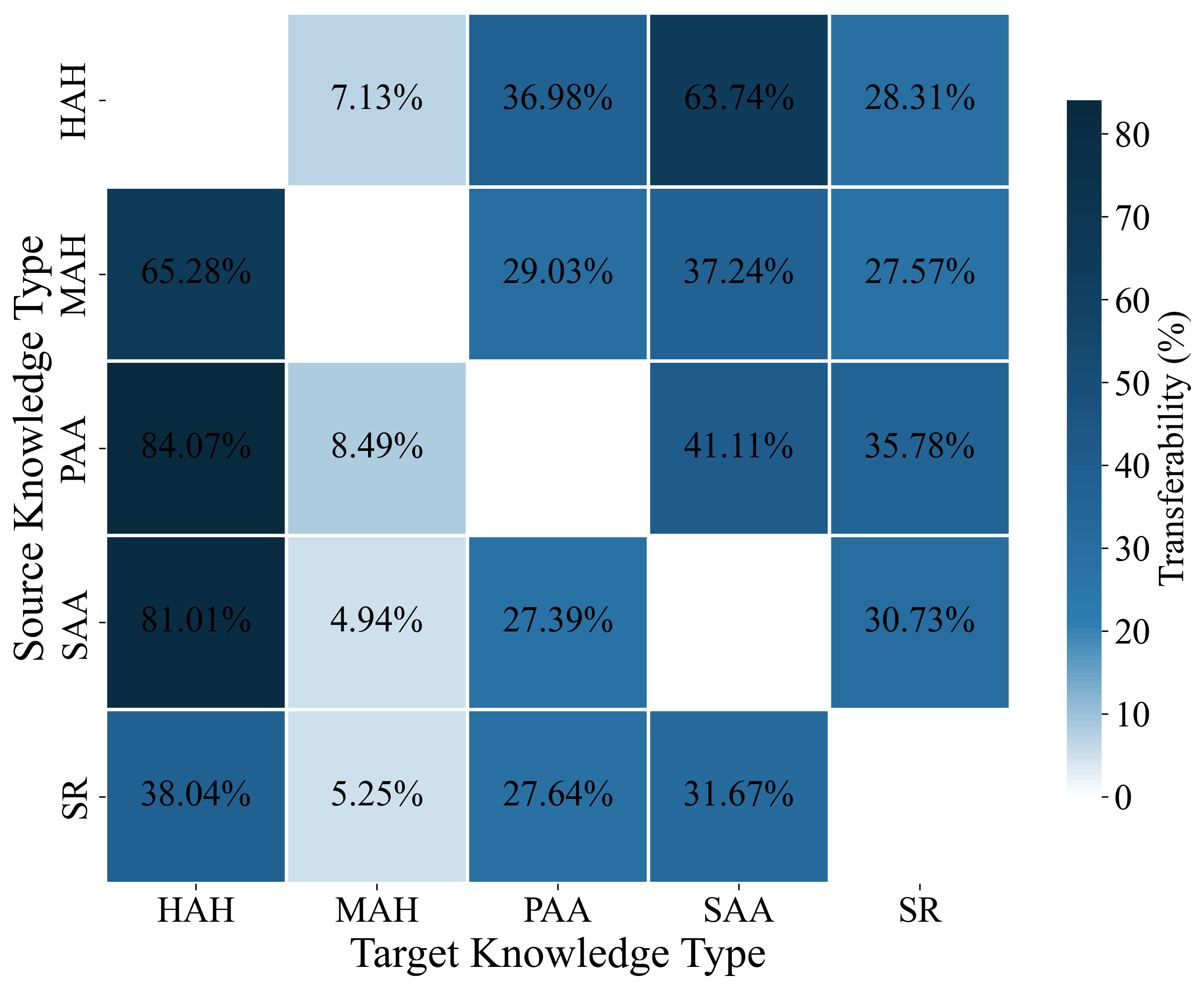
Figure 8: Paired transferability heatmap among knowledge types, showing heterogeneous and asymmetric synergy.
Practical and Theoretical Implications
The findings have direct implications for the design of continual learning strategies, curriculum learning, and proactive interference mitigation. Circuit-level analysis reveals interpretable signals for both learning and forgetting, suggesting that modularization and hub attenuation (reducing circuit overlap among simultaneously trained concepts) may be beneficial. The observed non-uniformity of transfer effects across knowledge types argues for targeted data ordering interventions, leveraging categories that act as scaffolds for subsequent relational encodings.
Theoretically, the results reinforce the perspective that LLMs encode concepts as distributed, circuit-level entities whose acquisition and retention properties are constrained by graph-theoretic structure. Explicitly mapping and leveraging these circuits could inform model design, diagnostic tools for continual learning, and interventions to prevent catastrophic forgetting.
Conclusion
This work establishes that concept learning, retention, interference, and synergy in LLMs can be robustly characterized at the computational subgraph level. By connecting behavioral outcomes with interpretable circuit features, it provides an actionable foundation for concept-aware continual pre-training and curriculum construction. The analysis demonstrates the limitations of highly integrated, non-modular representations for long-term knowledge retention, and the value of circuit-level interpretability in managing cross-concept and cross-knowledge transfer dynamics. Future directions include scaling to larger models, validating interventions based on detected circuit vulnerabilities, and integrating circuit-aware feedback into training pipelines.