- The paper introduces a dual-path framework combining training-free clustering and RL-driven routing to optimally orchestrate LLMs and tools.
- It demonstrates significant performance gains on 15 benchmarks, with improvements in both in-distribution and out-of-distribution settings.
- Atlas offers dynamic adaptation and extensibility by integrating new domain-specialized models and tools at runtime without retraining.
Atlas: A Dual-Path Framework for Orchestrating Heterogeneous Models and Tools in Multi-Domain Reasoning
Introduction and Motivation
The proliferation of LLMs and specialized external tools has expanded the operational landscape of AI agents, enabling finer-grained reasoning and multi-modal problem solving. However, this increasing heterogeneity introduces a non-trivial high-dimensional optimization challenge: determining the optimal orchestration of LLMs and tools for diverse and evolving tasks. Previous systems in tool-augmented LLMs or model routing tend to decouple routing and tool usage, thus failing to extract synergistic potential from their joint configuration space. "Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning" (2601.03872) presents a unified dual-path framework—Atlas—that dynamically aligns and invokes heterogeneous LLM-tool pairs through domain-aware clustering and reinforcement learning (RL)-driven policy optimization.
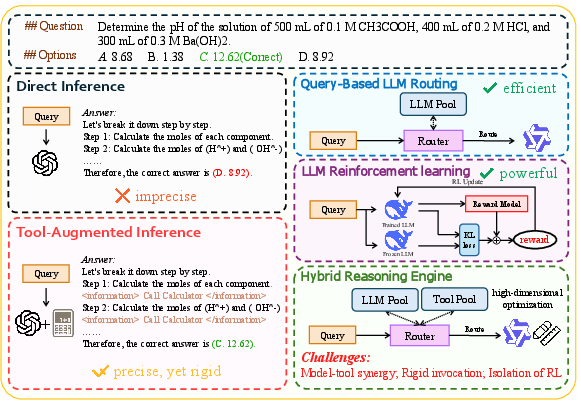
Figure 1: Comparison of different LLM inference paradigms. While routing (efficiency) and RL (performance optimization) present a promising approach, dynamic tool usage still faces significant challenges.
Methodological Framework
Atlas introduces a dual-path architecture that explicitly leverages both empirical priors and autonomous multi-step exploration. The framework consists of:
- Training-Free Cluster-Based Routing: Queries are embedded into a latent semantic space and. clustered (typically via KMeans) to capture domain-specific reasoning and tool affinity. For each (model, tool) pair within every cluster, Atlas computes empirical statistics—accuracy and resource cost—derived from historical data. At inference, new queries are mapped to clusters, and the optimal model-tool pair is retrieved via a utility-maximization criterion balancing performance and cost. This approach enables low-latency selection with constant-time complexity in the number of clusters.
- RL-Driven Multi-Step Routing: For queries outside established empirical priors (unseen domains or complex tasks), an RL policy is trained over an augmented action space comprising both internal reasoning ("think" operations) and dynamic (model, tool) invocations ("route" actions). The agent iteratively constructs a reasoning trajectory, adaptively interleaving internal deliberation and external tool usage, and is trained via PPO with carefully synthesized reward signals: output format integrity, task outcome correctness, and selection efficiency.
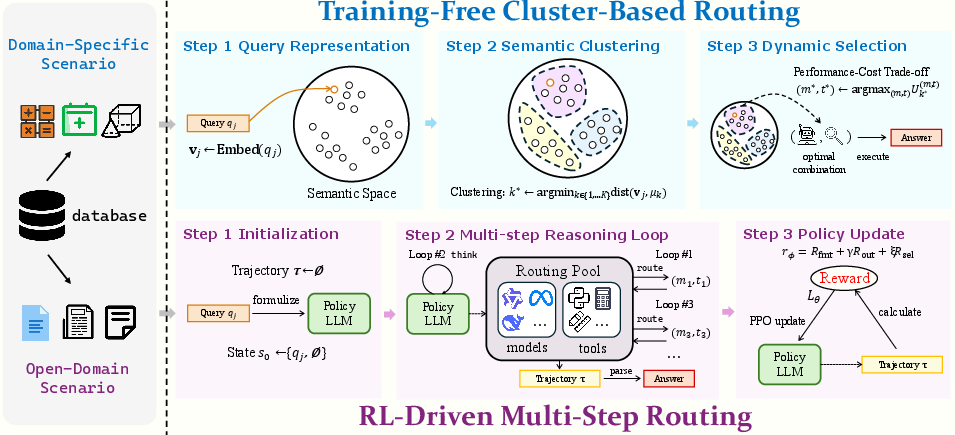
Figure 3: Overview of Adaptive Tool-LLM Alignment and Synergistic Invocation (Atlas). The framework operates via a dual-path approach: (1) Training-free Cluster-based Routing; and (2) RL-driven Multi-step Routing.
This architecture directly models the Cartesian product space of LLMs and tools, bridging the dichotomy between isolated model routing and static tool augmentation by incorporating synergies in a dynamic, query-driven manner.
Experimental Evaluation and Results
Evaluation is conducted on 15 benchmarks spanning mathematical, logical, commonsense, code, and scientific reasoning, as well as challenging multi-modal tasks (e.g., ChartQA, Geometry3K, TableVQA). The framework is compared with sophisticated closed-source systems (e.g., GPT-4o, GPT-5, Gemini2.5) and diverse open-source routing approaches, including contrastive learning-based (RouterDC), MLP and BERT-based classifiers, and prompting-based routers.
Atlas demonstrates the following key results:
- In in-distribution settings, cluster-based routing achieves 63.5% average accuracy, outperforming supervised routers (RouterDC: 53.4%) by +10.1% and even surpassing GPT-4o (53.1%). Notably, on highly nontrivial mathematical reasoning (e.g., AIME25), Atlas gives 40.0% (vs. 23.3% for RouterDC).
- Out-of-distribution (OOD) generalization—where training is restricted to three domains and evaluated on seven others—shows that cluster-based routing degrades sharply (e.g., AIME25: 3.3%). However, RL-based routing sustains robust OOD accuracy, giving a +13.1% gain over RouterDC and a +10.2% gain over the cluster method.
- On multi-modal benchmarks, Atlas via dynamic tool orchestration achieves 68.9% mean accuracy—outperforming any single tool baseline.
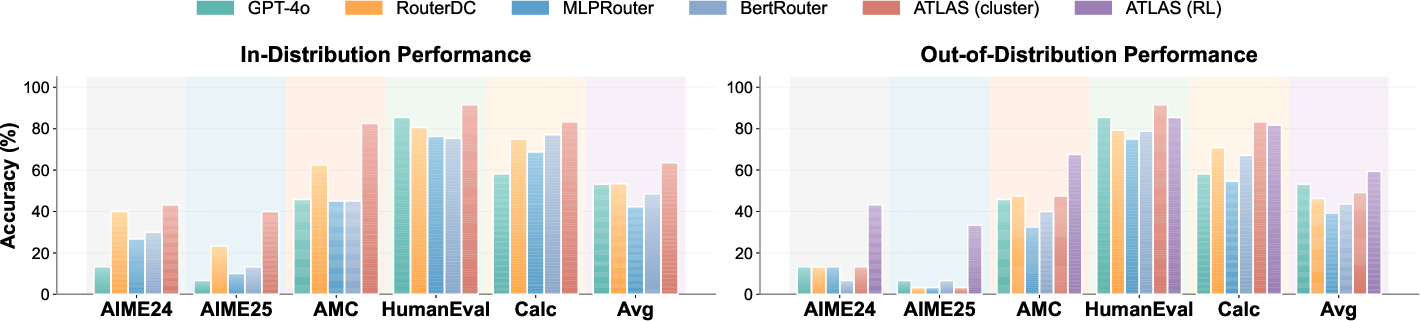
Figure 2: Performance comparison on in-distribution and out-of-distribution settings. Our Atlas method consistently outperforms all baselines across diverse datasets, demonstrating superior generalization capability.
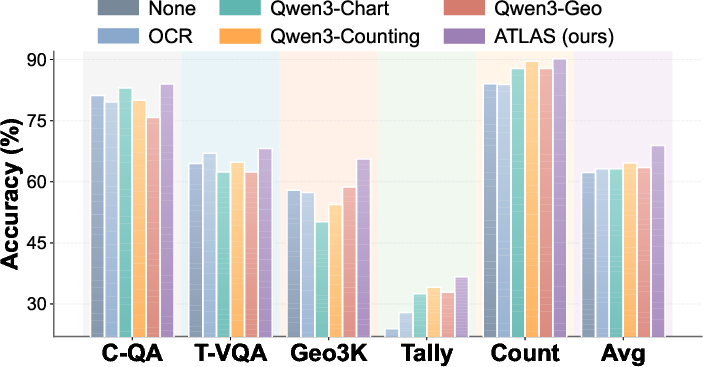
Figure 4: Performance comparison of Atlas against single-tool baselines across multi-modal benchmarks. `None' denotes direct reasoning without any tools. Atlas achieves the highest accuracy.
Robustness to Pool Expansion
Atlas exhibits strong extensibility: by integrating new domain-specialized models and tools at test time, RL-trained policies attain further performance gains (+2.3% on average), most notably on newly-covered domains, without retraining.
Analysis of Reasoning Dynamics
- Pass@k metrics indicate that RL optimization substantially raises both exploration efficiency (pass@1) and the ceiling of achievable reasoning (pass@16), reflecting enhanced multi-stage decision-making.
- API call count analysis reveals task-adaptive resource allocation, with more model/tool invocations on complex tasks and parsimonious selection when simple solutions suffice.
- RL training curves (reward, entropy loss) show that including model selection rewards accelerates convergence and yields more confident, deterministic routing strategies.
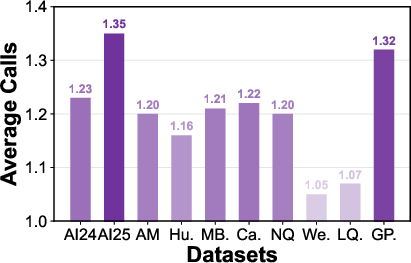
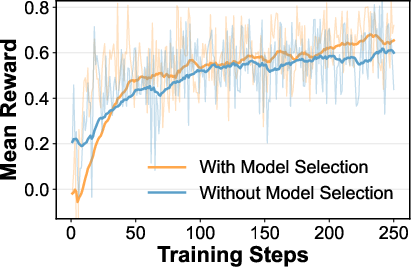
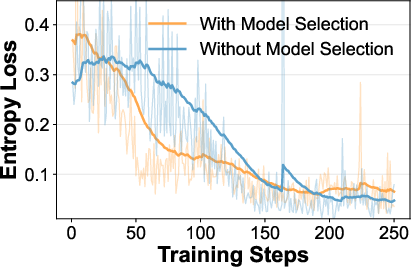
Figure 5: Analysis of LLM API call count and Atlas(RL) training dynamics.
Case Studies and Illustrative Reasoning Trajectories
Detailed case studies demonstrate Atlas’s flexible orchestration strategies:
- Logical reasoning tasks involve iterative re-routing across models and tools when initial reasoning is contradicted by subsequent evidence (see Figure 6: LQA2 example).
- Mathematical computation triggers direct invocation of the calculator tool; factual queries trigger web search tool usage.
- Atlas consistently aligns programming problems with code-specialized models and arithmetic problems with calculators, demonstrating learned alignment preferences.
- In multi-step reasoning, Atlas’s RL policy adapts discourse structure and external tool usage in response to intermediate outcomes.

Figure 7: Example 1 on the LQA2 dataset.

Figure 9: Example 4 on the MBPP dataset.

Figure 11: Example 5 on the AIME dataset.
Implications and Theoretical Perspectives
Atlas substantiates that optimal performance in complex, heterogeneous reasoning tasks necessitates moving beyond monolithic model scaling or isolated tool usage towards adaptive, ecosystem-centric orchestration. The dual-path architecture displays complementary strengths: clustering offers lightweight, domain-aware deployment in environments with abundant labeled data, while RL-based policies are critical in OOD generalization and settings with task drift or dynamic pool expansion.
The composite reward—comprising format, outcome, and selection efficiency—enables decoupling structural execution from model/tool alignment, facilitating transferability and robust adaptation in real-world deployments. Furthermore, Atlas’s design demonstrates that explicit modeling of model-tool synergies in routing policies yields measurable gains in both efficiency and predictive accuracy, even using only moderately-sized (7B/8B) LLMs.
Future Directions
Key future avenues include:
- Extension to additional modalities (audio, video) and inclusion of broader tool types.
- Incorporation of self-verification and pseudo-labeling dynamics to further reduce reliance on labeled reward signals.
- Exploration of more sample- and latency-efficient RL or meta-learning policies for real-time, low-resource environments.
- Addressing distributed latency and unreliable tool/model endpoints in real-world, production-grade deployments.
Conclusion
Atlas establishes a new design paradigm for dynamic LLM-agent orchestration, achieving robust performance and generalization by leveraging both empirical semantic priors and RL-driven reasoning over heterogeneous LLM-tool spaces. The dual-path framework provides a scalable and adaptable blueprint for future multi-domain AI agents, underlining the shift from model-centric to ecosystem-centric intelligence in complex reasoning scenarios.